爬虫进阶Selenium处理iframe, 多窗口调度
Posted ZSYL
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫进阶Selenium处理iframe, 多窗口调度相关的知识,希望对你有一定的参考价值。
Selenium处理iframe, 多窗口调度
前言
上回说到我们已经可以通过selenium拿到拉钩网的招
聘信息了. 但是, 信息不够全面. 我们希望得到的不仅仅是⼀个岗位名称和公司名称, 我更想知道更加详细的职位描述以及岗位要求.
1. 切换窗口
此时问题就来了. 我们可以在搜索页面点击进入到这个详情页. 然后就可以看到想要的职位描述了. 但是, 这时就涉及到如何从⼀个窗口转向另⼀个窗口了(切换选项卡).
首先, 我们先通过selenium定位到搜索页上的职位超链接.
from selenium.webdriver import Chrome
from selenium.webdriver.common.keys import Keys
import time
web = Chrome()
web.get("http://www.lagou.com")
web.find_element_by_xpath('//*[@id="changeCityBox"]/ul/li[1]/a').click()
time.sleep(2)
web.find_element_by_xpath('//*[@id="search_input"]').send_keys("python",Keys.ENTER)
time.sleep(2)
# 不要红包
web.find_element_by_xpath('/html/body/div[8]/div/div[2]').click()
# 点击职位
web.find_element_by_xpath('//*[@id="s_position_list"]/ul/li[1]/div[1]/div[1]/div[1]/a/h3').click()
time.sleep(1)
正片开始
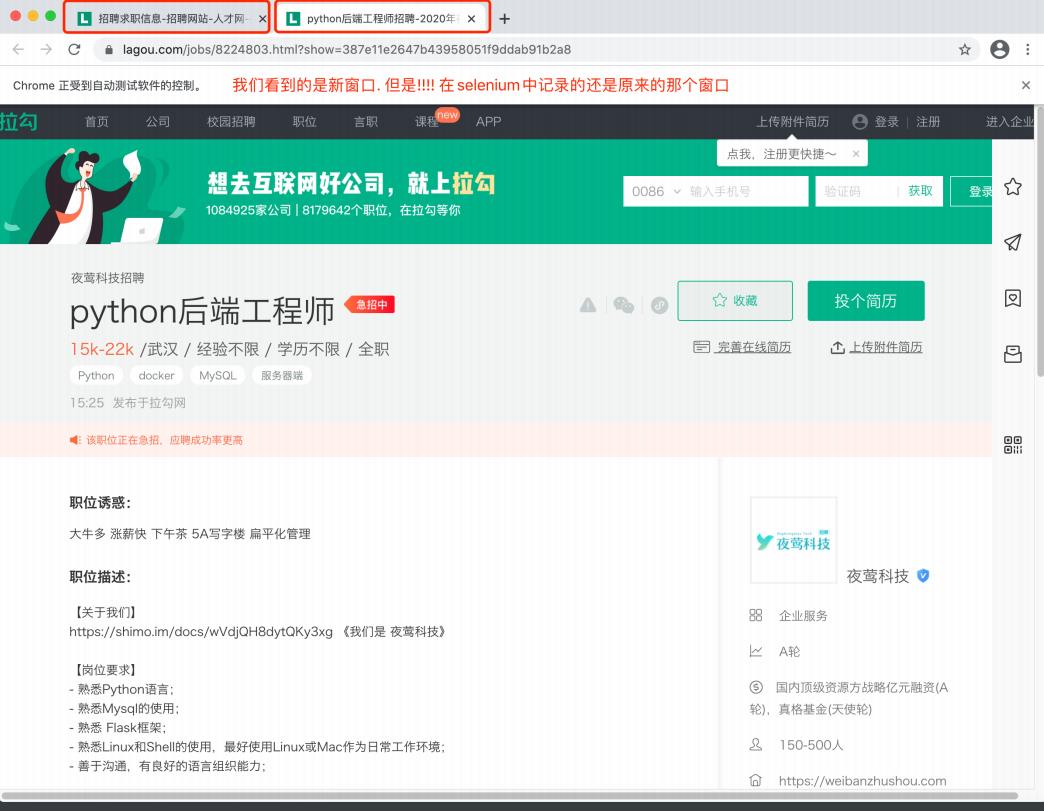
注意! 我们看到的是新窗口的内容, 但是在selenium的视角里, 窗口依然停留在刚才那个窗口. 此时, 必须要将窗口调整到最新的窗口上才可以。
# 正⽚开始
web.switch_to.window(web.window_handles[-1]) # 跳转到最后⼀个窗⼝
job_detail = web.find_element_by_xpath('//*[@id="job_detail"]/dd[2]').text
print(job_detail)
2. iframe处理
接下来我们来看另⼀种操作.
之前我们抓取过⼀个网站. 里面把视频内容嵌套在⼀个iframe中.
那如果换成了selenium应该如何应对呢?

web = Chrome()
web.get("https://www.91kanju.com/vod-play/541-2-1.html")
# 找到那个iframe
iframe = web.find_element_by_xpath('//*[@id="player_iframe"]')
web.switch_to.frame(iframe)
val = web.find_element_by_xpath('/html/body/div[4]').get_attribute("value")
print(val)
3. 后序
Selenium的更多内容,请参考:【爬虫进阶】Selenium的常用方法(建议收藏)
加油!
感谢!
努力!
以上是关于爬虫进阶Selenium处理iframe, 多窗口调度的主要内容,如果未能解决你的问题,请参考以下文章