全网最快掌握机器学习之深度学习之神经网络数学基础(附源代码)
Posted yk 坤帝
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了全网最快掌握机器学习之深度学习之神经网络数学基础(附源代码)相关的知识,希望对你有一定的参考价值。
个人公众号yk 坤帝
后台回复 机器学习 获得源代码
1.全文简介
要理解深度学习,需要熟悉很多简单的数学概念:张量、张量运算、微分、梯度下降等。本文目的是用不那么技术化的文字帮你建立对这些概念的直觉。特别地,我们将避免使用数学符号,因为数学符号可能会令没有任何数学背景的人反感,而且对解释问题也不是绝对必要的。
本文将首先给出一个神经网络的示例,引出张量和梯度下降的概念,然后逐个详细介绍。请记住,这些概念对于理解后续文章中的示例至关重要。
读完本文后,你会对神经网络的工作原理有一个直观的理解,然后就可以学习神经网络的实际应用了(从下一篇开始)。
2.1 初识神经网络
我们来看一个具体的神经网络示例,使用 Python 的 Keras 库来学习手写数字分类。如果你没用过 Keras 或类似的库,可能无法立刻搞懂这个例子中的全部内容。甚至你可能还没有安装Keras。没关系,下一章会详细解释这个例子中的每个步骤。因此,如果其中某些步骤看起来有些随意,或者像魔法一样,也请你不要担心。下面我们要开始了。
我们这里要解决的问题是,将手写数字的灰度图像(28 像素×28 像素)划分到 10 个类别中(0~9)。我们将使用 MNIST 数据集,它是机器学习领域的一个经典数据集,其历史几乎和这个领域一样长,而且已被人们深入研究。这个数据集包含 60 000 张训练图像和 10 000 张测试图像,由美国国家标准与技术研究院(National Institute of Standards and Technology,即 MNIST 中 的 NIST)在 20 世纪 80 年代收集得到。你可以将“解决”MNIST 问题看作深度学习的“Hello World”,正是用它来验证你的算法是否按预期运行。当你成为机器学习从业者后,会发现MNIST 一次又一次地出现在科学论文、博客文章等中。图 2-1 给出了 MNIST 数据集的一些样本。
关于类和标签的说明
在机器学习中,分类问题中的某个类别叫作类(class)。数据点叫作样本(sample)。某个样本对应的类叫作标签(label)。

你不需要现在就尝试在计算机上运行这个例子。但如果你想这么做的话,首先需要安装Keras,安装方法见 3.3 节。
MNIST 数据集预先加载在 Keras 库中,其中包括 4 个 Numpy 数组。

from keras.datasets import mnist
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
train_images 和 train_labels 组成了训练集(training set),模型将从这些数据中进行学习。然后在测试集(test_set,即 test_images 和 test_labels)上对模型进行测试。
图像被编码为 Numpy 数组,而标签是数字数组,取值范围为 0~9。图像和标签一一对应。
我们来看一下训练数据:

下面是测试数据:

接下来的工作流程如下:首先,将训练数据(train_images 和 train_labels)输入神经网络;其次,网络学习将图像和标签关联在一起;最后,网络对 test_images 生成预测,而我们将验证这些预测与 test_labels 中的标签是否匹配。
下面我们来构建网络。再说一遍,你现在不需要理解这个例子的全部内容。


神经网络的核心组件是层(layer),它是一种数据处理模块,你可以将它看成数据过滤器。
进去一些数据,出来的数据变得更加有用。具体来说,层从输入数据中提取表示——我们期望这种表示有助于解决手头的问题。大多数深度学习都是将简单的层链接起来,从而实现渐进式的数据蒸馏(data distillation)。深度学习模型就像是数据处理的筛子,包含一系列越来越精细的数据过滤器(即层)。
本例中的网络包含 2 个 Dense 层,它们是密集连接(也叫全连接)的神经层。第二层(也是最后一层)是一个 10 路 softmax 层,它将返回一个由 10 个概率值(总和为 1)组成的数组。每个概率值表示当前数字图像属于 10 个数字类别中某一个的概率。
要想训练网络,我们还需要选择编译(compile)步骤的三个参数。
‰ 损失函数(loss function):网络如何衡量在训练数据上的性能,即网络如何朝着正确的方向前进。
‰ 优化器(optimizer):基于训练数据和损失函数来更新网络的机制。
‰ 在训练和测试过程中需要监控的指标(metric):本例只关心精度,即正确分类的图像所占的比例。
后续两章会详细解释损失函数和优化器的确切用途。

在开始训练之前,我们将对数据进行预处理,将其变换为网络要求的形状,并缩放到所有值都在 [0, 1] 区间。比如,之前训练图像保存在一个 uint8 类型的数组中,其形状为(60000, 28, 28),取值区间为 [0, 255]。我们需要将其变换为一个 float32 数组,其形状为 (60000, 28 * 28),取值范围为 0~1。

我们还需要对标签进行分类编码,第 3 章将会对这一步骤进行解释。

现在我们准备开始训练网络,在 Keras 中这一步是通过调用网络的 fit 方法来完成的——我们在训练数据上拟合(fit)模型。

训练过程中显示了两个数字:一个是网络在训练数据上的损失(loss),另一个是网络在训练数据上的精度(acc)。
我们很快就在训练数据上达到了 0.989(98.9%)的精度。现在我们来检查一下模型在测试集上的性能。

测试集精度为 97.8%,比训练集精度低不少。训练精度和测试精度之间的这种差距是过拟合(overfit)造成的。过拟合是指机器学习模型在新数据上的性能往往比在训练数据上要差,它是第 3 章的核心主题。
第一个例子到这里就结束了。你刚刚看到了如何构建和训练一个神经网络,用不到 20 行的Python 代码对手写数字进行分类。下一章会详细介绍这个例子中的每一个步骤,并讲解其背后的原理。接下来你将要学到张量(输入网络的数据存储对象)、张量运算(层的组成要素)和梯度下降(可以让网络从训练样本中进行学习)。
2.2 神经网络的数据表示
前面例子使用的数据存储在多维 Numpy 数组中,也叫张量(tensor)。一般来说,当前所有机器学习系统都使用张量作为基本数据结构。张量对这个领域非常重要,重要到 Google 的TensorFlow 都以它来命名。那么什么是张量?
张量这一概念的核心在于,它是一个数据容器。它包含的数据几乎总是数值数据,因此它是数字的容器。你可能对矩阵很熟悉,它是二维张量。张量是矩阵向任意维度的推广[注意,张量的维度(dimension)通常叫作轴(axis)]。
2.2.1 标量(0D 张量)
仅包含一个数字的张量叫作标量(scalar,也叫标量张量、零维张量、0D 张量)。在 Numpy中,一个 float32 或 float64 的数字就是一个标量张量(或标量数组)。你可以用 ndim 属性来查看一个 Numpy 张量的轴的个数。标量张量有 0 个轴(ndim == 0)。张量轴的个数也叫作阶(rank)。下面是一个 Numpy 标量。

2.2.2 向量(1D 张量)
数字组成的数组叫作向量(vector)或一维张量(1D 张量)。一维张量只有一个轴。下面是一个 Numpy 向量。
>>> x = np.array([12, 3, 6, 14, 7])
>>> x
array([12, 3, 6, 14, 7])
>>> x.ndim
1
这个向量有 5 个元素,所以被称为 5D 向量。不要把 5D 向量和 5D 张量弄混! 5D 向量只有一个轴,沿着轴有 5 个维度,而 5D 张量有 5 个轴(沿着每个轴可能有任意个维度)。维度(dimensionality)可以表示沿着某个轴上的元素个数(比如 5D 向量),也可以表示张量中轴的个数(比如 5D 张量),这有时会令人感到混乱。对于后一种情况,技术上更准确的说法是 5 阶张量(张量的阶数即轴的个数),但 5D 张量这种模糊的写法更常见
2.2.3 矩阵(2D 张量)
向量组成的数组叫作矩阵(matrix)或二维张量(2D 张量)。矩阵有 2 个轴(通常叫作行和 列)。你可以将矩阵直观地理解为数字组成的矩形网格。下面是一个 Numpy 矩阵。
>>> x = np.array([[5, 78, 2, 34, 0],
[6, 79, 3, 35, 1],
[7, 80, 4, 36, 2]])
>>> x.ndim
2
第一个轴上的元素叫作行(row),第二个轴上的元素叫作列(column)。在上面的例子中,[5, 78, 2, 34, 0] 是 x 的第一行,[5, 6, 7] 是第一列。
2.2.4 3D 张量与更高维张量
将多个矩阵组合成一个新的数组,可以得到一个 3D 张量,你可以将其直观地理解为数字组成的立方体。下面是一个 Numpy 的 3D 张量。
> 个人公众号yk 坤帝
> 后台回复 机器学习 获得源代码
>>> x = np.array([[[5, 78, 2, 34, 0],
[6, 79, 3, 35, 1],
[7, 80, 4, 36, 2]],
[[5, 78, 2, 34, 0],
[6, 79, 3, 35, 1],
[7, 80, 4, 36, 2]],
[[5, 78, 2, 34, 0],
[6, 79, 3, 35, 1],
[7, 80, 4, 36, 2]]])
>>> x.ndim
3
将多个 3D 张量组合成一个数组,可以创建一个 4D 张量,以此类推。深度学习处理的一般是 0D 到 4D 的张量,但处理视频数据时可能会遇到 5D 张量。
2.2.5 关键属性
张量是由以下三个关键属性来定义的。
‰
轴的个数(阶)。例如,3D 张量有 3 个轴,矩阵有 2 个轴。这在 Numpy 等 Python 库中 也叫张量的 ndim。
‰
形状。这是一个整数元组,表示张量沿每个轴的维度大小(元素个数)。例如,前面矩 阵示例的形状为 (3, 5),3D 张量示例的形状为 (3,3, 5)。向量的形状只包含一个 元素,比如 (5,),而标量的形状为空,即 ()。
‰
数据类型(在 Python 库中通常叫作> dtype)。这是张量中所包含数据的类型,例如,张 量的类型可以是 float32、uint8、float64 等。在极少数情况下,你可能会遇到字符 (char)张量。注意,Numpy(以及大多数其他库)中不存在字符串张量,因为张量存储在预先分配的连续内存段中,而字符串的长度是可变的,无法用这种方式存储。
为了具体说明,我们回头看一下 MNIST 例子中处理的数据。首先加载MNIST 数据集。
> 个人公众号yk 坤帝
> 后台回复 机器学习 获得源代码
from keras.datasets import mnist
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
接下来,我们给出张量 train_images 的轴的个数,即 ndim 属性。
>>> print(train_images.ndim)
3
下面是它的形状。
>>> print(train_images.shape)
(60000, 28, 28)
下面是它的数据类型,即 dtype 属性。
>>> print(train_images.dtype)
uint8
所以,这里 train_images 是一个由 8 位整数组成的 3D 张量。更确切地说,它是 60 000个矩阵组成的数组,每个矩阵由 28×28 个整数组成。每个这样的矩阵都是一张灰度图像,元素取值范围为 0~255。
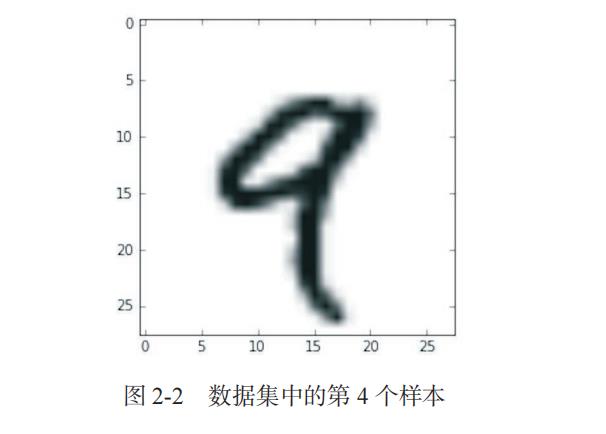
我们用 Matplotlib 库(Python 标准科学套件的一部分)来显示这个 3D 张量中的第 4 个数字,如图 2-2 所示。
代码清单 2-6 显示第 4 个数字
digit = train_images[4]
import matplotlib.pyplot as plt
plt.imshow(digit, cmap=plt.cm.binary)
plt.show()
个人公众号yk 坤帝
后台回复 机器学习 获得源代码
以上是关于全网最快掌握机器学习之深度学习之神经网络数学基础(附源代码)的主要内容,如果未能解决你的问题,请参考以下文章