高并发服务优化篇:一图详解1.7HashMap死循环的产生
Posted 程序员大咖
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了高并发服务优化篇:一图详解1.7HashMap死循环的产生相关的知识,希望对你有一定的参考价值。
????????关注后回复 “进群” ,拉你进程序员交流群????????
作者丨Coder的技术之路
来源丨Coder的技术之路
上篇文章详细剖析多线程下的linkedHashMap读写锁下的内存泄漏问题。不少朋友私下说这种按步骤详细剖析的方式很不错。
我给这种形式起了个响亮的名字--刨根问底儿拦不住。
并发下的线程安全问题,还有一个典型的例子就是1.7之前的HashMap,也是很多面试官喜欢问的,那么,为什么其在多线程下会出现死循环。今天我们就来一起剖析一下~
Part1JDK1.7的HashMap概述
先说一点大家都知道的。
HashMap采用数组+链表的方式进行存储。来解决hash查询和hash冲突。
随着元素的不断增多,HashMap会进行数组扩容,装填因子之类的信息我们这里就忽略了。
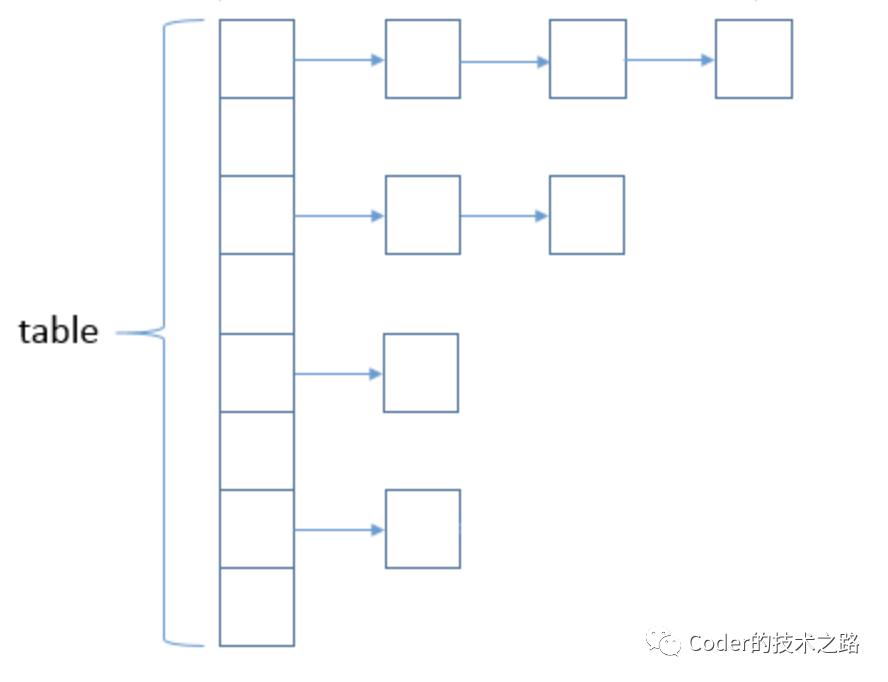
由于元素的hash是和数组大小有关的,因此,在扩容之后,需要重新hash,将元素移动到正确的位置上,以便hash定位。
扩容和移动的方式,是创建一个新的数组,将原始数据,根据新的hash值,用头插法插入到新的数组。最后,用新的数组代替老的数组,完成扩容。
那么,为什么多线程下,这个过程会发生死循环异常呢?
Part2剖析死循环的产生
一图胜千言,更何况是动态图~
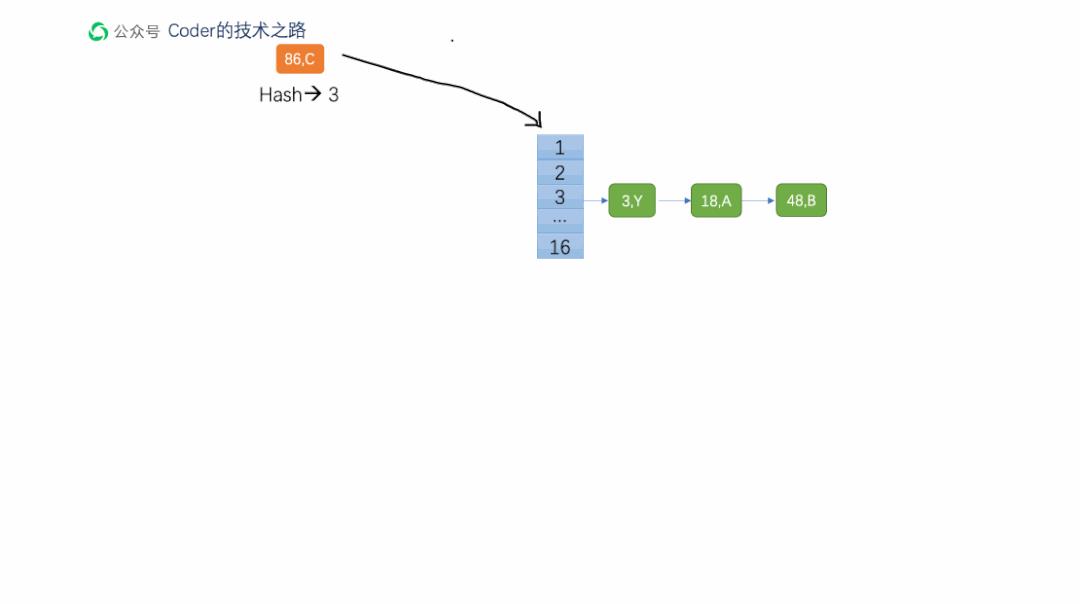
结合上图,现在有<18,A> <48,B> <86,C> 三个元素被存储在table[3]的链表中。
当线程1执行到一半,正好时间片用完,此时:e = <18,A> ,next = <48,B>
再一次获取到时间片时,table引用已经是线程2处理完的结果。即newTable[19]=<86,C> -> <48,B> -> <18,A> (尾插法的结果)
这时,如果线程1再继续按原始顺序处理,将e = <18,A> ,next = <48,B> 依次插入链表头部,则变成了:
<48,B> -> <18,A> -> <86,C> -> <48,B> -> <18,A>
<18,A>.next 本来应该是Null,或者其他元素,现在变成了*<86,C>*,链表成环。
此时,如果有线程来get(19) , 而元素又在A,B,C 之外,在链表中遍历,就有可能一直循环下去。
Part3那1.8为什么不会成环
我们先看下jdk1.8下的resize源码:
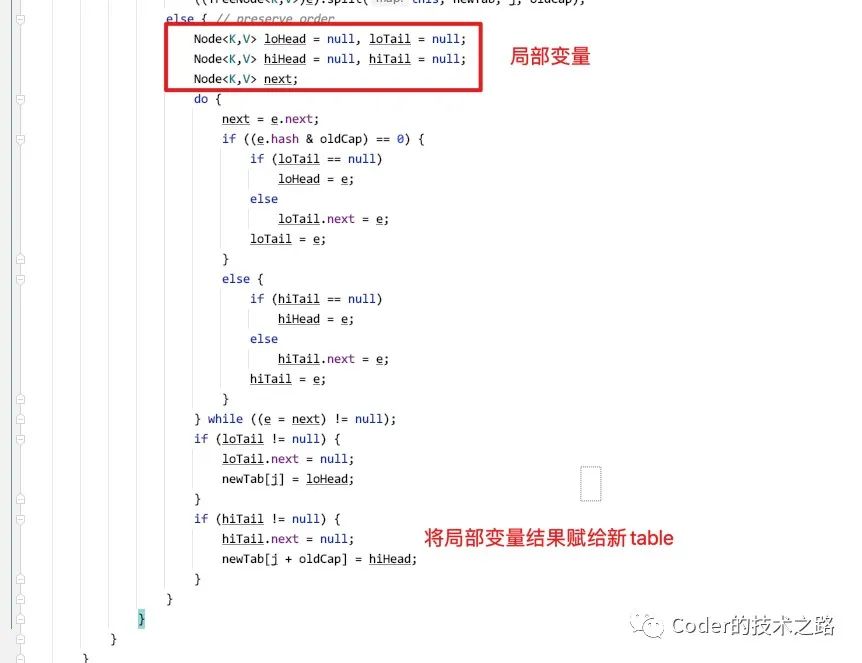
一个是改用了尾部插入来保证了新链表顺序和原始链表顺序一致;另一个是改用局部变量来维护需要移动的元素,最后再把局部变量赋值给newTab,避免了直接在tab上操作导致成环。
Part4后话
不管是哪个版本的hashMap,都是线程不安全的,使用时要特别注意~
上述剖析,发现有啥问题,欢迎大家菜单栏加我微信一起交流探讨~
刨根问底儿拦不住,当在一行一行代码的探究下,把问题搞清楚时,不会有一种浑身得劲的感觉么~
-End-
最近有一些小伙伴,让我帮忙找一些 面试题 资料,于是我翻遍了收藏的 5T 资料后,汇总整理出来,可以说是程序员面试必备!所有资料都整理到网盘了,欢迎下载!
点击????卡片,关注后回复【面试题】即可获取
在看点这里 好文分享给更多人↓↓
好文分享给更多人↓↓
以上是关于高并发服务优化篇:一图详解1.7HashMap死循环的产生的主要内容,如果未能解决你的问题,请参考以下文章