Linux监控详解
Posted givenchy_yzl
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Linux监控详解相关的知识,希望对你有一定的参考价值。
什么是监控?
监控===监测+控制
生活中的监控:事故追责
运维中的监控:事后追责,事前预警,性能分析,实时报警
为什么要使用监控
监控是整个产品周期中最重要的一环,及时预警减少故障避免影响扩大,根据历史数据可以追溯问题根源,并且分析监控数据,可以找出用户体验优化方案。
随着用户的增多,服务随时可能会被系统oom(out of memory内存溢出)
后果:kill -9 mysql
如何判断?,web服务是因为用户访问过多,达到了瓶颈? 还是程序代码bug导致的,内存过多?
上线一个新网站:压力测试 2000并发,oom(out of memeory)
监控的类型
按照层次划分可简单分为:
应用层:nginx,mysql,java
运行层:Windows,linux
硬件层:内存,cpu,磁盘,网络
常见的监控方法
Linux常用监控命令
下列命令多用来监控网络,cpu,内存,硬盘
1.top #系统时间 登录用户 负载 进程 cpu 内存 swap 进程详细信息
2.htop(eple) # 系统时间 登录用户 负载 进程 cpu 内存 swap 进程详细信息 支持鼠标 树状 快捷键
3.uptime #当前系统运行时间、登录用户数、负载数
4.free # 监控内存
5.vmstat # 进程、虚存、页面交换空间及CPU
5.iostat # 磁盘I/O统计
6.df # 查看硬盘使用 -h block -i inode
7.iftop # 流量监控工具
8.nethogs # 查看进程占用的网络带宽
9.iotop # 进程占用的硬盘I/O
脚本
不使用工具的情况下,可以使用脚本+定时任务完成监控操作
缺点:效率低,无法集中报警,无法分析历史数据
如:监控内存的脚本
[root@k8s ~]# cat mem_alter.sh
#!/bin/bash
MEM=`free -m|awk 'NR==2{print $NF}'`
if [ $MEM -lt 100 ];then
echo "web服务器 192.168.15.1 可用内存不足,当前可用内存
$MEM" | mail -s "web服务器内存不足" yzl_long@qq.com
fi
防止dos攻击的脚本(定义一个异常值,此处为20)
#!/bin/bash
while true
do
awk '{print $1}' /uer/local/nginx/logs/access.log |grep -v "^$" |sort |uniq -c >tmp.log
exce < tmp.log
while read line
do
ip = `echo $line |awk '{print 2}'`
count =`echo $line |awk '{print 1}'`
if [$count -gt 20] && [`iptables -n -L |grep "$ip" |wc -l ` -lt 1]
then
iptables -I INPUT -s $ip -j DROP
echo "iptables is open make $line is block " >> blockip.log
fi
done
sleep 3
done
监控工具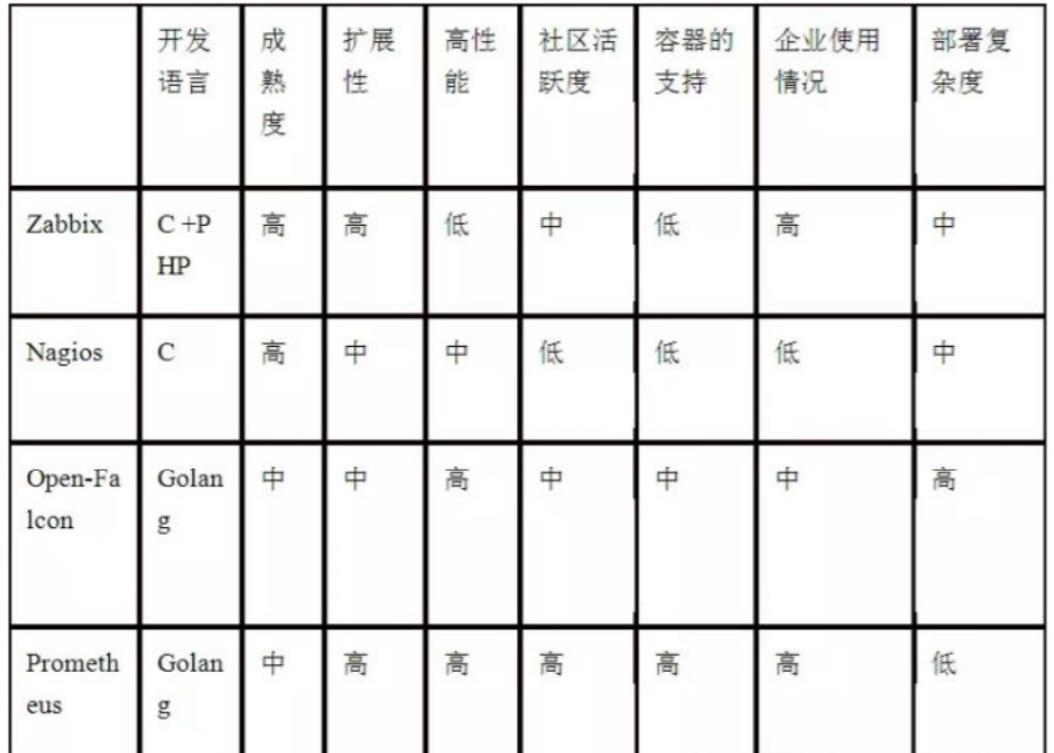
监控流程
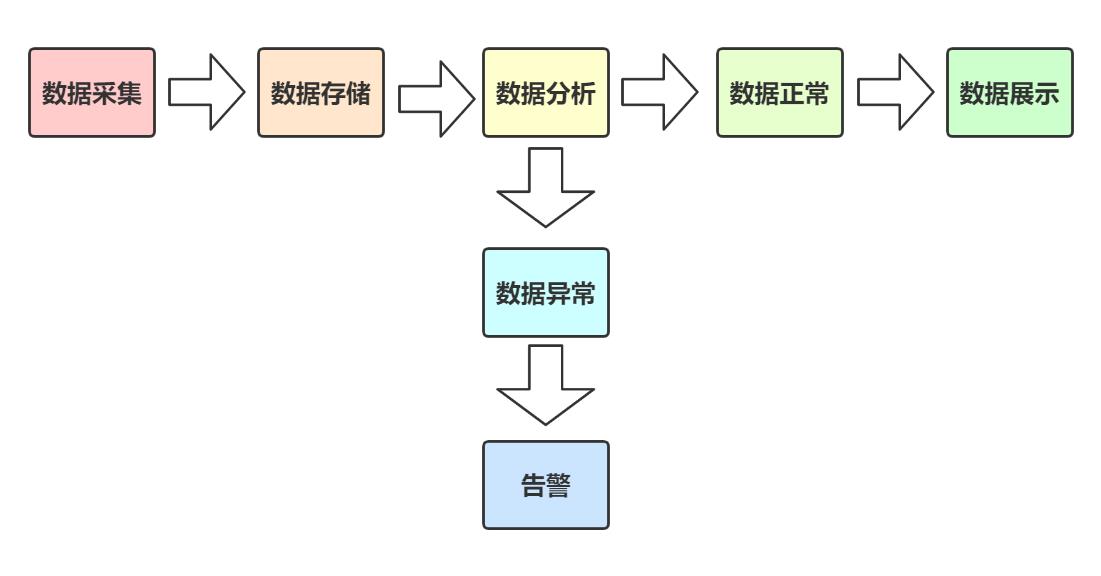
监控指标
| 监控项目 | 监控内容 |
|---|---|
| 主机 | 内存,磁盘(使用空间/剩余空间), |
| 网卡 | ping的响应时间,数据包的收发成功率,网卡的流入流出量和错误的数据包数量 |
| io_wait | 反映cpu是否空转 |
| code | 查看URL访问过程中的返回码,由此了解服务器在特定时间的状态 |
| uv | 反映服务的热度 |
| pv | 反映服务的用户满意度 |
| qps | 每秒查询率(Query Per Second) ,每秒的响应请求数,也即是最大吞吐能力。 |
| 应用程序 | 服务状态,端口和内存使用率,cpu使用率,请求数量,并发访问请求 |
| 数据库 | 指定数据库中的表空间,数据库的游标数,会话数,事务数 |
| 日志 | 错误日志,特定字符串匹配 |
| 磁盘使用量 | 根据磁盘使用量,了解磁盘使用情况 |
拓展内容:
QPS:
每秒查询率(Query Per Second) ,每秒的响应请求数,也即是最大吞吐能力。
QPS = req/sec = 请求数/秒
QPS统计方式 [一般使用 http_load 进行统计]
QPS = 总请求数 / ( 进程总数 * 请求时间 )
QPS: 单个进程每秒请求服务器的成功次数
峰值QPS:
原理:每天80%的访问集中在20%的时间里,这20%时间叫做峰值时间
公式:( 总PV数 * 80% ) / ( 每天秒数 * 20% ) = 峰值时间每秒请求数(QPS)
PV:
访问量即Page View, 即页面浏览量或点击量,用户每次刷新即被计算一次
单台服务器每天PV计算
公式1:每天总PV = QPS * 3600 * 6
公式2:每天总PV = QPS * 3600 * 8
UV:
独立访客即Unique Visitor,访问您网站的一台电脑客户端为一个访客。00:00-24:00内相同的客户端只被计算一次
服务器数量:
机器:峰值时间每秒QPS / 单台机器的QPS = 需要的机器
机器:clie( 每天总PV / 单台服务器每天总PV )
并发数:
并发用户数是指系统可以同时承载的正常使用系统功能的用户的数量
吐吞量:
吞吐量是指系统在单位时间内处理请求的数量
响应时间(RT):
响应时间是指系统对请求作出响应的时间
例子:
每天500w PV 的在单台机器上,这台机器需要多少QPS?
答:( 5000000 * 0.8 ) / (86400 * 0.2 ) = 231 (QPS)
如果一台机器的QPS是90,需要几台机器来支持?
答:231 / 90 = 3
以上是关于Linux监控详解的主要内容,如果未能解决你的问题,请参考以下文章