数据结构与算法之深入解析二叉树的基本算法和递归套路深度实践
Posted Forever_wj
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据结构与算法之深入解析二叉树的基本算法和递归套路深度实践相关的知识,希望对你有一定的参考价值。
一、二叉树的遍历
- 二叉树节点定义:
Class Node {
// 节点的值类型
V value;
// 二叉树的左孩子指针
Node left;
// 二叉树的右孩子指针
Node right;
}
- 递归实现先序、中序、后序遍历:
-
- 先序:任何子树的处理顺序都是,先头结点,再左子树,再右子树,先处理头结点;
-
- 中序:任何子树的处理顺序都是,先左子树,再头结点,再右子树,中间处理头结点;
-
- 后序:任何子树的处理顺序都是,先左子树,再右子树,再头结点,最后处理头结点。
- 对于下面的一棵树:
-
- 先序遍历为:1 2 4 5 3 6 7;
-
- 中序遍历为:4 2 5 1 6 3 7;
-
- 后序遍历为:4 5 2 6 7 3 1。
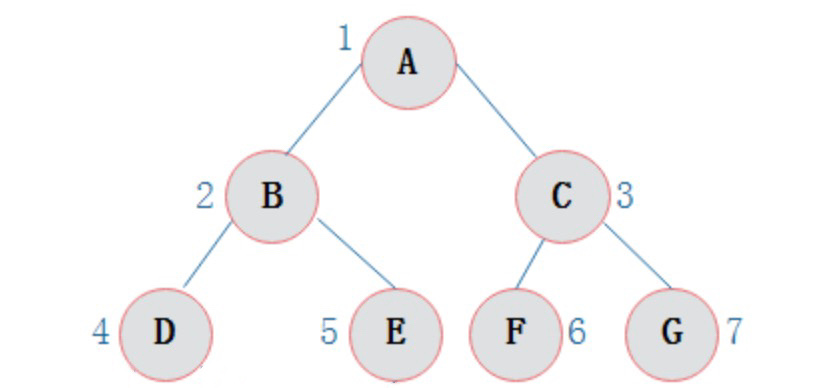
- Java 的算法实现示例如下:
package class07;
public class Code01_RecursiveTraversalBT {
public static class Node {
public int value;
public Node left;
public Node right;
public Node(int v) {
value = v;
}
}
public static void f(Node head) {
if (head == null) {
return;
}
// 1 此处打印等于先序
f(head.left);
// 2 此处打印等于中序
f(head.right);
// 3 此处打印等于后序
}
// 先序打印所有节点
public static void pre(Node head) {
if (head == null) {
return;
}
// 打印头
System.out.println(head.value);
// 递归打印左子树
pre(head.left);
// 递归打印右子树
pre(head.right);
}
// 中序遍历
public static void in(Node head) {
if (head == null) {
return;
}
in(head.left);
System.out.println(head.value);
in(head.right);
}
// 后序遍历
public static void pos(Node head) {
if (head == null) {
return;
}
pos(head.left);
pos(head.right);
System.out.println(head.value);
}
public static void main(String[] args) {
Node head = new Node(1);
head.left = new Node(2);
head.right = new Node(3);
head.left.left = new Node(4);
head.left.right = new Node(5);
head.right.left = new Node(6);
head.right.right = new Node(7);
pre(head);
System.out.println("========");
in(head);
System.out.println("========");
pos(head);
System.out.println("========");
}
}
- 对于树的递归,每个节点实质上会到达三次,例如上文的树结构,对于 f 函数,传入头结点,再调用左树再调用右树,实质上经过的路径为1 2 4 4 4 2 5 5 5 2 1 3 6 6 6 3 7 7 7 3 1。在每个节点三次返回的基础上,第一次到达该节点就打印,就是先序,第二次到达该节点打印就是中序,第三次到达该节点就是后序。因此先序中序后序,只是递归顺序加工出来的结果。
- 非递归实现先序中序后序遍历(DFS):由于任何递归可以改为非递归,可以使用压栈来实现,实质就是深度优先遍历(DFS),用先序实现的步骤,其它类似:
-
- 步骤一,把节点压入栈中,弹出就打印;
-
- 步骤二,如果有右孩子先压入右孩子;
-
- 步骤三,如果有左孩子压入左孩子。
package class07;
import java.util.Stack;
public class Code02_UnRecursiveTraversalBT {
public static class Node {
public int value;
public Node left;
public Node right;
public Node(int v) {
value = v;
}
}
// 非递归先序
public static void pre(Node head) {
System.out.print("pre-order: ");
if (head != null) {
Stack<Node> stack = new Stack<Node>();
stack.add(head);
while (!stack.isEmpty()) {
// 弹出就打印
head = stack.pop();
System.out.print(head.value + " ");
// 右孩子不为空,压右
if (head.right != null) {
stack.push(head.right);
}
// 左孩子不为空,压左
if (head.left != null) {
stack.push(head.left);
}
}
}
System.out.println();
}
// 非递归中序
public static void in(Node head) {
System.out.print("in-order: ");
if (head != null) {
Stack<Node> stack = new Stack<Node>();
while (!stack.isEmpty() || head != null) {
// 整条左边界依次入栈
if (head != null) {
stack.push(head);
head = head.left;
// 左边界到头弹出一个打印,来到该节点右节点,再把该节点的左树以此进栈
} else {
head = stack.pop();
System.out.print(head.value + " ");
head = head.right;
}
}
}
System.out.println();
}
// 非递归后序
public static void pos1(Node head) {
System.out.print("pos-order: ");
if (head != null) {
Stack<Node> s1 = new Stack<Node>();
// 辅助栈
Stack<Node> s2 = new Stack<Node>();
s1.push(head);
while (!s1.isEmpty()) {
head = s1.pop();
s2.push(head);
if (head.left != null) {
s1.push(head.left);
}
if (head.right != null) {
s1.push(head.right);
}
}
while (!s2.isEmpty()) {
System.out.print(s2.pop().value + " ");
}
}
System.out.println();
}
// 非递归后序2:用一个栈实现后序遍历,比较有技巧
public static void pos2(Node h) {
System.out.print("pos-order: ");
if (h != null) {
Stack<Node> stack = new Stack<Node>();
stack.push(h);
Node c = null;
while (!stack.isEmpty()) {
c = stack.peek();
if (c.left != null && h != c.left && h != c.right) {
stack.push(c.left);
} else if (c.right != null && h != c.right) {
stack.push(c.right);
} else {
System.out.print(stack.pop().value + " ");
h = c;
}
}
}
System.out.println();
}
public static void main(String[] args) {
Node head = new Node(1);
head.left = new Node(2);
head.right = new Node(3);
head.left.left = new Node(4);
head.left.right = new Node(5);
head.right.left = new Node(6);
head.right.right = new Node(7);
pre(head);
System.out.println("========");
in(head);
System.out.println("========");
pos1(head);
System.out.println("========");
pos2(head);
System.out.println("========");
}
}
- 二叉树按层遍历(BFS):其实就是宽度优先遍历(BFS)用队列,可以通过设置flag 变量的方式,来发现某一层的结束;
-
- 按层打印输出二叉树:
package class07;
import java.util.LinkedList;
import java.util.Queue;
public class Code03_LevelTraversalBT {
public static class Node {
public int value;
public Node left;
public Node right;
public Node(int v) {
value = v;
}
}
public static void level(Node head) {
if (head == null) {
return;
}
// 准备一个辅助队列
Queue<Node> queue = new LinkedList<>();
// 加入头结点
queue.add(head);
// 队列不为空出队打印,把当前节点的左右孩子加入队列
while (!queue.isEmpty()) {
Node cur = queue.poll();
System.out.println(cur.value);
if (cur.left != null) {
queue.add(cur.left);
}
if (cur.right != null) {
queue.add(cur.right);
}
}
}
public static void main(String[] args) {
Node head = new Node(1);
head.left = new Node(2);
head.right = new Node(3);
head.left.left = new Node(4);
head.left.right = new Node(5);
head.right.left = new Node(6);
head.right.right = new Node(7);
level(head);
System.out.println("========");
}
}
-
- 找到二叉树的最大宽度:
package class07;
import java.util.HashMap;
import java.util.LinkedList;
import java.util.Queue;
public class Code06_TreeMaxWidth {
public static class Node {
public int value;
public Node left;
public Node right;
public Node(int data) {
this.value = data;
}
}
// 方法1使用map
public static int maxWidthUseMap(Node head) {
if (head == null) {
return 0;
}
Queue<Node> queue = new LinkedList<>();
queue.add(head);
// key(节点) 在 哪一层,value
HashMap<Node, Integer> levelMap = new HashMap<>();
// head在第一层
levelMap.put(head, 1);
// 当前你正在统计哪一层的宽度
int curLevel = 1;
// 当前层curLevel层,宽度目前是多少
int curLevelNodes = 0;
// 用来保存所有层的最大值,也就是最大宽度
int max = 0;
while (!queue.isEmpty()) {
Node cur = queue.poll();
int curNodeLevel = levelMap.get(cur);
// 当前节点的左孩子不为空,队列加入左孩子,层数在之前层上加1
if (cur.left != null) {
levelMap.put(cur.left, curNodeLevel + 1);
queue.add(cur.left);
}
// 当前节点的右孩子不为空,队列加入右孩子,层数也变为当前节点的层数加1
if (cur.right != null) {
levelMap.put(cur.right, curNodeLevel + 1);
queue.add(cur.right);
}
// 当前层等于正在统计的层数,不结算
if (curNodeLevel == curLevel) {
curLevelNodes++;
} else {
// 新的一层,需要结算
// 得到目前为止的最大宽度
max = Math.max(max, curLevelNodes);
curLevel++;
// 结算后,当前层节点数设置为1
curLevelNodes = 1;
}
}
// 由于最后一层,没有新的一层去结算,所以这里单独结算最后一层
max = Math.max(max, curLevelNodes);
return max;
}
// 方法2不使用map
public static int maxWidthNoMap(Node head) {
if (head == null) {
return 0;