YOLO系列的又一集大成者:YOLOX!
Posted Charmve
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了YOLO系列的又一集大成者:YOLOX!相关的知识,希望对你有一定的参考价值。
最新的YOLO系列工作:YOLOX开源啦!
强如旷视,又为Detection领域带来了新工具!


- 论文链接:https://arxiv.org/abs/2107.08430
- 代码链接:https://github.com/Megvii-BaseDetection/YOLOX
就不多说形而上的废话了,我们直接来看看这个YOLOX都有哪些干货吧。
1.Baseline:YOLOv3
通常在做研究的时候,我们都会选择一个还不错的Baseline,常用的是RetinaNet和Faster RCNN。既然YOLOX针对的是YOLO系列,自然也就选了YOLO。本文以YOLOv3作为后续工作的baseline——为什么不选v4呢?个人觉得是因为v4堆的trick太多,不太适合做baseline。
笔者认为,在选baseline的时候,应该具备至少两点:性能还不错,用的trick还少。像常用的RetinaNet,基本就是随手造的一个普通模型,纯为focal loss服务的,几乎没加太多trick,这样的工作就很适合用来验证我们自己改进出来的东西是否好用。
有的时候trick用得太多,自己的东西加上去不但不涨点,还掉点。但要注意,这个时候不一定是你的东西有问题,很可能是和哪一个trick冲突了。
在YOLOX中,便选了YOLOv3。关于YOLOv3,笔者就不做过多讲解了。
2.实验部署参数
选好了baseline后,接下来就要设计实验了。注意,YOLOX工作是偏向工程的,放出来的arxiv更像是一篇tech report,而不是research paper,所以,这里也就没有“乱花渐欲迷人眼”的东西,更没有障眼法了。
训练配置很朴素:
-
300epoch的训练长度,其中,前5个epoch使用warmup学习率策略;
-
优化器使用标配的SGD;
-
学习率:
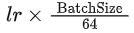
,其中初始学习率lr=0.01。使用余弦学习率策略; -
batch size为128,使用8块GPU……啊这……看了下自己的设备,有点劝退……当然,作者也说了,单卡GPU和64batch size也是可以work,就是训练得挺久~
-
多尺度训练:448-832,不再是以往的320-608了。这应该是追求large input size的涨点。
-
Backbone就是v3所使用的DarkNet-53。
-
预测部分加入了IoU-aware分支,这一点应该是和PP-YOLO是对齐的
-
损失函数:obj分支和cls分支还是使用BCE,reg分支则使用IoU loss;
-
使用EMA训练技巧(这个很好用,可以加快模型的收敛速度);
-
数据增强仅使用RandomHorizontalFlip、ColorJitter以及多尺度训练,不使用RandomResizedCrop,作者认为RandomResizedCrop和Mosaic有点重合了。由于后续会上Mosaic Augmentation,所以这里暂时先不要了。
通过上述的训练配置,YOLOX的baseline:YOLOv3在COCO val上的性能达到了38.5AP。
在这个strong baseline的基础上,YOLOX就要开始它的show time了~

3.Decoupled Head
第一个改进就是YOLOv3的head部分。一直以来,YOLO工作都是仅使用一个branch就同时完成obj、cls以及reg三部分的预测。而我们所熟知的RetinaNet则是使用两个并行分支去分别做cls和reg的预测。YOLOX作者认为仅使用一个分支是不合适的,于是,就把原先的Coupled head改成类似于RetinaNet的那种Decoupled head,如下图所示。

完成这个改进后,baseline的性能再一次提升,不过速度略微下降,但完全在可接受的范围内。
图 Decoupled head涨点

图 原先的Coupled head和改进的Decoupled head的对比
后续的YOLOX会改成end-to-end的形式,也就是不适用NMS操作,作者发现原先的Coupled head会掉点严重,而采用RetinaNet的那种Decoupled head就会缓解很多,同时,性能还略有提升。
其实,这一点是很好理解的,毕竟cls的学习显然和reg不一样,仅使用一个branch来完成两个类型完全不同的目标,确实有点难度。
另外,注意上图的下半部分,我们会发现没有了anchor,也就是anchor box被去掉了,变成了anchor box free工作,这是后话,我们暂且不提。
4.数据增强:Mosaic和Mix-up
YOLOX继续给baseline增加了Mosaic和Mix-up两个数据增强手段。在训练的最后15个epoch,这两个数据增强会被关闭掉,而在这之前,Mosaic和Mix-up是都开着的,这个细节需要注意一下,笔者的经验是,如果我们从头到尾都开这两个数据增强,性能反而提升不大。
加入了这两个strong data augmentation后,baseline的性能直接涨到了42.0AP:
图 Mosaic和Mix-up涨点
由于加入了这么强的两个数据增强后,YOLOX从这里开始就不再需要pre-trained mode了,而是直接train from scratch。
5.Anchor-free
有关于anchor box的种种缺点,相信大家都很清楚了,在先前讲解FCOS的文章里也详说了这一点,就不再赘述了。于是,YOLOX作者便去掉了anchor box,和FCOS一样,每个grid都只预测一个目标。
去掉了anchor box,也就是去掉了size的先验,故而FPN肯定会出现问题:如何做尺度分配?对于这一问题,YOLOX直接使用FCOS的路子,预先设定一个尺寸范围,根绝每个gt的size来判断应该分配到哪个尺度上去。这个预先设定的size范围,论文里没有给出,就需要我们自己去看源码了,但这个不是实质问题,不影响后续的阅读。
对于一个给定的gt边界框,首先根据它的size确定所匹配的尺度,然后就和YOLOv3一样了,计算它在这个尺度上的中心点位置,计算中心点偏差 ,至于宽高 ,就直接作为回归目标(注意,这里要把宽高做归一化,这是基操。)。
还是很简单的,没有复杂的细节。
完成了anchor-free化的操作后,性能略微提升:
图 anchor-free化涨点
可见,对于YOLO来说,anchor box不是必要的,去掉anchor box性能依旧很好,而且由于预测层的参数少了,推理速度上来了。
其实,将YOLOv3改成anchor-free的工作,笔者也做过类似的,但没刷高这么高,实属遗憾。
多说一句,anchor-free再怎么anchor-free,它的本质还是anchor-based,只不过,一个anchor处没再放k个anchor box。真正的anchor free,在笔者看来,应该是完全不要spatial维度,或者说,完全不需要再spatial维度上去做遍历(俗称查网格)找目标。所以,相较于anchor-free,笔者更喜欢用更加提切的、误导性更小的anchor box free。
6.Multi positives
在完成了anchor-free化的改进后,我们会发现一个问题,那就是一个gt框只有一个正样本,也就是one-to-one,这个问题所带来的最大阻碍就是训练时间会很长,同时收敛速度很慢。为了缓解这一问题,YOLOX作者便自然想到可以增加正样本的数量,使用one-to-many策略。
很简单,之前只考虑中心点所在的网格,这会改成以中心点所在的网格的3x3邻域,都作为正样本,直观上来看,正样本数量增加至9倍。每个grid都去学到目标中心点的偏移量和宽高,此时,显然这个中心点偏移量不再是01了,这一点细节的变化需要留意一下。
加入更多的positives后,性能提升显著:
Multi positives涨点
7.OTA
最后,YOLOX作者算是给自家的最新工作OTA:《OTA: Optimal Transport Assignment for Object Detection》做了个宣传。该工作笔者没有关注太多,简而言之是基于Optimal Transport问题提出了一个新的label assign方法,来提升FCOS这种基于point的anchor-free工作的性能。
并且,使用了OTA策略后,就完全不需要类似于FCOS那种基于size的尺度分配策略,这一点大大减少了数据预处理部分的人工先验,还是挺舒服的~
将OTA加入到YOLOX中,涨点也是很明显的:
OTA涨点
那么,YOLOX的主体内容就说完了。
可见,这又是一次YOLO系列的“集大成”工作系列。后续YOLOX还和YOLOv5做了对比,简而言之,这个anchor-free版本的YOLO要略强于YOLOv5。
最重要的一点是,YOLOX开源代码的同时,也开源了各平台的模型部署,这对于工业界还是很友好的。就从这一点,YOLOX工作还是很值得夸赞的!当然,其本身性能也是非常高的。
笔者很喜欢这种干货十足的工作,没有太多理论上的弯弯路子绕得人头晕眼花,直来直去,告诉我们都做了什么、怎么做的、性能怎么样,就非常棒~
专栏链接 https://blog.csdn.net/charmve/category_10101246.html


- GitHub链接 https://github.com/Charmve/computer-vision-in-action
- 📘 在线电子书 https://charmve.github.io/computer-vision-in-action/
- 👇项目主页 https://charmve.github.io/l0cv-web
以上是关于YOLO系列的又一集大成者:YOLOX!的主要内容,如果未能解决你的问题,请参考以下文章
YOLOX: Exceeding YOLO Series in 2021 --- Study Notes
深入浅出Yolo系列之Yolov3&Yolov4&Yolov5&Yolox核心基础知识完整讲解
YOLO Air一款面向科研小白的YOLO项目|包含大量改进方式教程|适用YOLOv5,YOLOv7,YOLOX,YOLOv4,YOLOR,YOLOv3,transformer等算法