自然场景下的文字检测:从多方向迈向任意形状
Posted 等待破茧
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了自然场景下的文字检测:从多方向迈向任意形状相关的知识,希望对你有一定的参考价值。
转载自https://zhuanlan.zhihu.com/p/68058851

自然场景下的文字检测:从多方向迈向任意形状
xieenze.github.io
题外话
本次分享的主题是文字检测(Text Detection),分享者是旷视研究院检测组算法研究员谢恩泽。通过这篇文章,可以一窥旷视研究院近两年在该方向的工作与思考,并希望为计算机视觉社区带来启发,进一步推动文字检测技术的研究与落地。
文字检测是文字识别的第一站,旷视研究院的努力主要体现在紧紧围绕文字检测领域顽固而核心的问题展开,攻坚克难,功夫花在刀刃上,比如文字形状变化及 FP 问题等。
本文主要介绍自然场景下的文字检测的一些定义、挑战和旷视研究院检测组的相关工作,主要包括:1)SPCNet(AAAI 2019),2)PSENet(CVPR 2019) ,3)ICDAR 2019 ArT 检测冠军的经验分享。
导语
文字在人类生活中不可或缺,它代表着人类文明的发展,是人与人交流的载体。文字承载了丰富和准确的高级语义信息,人们可以通过文字传达思想和情感。
自然场景下的文字检测是计算机视觉和目标检测的基础研究之一,近年在深度卷积神经网络的推波助澜下飞速进展,其目的是给定一张图像,定位出其中的文字区域。
一般情况下文字检测分为单词和文本行两个级别,如下图所示:

文字检测是很多计算机视觉任务的前置步骤,比如文字识别,身份认证等,因此,文字的精准定位既十分重要又具备挑战。 相较于通用检测,文字具有多方向、不规则形状、极端长宽比、字体、颜色、背景多样等特点,因此,往往在通用物体检测上较为成功的算法无法直接迁移到文字检测中。
水平/多方向文字检测
深度学习时代,传统文字检测算法被刷新,水平文字和多方向文字检测技术获得大发展,经典算法有: 1)CTPN[1],2)EAST[2],3)TextBoxes[3],4)TextBoxes++[4],5) SegLink[5],6)RRPN[6] 等。
上述算法主要从通用物体检测中汲取灵感,比如 CTPN、RRPN 基于两步法检测器Faster R-CNN;TextBoxes 系列和 Seglink 基于一步法检测器 SSD;EAST 基于 Anchor Free 检测器 DenseBox 和 UnitBox。
下面简单介绍一下这几个算法的优势和局限性:
- CTPN: 通过 Faster R-CNN+LSTM 预测固定宽度的 text proposal,在后处理部分再将这些小文本段连接起来,得到文本行。只能检测水平文本。
- EAST: 继承 DenseBox 和 UnitBox, 通过预测 shrink 的文字区域,并对区域内的每个像素预测它到上下左右的四个距离和一个旋转角度,Pipeline 十分简单,同时速度较快。
- TextBoxes/TextBoxes++: TextBoxes 基于 SSD 修改卷积核尺寸,更适合文字检测,但是只能检测水平文字。TextBoxes++ 基于 TextBoxes, 将回归水平 box 改为回归上下左右 4 个点,可以检测倾斜文字。
- RRPN:基于 Faster R-CNN,通过引入 rotate anchor,实现多方向的文字检测,但是引入的 anchor 成倍增加,速度较慢,计算量也较大。
这些算法在水平和多方向文字检测数据集上不断刷出 SOTA 成绩,但是无法很好地建模弯曲文字。
弯曲文字检测
在自然场景中,弯曲文字也同样很常见,比如最经典的星巴克 LOGO,如下图所示。 如何科学地建模弯曲文字是一个很有挑战的问题。

弯曲文字检测的发展史要从两个重要的数据集说起:1)Total-Text[9] 和 2)CTW-1500[10]。2017年提出两个数据集之后,大量学术界和工业界关于弯曲文字的研究纷至沓来。旷视研究院是最早针对弯曲文字检测展开研究并提出自身见解的机构之一。
弯曲文字检测的两种方法
经过一年多的发展,弯曲文字检测技术形成两条主线: 1)Top-Down 和 2)Bottom-Up方法。
Top-Down方法
将弯曲文字检测转化为实例分割问题,如下图所示,通过检测水平 box 和分割 box 内的实例,可以很好地解决弯曲文字检测问题。现有 Top-Down 方法大多基于 Mask R-CNN,比如 SPCNet[7],PMTD[11]。

Bottom-Up方法
将弯曲文字检测转化为语义分割问题,通过像素级的分类去判断文字区域。但是由于很多情况下文本行相邻较近,现有 Bottom-Up方法往往通过预测中心线定位文字实例,并通过不同方法建模完整的文字区域,比如 PSENet[8],TextSnake[12]。
弯曲文字检测存在的问题
False Positives

由于自然场景中不少 False Positives(FP)和文字具有相似的纹理,比如圆盘、栅栏,从而很容易被误检为文字。旷视研究院检测组在 AAAI2019 提出 SPCNet[7],将语义分割信息引入 Mask R-CNN,并对文字实例重新打分,从而抑制 FP 的检测。
Pipeline过于复杂,无法达到实时性
基于 Top-Down 方法的弯曲文字检测虽能达到 SOTA 性能,但流程过于复杂,超参数太多,还无法实时运行。
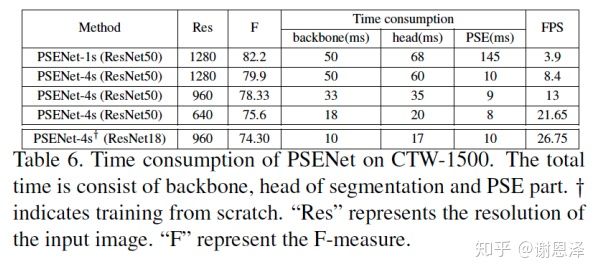
面对这一问题,旷视研究院检测组和南京大学合作,在 CVPR 2019 提出 PSENet[8],通过一个简单的语义分割框架分割出多尺度的文字,并通过渐进式扩展算法合并得到最终结果,在CTW1500 数据集取得 26FPS 的运行速度。
总而言之,目前弯曲文字检测技术主要分为自上向下(Top-Down)和自下向上(Bottom-Up)两条路。
方法
旷视研究院检测组是最早发表弯曲文字检测研究的机构之一,并在 Top-Down 和 Bottom-Up 两个方向分别贡献了一篇论文,分别针对 FP 和实时性两个问题。
接下来介绍的两篇文章都是针对任意形状文字检测而建模的,不仅在传统的水平文字/多方向文字检测任务中效果很好,更是可以灵活地检测弯曲和不规则的文本。
Top-Down方法:SPCNet

本文以 Mask R-CNN 为 Baseline, 并在 Mask R-CNN 的基础上引入 Text Context 模块和 Re-Score 机制,从而提高检测准确率,降低 FP 的出现。
为什么要用 Mask R-CNN?首先,弯曲文字检测可以转化为一个实例分割问题,而 Mask R-CNN 是当前最优的实例分割框架,大多数 COCO Instance Segmentation 冠军队伍都采用Mask R-CNN 作为 Baseline。
本文同样采用 Mask R-CNN 取得了很高的 Baseline,通过水平 box 定位出文字区域,通过分割文字实例得到精准的轮廓。
整个网络流程如下图所示,(a) 是 FPN 结构,(b) 是 text context(TCM)模块,(c) 是Mask R-CNN 的分支,(d) 是 TCM 具体的方法。
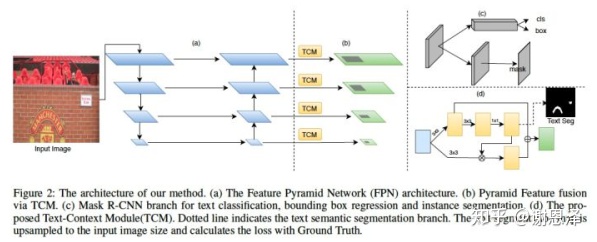
整个方法在 Mask R-CNN 基础上多一个分支做文字语义分割,并把语义分割的中间特征和检测分支的特征融合起来,再把语义分割的预测结果作为一个 attention mask 乘回 feature map,起到一个对特征 attention 的作用。
下图是重打分的一个可视化说明,绿色的是水平 box,红色的是 instance seg 结果,下面的是全局语义分割结果,旷视研究院把 instance seg 结果投影到语义分割图上,并在该区域内算一个响应值,得到 instance score,并和原来的 classification score 融合得到最终的 score。
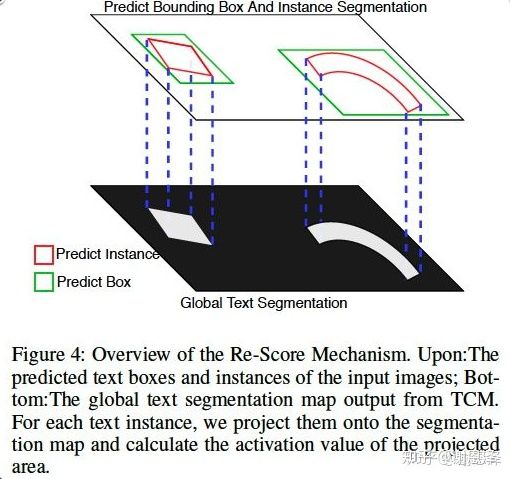
为什么要引入Rescore?下图是 re-score 模块的可视化图。由图可知,Mask R-CNN 将水平box 的分类分数最终的 score,对于倾斜文本不是很友好,并且可能会引入 FP,我们在这里将语义分割图上的响应和原本的 score 融合起来,得到的 fus-score 可以缓解 Mask R-CNN 直接移植到文字检测上分类分数不准的问题。

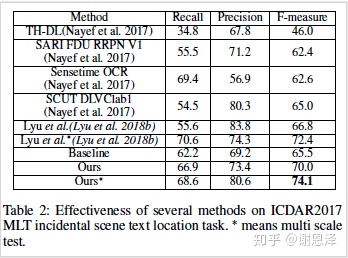
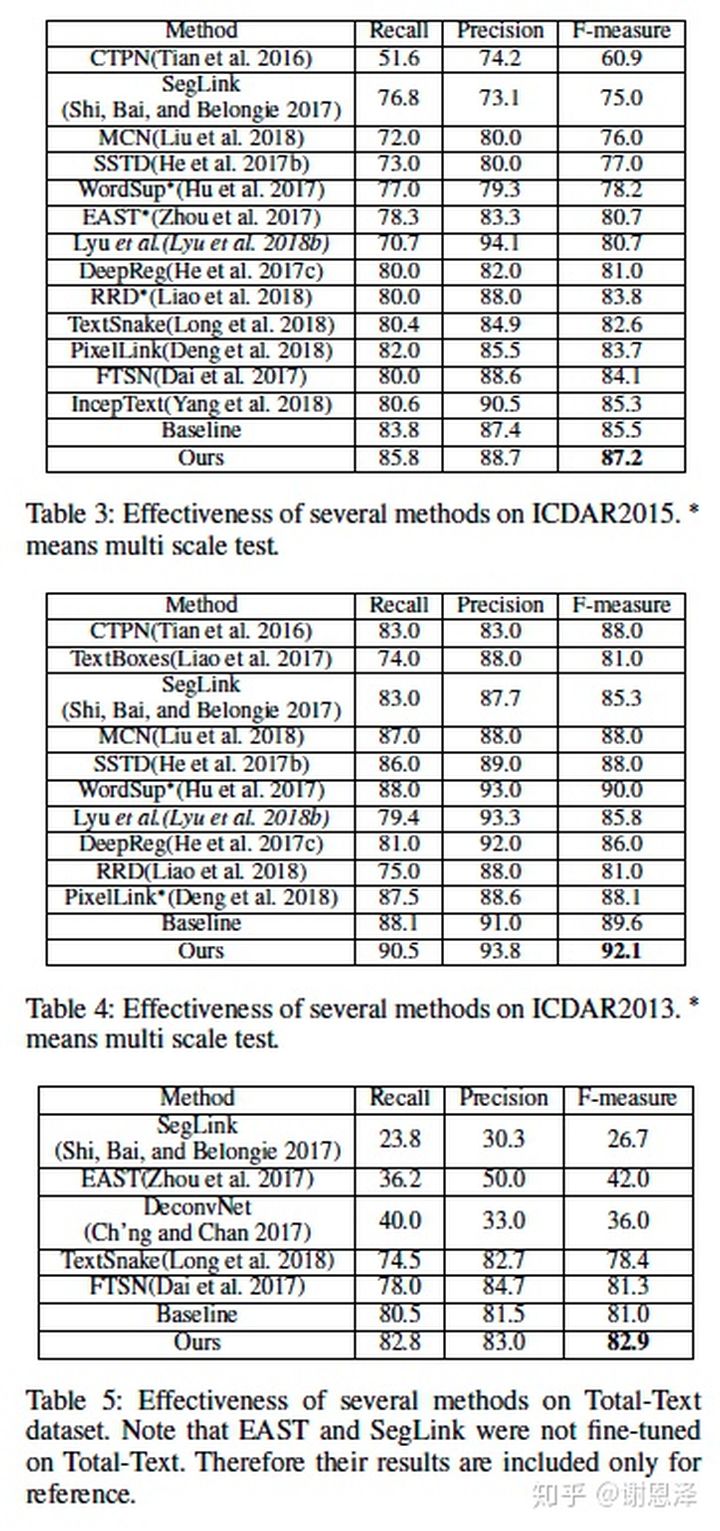
最终,SPCNet 在几个标准数据集 ICDAR2013、ICDAR2015、ICDAR2017 和 Total-Text 上都取得了 state-of-the-art 结果。
一些可视化效果图如下。

在 ICDAR2015 上对比一些经典方法(EAST、RRPN、TextBoxes++)的 FP 情况,可以看到我们的方法可以有效抑制 FP。

Bottom-Up方法:PSENet
- 论文链接:Shape Robust Text Detection with Progressive Scale Expansion Network
- 其他论文解读:whai362:大白话《Shape Robust Text Detection with Progressive Scale Expansion Network》

本文由旷视检测组和南京大学合作,从另一种思路去解决弯曲文字检测的问题,即像素级语义分割。考虑到基于 bounding box的方法无法很好地建模弯曲文字,语义分割方法对文字进行像素级分类,可以很容易建模弯曲文字,但是对于挨得很近的文本实例则无法区分,如下图所示。

直接用语义分割来检测文字又会遇到新问题:很难分离靠的很近的文字块。因为语义分割只关心每个像素的分类问题,所以即使文字块的一些边缘像素分类错误对 loss 的影响也不大。
对于这个问题,一个直接的思路是:增大文字块之间的距离,使其离得远一点。基于这个思路,旷视研究院引入了新的概念 “kernel”,顾名思义就是文字块的核心。
从下图可知:利用“kernel”可以有效地分离靠的很近的文字块。

首先看一下网络结构:
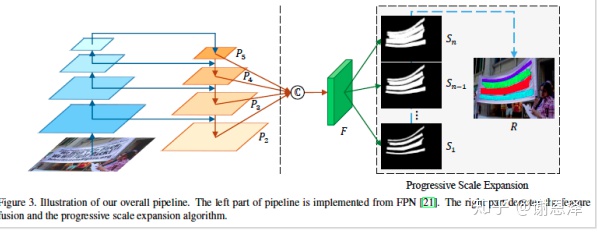
网络采用 FPN 结构,输入一张图片,网络会预测出带有不同尺度的 kernels 的分割结果,并通过渐进式扩展算法去重建文字区域。
本文通过引入渐进式扩展算法(PSE),可以高效地基于多个尺度的 kernels 重建出文字区域。具体流程如下:
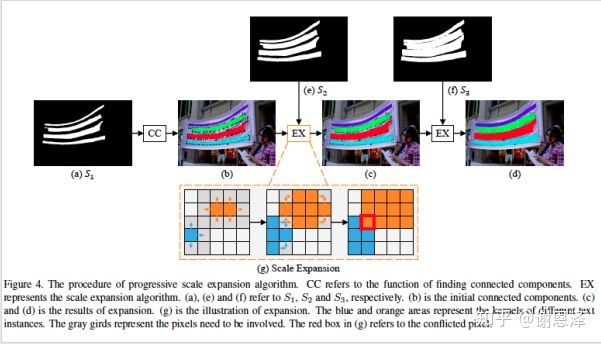
该算法主要是对于每个 kernel,向其周围上下左右四个方向扩展像素,直到到达最大的 kernel 的分割边界或者两个 kernel 在扩展时冲突。 因此该算法可以区分挨得很近的文字实例。
PSENet 在两个弯曲文字检测数据集上都取得了 SOTA 结果,并在多方向数据集上也取得了令人满意的结果。

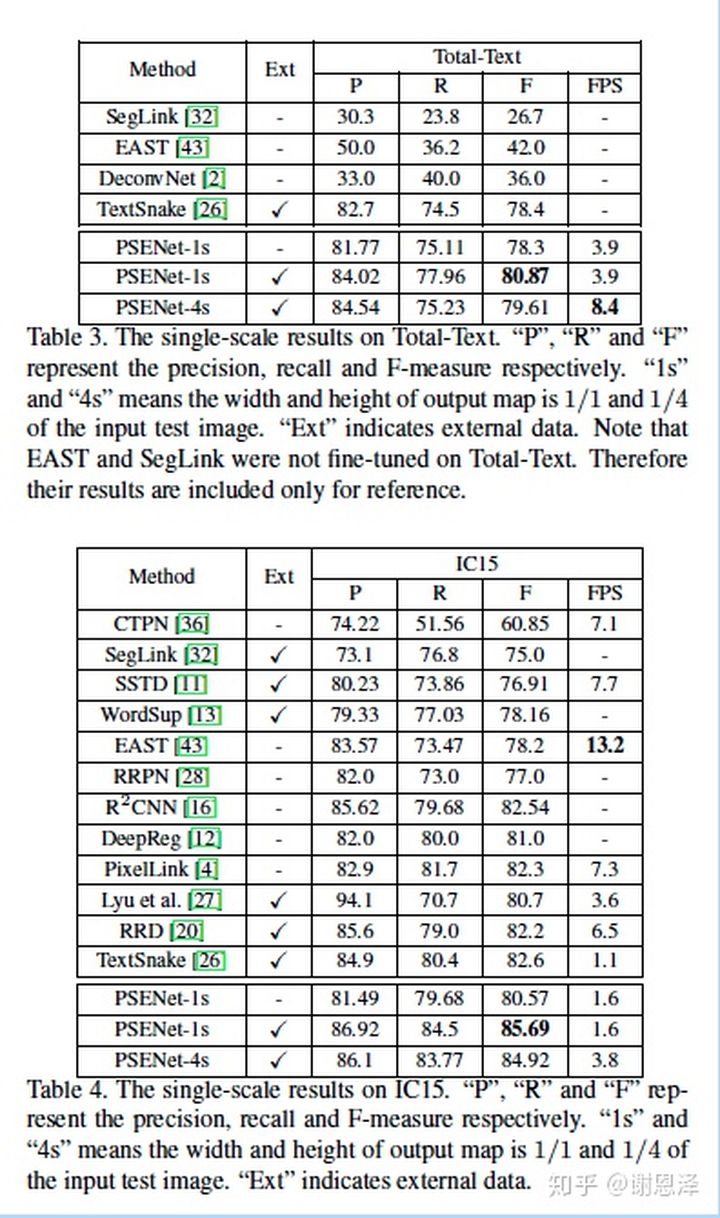
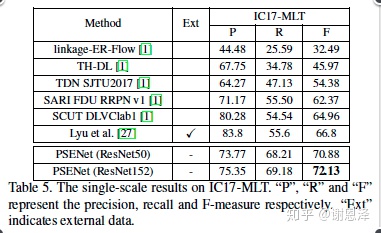
一些可视化效果图如下。

最重要的是,在压缩 backbone 和图片分辨率的情况下,PSENet 可以做到实时性检测,而检测结果同样具有竞争力,这是第一个在弯曲文字数据集上实现 >20FPS 的算法。
ICDAR 2019 Arbitrary-Shaped Text Detection 经验分享
ICDAR “Robust Reading Competitions” 竞赛是评估自然场景/网络图片/复杂视频文本提取与智能识别新技术进展的权威国际赛事及评测标准,竞赛中涌现出诸多方法持续推动业界新技术的创新与应用。参与者不乏国内外顶尖 CV 公司团队和知名高校实验室团队。
旷视检测组的几名实习生参加了本次比赛,这个部分主要分享一些旷视检测组在 ICDAR2019 ArT 比赛中获得冠军的一些经验。
比赛获奖链接如下:https://rrc.cvc.uab.es/files/ICDAR2019-ArT1.pdf
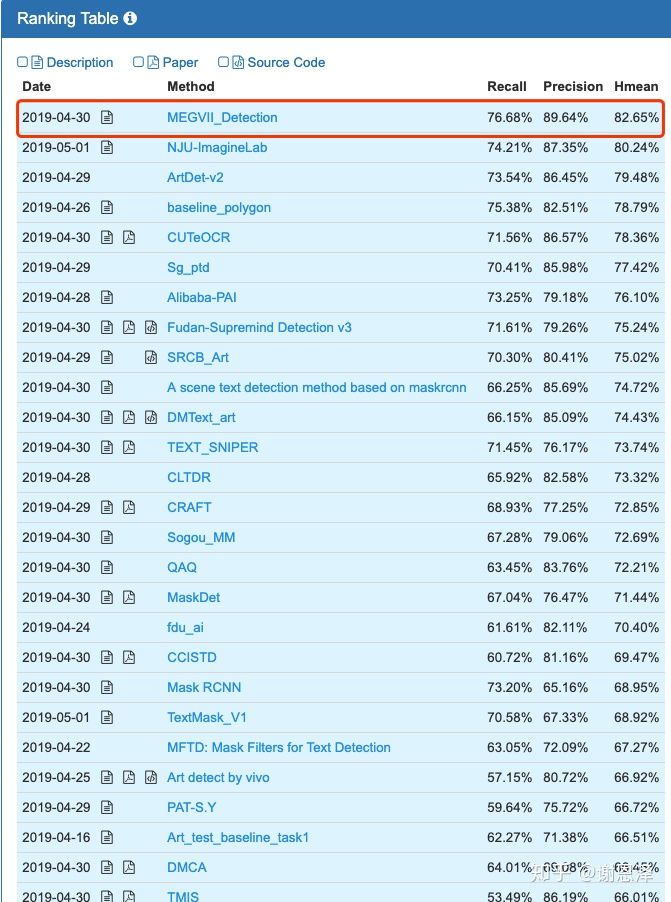
首先放出比赛结果:
简单介绍一下任意形状文本检测的任务:传统的物体检测的方法使用的是四点框或者是矩形框,但是因为文字本身的形状具有多变性,后续的一些弯曲文字的数据集比如 Total Text 和 CTW 都是采用多个点的标注形式,而这次 ArT 比赛使用的数据是目前为止最大的弯曲文字数据集,一共有 10166 张图像(5603 张训练图像和 4563 张测试图像)。
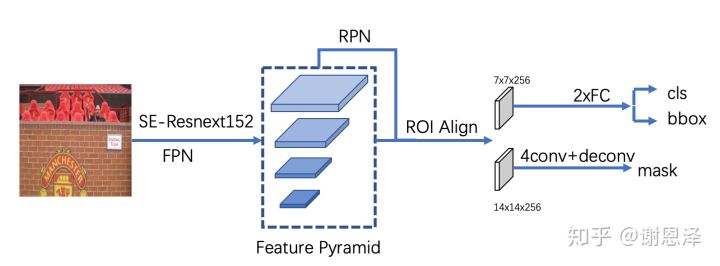
本文方法是 base 在 Mask R-CNN 之上,网络整体流程如下:
对于多点的标注,先求其最小外接的矩形作为 Mask R-CNN 的 gt box,而多点的标注就作为 gt mask,一个简单的可视化效果如下图所示:

上图中,黄色框是训练数据的 gt 的标注,而绿色的矩形是我们根据 gt 生成的 box。
当然,只有 Mask R-CNN 是不够的,实际中我们会遇到各种问题,比如说文字有一个很神奇的特性:文字框的某些部分还是文字,但是物体检测中的物体是没有这种局部性的。所以有时候会出现断框的情况,拿上图举例,可能你检测模型的结果是“天主”出了一个框,“堂”出了一个框,这样在评价指标下肯定是不如“天主堂”出一个框更好的。
虽然对于这类问题我们可以采取后处理方法去解决,但是后处理方法要么逻辑复杂很难写,要么效果不理想,解决的方法不是很本质,因此最好的方法是在网络层面解决这个问题。
再比如一些图像因为拍摄视角的原因可能会导致文字本身的检测变得非常困难,尝试采取 affine变换也不能很好地解决等等问题。
那么怎样解决上述的一些问题呢?
在这次比赛中,对于第二个问题我们借鉴了 SeNet 中 attention 的做法,这样使得我们的模型能更好地 focus 在需要关注的特征上,这种做法可以有效检测出一些因为视角问题导致的 bad case。
一个简单的例子如下图所示(绿色部分是我们模型检测结果,红色是 gt box 结果,图像来自我们自己切出来的 validation set,下同):

另外对于预测的 box 的情形,我们采用了增大模型感受野的方法,除了加深网络本身的层数之外,我们还在检测模型的中加入了 PSP 模块,这样做可以使得我们可以 cover 住一些极致长宽比的文字,可以有效杀掉模型中的 FP,使得模型在高 IoU 的结果下面更好。
效果如下图所示:

上图中的“爱酷儿”和“品牌折扣店”很容易检测成两个 box,但是采用我们的方法增大了模型的感受野之后就可以更好地解决这个问题,相比一些繁琐的后处理的方法也更加有效。
可以看到,我们在 IoU>0.5 和 IoU>0.7 两个指标下的分值上都是第一,而且在高 IoU 下的优势更加明显,这表明相比其他队伍的参赛模型,我们的模型预测的 box 也更加精准。
我们在最后的 Ensemble 中融合了Shufflenet v2 作为 Backbone 的模型,Shufflenet v2 也是旷视的工作。
当然,实际比赛中的问题远不止这些,篇幅原因我们拿上述两个问题简单分析一下。
感谢队友@王枫(计算所) @胡立(浙大)
(西交) @王文海(南大) 在比赛中做出的贡献,这是我们几个在旷视Detection组实习期间一起做的工作。
最后,欢迎来旷视研究院Detection组来实习,简历可以发送至旷视研究院检测组Leader俞刚:yugang@megvii.com。
作者简介
谢恩泽,同济大学计算机硕士,旷视研究院 Detection Team算法研究员,研究方向文字检测、识别等;文字检测算法 SPCNet 和 PSENet 作者;2019 年参加文字领域权威比赛ICDAR2019 挑战赛 Arbitrary-Shaped Text Detection 获得冠军。
参考文献
[1]Tian, Z.; Huang, W.; He, T.; He, P.; and Qiao, Y. 2016. Detecting text in natural image with connectionist text proposal network. In ECCV.
[2]Zhou, X.; Yao, C.; Wen, H.; Wang, Y.; Zhou, S.; He, W.; and Liang, J. 2017. East: an efficient and accurate scene text detector. In CVPR.
[3]Liao, M.; Shi, B.; Bai, X.; Wang, X.; and Liu, W. 2017. Textboxes: A fast text detector with a single deep neural network. In AAAI.
[4]Liao, M.; Shi, B.; and Bai, X. 2018. Textboxes++: A single- shot oriented scene text detector. IEEE Transactions on Im- age Processing.
[5]Shi, B.; Bai, X.; and Belongie, S. 2017. Detecting oriented text in natural images by linking segments. CVPR.
[6]Ma, J.; Shao, W.; Ye, H.; Wang, L.; Wang, H.; Zheng, Y.; and Xue, X. 2018. Arbitrary-oriented scene text detection via rotation proposals. IEEE Transactions on Multimedia.
[7]E.Xie,Y.Zang,S.Shao,G.Yu,C.Yao,andG.Li.Scenetext detection with supervised pyramid context network. arXiv preprint arXiv:1811.08605, 2018.
[8]Wang W, Xie E, Li X, et al. Shape Robust Text Detection with Progressive Scale Expansion Network[J]. arXiv preprint arXiv:1903.12473, 2019.
[9]C. K. Ch’ng and C. S. Chan. Total-text: A comprehensive dataset for scene text detection and recognition. In ICDAR, 2017.
[10]Y. Liu, L. Jin, S. Zhang, and S. Zhang. Detecting curve text 930 in the wild: New dataset and new solution. 2017.
[11]Jingchao Liu, Xuebo Liu, Jie Sheng, Ding Liang, Xin Li, Qingjie Liu. Pyramid Mask Text Detector[J] arXiv preprint arxiv:1903.11800
[12]Long S, Ruan J, Zhang W, et al. Textsnake: A flexible representation for detecting text of arbitrary shapes[C]//Proceedings of the European Conference on Computer Vision (ECCV). 2018: 20-36.
编辑于 2019-06-04
以上是关于自然场景下的文字检测:从多方向迈向任意形状的主要内容,如果未能解决你的问题,请参考以下文章