优Tech分享 自然场景下的不规则目标检测
Posted 等待破茧
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了优Tech分享 自然场景下的不规则目标检测相关的知识,希望对你有一定的参考价值。
目标检测技术作为计算机视觉的基础任务之一,在过去几十年取得了显著的进步,尤其近几年,随着深度学习的发展,基于深度神经网络的标准正框目标检测方法迅速取代了传统方法,成为智能安防、家居、出行等领域不可或缺的关键技术,比如人脸检测、人体检测、车辆检测、通用物体检测等。然而,还有一些场景的目标普遍带有任意旋转的多角度并且呈现密集排列,普通正框检测的方法无法满足需求,比如遥感目标检测、货架商品检测、自然场景下的文本检测、顶拍鱼眼镜头下的人体或物体检测。本文将这些场景的目标检测统称为不规则目标检测,之后从目标框定义、特征表达和损失函数设计这三个方面介绍不规则目标框检测算法的相关进展,并在最后介绍腾讯优图发表在CVPR2020的不规则目标检测论文。



五参数表示法主要用于对旋转框的表示。具体的定义方法是 ,其中(x, y)是中心点的坐标,(w, h)是目标框的宽和高, 旋转框的角度。根据不同的定义方法, 的取值范围也不同。OpenCV定义法的
取值范围为[-90, 0],长边定义法的取值范围是[-90, 90]。定义方法示意图如下图1所示。使用五参数表示法的相关的文章包括 [1, 2, 3, 4, 5, 6]。
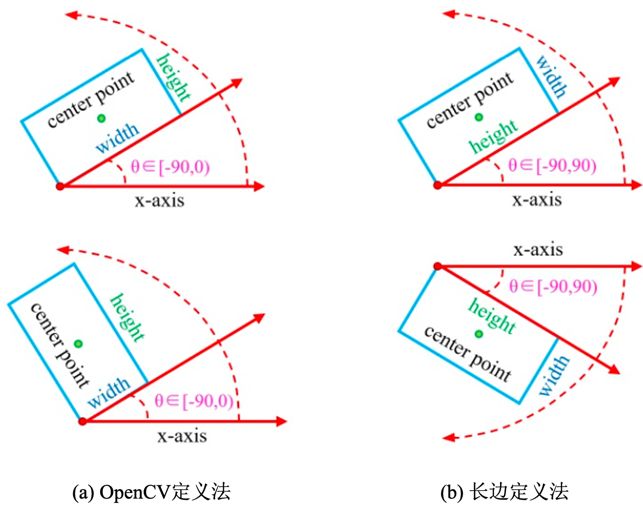
图1:五参数定义法
现在八参数表示法主要指有序四边形定义法和顶点偏移定义法。有序四边形定义法具体的定义方式是 ,以最左边的点为起始点,其他的点逆时针排列。相关的文章包括 [7, 8, 9] 。定义方式如下图2(a)所示。相比于直接预测4个顶点的值TPAMI2020的一篇论文“Gliding vertex on the horizontal bounding box for multi-oriented object detection” [10] 使用如图2(b)所示的方式来预测中心点位置、宽高、四个点相对于顶点的偏移占比,实际上该网络还会预测一个倾斜度因子来解决一些边界细节问题,具体可以参考论文了解。
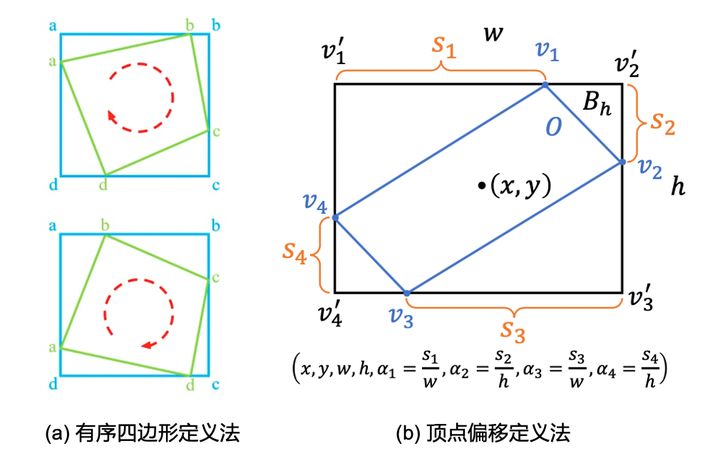
图2:八参数定义法

四极点+中心点表示法是由Xingyi Zhou等[12] 提出的对Anchor-free中水平框回归的改进。之所以说它可以表示不规则的目标框,是因为作者将获取的四极点进行后处理(具体的后处理方式参考[12])形成了8个坐标点,然后将8点进行相连就可以获取一个近似的边缘。其表示方法是中心点,加上该目标的上下左右四个极点的坐标,具体的形式为 。具体的表示方法如下图3所示。

图3:四极点+中心点表示法

Pairwise Points是[13]中提出来的针对任意形状文本检测的表示法。基于文本区域都具有近似对称的上边界和下边界的假设,提出了分别从上下边界提取成对的坐标点(Pairvise points)来表示文本区域的形状。具体的表示方法如下图4所示。这种方法对于任意形状的非文本目标可能不具有很好的适用性。

图4:Pairwise points表示法
当然,这样成对的坐标点对于不同的形状个数是不一致的。所以文中采取的处理办法就是利用LSTM来预测每一对坐标点。具体的网络框架如下图所示。
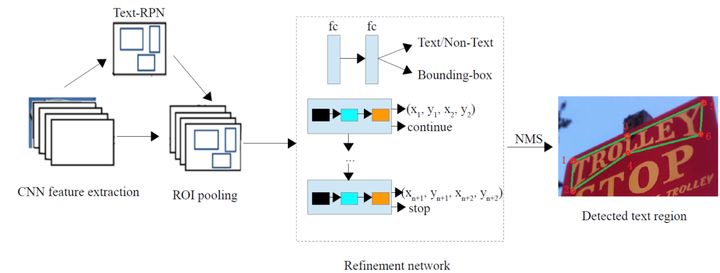
图5:网络架构图
Bezier-Curve表示法[14]也是针对任意形状文本检测提出来的表示方法。具体的表示方法是对文本区域的上下边界两个曲线进行Bezier-Curve近似。具体的表示如下图6所示。
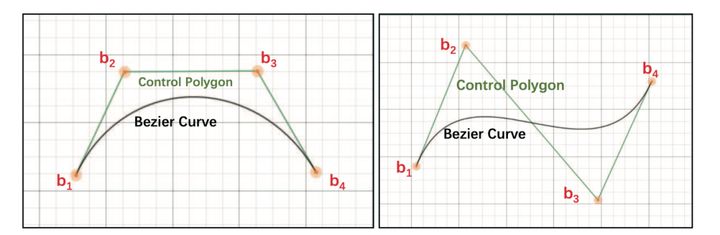
图6:Bezier曲线近似
如上图可以看出,通过4个点就可以近似文本上下边界的曲线形状,而且比较平滑。具体的公式表示形式如下。
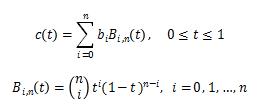
上式中,n代表的是control point的个数, 代表的是每个control point,t代表的是曲线的自变量。论文中提出,利用4个control points就可比较好的表征曲线,上下边界一共就构成了8个control points。

针对不规则目标框检测,现有加强特征表达的文章多集中于对旋转框的预测。对于multi-oriented的目标预测,针对特征方面的研究主要集中在三方面:
1)特征配准;
2)背景噪声抑制;
3)task-specific 特征提取

ROI Transformer[1]利用Rotated Position Sensitive ROI Align来更好的配准第二阶段的输入特征;[3]通过在RPN网络中设置旋转的Anchor来获取rotated proposals,然后通过RRoI pooling对特征进行resize,达到更好的特征配准; [4]属于refined 单阶段检测网络,通过FRM (Feature Refinement Module)来对特征进行配准,然后送入到refined阶段来实现更好的旋转框检测;具体的网络形式如下图7(a),(b),(c)所示。
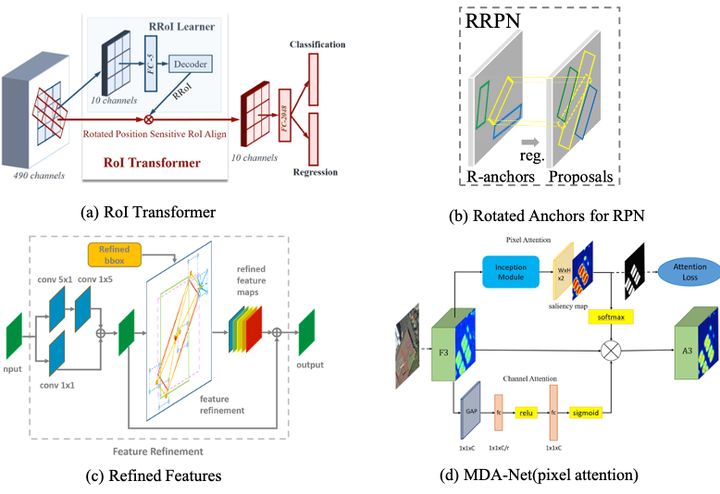
图7:不同的特征增强方式

其实,2.1 所提到的特征配准其实就是一种背景噪声抑制的方法,其采取的方式就是更好的crop出前景的特征。而SCRDet [5]则是通过Attention的机制直接抑制背景部分的特征,其提出的MDA-Net通过mask提前预监督形成pixel attention实现了对噪声的抑制。具体的方式如图7(d)所示。

对于有方向目标的预测,我们的直观想法是:对于回归角度,需要对旋转比较敏感(rotation-sensitive)的特征,而对于分类来说,则需要具有旋转不变性(rotation-invariant)的特征。RRD[15] 正是基于这个假设,提出了利用ORN [16]提取具有旋转敏感性的特征用于回归分支,然后利用ORP (Oriented Response Pooling)来获取旋转不变形特征用于分类。在场景文本检测中取得了较好的效果。具体的方式请见图8。
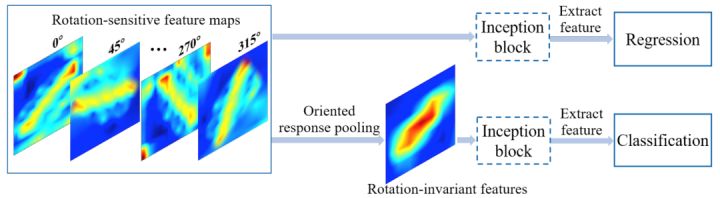
图8:Rotation-Sensitive Regression (RSR)结构示意图


针对五参数表示法中存在的PoA和EoE的问题,SCRDet [5]提出了IoU-smooth L1 loss,在原有的smooth L1 loss的基础上,加入了IoU的常量因素(constant factor),具体的形式如下式所示。
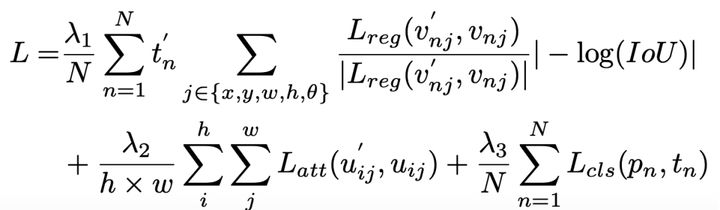
同样针对五参数表示法的PoA和EoE的问题,[9] 提出了modulated rotation loss,形式如下式所示。在遇到边界问题的时候,允许角度直接逆时针旋转来拟合ground-truth框。
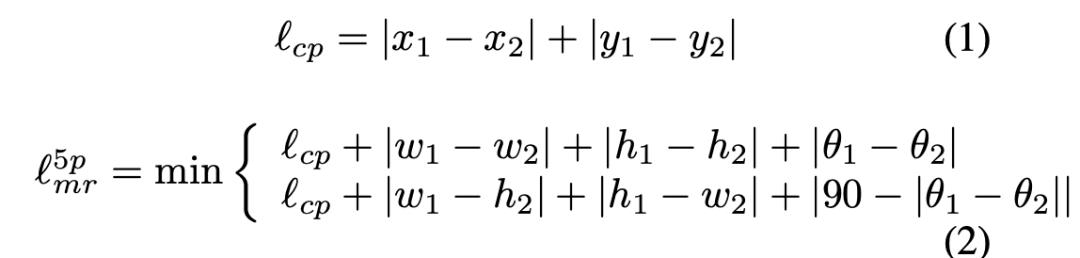
同样针对五参数表示法,[11] 提出PoA和EoE的本质问题是理想的拟合情况超出了我们输出定义的范围,进而提出图9所示的Circular Smooth Label [11] ,利用分类的方式代替原来的角度回归。这种方法有效的避免了PoA的问题。
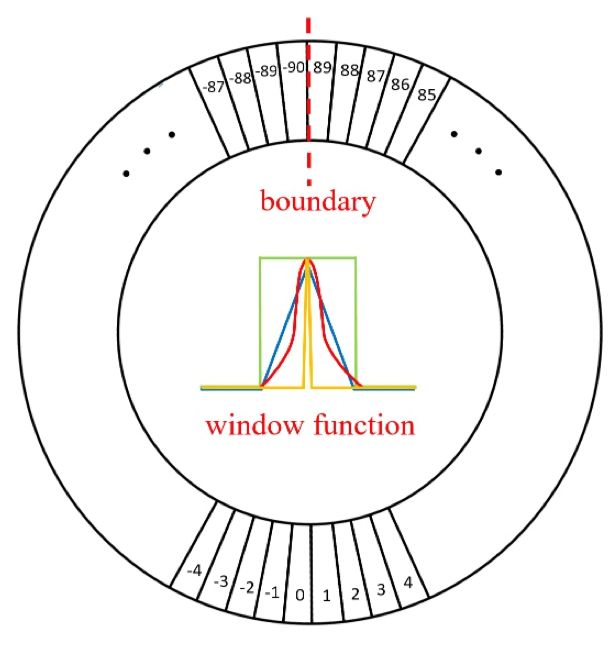
图9:Circular Smooth Label

针对八参数表示法中存在的边界不连续的问题,[9] 提出了改进的方案,即同时顺时针方向和逆时针方向计算误差,选取其中小的那个。这样就避免掉了边界不连续的问题。具体的定义形式如下。
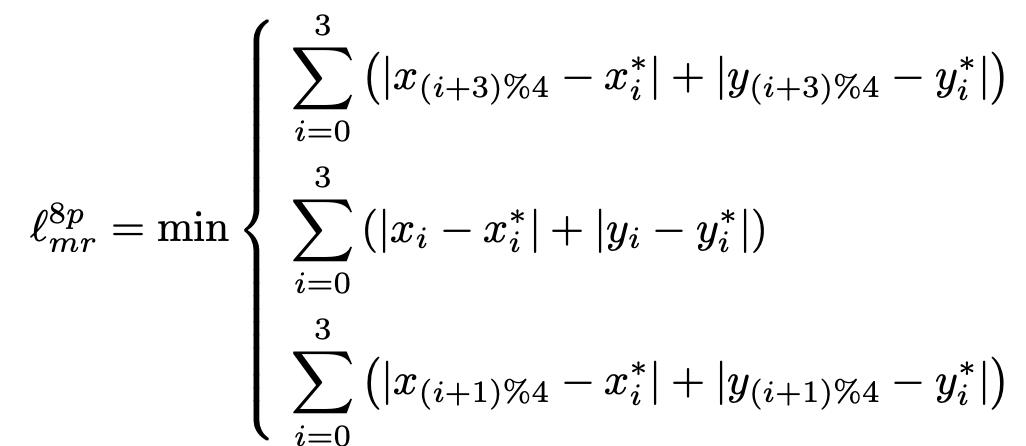

腾讯优图基于内容理解等相关业务需求,也一直在研究不规则目标检测相关的算法,并重点关注和业务需求更紧密的密集场景多角度目标检测这一方向。我们觉得导致密集场景多角度目标检测还不太好的主要原因有以下2点:
1、单一感受野不能很好的适配多变物体:一般网络的感受野都是固定大小并且沿着水平方向进行计算,没有角度,而实际物体大多具有多种不同的尺度和角度。
2、静态范式的固定模型无法很好的对每个独特样本进行推断:检测网络中的分类和回归分支丧失了对每个独特样本进行灵活响应的能力,进而降低了模型的泛化性能。
针对这两个问题,我们在CVPR论文 [6] 中提出了动态修正网络DRN,它主要包含两个模块:Feature Selection Module 和 Dynamic Refinement Head。从图10前2张图可以看到,传统的卷积网络在同一层的卷积核对应的感受野大小是固定的,并且都是水平方向,而密集场景中物体的角度和大小是不固定的,从图中可以看到感受野无法和物体相匹配。为了使得密集场景下感受野和多角度目标更匹配以提取更好的特征,如图所示,我们需要使用不同shape的卷积核并且要具有和旋转目标相匹配的角度。

图10:旋转卷积核和旋转目标更匹配
我们论文中提出的Feature Selection Module 就具有这样一个功能,如图11,它能够使网络依据目标的大小和角度自适应的调整感受野。具体来说:我们设计了一个多分支结构,在每个分支中,我们利用不同shape的旋转卷积进行特征的聚合,再利用Spatial-wise Attention 进行多分支信息的融合。
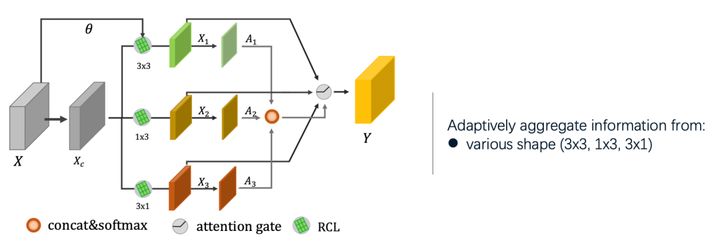
图11:特征选择模块FSM
其中的旋转卷积RCL如图12所示,灵感来自于可变形卷积,不同之处在于,我们预测出每个位置的物体角度之后,通过旋转矩阵计算出每个卷积核对应的偏移值从而进行旋转特征的提取。
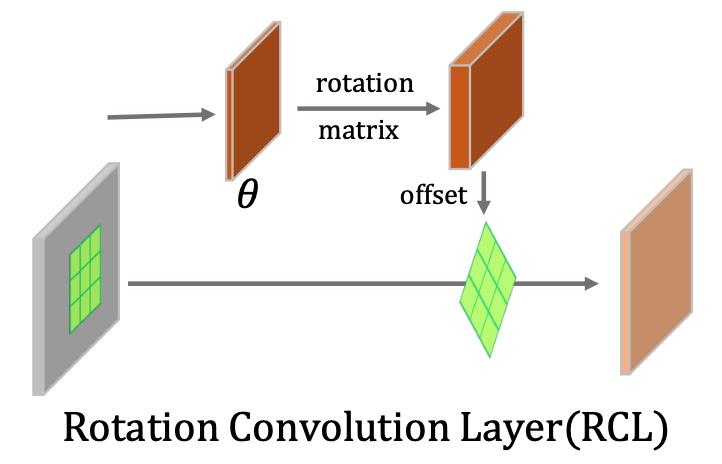
图12:旋转卷积RCL
我们的第二个contribution是动态修正模块。现有的技术绝大部分采用静态范式,即在训练阶段学习模型,之后固定模型的所有参数,并对测试样本进行推断,这使得模型丧失了对每个独特样本进行灵活响应的能力,进而降低了模型的泛化性能。如图13所示是一个三分类的示意图,不同颜色的实心圆点表示不同类别的样本。整个圆形区域表示特征空间,而不同颜色的半径线段表示分类界面。图中有些样本距离分类界面很近,正确分类难度较大,这些样本则与模型学习到的一般性知识不是十分契合。因此,我们需要更加灵活的模型,能够对不同的样本进行灵活响应。
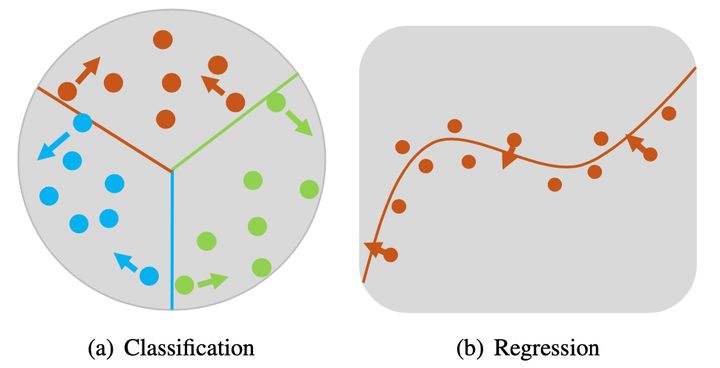
图13:动态修正网络应用于分类和回归示意图
基于此,我们提出动态修正技术,赋予模型能够根据样本独特性进行动态修正的能力。具体就是:针对分类任务设计的动态特征修正模块DRC,和针对回归任务设计的动态预测修正模块DRR。如图14所示是DRC,我们首先通过动态滤波器学习器(Gc)学习得到Example-wise Kernel Weights Kc。之后将Kc作为卷积核对F_mid 进行卷积操作,得到 。同时,为了达到网络可以根据样本自身特点进行自适应调整的目的,我们对 在通道方向进行归一化,作为针对F_mid在对应位置的修正特征。当然,为了使模型更好的收敛,我们设置一个超参数,限定特征移动的范围。
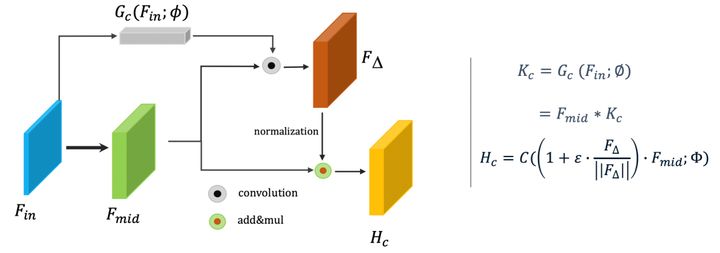
图14:Dynamic Refinement for Classification (DRC)
同样的,在回归任务中,我们通过对每个目标预测一个偏移值进行回归结果的修正,我们称之为DRR。与DRC不同的是,此时 不是作为特征修正向量作用于特征,而是直接对预测结果 进行修正。
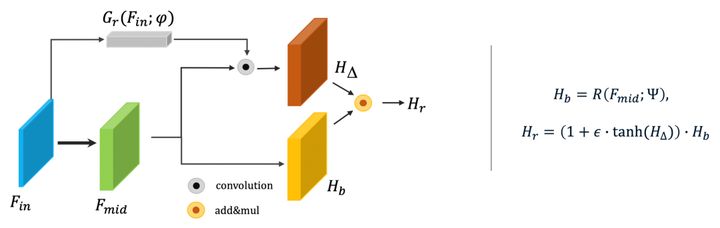
图15:Dynamic Refinement for Regression (DRR)
整体旋转检测框架我们使用CenterNet作为baseline,这是一个anchor free的目标检测框架,它将物体定义为一个中心点,可以看到在提取特征之后,网络利用heatmap预测物体中心点,并回归物体的尺寸大小和中心点偏移。为了预测旋转目标,我们添加了一个新的分支来回归旋转框的角度同时将我们的Feature Selection Module 添加在最后一个卷积层和检测头之间。最后,如图16虚线框部分所示,我们用前面介绍的动态调整模块替换掉常规的分类和回归分支以提高模型效果,最终在DOTA、HRSC2016和SKU110k上都取得了当时不错的效果。
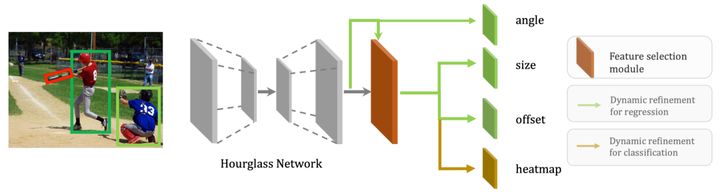
图16:Dynamic Refinement Network (DRN)整体框架图
具体业务实践中,我们不规则目标检测当前主要应用在内容理解相关业务场景中,比如旗帜检测、货架商品检测和顶拍人体检测等业务领域。

图17:不规则目标检测主要业务场景
参考文献
[1] Ding, J., Xue, N., Long, Y., Xia, G.S., Lu, Q.: Learning roi transformer for oriented object detection in aerial images. In: (CVPR) (June 2019) .
[2] Jiang, Y., Zhu, X., Wang, X., Yang, S., Li, W., Wang, H., Fu, P., Luo, Z.: R2cnn: rotational region cnn for orientation robust scene text detection. arXiv preprint arXiv:1706.09579 (2017) .
[3] Ma, J., Shao, W., Ye, H., Wang, L., Wang, H., Zheng, Y., Xue, X.: Arbitrary- oriented scene text detection via rotation proposals. IEEE Transactions on Multi- media (2018) .
[4] Yang, X., Liu, Q., Yan, J., Li, A., Zhang, Z., Yu, G.: R3det: Refined single-stage detector with feature refinement for rotating object. arXiv preprint arXiv:1908.05612 (2019) .
[5] Yang, X., Yang, J., Yan, J., Zhang, Y., Zhang, T., Guo, Z., Sun, X., Fu, K.: Scrdet: Towards more robust detection for small, cluttered and rotated objects. In: (ICCV) (October 2019) .
[6] Xingjia Pan, Yuqiang Ren, Kekai Sheng, Weiming Dong, Haolei Yuan, Xiaowei Guo, Chongyang Ma, Changsheng Xu. Dynamic Refinement Network for Oriented and Densely Packed Object Detection. (CVPR), 2020 .
[7] Liao, M., Shi, B., Bai, X.: Textboxes++: A single-shot oriented scene text detector. IEEE transactions on image processing 27(8), 3676–3690 (2018) .
[8] Liu, Y., Zhang, S., Jin, L., Xie, L., Wu, Y., Wang, Z.: Omnidirectional scene text detection with sequential-free box discretization. arXiv preprint arXiv:1906.02371 (2019) .
[9] Qian,W.,Yang,X.,Peng,S.,Guo,Y.,Yan,C. Learning modulated loss for rotated object detection. arXiv preprint arXiv:1911.08299 (2019) .
[10] Y. Xu et al., "Gliding vertex on the horizontal bounding box for multi-oriented object detection," TPAMI.2020.2974745.
[11] X. Yang and J. Yan, “Arbitrary-oriented object detection with circular smooth label,” arXiv preprint arXiv:2003.05597, 2020.
[12] X. Zhou, J. Zhuo, and P. Kra ̈henbu ̈hl. Bottom-up object detection by grouping extreme and center points. In CVPR, 2019.
[13] Xiaobing Wang, Yingying Jiang, Zhenbo Luo, Cheng-Lin Liu, Hyunsoo Choi, and Sungjin Kim. Arbitrary shape scene text detection with adaptive text region representation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 6449–6458, 2019.
[14] Y. Liu, H. Chen, C. Shen, T. He, L. Jin, and L. Wang, “ABCNet: real- time scene text spotting with adaptive bezier-curve network,” in Proc. IEEE Conf. Comp. Vis. Patt. Recogn., 2020.
[15] Liao, M., Zhu, Z., Shi, B., Xia, G.s., Bai, X.: Rotation-sensitive regression for oriented scene text detection. In: Proc. CVPR. pp. 5909–5918 (2018) .
[16] Y. Zhou, Q. Ye, Q. Qiu, and J. Jiao. Oriented response networks. In CVPR, 2017.
以上是关于优Tech分享 自然场景下的不规则目标检测的主要内容,如果未能解决你的问题,请参考以下文章