自然场景文本检测识别 - 综述
Posted 等待破茧
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了自然场景文本检测识别 - 综述相关的知识,希望对你有一定的参考价值。
自然场景文本检测识别 - 综述 - Part II
坚果粥:自然场景文本检测识别 - 综述 - Part I26 赞同 · 1 评论文章

拥有这些背景知识后,我们可以开始学习自然场景文本检测识别(STR)的算法模型。近几年关于STR的文献大概可以分为文本检测、文本识别和端到端检测识别,以下我对它们分别做一个介绍。(题图取自[1])
一,文本检测(Text Detection)
文本检测算法专注于检测文本的存在和位置,具体来说,任务是输出每个文本目标的边框,但不关心识别具体的文字内容。文本检测主流算法大致可以分为两类。第一类与目标检测非常相似,第二类则基于图像分割的思想。
(1)基于目标检测的算法
这一类算法在骨干卷积网络的基础上,增加卷积层提出文本框提案,再执行两个子任务:判断提案对应于文本的概率和回归调节正样本提案的位置。文本框提案既可通过预设锚框的方式(如RRPN,TextBoxes++),也可通过直接预测的方式(如EAST,ABCNet)。相比于常规的目标检测,文本目标通常为长条形、具有较大的纵横比,而且可能存在旋转歪斜的情况。因此,此类算法通常使用扁平竖高的文本框、旋转文本框或者直接使用多边形文本框,从而可以判别歪斜的文本。
例如,在TextBoxes++中,作者预设了一系列长宽比为1,2,3,5,1/2,1/3,1/5的锚框以刻画不同形状的文本。在骨干网络的基础上,模型增加了卷积层输出每个位置上每个锚框对应于文本的概率和位置回归。图中的绿色和黑色虚线都是预设的锚框,绿色对应于正例而黑色对应于负例。在对正例做位置回归时,模型同时执行两个任务,一个是计算最小的包含文本的四边形(黄色实线)的顶点坐标相对于锚框的位置偏移,如图中红线所示;另一个是计算最小的包含文本的水平矩形(绿色实线)相对于锚框的位置偏移。这两个任务可以用于不同的应用。
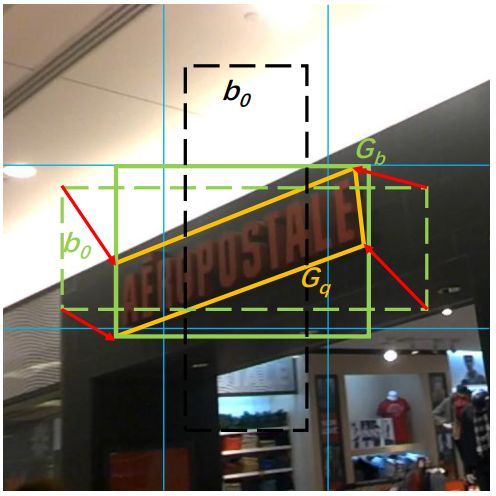
基于锚框的文本检测,图片取自[3]
(2)基于图像分割的算法
第二类算法的研究者认为,使用预设形状的文本框无法很好地描述某些特殊形状的文本(如纵横比过大或者弧形)。他们受图像分割工作的启发,另辟蹊径,先从像素层面做分类,判别每一个像素点是否属于一个文本目标和它与周围像素的连接情况,再将相邻像素结果整合为一个文本框。这种做法可以适应任何形状和角度的文本,典型代表有pixelLink,CRAFT等。

基于图像分割的文本检测,图片取自[5]
例如,在CRAFT中,模型在骨干卷积网络的基础上,额外增加了几个卷积层,最后使用的1x1卷积层有两个卷积核。第一个卷积核输出每个像素点属于某一字符的概率,也叫位置分;第二个卷积核输出每个像素点处于两个字符间隙的概率,也叫邻域分。模型为这两个分数分别设定一个阈值,并取出模型输出两个分数中至少一方高于阈值的像素点,所有相连的满足要求的像素点便组成了一个文本目标。最终模型计算包围每个目标的最小矩形作为文本框输出。关于CRAFT的详细介绍可见以下链接:
坚果粥:自然场景文本检测识别 - CRAFT28 赞同 · 9 评论文章

二,文本识别(Text Recognition)
文本识别算法不检测文本目标的存在和位置,而是对已经检测出来的文本区域进行文字的识别。换句话说,将文本检测的结果作为文本识别的输入,即可完成完整的检测识别过程。如果说文本检测与目标检测还比较类似,文本识别与图像分类则大有不同。图像分类中的目标作为一个整体属于某一类别,而文本识别中的目标为一段具有上下文语义信息的序列,对其字符单元我们可以分类,而对整个序列不宜用直接分类的思维来处理。

图像分类vs文本识别,图片取自[7][8]
由于图像卷积层的像素点个数与文本的长度不同,卷积层特征与字符并没有一一对应关系。如何建立图像与文本之间的联系,是文本识别算法的关键。常用的文本识别算法有两类,第一类基于Connectionist Temporal Classification(CTC),第二类基于自然语言处理(NLP)中的Sequence-To-Sequence(Seq-To-Seq)。
(1)基于CTC的算法
由于图片中的字符大小千差万别,图片卷积层上的像素单元与真实文本的长度不一定匹配。换句话说,可能存在(1)多个单元属于同一字符,或者(2)有些单元对应字符间空隙的情况。CTC算法解决的核心问题是,在没有像素单元一一对应的字符标注,只有整段文本标注的情况下,如何设计和训练字符分类器。这一类算法在分类目标中额外增加了一个空白字符"-",对每个像素单元预测完字符进行整合时,先去除连续重复出现的字符以解决问题(1),再去除空白字符以解决问题(2)。由于存在多条路径对应同样的最终文本,如"AAB","A-B”和“ABB”都对应“AB”,算法中需要将这些路径的概率求和得到模型预测文本为“AB”的概率。
由于文本具有上下文语义信息,我们在肉眼识别文本时,对于某些模糊或不确定的字符可以根据上下文推断出来。同理,在文本识别模型中,整合上下文语义信息有利于提高模型的准确性。在NLP中,我们通常使用递归神经网络(RNN)来描述文本序列。在RNN中经常出现信息无法长距离传播的问题,LSTM是一种典型的RNN设计用于解决长距离传播问题。在LSTM中,每个单元有一个输入和输出值,模型除了隐变量h以外还有一个cell state c,模型对c没有直接的门操作,因而它可以在长距离内顺畅传播信息。每一单元的h和c由上一单元的h,c和这一单元的输入通过一系列门操作计算而来,而输出值由这一单元的h得到。在LSTM中,每一单元整合了之前单元的语境,适合于描述文本序列。双向LSTM就是两个反向的LSTM同时存在,因而序列可以同时整合上文和下文的信息。
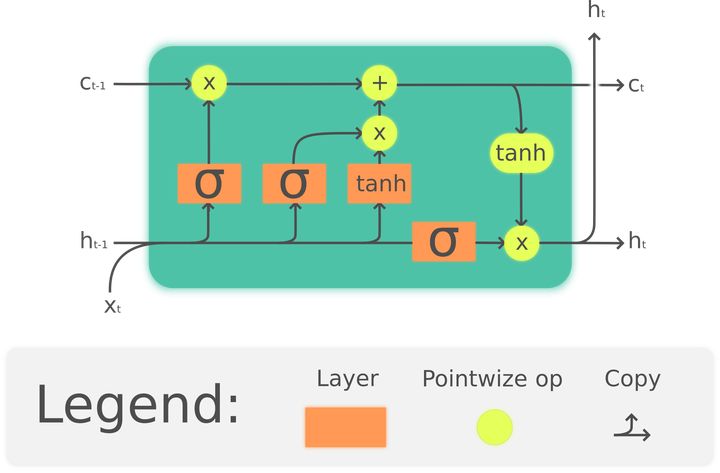
LSTM网络结构,图片取自[10]
例如,在[11]中,作者在使用骨干网络得到卷积特征后,先使用了双向LSTM整合上下文语境信息。LSTM的长度与卷积特征长度相同,每个单元以其对应的卷积层像素值为输入,结合上下文语义后输出。输出层再经过一层CTC网络,得到最终的文本序列。如下图所示,CTC预测的最大概率序列为“-s-t-aatte”,经过前述规则最终转变为state。
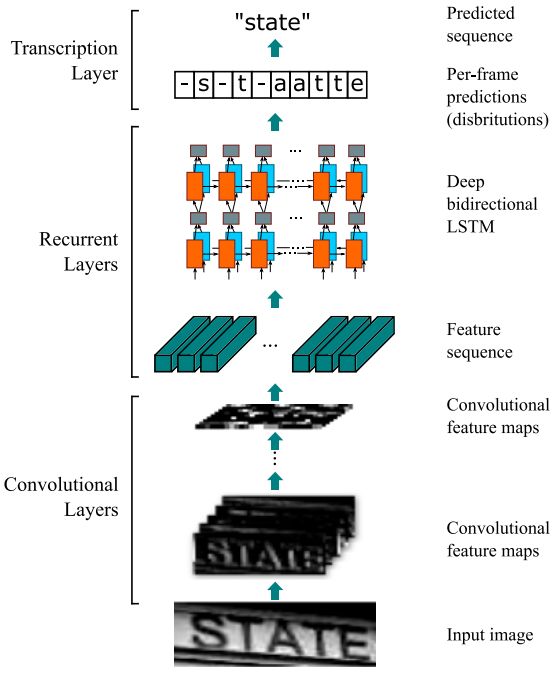
基于CTC的文本识别,图片取自[11]
(2)基于Seq-To-Seq的算法
第二类算法基于NLP中的Seq-to-Seq思想,直接使用RNN输出长度可变的字符序列,以解决上述的序列对齐问题。在NLP的Seq-To-Seq任务中,我们常常使用encoder-decoder架构,先用encoder将输入序列抽象为编码,再用decoder将编码解码为输出序列。在我们的文本识别任务里,骨干卷积网络已经获得了图像的深层卷积特征,可以理解为已经对图像进行了编码。因此,我们只需要一个decoder RNN将卷积特征输出为文本序列。
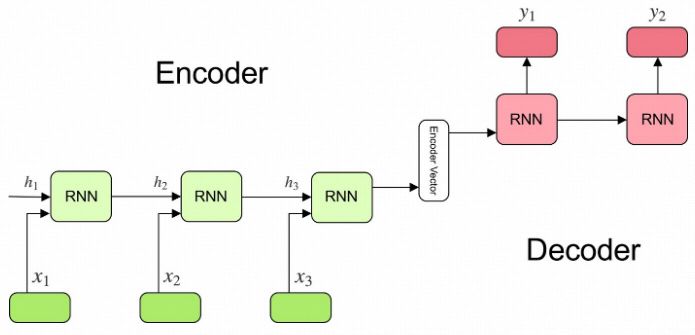
Encoder-Decoder网络,图片取自[12]
近年来,注意力机制(Attention)被引入到encoder-decoder模型中,极大的提升了模型准确性。在传统的encoder-decoder中,输入序列的全部信息被抽象到一个编码变量中,再由编码变量生成输出序列,输入与输出仅仅靠编码变量联系。然而我们知道,在常见的Seq-To-Seq任务(如翻译)中,输出的每一个字符往往与输入中的特定字符有一一对应关系。例如,在将“Today is Wednesday”翻译为"今天是星期三"的任务中,“Wednesday”与“星期三”语义对应。仅仅靠整个输入序列抽象出来的一个编码变量无法很好的利用这种对应关系。Attention机制有效的解决了这个问题,Attention中,在decoder RNN的每一个节点D(n),我们不仅利用上一节点D(n-1)的数据,还会利用整个encoder网络中的数据,而且我们会寻找与当前节点语义对应的encoder节点E(m),赋予这一节点的隐变量一个较大的权重。具体的权重分配是通过计算上一节点D(n-1)与整个encoder中的隐变量E的相似度得到。
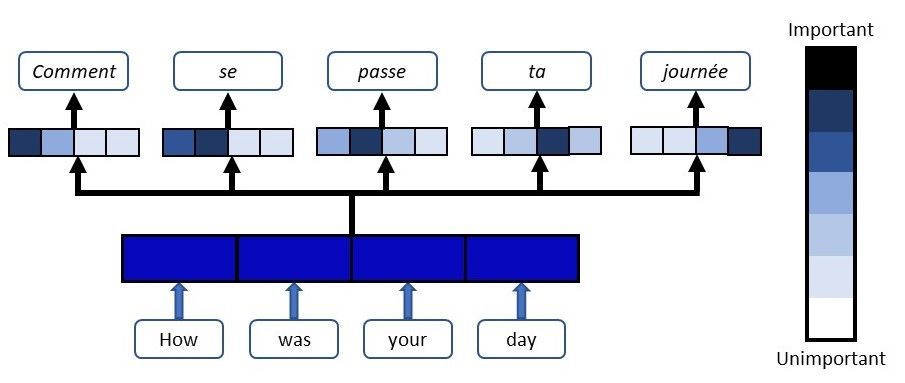
翻译任务中,翻译出每个词时模型会将注意力集中到对应的原句中的词语,图片取自[14]
回到我们的文本识别算法,在识别特定字符时,算法会将注意力集中到图片上对应的区域,如下图中,当decoder RNN在输出字符“p”时,我们希望模型注意力集中在图片中的"p"所在的像素区域。具体操作中,在decoder的每一节点,我们计算上一节点与整个图像卷积层上各像素点的相似度,从而得到每个像素点的权重,作为当前节点的一个额外输入。Attention极大地提升了识别的准确性,典型的工作有RARE,ASTER,ShowAttendRead等。
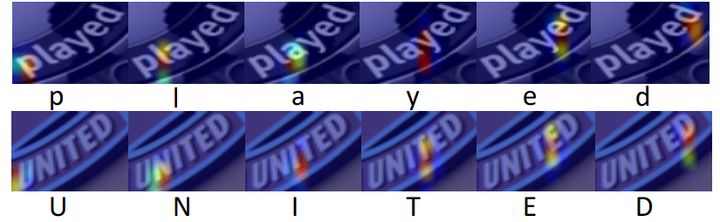
注意力可视化,图片取自[17]
三,端到端检测识别(Text Spotting)
尽管文本检测和识别算法分别取得了不错的效果,两步法在操作上很不方便。另一方面,文本识别的结果可以为文本检测模型提供额外信息,纠正检测的错误,所以联合训练可以进一步提高整体的准确性。因此,端到端(End-to-End, E2E)模型的设计依然十分重要。在这里我们简要介绍三个典型的E2E模型,FOTS,Mask TextSpotter和CharNet。
Fast Oriented Text Spotting (FOTS)是2018年1月由商汤科技和中科院深圳先进技术研究院提出的E2E模型,文章被引用超过130次。FOTS模型架构大体上可以分为几部分,首先文章以深度残差网络(ResNet)为骨干网络获取图片的卷积特征,这一部分中作者采用了一种类似于Feature Pyramid Network的架构,简单来说就是不仅仅使用骨干网络最后一层的输出,而是将骨干网络的浅层和深层特征结合在一起,同时保留了浅层的结构特征和深层的语义特征,使得网络的输出含有丰富的信息。接着是文本检测器,它在卷积层的每个像素单元,预测一个文本框的位置和旋转角度。由于文本框可能倾斜,在输入文本识别器之前,文章设计了一种算法ROI Rotate,将目标旋转后再缩放为固定的大小,ROI Rotate其实就是在ROI Align的基础上增加了旋转操作。最后,作者使用双向LSTM结合上下文信息后,输入CTC层做文本识别。整个模型可以做端到端的训练。FOTS在保证准确性的同时,拥有极快的推断速度。

FOTS模型架构,图片取自[18]
坚果粥:自然场景文本检测识别 - FOTS11 赞同 · 0 评论文章

Mask TextSpotter是2018年8月由华中科技大学和旷视科技提出的E2E模型。模型算法依然采用了ResNet+FPN的骨干网络。在文本检测上,模型采用了目标检测中常见的锚框分类回归的方法,提出潜在文本目标区域并做文本框精细回归调节。文章的主要亮点在于文本识别模块,不同于FOTS使用的RNN+CTC结构,模型对文本区域设计了两个图像分割任务:一是对整个文本目标的分割任务以确定文本在矩形文本框中的精确位置,如下图中间的白色扇形区域;二是对每个字典字符做图像分割,作者使用了26个英文字母+10个阿拉伯数字+1个背景共37个分割子任务,从而得到每个字符的识别概率分布。在推断时,通过对字符区域中所有像素点上不同字符分割子任务得到的概率求平均,投票得到概率最高的字符作为输出,如下图右端的彩色小方形。作者于2019年8月更新了第二版模型,在识别任务中增加了一个Attention+RNN模块。Mask TextSpotter以其独特的识别模型取得了很好的识别准确性。
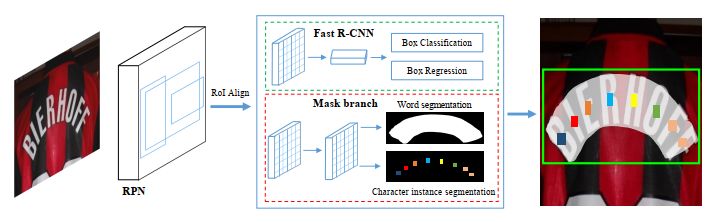
Mask TextSpotter模型架构,图片取自[19]
CharNet是2019年10月由码隆科技和阿德莱德大学等提出的E2E模型。上面介绍的两个E2E模型都需要将检测的结果取出再缩放后输入到识别模型中,识别模型依赖于检测的输出,整个流程需要串行。而CharNet中,检测和识别是并行的,省去了ROI Align操作,避免了其对不规则文本带来的不准确性。CharNet中的检测部分类似于FOTS,在每个卷积层像素单元预测一个文本框。识别部分则分为三个分支,前两支与Mask TextSpotter类似,第一支做整个文本段的图片分割,第二支对字典里的每个字符做分割,而第三支对每个字符预测一个字符框。最终整合结果时,先取第一支中的文本概率大于一定阈值的像素点,输出对应的字符框即第三支的结果,再将该点上第二支的概率最大字符作为该字符框的字符。最后,将同一检测框中的所有字符拼接起来,输出最终结果。CharNet在很多数据集和任务中取得了SOTA的效果。
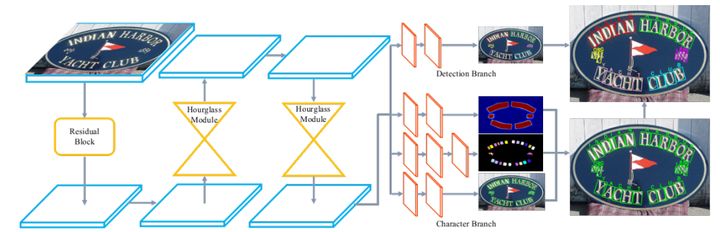
CharNet模型架构,图片取自[20]
坚果粥:自然场景文本检测识别 - CharNet3 赞同 · 9 评论文章

值得注意的是,在初版Mask TextSpotter和CharNet中,模型对所有字典字符使用了图像分割的思想做文本识别,相当于对每一字符独立做分类再拼接起来,没有采用RNN+CTC或Attention RNN的思路。因此,模型并没有直接使用文本上下文信息,然而也取得了很好的效果。
四,资源推荐
以上就是关于STR的一个简要介绍。看了这么多,如果大家想拿一个模型快速使用,给大家推荐两个最新的、开源的、附带预训练模型的文本检测识别包,亲测有效:
英文:CharNet
坚果粥:自然场景文本检测识别 - CharNet3 赞同 · 9 评论文章
中英文:AttentionOCR
坚果粥:自然场景文本检测识别 - Attention OCR29 赞同 · 33 评论文章

另外附上一篇2019年的综述文章和一个收集齐全了大量最新文献链接及效果的网站:
Scene Text Detection and Recognition: The Deep Learning Era
https://github.com/hwalsuklee/awesome-deep-text-detection-recognition
最后,由于我水平有限,如果大家有什么问题和建议,欢迎在评论区指出~
看到这里了,点赞关注一下吧!
[1] EAST: An Efficient and Accurate Scene Text Detector. arXiv:1704.03155v2
[2] Arbitrary-Oriented Scene Text Detection via Rotation Proposals. arXiv:1703.01086v3
[3] TextBoxes:++ A Single-Shot Oriented Scene Text Detector. arXiv:1801.02765v3
[4] ABCNet: Real-time Scene Text Spotting with Adaptive Bezier-Curve Network. arXiv:2002.10200v2
[5] PixelLink: Detecting Scene Text via Instance Segmentation. arXiv:1801.01315v1
[6] Character Region Awareness for Text Detection. arXiv:1904.01941v1
[7] https://www.kdnuggets.com/2018/09/object-detection-image-classification-yolo.html
[8] https://vision.cornell.edu/se3/wp-content/uploads/2014/09/wang_iccv2011.pdf
[9] Connectionist Temporal Classification: Labelling Unsegmented Sequence Data with Recurrent Neural Networks. icml_2006
[10] https://en.wikipedia.org/wiki/Long_short-term_memory
[11] An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition. arXiv:1507.05717v1
[12] https://towardsdatascience.com/understanding-encoder-decoder-sequence-to-sequence-model-679e04af4346
[13] Neural Machine Translation by Jointly Learning to Align and Translate. arXiv:1409.0473v7
[14] https://blog.floydhub.com/attention-mechanism/
[15] Robust Scene Text Recognition with Automatic Rectification. arXiv:1603.03915v2
[16] ASTER: An Attentional Scene Text Recognizer with Flexible Rectification. 10.1109/TPAMI.2018.2848939
[17] Show, Attend and Read: A Simple and Strong Baseline for Irregular Text Recognition. arXiv:1811.00751v2
[18] FOTS: Fast Oriented Text Spotting with a Unified Network. arXiv:1801.01671v2
[19] Mask TextSpotter: An End-to-End Trainable Neural Network for Spotting Text with Arbitrary Shapes. arXiv:1908.08207v1
[20] Convolutional Character Networks. arXiv:1910.07954v1
[21] Deep Residual Learning for Image Recognition. arXiv:1512.03385v1
[22] Feature Pyramid Networks for Object Detection. arXiv:1612.03144v2
[23] A Feasible Framework for Arbitrary-Shaped Scene Text Recognition. arXiv:1912.04561v2
[24] Scene Text Detection and Recognition: The Deep Learning Era. arXiv:1811.04256v4
以上是关于自然场景文本检测识别 - 综述的主要内容,如果未能解决你的问题,请参考以下文章