实时语音质量监控
Posted 声网Agora
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了实时语音质量监控相关的知识,希望对你有一定的参考价值。
今天主要想介绍下,实时语音的质量到底是什么样的,大概介绍一下这个领域的一些已有的一些方法,然后会再介绍一下现有的方法,并且介绍一下未来想做的一些事情。
语音质量评估方法
首先,大概介绍一下语音质量评估,这个之前就一般从那个方法而言的话,是分为主观的一个评价方法,还有一个客观的评价方法的。那主观性评价方法的话,其实就是完全靠人的一个情感,那主观其实也是分两种的,一种是我完全不给你一个原始的参考信号,就是我只给你一段语音,然后你听完之后你来告诉我,你认为这在于它的分数是应该是多少,那还有一种方法呢,会给你一个锚点,然后告诉你这个是最差的,然后让你去基于这个最差的去做一个评价,这个方法也是在目前论文中用的最多的一种,就是主观的一个评价方法。
客观评价方法
对于客观评价方法,根据是不是需要一个原始无损的参考信号,分为有参考的客观条件,有参考的客观评价方法,最早差不多是大概九六年左右,就有一个标准叫 P.861 的,率先就是提出来一种方法,就是给一个无损的,再给一个受损的语音信号,然后来比较它们的一些相似度,或者是一些听觉的一些损伤,然后来给一个分数。2000 年的时候,出来了一个 p.862,后来大概在 04 年,有一个称为 PESQ-WB 的方法,就把之前 pesq 从 8khz 的测试范围扩大到 16khz,然后,我们现在常用的一般就是这个 PESQ-WB。现在很多论文,其中包括比如:降噪、无损等,都还会用这种方法来做一个评价。差不多到 12 年的时候,ITPO 出来一个新的标准,p.863,这个 POLQA 方法其实是 pesq 的升级版,就是其在噪声的抑制上做了一些改进,另外,它的准确性其实还是蛮高的,这里说的准确性,其实就是同一段语调,用 POLQA 测出来的结果,跟人听出来的分数看是否接近,越接近,则测试越高的。
有参考客观评价方法
- P.861 PSQM 最早的标准
- P.862 PESQ、PESQ-WB,应用最广泛的有参考评价方法
- P.863 POLQA,最新的有参考评价方法
无参考客观评价方法
- P.563,最著名的窄带无参考评价方法
- ANIQUE,据作者称准确度超过有参考的 PESQ
- E-Model/P.1201,参数域评价方法
- xxNet,深度学习域评价方法
其实还是蛮多的,就比如说,最常用的那个 Itot 的 p.563 方法,其实主要就是只要给他一段语音就不需要给它一个原始无损的语音,然后他它会从它的语音的完整性,然后得到一个噪声的程度,然后看是不是都够流畅来判断这段语音是不是 OK。如果是它觉得这些 feature 所有的都没有问题的话,它就会给一个高分,如果有一些 feature,非常大的原因可能出现了,比如说语音之间的断裂,或者是因为噪声过大,它也会给一个相对低的一个分数,在 p.563 之后,又出来一个 ANIQUE,是美国的一个标准,据其文献称,它的准确度会超过刚才讲过的有参考的 pesq 的方法。再有就是参数域的方法,参数域的话,不会对语音信号去做处理,而是去用一些状态信息去做一个估计的事情。比如:这个 E-Model 方法,从采集到回声,再到编码的一整个,如果有哪个模块有一些损伤,它们会把损伤的影响因子从整体中裁剪掉。还有一种比较新的 p.1201 标准,这个标准包括音频、视频两种评价方法。其中音频部分,主要包括网络参数、编解码、音量参数等。
客观评价方法痛点
- 有参考方法,只能用在上线前
- 无参考方法-传统信号域,应用场景窄、鲁棒性差
- 无参考方法-传统参数域,仅在有限弱网条件下可以保持精度
- 无参考方法-深度学习,应用场景和语料有限,复杂度略高
- 场景窄
- 精确率差
- 鲁棒性差
- 复杂度高
线下测试的线上化
在线质量感知能力,其特点是,高精确、广覆盖、低复杂、强鲁棒。质量评估足够准确,覆盖绝大多数业务场景,不引入过多算法复杂度,和语音内容弱相关。
下行链路质量评价方法
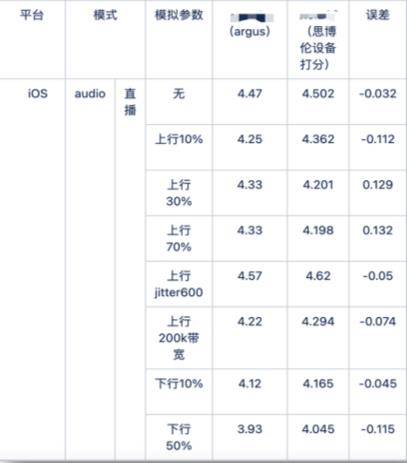
一个标准流程:编码-传输-解码-播放,所以其涉及到的因素:编解码器性能、网络质量、弱网对抗算法质量、设备播放能力等。我们做一组数据测试:在多弱网、多设备、多模式的测试 case 下,该方法的打分与 POLQA 的参考打分 MAE 小于 0.1 分,MSE 小于 0.01 分,误差最大值小于 0.15 分。下图是某设备某模式的多弱网测试结果:
上行链路质量评价方法
模块比较多,而且每个模块独立,所以,首先,每个模块有自己的独立检测能力。比如:回声模块,当前可能会漏掉回声,这一点,本身需要知道。然后,在所有模块自我检测完之后,在编码之前,还会做统一检测的模块,相当于一个卫士,做整个流程的把关。把所有的场景的共性提取,我们可以总结为四点:
- 设备采集稳定性
- 回声消除能力
- 噪声抑制能力
- 音量调整能力
漏回声的原因
其实我们非常希望知道当前是否会漏回声,那漏回声原因总体分为四大类:
- 延时抖动,引起延时抖动的原因可能有很多,比如:线程卡住没有及时送入信号,还有可能是当前外放设备非线性严重,双设备、非因果,非因果一般因为 buffer 原因
- 大混响环境,混响长度超过滤波器长度
- 采集信号溢出,导致滤波器不收敛
- 双讲,强依赖 NLP,顾此失彼
噪音、杂音原因
- 设备噪声,单频音、工频噪声、笔记本⻛扇声、无序杂音
- 环境噪声,Babble、鸣笛等
- 信号溢出,爆破音
- 算法引入,残留回声等
音量小
-
设备采集能力弱/说话声音小,大多数
设备播放能力弱,对端
-
模拟增益、模拟 boost 增益小,PC 端
数字增益小,双向增益
独立检测模块
- 啸叫检测,检测并抑制
- 杂音检测,预警
- 噪音检测,量化噪音引入的影响
- 硬件检测,估计设备外放性能
未来
感知、反馈和监控的一体化
- 内部状态更细
- 体验覆盖更广
- 反馈速度更快
- 覆盖通话更全
以上是关于实时语音质量监控的主要内容,如果未能解决你的问题,请参考以下文章