多图详解attention和mask。从循环神经网络transformer到GPT2,我悟了
Posted 神洛华
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了多图详解attention和mask。从循环神经网络transformer到GPT2,我悟了相关的知识,希望对你有一定的参考价值。
transformaer原理
文章目录
说明:
本文主要来自datawhale的开源教程 《基于transformers的自然语言处理(NLP)入门》,此项目也发布在 github。部分内容(章节2.1-2.5,3.1-3.2,4.1-4.2)来自北大博士后卢菁老师的《速通机器学习》一书,这只是我的一个读书笔记,进行一般性总结,所以有些地方进行了简写(比如代码部分,不要喷我。有误请反馈)。想要了解更详细内容可以参考datawhale教程(有更多的图片描述、部分动图和详细的代码)和《速通》一书。
另外篇幅有限(可也能是水平有限),关于多头注意力的encoder-decoder attention模块进行运算的更详细内容可以参考 《Transformer概览总结》。从attention到transformer的API实现和自编程代码实现,可以查阅 《Task02 学习Attention和Transformer》(这篇文章排版很好,干净简洁,看着非常舒服,非常推荐)
1. Transformer的兴起
2017年,《Attention Is All You Need》论文首次提出了Transformer模型结构并在机器翻译任务上取得了The State of the Art(SOTA, 最好)的效果。2018年,《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》使用Transformer模型结构进行大规模语言模型(language model)预训练(Pre-train),再在多个NLP下游(downstream)任务中进行微调(Finetune),一举刷新了各大NLP任务的榜单最高分,轰动一时。2019年-2021年,研究人员将Transformer这种模型结构和预训练+微调这种训练方式相结合,提出了一系列Transformer模型结构、训练方式的改进(比如transformer-xl,XLnet,Roberta等等)。如下图所示,各类Transformer的改进不断涌现。
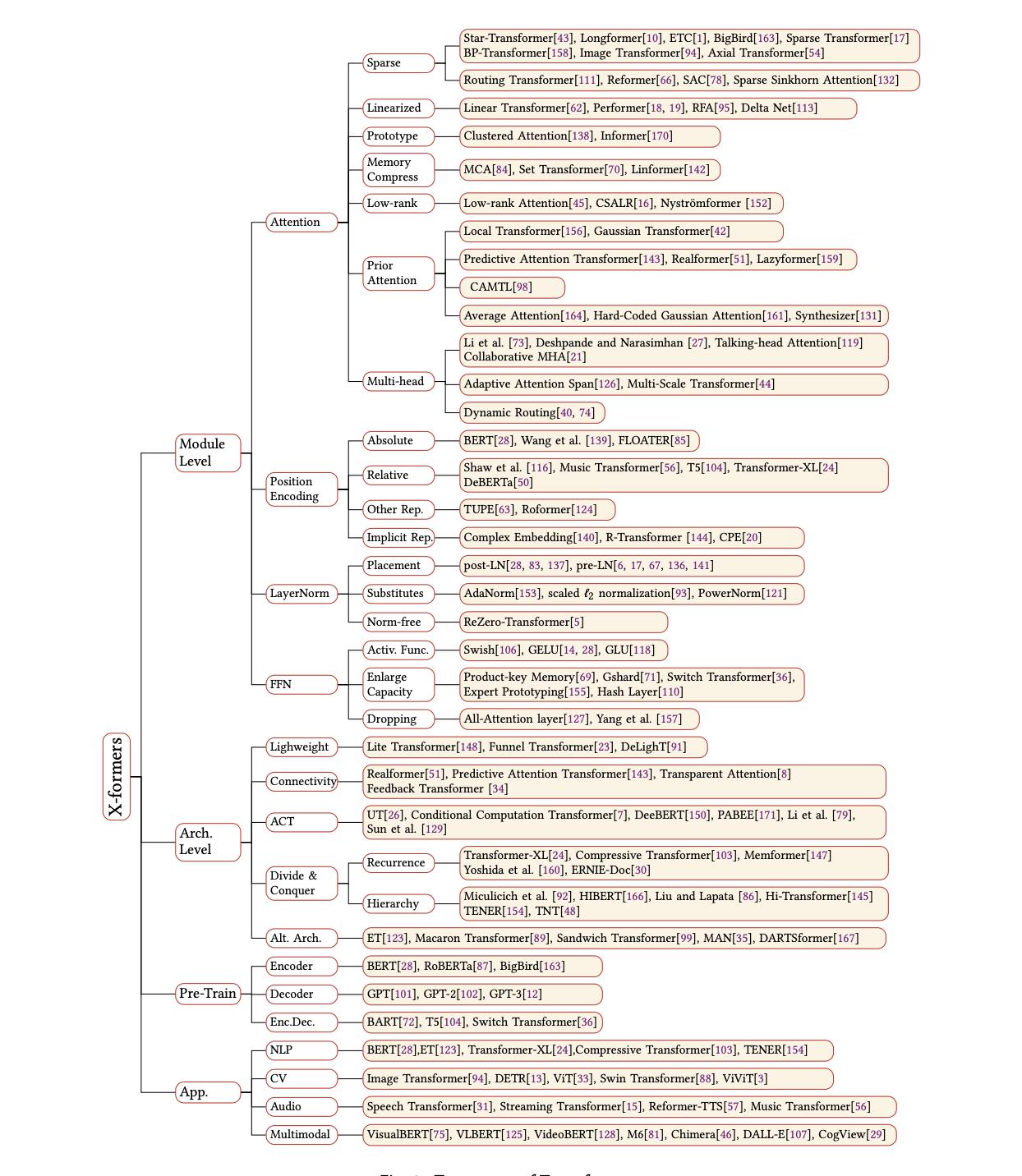
图片来自复旦大学邱锡鹏教授:NLP预训练模型综述《A Survey of Transformers》。中文翻译可以参考:https://blog.csdn.net/Raina_qing/article/details/106374584
https://blog.csdn.net/weixin_42691585/article/details/105950385
另外,由于Transformer优异的模型结构,使得其参数量可以非常庞大从而容纳更多的信息,因此Transformer模型的能力随着预训练不断提升,随着近几年计算能力的提升,越来越大的预训练模型以及效果越来越好的Transformers不断涌现。
本教程也将基于HuggingFace/Transformers, 48.9k Star进行具体编程和解决方案实现。
NLP中的预训练+微调的训练方式推荐阅读知乎的两篇文章 《2021年如何科学的“微调”预训练模型?》 和《从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史》。
2. 图解Attention
2.1 seq2seq
seq2seq模型是由编码器(Encoder)和解码器(Decoder)组成的。其中,编码器会处理输入序列中的每个元素,把这些信息转换为一个向量(称为上下文context)。当我们处理完整个输入序列后,编码器把上下文(context)发送给解码器,解码器开始逐项生成输出序列中的元素。上下文向量的长度,基于编码器 RNN 的隐藏层神经元的数量
如何把每个单词都转化为一个向量呢?我们使用一类称为 “word embedding” 的方法。这类方法把单词转换到一个向量空间,这种表示能够捕捉大量单词之间的语义信息。(word2vec)通常embedding 向量大小是 200 或者 300。
在机器翻译任务中,上下文(context)是一个向量(基本上是一个数字数组)。编码器和解码器在Transformer出现之前一般采用的是循环神经网络。上下文context向量是这类模型的瓶颈。以两个具有不同参数的LSTM分别作为encoder和decoder处理机器翻译为例,结构如下:
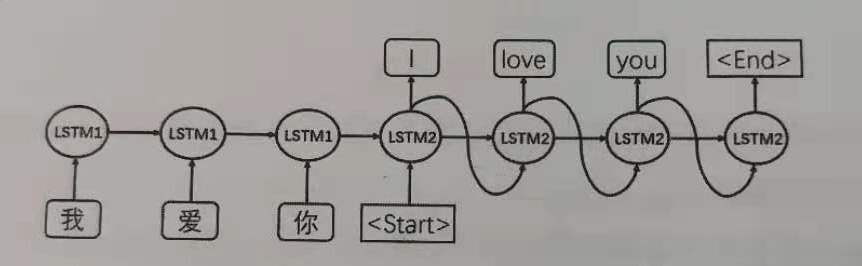
LSTM1为编码器,在最后时刻的上下文信息 C 包含中文“我爱你”的完整信息,传给给解码器LSTM2,作为翻译阶段,LSTM2的起始状态start。之后每时刻的预测结果作为下一时刻的输入,翻译顺序进行直到终止符停止翻译。
2.2 循环神经网络的不足:
循环神经网络的处理此类任务存在一些不足:
1.机器翻译中,使用LSTM的encoder只输出最后时刻的上下文信息C,而这两个模型都存在长距离衰减问题,使得C的描述能力有限。当编码句子较长时,句子靠前部分对C的影响会降低;
2.解码阶段,随着序列的推移,编码信息C对翻译的影响越来越弱。因此,越靠后的内容,翻译效果越差。(其实也是因为长距离衰减问题)
3.解码阶段缺乏对编码阶段各个词的直接利用。简单说就是:机器翻译领域,解码阶段的词和编码阶段的词有很强的映射关系,比如“爱”和“love”。但是seq2seq模型无法再译“love”时直接使用“爱”这个词的信息,因为在编码阶段只能使用全局信息C。(attention在这点做得很好)
在 2014——2015年提出并改进了一种叫做注意力attetion的技术,它极大地提高了机器翻译的质量。注意力使得模型可以根据需要,关注到输入序列的相关部分。
2.3 attention的引出(重点内容)
基于上面第3点,需要对模型进行改造。(图不是很好,将就看看)
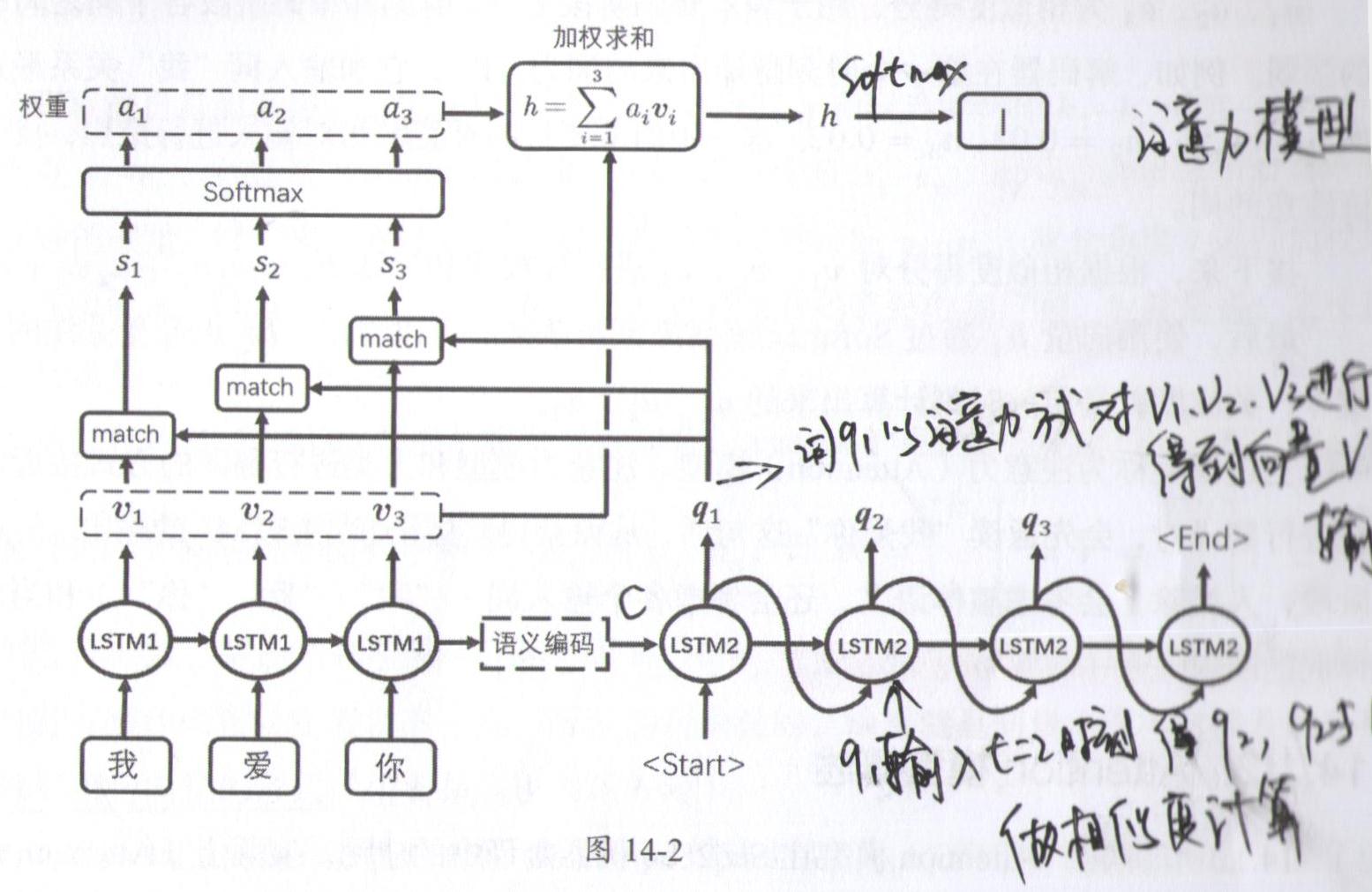
编码阶段和前面的模型没有区别,保留了各时刻LSTM1的输出向量v。解码阶段,模型预测的方法有了变化,比如在t=1时刻,预测方式为:
1.计算LSTM2在t=1时刻的输出q1,以及v1、v2、v3的相似度,即对q1和v1、v2、v3求内积:
s1=<q1,v1>
s2=<q1,v2>
s3=<q1,v3>
2.s1、s2、s3可以理解为未归一化的相似度,通过softmax函数对其归一化,得到a1、a2、a3。满足a1+a2+a3=1。a1、a2、a3就是相似度得分attention score。用于表示解码阶段t=1时刻和编码阶段各个词之间的关系。
例如解码器在第一个时刻,翻译的词是“I”,它和编码阶段的“我”这个词关系最近,
a
我
a_我
a我的分数最高(比如0.95)。由此达到让输出对输入进行聚焦的能力,找到此时刻解码时最该注意的词,这就是注意力机制。比起循环神经网络有更好的效果。
(attention score只表示注意力强度,是一个标量,一个系数,不是向量,不含有上下文信息,所以还不是最终输出结果。在此回答一些小伙伴的疑问)
3.根据相似度得分对v1、v2、v3进行加权求和,即
h
1
=
a
1
v
1
+
a
2
v
2
+
a
3
v
3
h_{1}=a_{1}v_{1}+a_{2}v_{2}+a_{3}v_{3}
h1=a1v1+a2v2+a3v3。
4.向量h1经过softmax函数来预测单词“I”。可以看出,此时的h1由最受关注的向量
v
我
v_我
v我主导。因为
a
我
a_我
a我最高。
上述模型就是注意力(Attention)模型)(这里没有用Self-Attention代替LSTM,主要还是讲attention机制是基于什么原因引出的。好的建议可以反馈给我)。(此处的模型没有key向量,是做了简化,即向量 K = V K=V K=V)
注意力模型和人类翻译的行为更为相似。人类进行翻译时,会先通读“我爱你”这句话,从而获得整体语义(LSTM1的输出C)。而在翻译阶段,除了考虑整体语义,还会考虑各个输入词(“我”、“爱”、“你”)和当前待翻译词之间的映射关系(权重a1、a2、a3来聚焦注意力)
一个注意力模型不同于经典的(seq2seq)模型,主要体现在 2 个方面:
1.编码器会把更多的数据传递给解码器。编码器把所有时间步的 hidden state(隐藏层状态)传递给解码器,而非只传递最后一个 hidden state。
2.解码器在产生输出之前,做了一个额外的处理。把注意力集中在与该时间步相关的输入部分:
a. 查看所有接收到的编码器的 hidden state(隐藏层状态)。其中,编码器中每个 hidden state(隐藏层状态)都对应到输入句子中一个单词。
b. 给每个 hidden state(隐藏层状态)一个分数(attention score)。
c. 将每个 hidden state(隐藏层状态)乘以经过 softmax 的对应的分数,分数的高低代表了注意力的强度。分数更大的hidden state更会被关注。
Tips:上面计算相似度s=<q,k>时,s要除以
(
d
k
e
y
)
\\sqrt(d_{key})
(dkey)(Key 向量的长度)。原因是:
求相似度时,如果特征维度过高(如词向量embedding维度),就会导致计算出来的相似度s过大。s值的过大会导致归一化函数softmax饱和(softmax在s值很大的区域输出几乎不变化)使得归一化后计算出来的结果a要么趋近于1要么趋近于0。即加权求和退化成胜者全拿,则解码时只关注注意力最高的(attention模型还是希望别的词也有权重)而且softmax函数的饱和区导数趋近于0,梯度消失。所以对公式s=<q,k>进行优化:
s
=
<
q
,
k
>
d
k
e
y
s=\\frac{<q,k>}{\\sqrt{d_{key}}}
s=dkey<q,k>
q和k求内积,所以其实key和q的向量长度一样。
2.4 从机器翻译推广到attention的一般模式
(本来不想写的,想到一个问题,还是把这节补了)
Attention不止是用来做机器翻译,甚至是不止用在NLP领域。换一个更一般点的例子,来说明Attention的一般模式。
比如有一个场景是家长带小孩取玩具店买玩具,用模型预测最后玩具是否会被购买。每个玩具有两类特征,1-形状颜色功能等,用来吸引孩子;第二类特征是加个、安全、益智性等,用来决定家长是否购买。
假设孩子喜好用特征向量q表示,玩具第一类特征用向量k表示,第二类特征用向量v表示,模型结果如下:
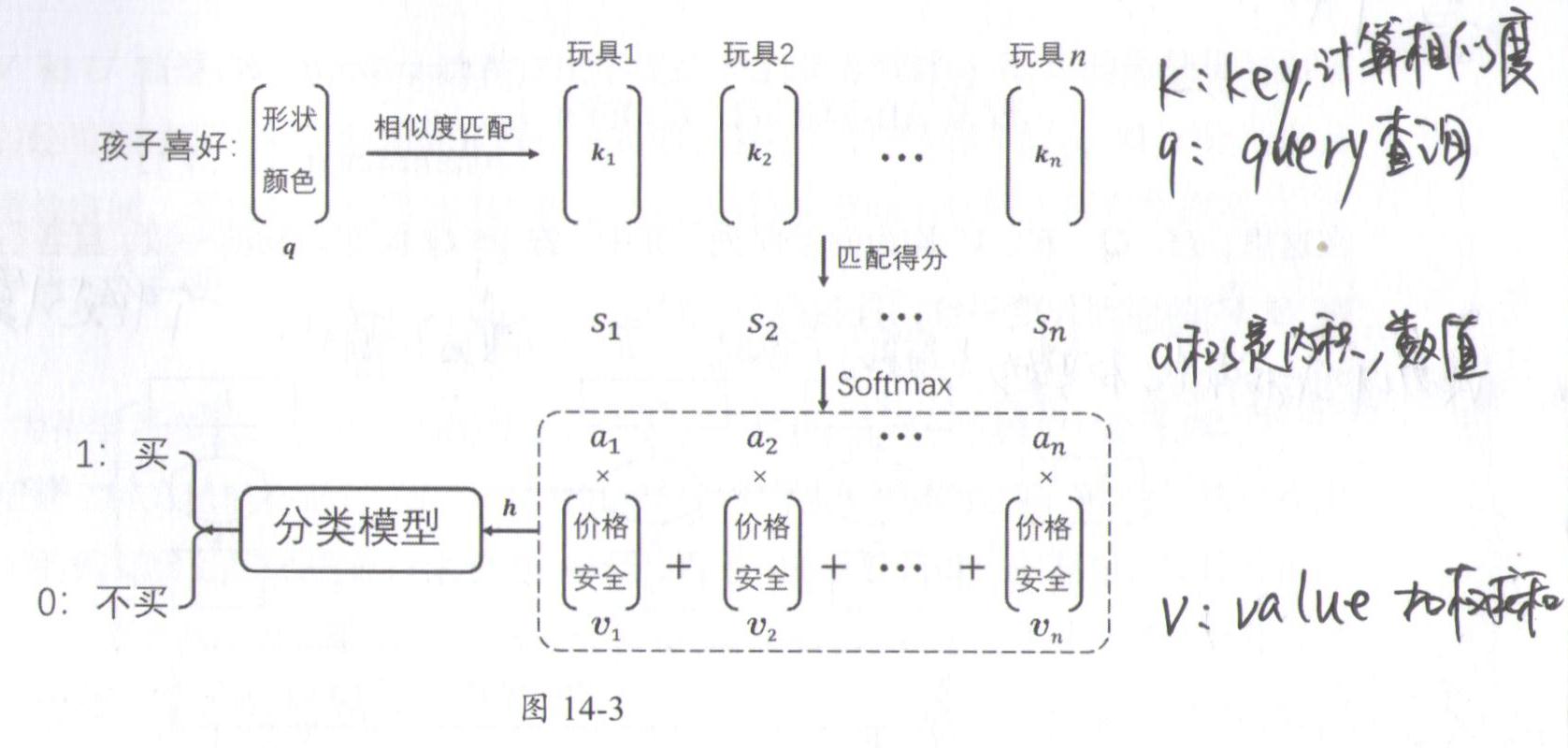
首先计算q和k的相似度
s
1
−
s
n
s_{1}-s_{n}
s1−sn,并归一化到
a
1
−
a
n
a_{1}-a_{n}
a1−an,a反映了孩子对玩具的喜好程度(权重)。接下来a对特征v进行加权求和(家长角度考虑),得到向量h。最后家长是否购买玩具是由向量h决定的。
上述过程就是Attention的标准操作流程。Attention模型三要素是
q
、
K
、
V
q、K、 V
q、K、V。
K
、
V
K、 V
K、V矩阵分别对应向量序列
k
1
k_1
k1到
k
n
k_n
kn和
v
1
v_1
v1到
v
n
v_n
vn。由于中间涉及到加权求和,所以这两个序列长度一致,而且元素都是对应的。即
k
j
k_j
kj对应
v
j
v_j
vj。但是k和v分别表示两类特征,所以向量长度可以不一致。
为了运算方便,可以将Attention操作计算为:
h
=
A
t
t
e
n
t
i
o
n
(
q
、
K
、
V
)
h=Attention(q、K、 V)
h=Attention(q、K、V)。q也可以是一个向量序列Q(对应机器翻译中输入多个单词),此时输出也是一个向量序列H。Attention通用标准公式为:
H
=
A
t
t
e
n
t
i
o
n
(
Q
,
K
,
V
)
=
[
A
t
t
e
n
t
i
o
n
(
q
1
,
K
,
V
)
.
.
.
A
t
t
e
n
t
i
o
n
(
q
m
,
K
,
V
)
]
H=Attention(Q,K,V)=\\begin{bmatrix} Attention(q_{1},K,V)\\\\ ...\\\\ Attention(q_{m},K,V)\\end{bmatrix}
H=Attention(Q,K,V)=⎣⎡Attention(q1,K,V)...Attention(qm,K,V)⎦⎤
这里,
Q
、
K
、
V
、
H
Q、K、 V、H
Q、K、V、H均为矩阵(向量序列)。其中,
H
H
H和
Q
Q
Q序列长度一致,各行一一对应(一个输入对应一个输出),
K
K
K和
V
V
V序列长度一致,各行一一对应。
2.5 Attention模型的改进形式
Attention模型计算相似度,除了直接求内积<q,k>,还有很多其它形式。
s
=
A
T
T
a
n
h
(
q
W
+
k
U
)
s=A^{T}Tanh(qW+kU)
s=ATTanh(qW+kU)
多层感知机,
A
、
W
、
U
A 、 W 、 U
A、W、U都是待学习参数。这种方法不仅避开了求内积时 q 和 k 的向量长度必须一致的限制,还可以进行不同空间的向量匹配。例如,在进行图文匹配时, q 和 k 分别来自文字空间和图像空间,可以先分别通过
W
、
U
W 、 U
W、U将它们转换至同一空间,再求相似度。
上面式子中,
W
、
U
W 、U
W、U是矩阵参数,相乘后可以使q和k的维度一致。比如机器翻译中,中文一词多义情况比较多,中文向量q维度可以设置长一点,英文中一词多义少,k的维度可以设置短一点。
q
W
+
k
U
qW+kU