为什么新一代的RustGo等编程语言都如此讨厌if-elseSwitch结构
Posted CSDN资讯
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了为什么新一代的RustGo等编程语言都如此讨厌if-elseSwitch结构相关的知识,希望对你有一定的参考价值。

作者 | 马超
出品 | CSDN(ID:CSDNnews)
今天我们还是继续来聊高并发的话题,我们知道Swich及if-else分支是一个非常有用的语法,这是一个可以回溯到上世纪的Pascal、C等经典语言的分支结构,主要的作用就是判断变量的取值并将程序代码送入不同的分支,这种设计在当时的环境下非常的精妙,但是在当前最新的CPU环境下,却会带来很多意想不到的坑。

Swich的坑,环境一变效率就差远了
由于Rust并没有Switch了,因此以下代码就暂用Go语言来演示了。我们先来看以下这段代码:
package main
import (
"fmt"
"math/rand"
//"sync"
"time"
)
func main() {
now := time.Now().UnixNano()
count := []int{0, 0, 0, 0, 0, 0}
for i := 0; i < 100000; i++ {
random := rand.Intn(100)
switch random {
case 1:
count[1]++
case 2:
count[2]++
case 3:
count[3]++
case 4:
count[4]++
case 5:
count[5]++
default:
count[0]++
}
}
fmt.Println(time.Now().UnixNano() - now)
fmt.Println(count)
}
它的运行结果如下:
[root@ecs-a4d3 hello_world]# time ./test1
288084
[99507 86 108 106 96 97]
real 0m0.004s
user 0m0.003s
sys 0m0.001s
我们再稍微把Random的范围由100改为5,
package main
import (
"fmt"
"math/rand"
//"sync
"time"
)
func main() {
now := time.Now().UnixNano()
count := []int{0, 0, 0, 0, 0, 0}
for i := 0; i < 100000; i++ {
random := rand.Intn(1000)
switch random {
case 1:
count[1]++
case 2
count[2]++
case 3:
count[3]++
case 4:
count[4]++
case 5:
count[5]++
default:
count[0]++
}
}
fmt.Println(time.Now().UnixNano() - now)
fmt.Println(count)
}
上述的代码运行结果如下:
[root@ecs-a4d3 hello_world]# time ./test1
4365712
[20184 20357 19922 19897 19640 0]
real 0m0.006s
user 0m0.004s
sys 0m0.002s
可以看到这两段程序的运行时间相差了30%多,这个结果真的是细思极恐,因为也就是实际代码执行逻辑完全没有任何变化 ,只是变量取值范围有所调整,就会使程序的运行效率大为不同,也就是说当系统遭遇到某些极端情况时,同样的程序所需要的运行时间却有天壤之别,要解释这个问题要从指令流水线说起。

CPU流水线与指令预测
我们知道CPU的每个动作都需要用晶体震荡而触发,以加法ADD指令为例,想完成这个执行指令需要取指、译码、取操作数、执行以及取操作结果等若干步骤,而每个步骤都需要一次晶体震荡才能推进,因此在流水线技术出现之前执行一条指令至少需要5到6次晶体震荡周期才能完成。

为了缩短指令执行的晶体震荡周期,芯片设计人员参考了工厂流水线机制的提出了指令流水线的想法,由于取指、译码这些模块其实在芯片内部都是独立的,完成可以在同一时刻并发执行,那么只要将多条指令的不同步骤放在同一时刻执行,比如指令1取指,指令2译码,指令3取操作数等等,就可以大幅提高CPU执行效率:
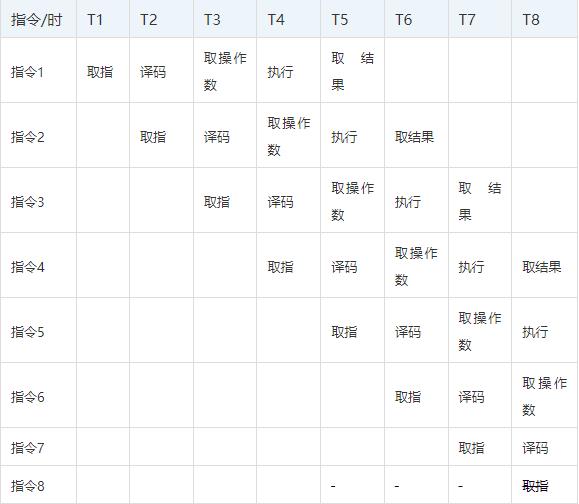
以上图流水线为例 ,在T5时刻之前指令流水线以每周期一条的速度不断建立,在T5时代以后每个震荡周期,都可以有一条指令取结果,平均每条指令就只需要一个震荡周期就可以完成。这种流水线设计也就大幅提升了CPU的运算速度。
但是CPU流水线高度依赖指指令预测技术,假如在流水线上指令5本是不该执行的,但却在T6时刻已经拿到指令1的结果时才发现这个预测失败,那么指令5在流水线上将会化为无效的气泡,如果指令6到8全部和指令5有强关联而一并失效的话,那么整个流水线都需要重新建立。
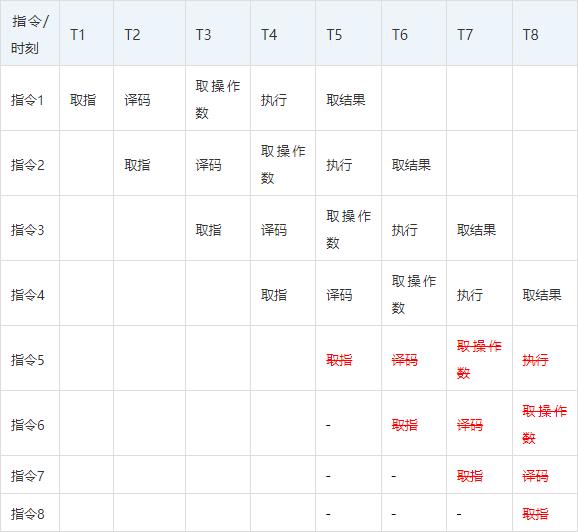
会是编译器隐式likely优化的原因吗?因此为了适应指令流水线的机制,不少对于性能要求极高的程序中,都会将不太会执行到的分支加上unlikely修饰符,从而引导CPU不要预测这个分支上的代码以提升效率,不过这个机制在本例中不太适用,会objdump –S查看原始代码也并没有发现,default前面加上了likely优化。
default:
count[0]++
49a0f9: 48 8b 44 24 60 mov 0x60(%rsp),%rax
49a0fe: 48 ff 00 incq (%rax)
49a101: eb 84 jmp 49a087 <main.main+0xa7>
case 3:
49a103: 48 83 f8 03 cmp $0x3,%rax
49a107: 75 0e jne 49a117 <main.main+0x137>
count[3]++
49a109: 48 8b 44 24 60 mov 0x60(%rsp),%rax
49a10e: 48 ff 40 18 incq 0x18(%rax)
49a112: e9 70 ff ff ff jmpq 49a087 <main.main+0xa7>
case 4:
49a117: 48 83 f8 04 cmp $0x4,%rax
49a11b: 75 0e jne 49a12b <main.main+0x14b>
所以可以看出这个效率差完全是CPU指令预测造成的。也就是说CPU自带的机制就是会对于执行概比较高的分支给出更多的预测倾斜。

Rust的if else也是一样的坑
当然我们说Switch不好也就不是说if else就避免了这个问题,根据指令流水线的原理,if else在处理分支时情况也一样,因此Rust也不太推荐if else的写法,以Rust为例如下:
use rand::Rng;
fn main() {
let mut rng = rand::thread_rng();
let mut arr = [0, 0, 0, 0, 0,0];
//println!("Integer: {}", arr[random]);
for i in 0..1000000 {
let mut random =rng.gen_range(0,5);
if random==0{
arr[0]=arr[0]+1;
}
else if random==1{
arr[1]=arr[1]+1;
}
else if random==2{
arr[2]=arr[2]+1;
}
else if random==3{
arr[3]=arr[3]+1;
}
else if random==4{
arr[4]=arr[4]+1;
}
else{
arr[5]=arr[5]+1;
}
}
println!("{},{},{},{},{},{}", arr[0], arr[1], arr[2], arr[3], arr[4], arr[5]);
}
将随机数的取值范围调整一下
let mut random =rng.gen_range(0,100);
可以观察到这两段程序运行的时间也要相差近40%,这样的结果也深刻说明了一个问题,这个例子其实模拟的是一个极端状态,也就是某一个变量取值突然从0-100变成了0-5那么程序的运行效率可能就会有极大的改变,这个推论就是一旦系统运行在某一个极端状态,比如错误占比过高或者其它极端场景,那么正常情况下的压力测试结果也许就完全不能说明问题了。

哈希表会是个好的选择吗?
我们上文也介绍过哈希表也就是字典,可以快速将键值key转化为值value,从某种程度上讲可以替换switch的作用,按照第一段代码的逻辑,用哈希表重写的方案如下:
package main
import (
"fmt"
"math/rand"
"time"
)
func main() {
now := time.Now().UnixNano()
//count := []int{0, 0, 0, 0, 0, 0}
count := map[int]int{0: 0, 1: 0, 2: 0, 3: 0, 4: 0, 5: 0}
for i := 0; i < 100000; i++ {
random := rand.Intn(5)
count[random]++
}
fmt.Println(time.Now().UnixNano() - now)
fmt.Println(count)
}
不过这段代码的运行结果如下:
[root@ecs-a4d3 hello_world]# time ./test2
5864780
map[0:20184 1:20357 2:19922 3:19897 4:19640 5:0]
real 0m0.008s
user 0m0.007s
sys 0m0.001s
虽然这个版本性能比较稳定,但却比之前的Switch方案最慢的情况还慢60%,原因也很简单我们之前介绍过哈希表也叫散列表,它的各个元素在内存中的而已并不连续,因此高速缓存对这种数据结构的加速作用有限。


☞iPhone13系列预计5499起;蔚来回应31岁企业家“自动驾驶”车祸去世;小米取消MIX4防丢失模式无卡联网服务|极客头条☞1.2亿次下载,近3万Star的开源项目是为何会“死”掉?☞免费的开源软件那么“香”,为何他们宁愿花钱去买软件?
以上是关于为什么新一代的RustGo等编程语言都如此讨厌if-elseSwitch结构的主要内容,如果未能解决你的问题,请参考以下文章