iOS底层探索之多线程—GCD源码分析(函数的同步性异步性单例)
Posted 卡卡西Sensei
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了iOS底层探索之多线程—GCD源码分析(函数的同步性异步性单例)相关的知识,希望对你有一定的参考价值。
回顾
在上篇博客已经对GCD的sync同步函数产生死锁的情况,进行了底层的源码探索分析,那么本篇博客继续源码的探索分析!

iOS底层探索之多线程(六)—GCD源码分析(sync 同步函数、async 异步函数)
1. 全局并发队列+同步函数
dq->dq_width == 1为串行队列,那么并发队列该怎么走呢?
如下图,走的是下面的框框中流程

但是这么多的分支,到底是走的哪一个呢?通过对_dispatch_sync_f_slow、 _dispatch_sync_recurse 、_dispatch_introspection_sync_begin 、_dispatch_sync_invoke_and_complete方法下符号断点,进行跟踪调试。
- 符号断点调试
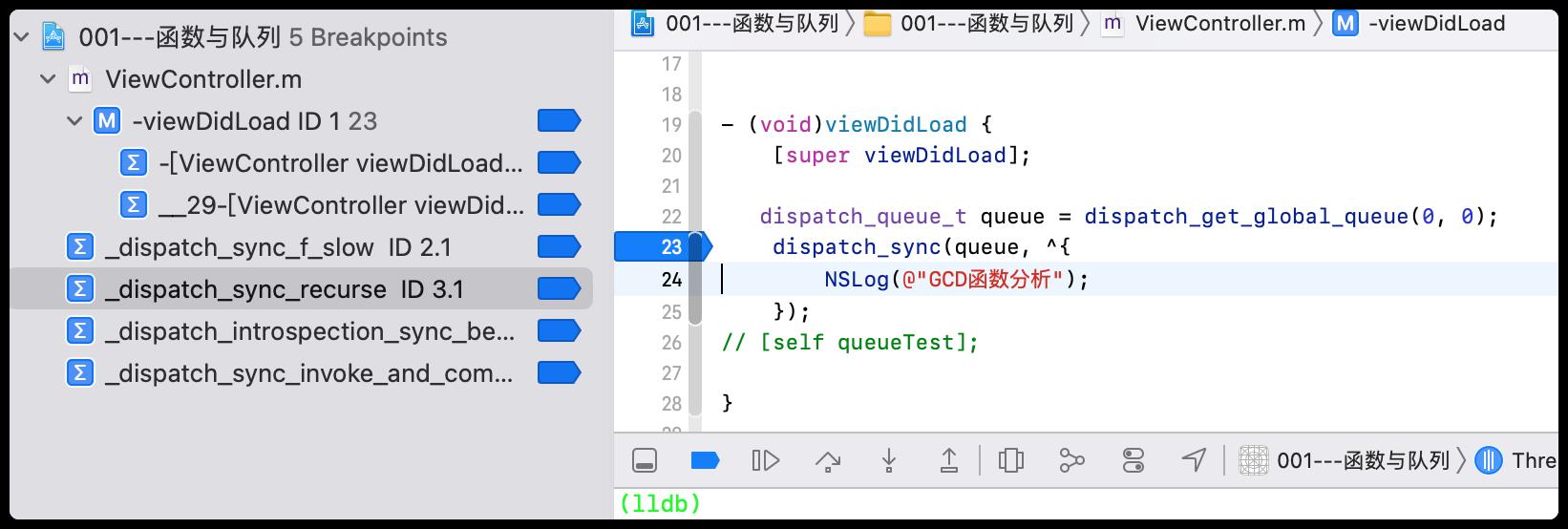
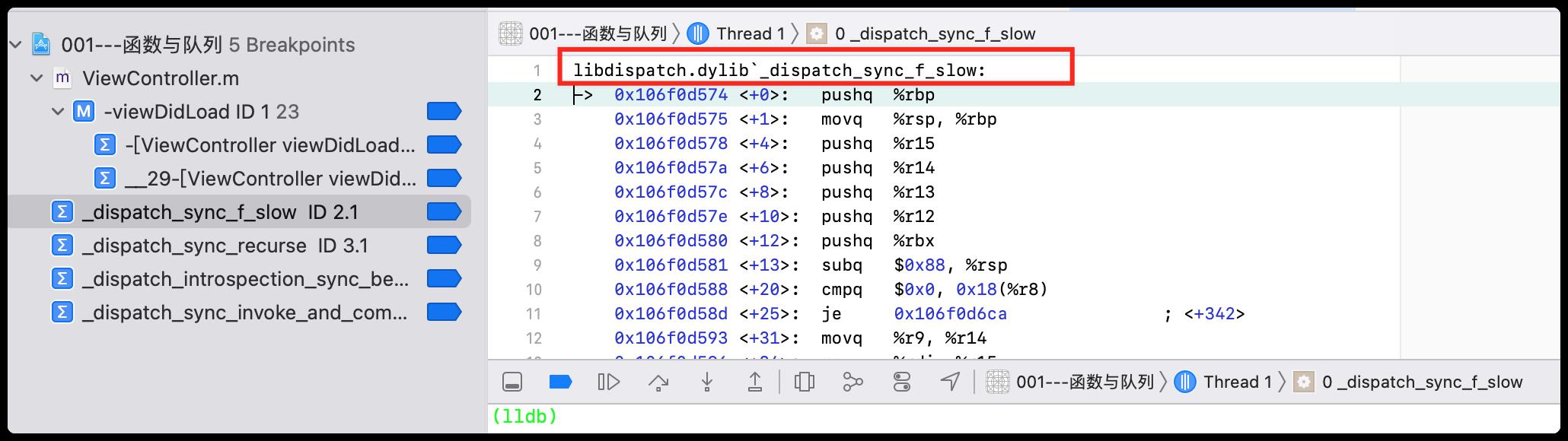
通过下符号断点跟踪,发现走了_dispatch_sync_f_slow,如下图所示:
通过阅读源码,发现一个有意思的事情,就是_dispatch_sync_invoke_and_complete方法

- _dispatch_sync_invoke_and_complete

在这个_dispatch_sync_invoke_and_complete方法的第三个参数是func也是需要执行的任务,但是 func的后面的整体也是一个参数,也就是DISPATCH_TRACE_ARG( _dispatch_trace_item_sync_push_pop(dq, ctxt, func, dc_flags)) 整体为一个参数,这就有意思了,中间居然没有逗号分隔开。老铁,你这很特别啊!够长的啊!
那么去DISPATCH_TRACE_ARG定义看看

在DISPATCH_TRACE_ARG的宏定义里面,你们有没有发现,这里居然把逗号放在了里面,好家伙,宏定义里面还可以这么玩,苹果工程师还真有意思哈!
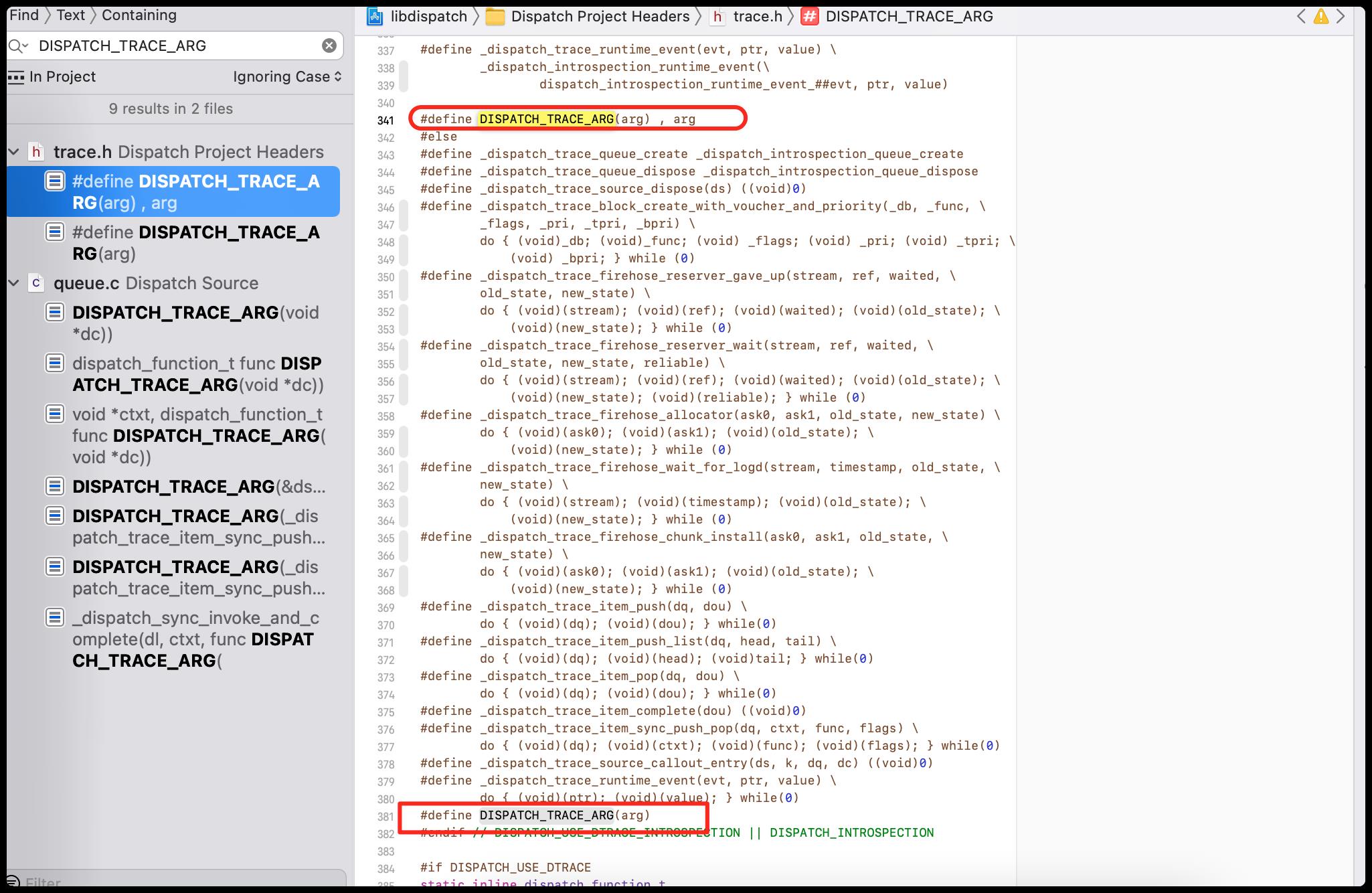
通过全局的搜索,发现这个宏定义有两处,一个有逗号,一个没有逗号,这就是根据不同的条件,进行设置,相当于是一个可选的参数,这一波操作又是非常的细节了!
既然下符合断点会走_dispatch_sync_f_slow方法,现在就去看看这个方法
- _dispatch_sync_f_slow
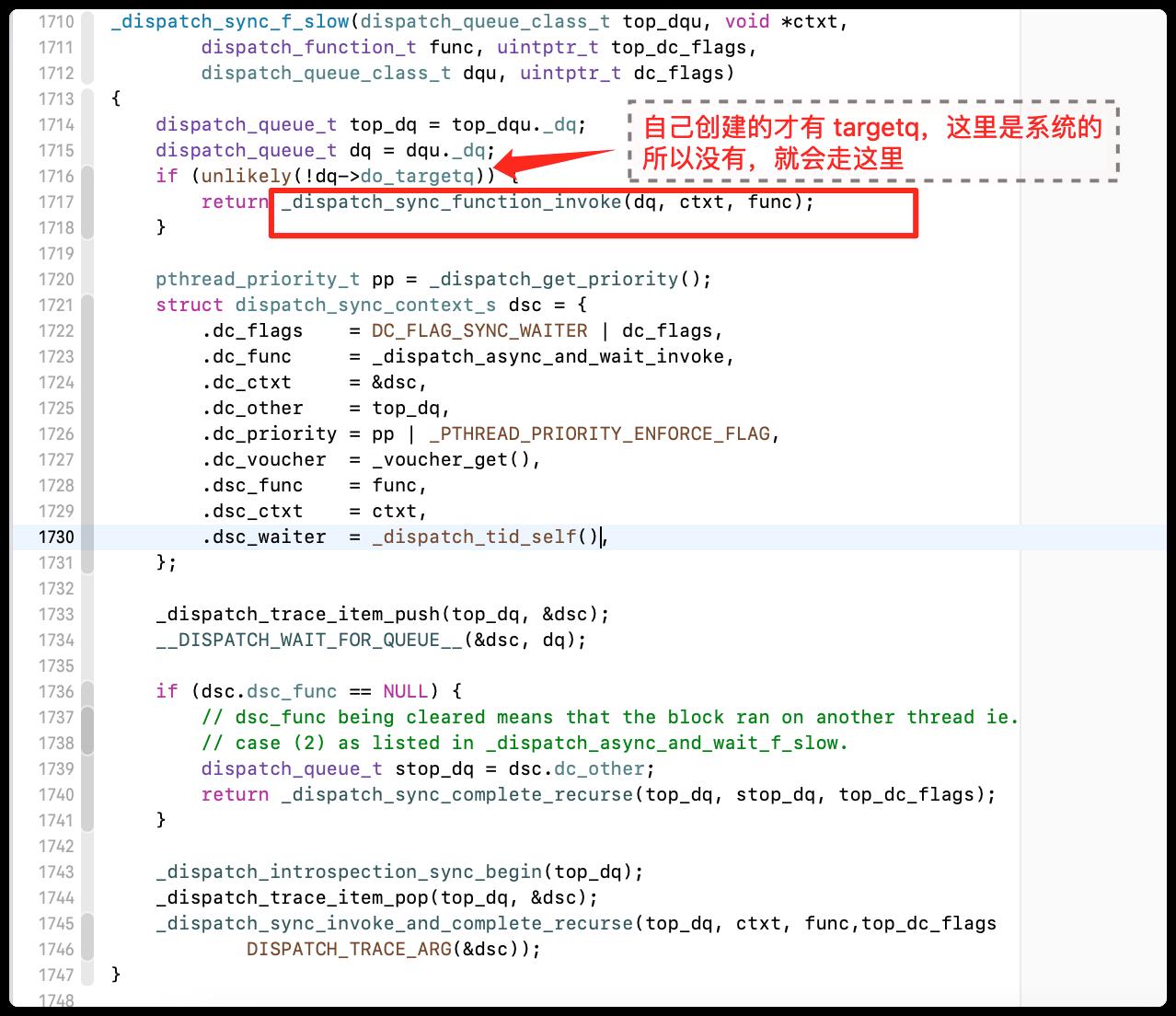
这里又是很多的分支,又通过下符合断点,发现走的是_dispatch_sync_function_invoke方法里面
- _dispatch_sync_function_invoke
static void
_dispatch_sync_function_invoke(dispatch_queue_class_t dq, void *ctxt,
dispatch_function_t func)
{
_dispatch_sync_function_invoke_inline(dq, ctxt, func);
}
- _dispatch_sync_function_invoke_inline
static inline void
_dispatch_sync_function_invoke_inline(dispatch_queue_class_t dq, void *ctxt,
dispatch_function_t func)
{
dispatch_thread_frame_s dtf;
_dispatch_thread_frame_push(&dtf, dq);
_dispatch_client_callout(ctxt, func);
_dispatch_perfmon_workitem_inc();
_dispatch_thread_frame_pop(&dtf);
}
push之后调用callout执行,最后再pop,所以可以同步的执行任务
2. 异步函数
dispatch_async异步函数的任务,是包装在 qos里面的,那么现在跟踪流程,去看看
- dispatch_async

- _dispatch_continuation_async
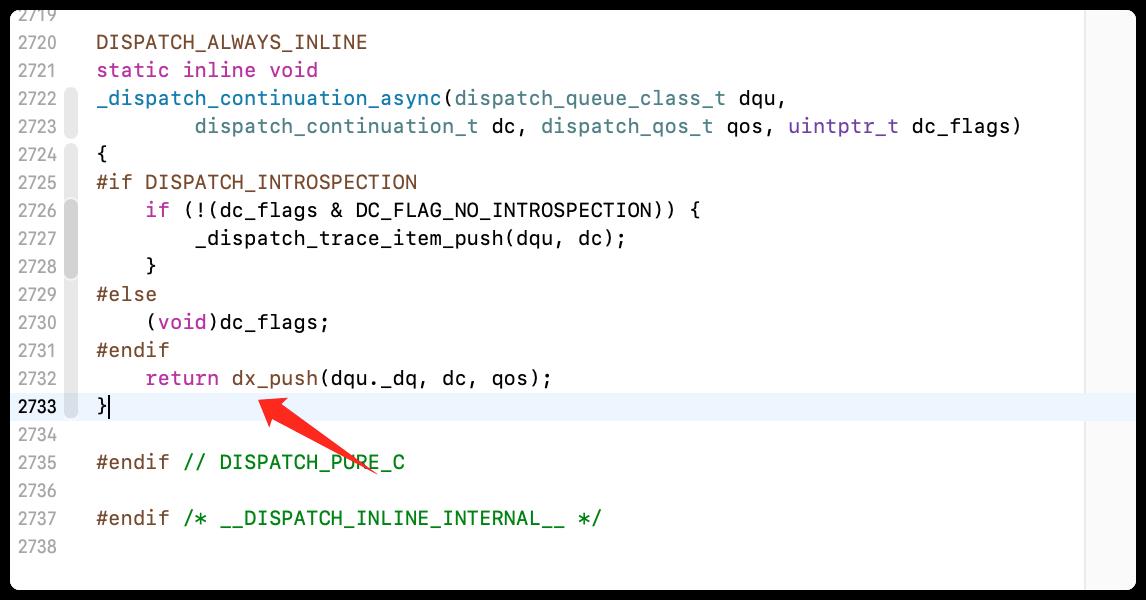
- dx_push

搜索dx_push调用的地方
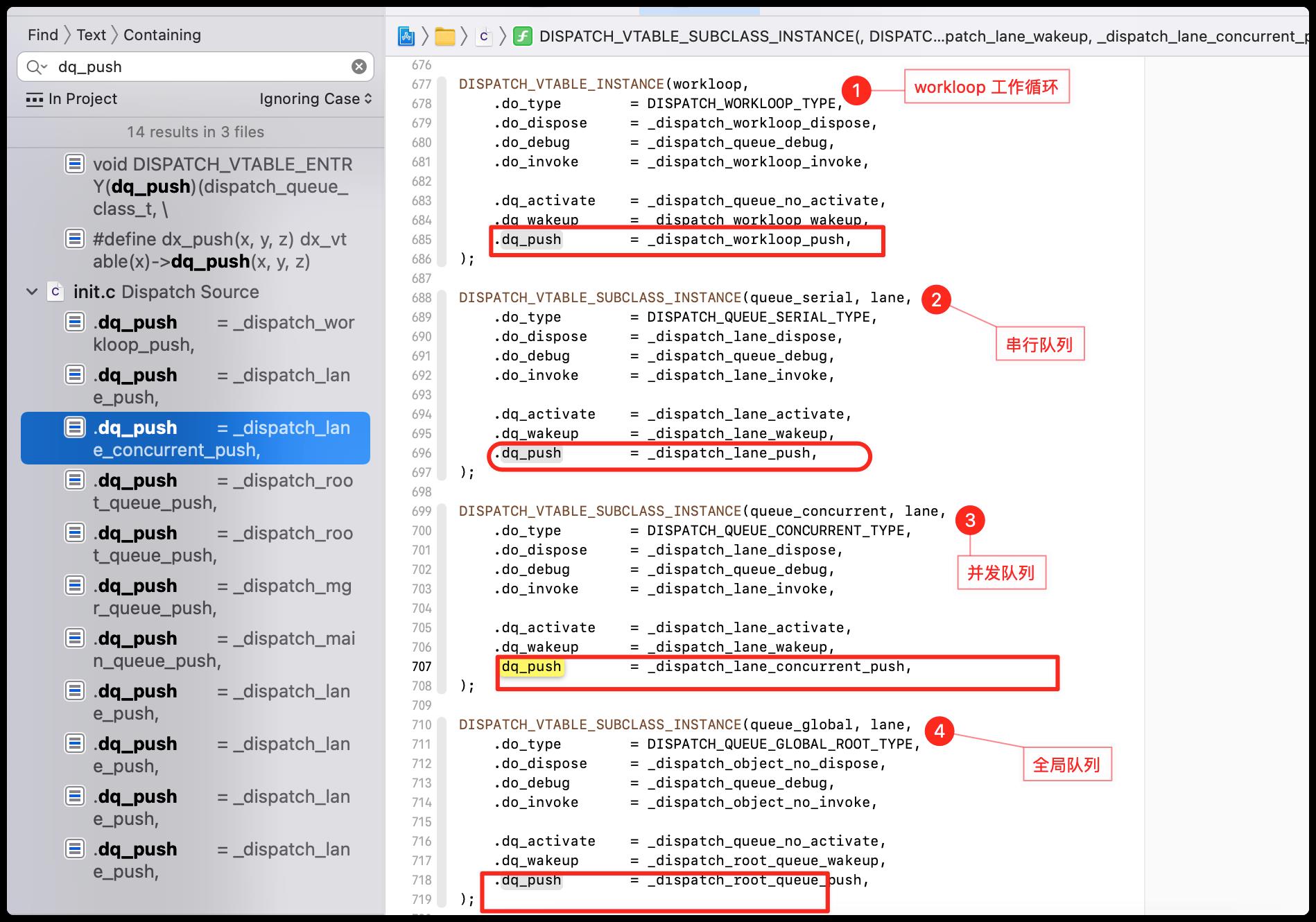
这里就先去看看并发队列里面的dq_push吧,
- _dispatch_lane_concurrent_push

这里if里面有对栅栏函数(_dispatch_object_is_barrier)的判断,栅栏函数这里就不分析了,后续的博客里面会分析的。
在_dispatch_lane_concurrent_push里面会去调用_dispatch_lane_push方法,在上面搜索dx_push的图里面,可以看到,在串行队列里面是直接调用了_dispatch_lane_push,也就是说串行和并发都会走这个方法。
- _dispatch_lane_push
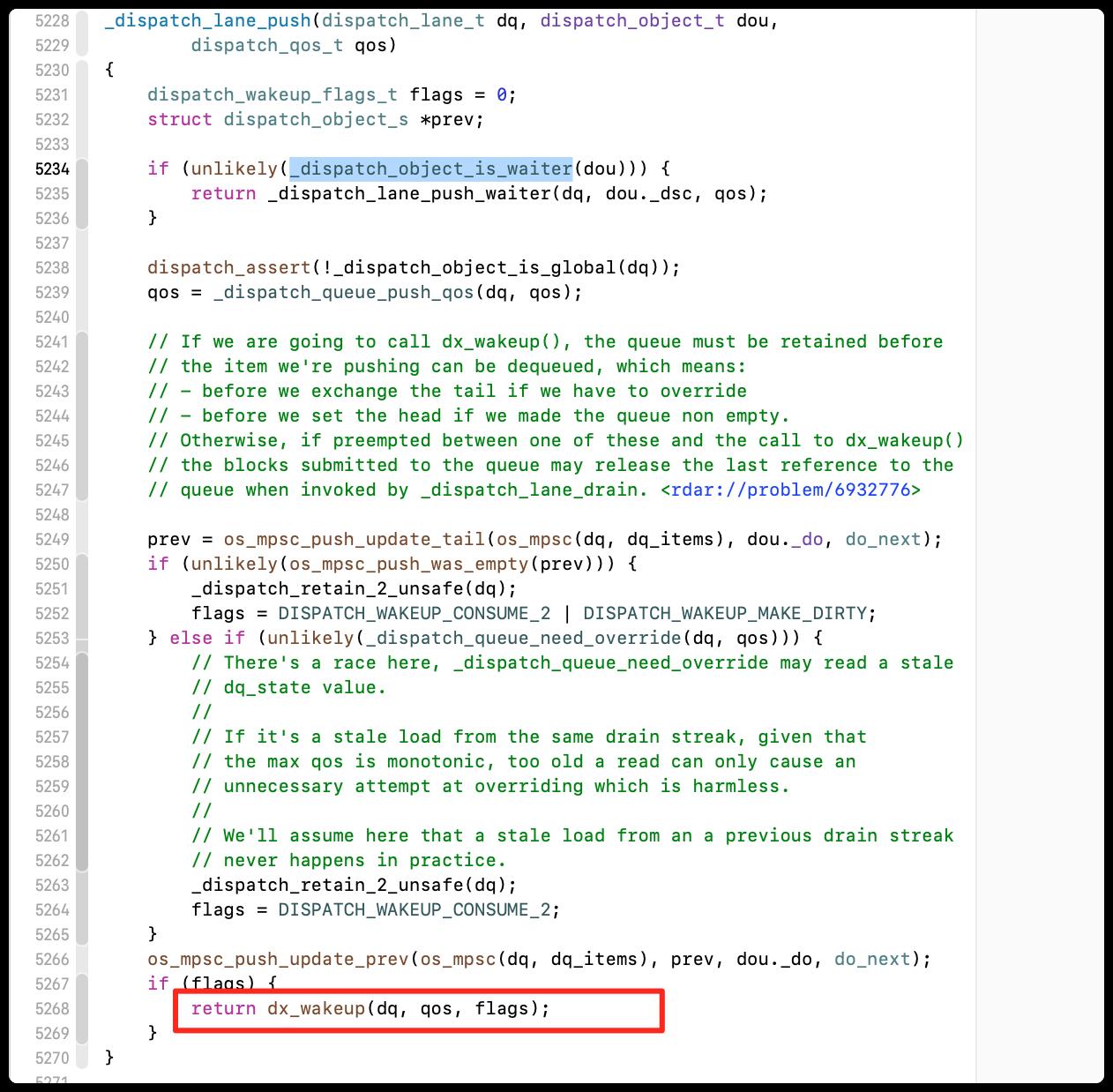
最后去调用dx_wakeup,再去搜索看看

dx_wakeup 是一个宏定义,看看dq_wakeup哪里调用了
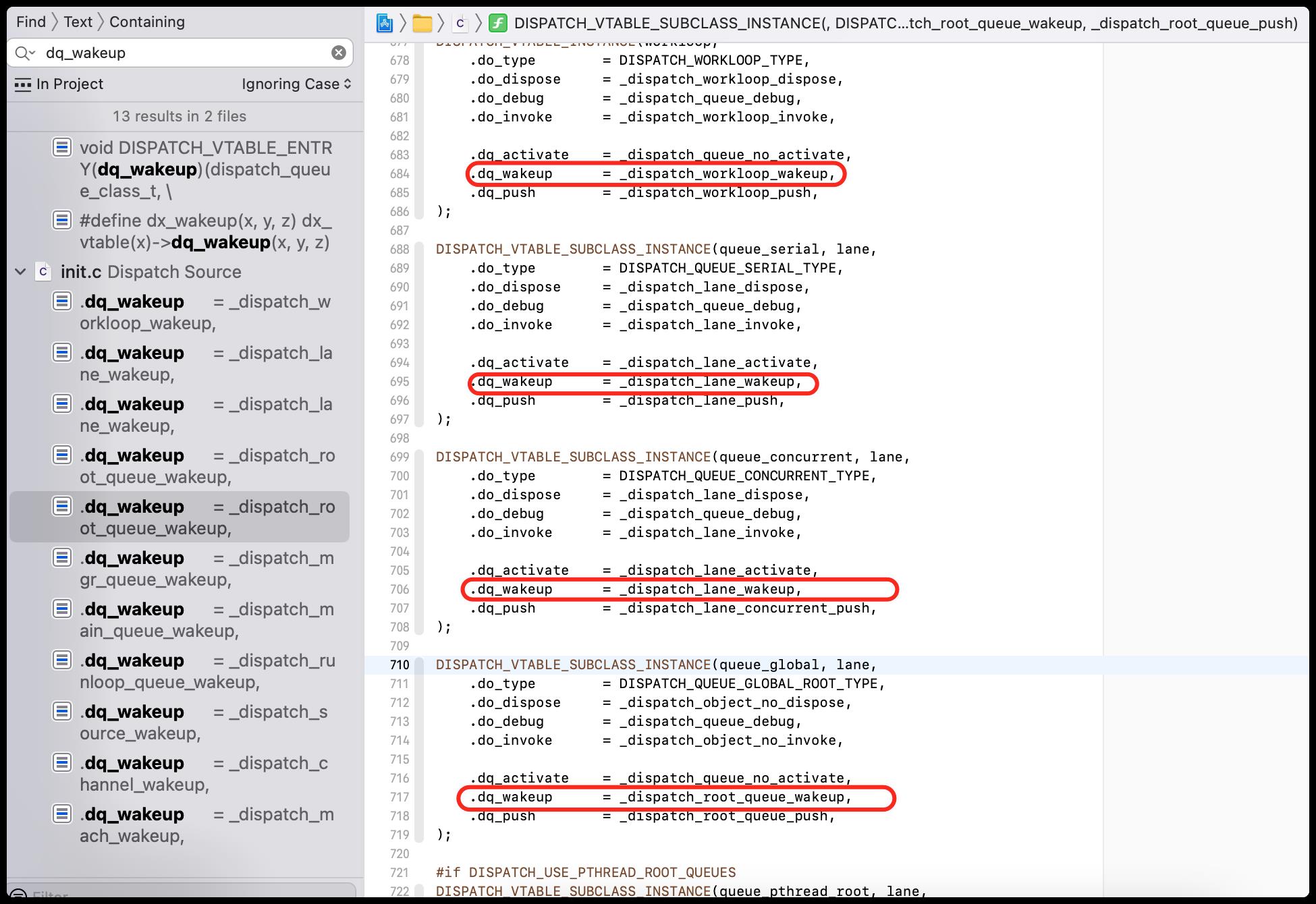
如上图可以发现,串行和并发都是_dispatch_lane_wakeup,全局的是_dispatch_root_queue_wakeup
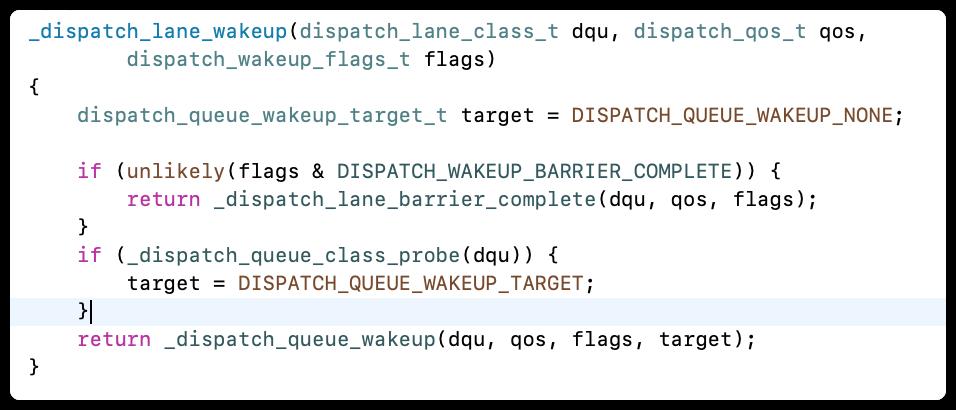
- _dispatch_queue_wakeup

通过下符合断点会走_dispatch_lane_class_barrier_complete

_dispatch_lane_class_barrier_complete里面循环递归一些,操作,还看到了一个系统的函数os_atomic_rmw_loop2o,在这个方法里面要么返回dx_wakeup或者做其他的一些处理。
全局并发队列会调用_dispatch_root_queue_push方法。通过下符号断点,跟踪源码,最终定位到一个重要的方法_dispatch_root_queue_poke_slow
dispatch_root_queue_push_inline(dispatch_queue_global_t dq,
dispatch_object_t _head, dispatch_object_t _tail, int n)
{
struct dispatch_object_s *hd = _head._do, *tl = _tail._do;
if (unlikely(os_mpsc_push_list(os_mpsc(dq, dq_items), hd, tl, do_next))) {
return _dispatch_root_queue_poke(dq, n, 0);
}
}
- _dispatch_root_queue_poke
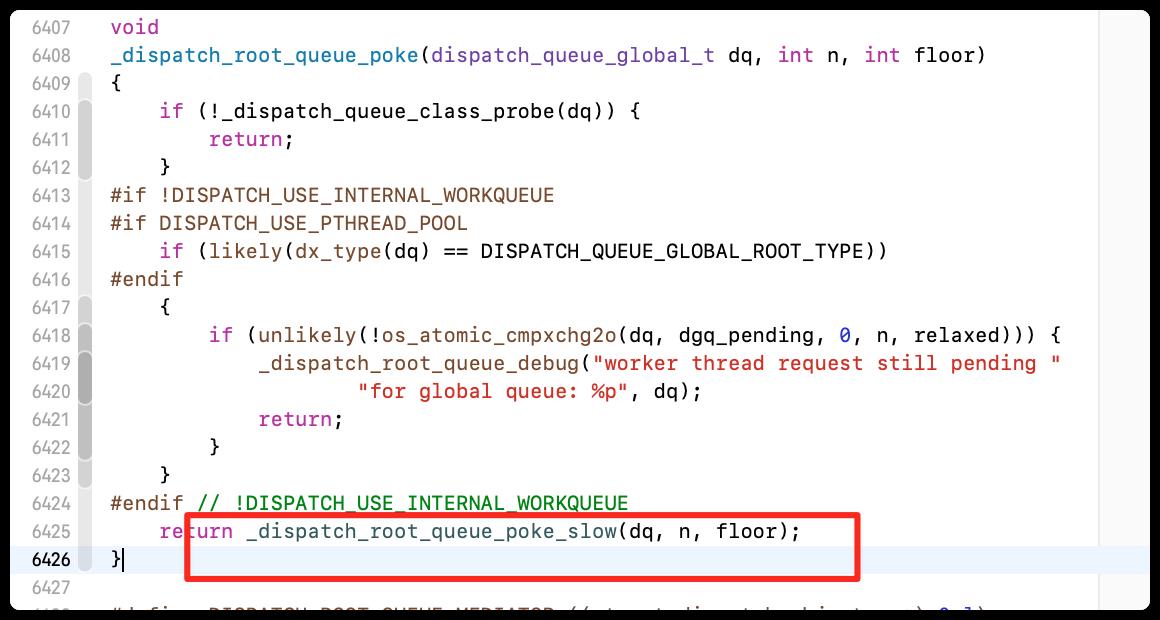
- _dispatch_root_queue_poke_slow

_dispatch_root_queues_init方法使用了单例。
static inline void
_dispatch_root_queues_init(void)
{
dispatch_once_f(&_dispatch_root_queues_pred, NULL,
_dispatch_root_queues_init_once);
}
在该方法中,采用单例的方式进行了线程池的初始化处理、工作队列的配置、工作队列的初始化等工作。同时这里有一个关键的设置,执行函数的设置,也就是将任务执行的函数被统一设置成了_dispatch_worker_thread2。见下图:

调用执行是通过workloop工作循环调用起来的,也就是说并不是及时调用的,而是通过os完成调用,说明异步调用的关键是在需要执行的时候能够获取对应的方法,进行异步处理,而同步函数是直接调用。
在上面的流程中_dispatch_root_queue_poke_slow方法,还没有继续分析,现在就去分析,如果是全局队列,此时会创建线程进行执行任务
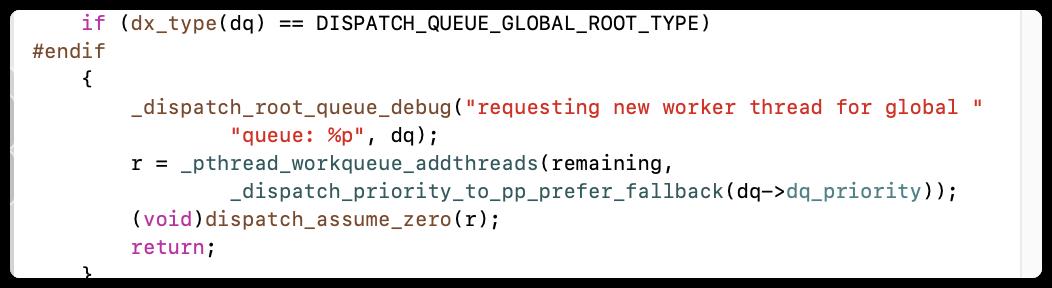
对线程池进行处理,从线程池中获取线程,执行任务,同时判断线程池的变化

remaining可以理解为当前可用线程数,当可用线程数等于0时,线程池已满pthread pool is full,直接return。底层通过pthread完成线程的开辟

就是_dispatch_worker_thread2是通过pthread完成oc_atmoic原子触发
那么我们的线程可以开辟多少线程条呢?
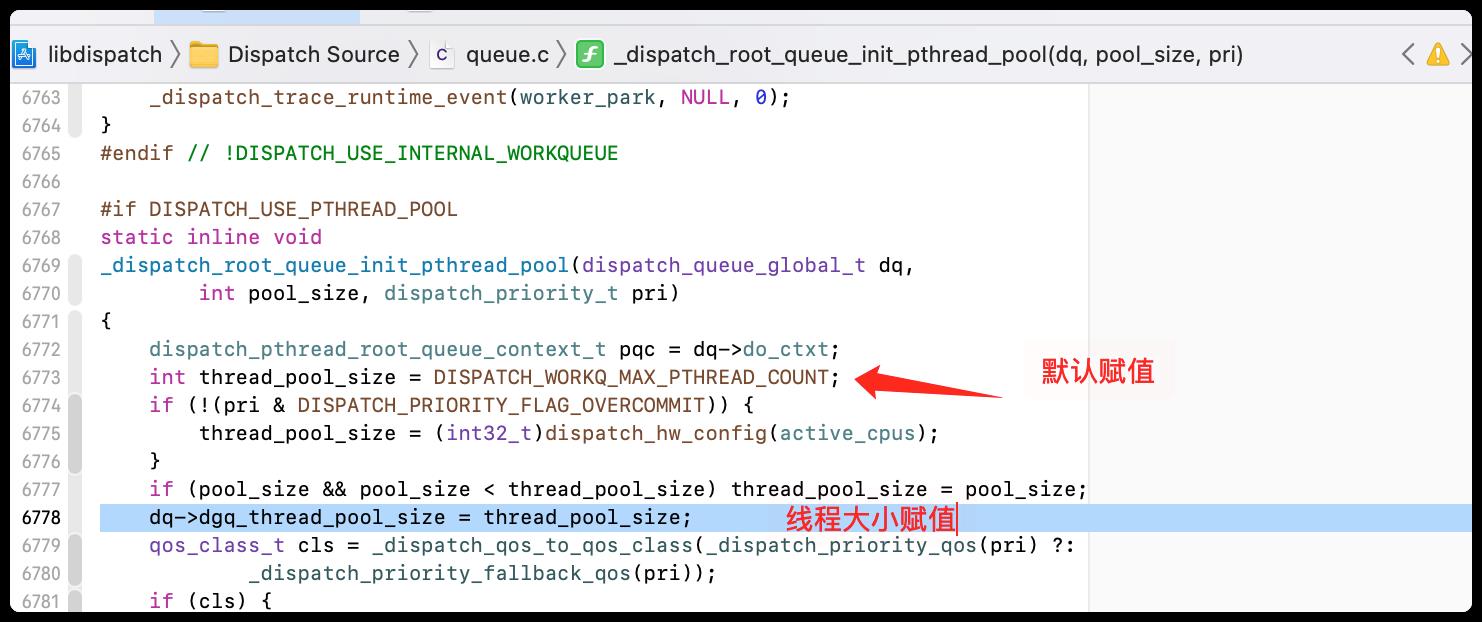
队列线程池的大小为:dgq_thread_pool_size。dgq_thread_pool_size = thread_pool_size ,默认大小如下:

255表示理论上线程池的最大数量。但是实际能开辟多少呢,这个不确定。在苹果官方完整Thread Management中,有相关的说明,辅助线程的最小允许堆栈大小为 16KB,并且堆栈大小必须是4KB 的倍数。见下图:

也就是说,一个辅助线程的栈空间是512KB,而一个线程所占用的最小空间是16KB,也就是说栈空间一定的情况下,开辟线程所需的内存越大,所能开辟的线程数就越小。针对一个4GB内存的ios真机来说,内存分为内核态和用户态,如果内核态全部用于创建线程,也就是1GB的空间,也就是说最多能开辟1024KB / 16KB个线程。当然这也只是一个理论值。
3. 单例
上面提到了单例,那么接下来就去分析一下单例
来看看简单的单例使用:
static dispatch_once_t token;
dispatch_once(&token, ^{
// 代码执行
});
- 单例的定义如下:

void
_dispatch_once(dispatch_once_t *predicate,
DISPATCH_NOESCAPE dispatch_block_t block)
{
if (DISPATCH_EXPECT(*predicate, ~0l) != ~0l) {
dispatch_once(predicate, block);
} else {
dispatch_compiler_barrier();
}
DISPATCH_COMPILER_CAN_ASSUME(*predicate == ~0l);
}
#undef dispatch_once
#define dispatch_once _dispatch_once
#endif
#endif // DISPATCH_ONCE_INLINE_FASTPATH
针对不同的情况作了一些特殊处理,比如栅栏函数等,这里只分析dispatch_once,进入dispatch_once实现

单例是只会执行一次,那么这里就是利用 val参数来进行控制的,接着去dispatch_once_f里面看看

对l的底层原子性进行关联,关联到uintptr_t v的一个变量,通过os_atomic_load从底层取出,关联到变量v上。如果v这个值等于DLOCK_ONCE_DONE,也就是已经处理过一次了,就会直接return返回
- _dispatch_once_gate_tryenter
static inline bool
_dispatch_once_gate_tryenter(dispatch_once_gate_t l)
{
return os_atomic_cmpxchg(&l->dgo_once, DLOCK_ONCE_UNLOCKED,
(uintptr_t)_dispatch_lock_value_for_self(), relaxed);
}
_dispatch_once_gate_tryenter里面是进行原子操作,就是锁的处理,如果之前没有执行过,原子处理会比较它状态,进行解锁,最终会返回一个bool值,多线程情况下,只有一个能够获取锁返回yes。
if (_dispatch_once_gate_tryenter(l)) {
return _dispatch_once_callout(l, ctxt, func);
}
通过_dispatch_lock_value_for_self上了一把锁,保证多线程安全。如果返回yes,就会执行_dispatch_once_callout方法,执行单例对应的任务,并对外广播
- _dispatch_once_callout
static void
_dispatch_once_callout(dispatch_once_gate_t l, void *ctxt,
dispatch_function_t func)
{
_dispatch_client_callout(ctxt, func);
_dispatch_once_gate_broadcast(l);
}
-
_dispatch_client_callout执行任务 -
_dispatch_once_gate_broadcast对外广播,标记为done -
_dispatch_once_gate_broadcast广播

将token通过原子比对,如果不是done,则设为done。同时对_dispatch_once_gate_tryenter方法中的锁进行处理。
- _dispatch_once_mark_done
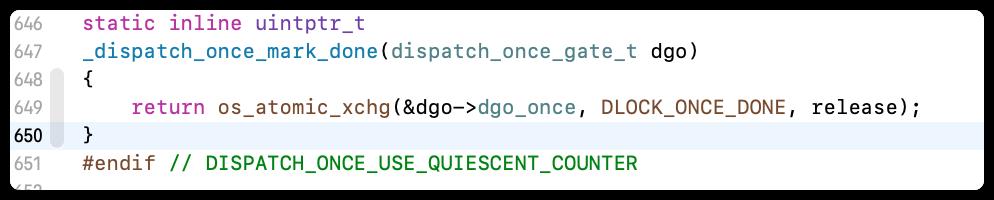
os_atomic_cmpxchg是一个宏定义,先进行比较再改变,先比较 dgo,在设置标记为DLOCK_ONCE_DONE也就是done
当token标记为done之后,就会直接返回,如存在多线程处理,没有获取锁的情况,就会调用_dispatch_once_wait,如下下:

_dispatch_once_wait,进行等待,这里开启了自旋锁,内部进行原子处理,在loop过程中,如果发现已经被其他线程设置once_done了,则会进行放弃处理

那么任务的执行交给谁了呢?

通过打印堆栈信息,发现是交给了下层的线程,通过一些包装,给了底层的pthread

这就可以说 GCD底层是封装了pthread,不管是iOS还是 Java都是封装了底层的通用线程机制pthread。
这里的执行是通过工作循环workloop,工作循环的调起受 OS(受 CPU调度执行的。)管控的,异步线程的异步体现在哪里呢?就是体现在是否可以获得,而不是立即执行,而同步函数是直接调用执行的,而这里并没有看到异步的直接调用执行。
更多内容持续更新
🌹 喜欢就点个赞吧👍🌹
🌹 觉得有收获的,可以来一波,收藏+关注,评论 + 转发,以免你下次找不到我😁🌹
🌹欢迎大家留言交流,批评指正,互相学习😁,提升自我🌹
以上是关于iOS底层探索之多线程—GCD源码分析(函数的同步性异步性单例)的主要内容,如果未能解决你的问题,请参考以下文章