谁来拯救存量SGX1平台?又一个内核特性合并的血泪史
Posted 阿里云云栖号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了谁来拯救存量SGX1平台?又一个内核特性合并的血泪史相关的知识,希望对你有一定的参考价值。
简介: 今天的故事主角,是一个被称为Flexible Launch Control的SGX平台特性。

前言
自从Intel内核开发人员Jarkko Sakkinen于2017年9月2日在intel-sgx-kernel-dev@lists.01.org邮件列表上发出v1版的SGX in-tree驱动以来,时间已经过去了3年多了。这期间这个驱动前前后后共修改了41个版本,终于在2020年11月13日,v41版本的补丁合入了5.11-rc1内核。Jarkko松了一口气,任务完成啦!不过,为什么合并一个普通的驱动模块会这么难?
事实上,由于SGX所代表的新的机密计算领域的特殊性,围绕着它的争议和讨论就从未停止过。甚至在最终的v41补丁中,也没能看到大佬们整齐划一的LGTM(社区黑话,Looks Good To Me的缩写,表示自己认可这个补丁),它依旧存在一些问题,同时还有人在不断提出修改建议。这不禁让人联想到另一个x86处理器特性FSGSBASE合入upstream时的命运多舛:后者的合入前后花了5年时间,甚至最后都不是Intel的人合入的(当然也不是AMD的人合入的😂,大家可以猜猜是谁)。
今天的故事主角,是一个被称为Flexible Launch Control(简称FLC)的SGX平台特性。对这个特性的争议,最终导致SGX in-tree驱动无法支持不具备FLC特性或关闭了FLC特性的所有SGX系统。大白话是啥意思呢?意思就是一批较早的支持Intel SGX的机器用Linux内核自带的官方驱动是无法加载和使用SGX的......纳尼!这个驱动竟然不向下兼容!哎,现在让我们先对FLC技术背景进行一个简单的介绍,然后再对其被社区抛弃的故事简单做个复盘,最后再给出我们的思考,以及我们的解决方案。
FLC的技术背景
友情提醒:想听故事不想了解技术细节的同学请直接跳到下一节。
在执行SGX EINIT指令初始化enclave的时候,被初始化的enclave必须通过Launch Control机制的检查,因此Launch Control是一种用于控制enclave能否启动的安全检查机制。
被初始化的enclave分为两类:Launch Enclave和普通enclave。Launch Enclave与普通的enclave的不同之处在于其SECS.ATTRIBUTES.EINITTOKEN_KEY == 1,即具有通过执行SGX EGETKEY指令派生出einit token key的权限。Einit token本质上是一个带有CMAC签名的token,其中的CMAC是Launch Enclave用einit token key生成的,意在对einit token本身提供完整性保护;在执行EINIT初始化普通enclave的时候,从Launch Enclave处返回的einit token需要作为输入参数的一部分,然后EINIT指令的微码会将einit token作为派生出einit token key的输入因子,最后用派生出的einit token key来验证输入的einit token中的CMAC,以确保einit token从生成到传给EINIT的过程中没有被篡改。
上面的流程中提到的einit token完整性检查适用于所有的普通enclave,而对于Launch Enclave,再执行EINIT初始化时有特殊处理。下面是在执行EINIT时完整的Launch Control流程:
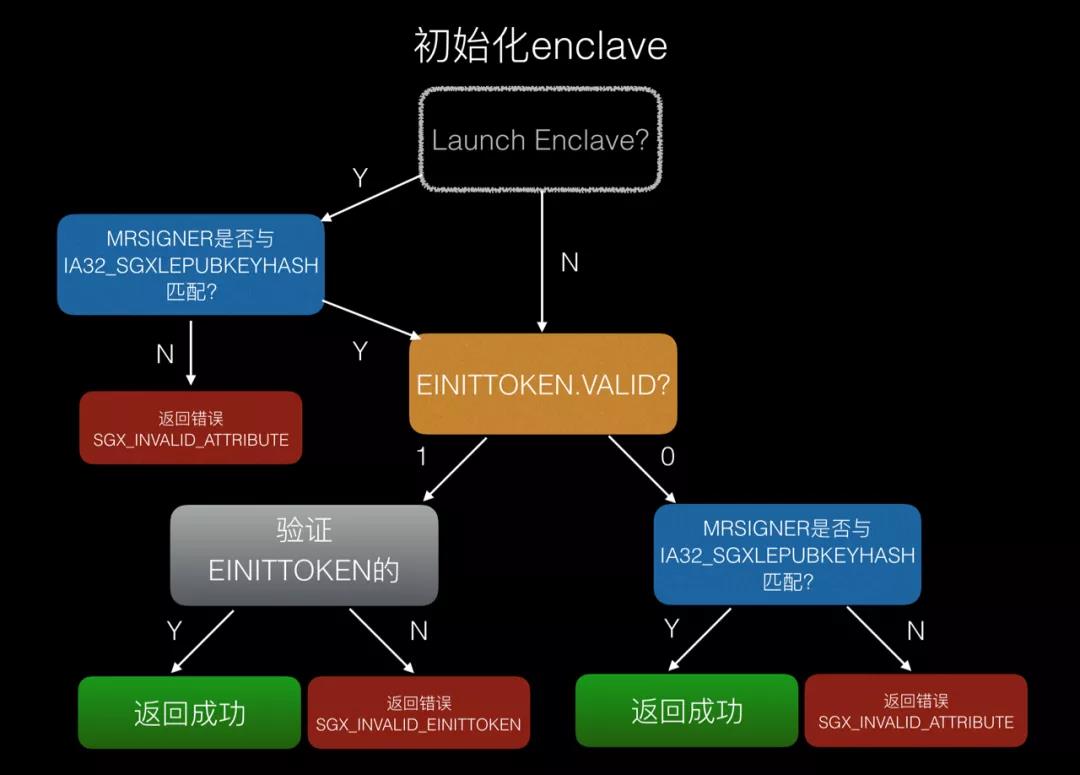
(上面的流程图是对Intel SDM手册中关于EINIT指令在微架构层的执行流程进行的总结;其中Launch Enclave验证两次IA32_SGXLEPUBKEYHASH的逻辑应该是冗余的,但我们还是按照原始流程的逻辑把它给完整地画出来了)
可以简单地将上述流程总结为以下两点规则:
1.只要在初始化enclave时能提供合法的einit token, 就能通过Launch Control的检查。
2. 如果在初始化enclave时没有提供合法的einit token, 则enclave的MRSIGNER必须与IA32_SGXLEPUBKEYHASH的值一致。
此外,还可以从第二点规则推导出适用于Launch Enclave的特殊规则:
1. Launch Enclave必须能够通过IA32_SGXLEPUBKEYHASH的校验才能被初始化。
2. 通过EINIT初始化Launch Enclave的时候,可以不提供einit token。
在处理器复位时,IA32_SGXLEPUBKEYHASH的默认值是Intel的MRSIGNER。如果处理器不支持FLC,任何普通的enclave在初始化时,必须持有合法的einit token,而负责颁发einit token的Launch Enclave则可以制定自己的策略来决定是否给一个普通enclave颁发einit token。 具体到Intel在不支持FLC的SGX1上实施的策略则是:用户运行的enclave必须是由Intel授权的密钥签过的,这样才能得到Intel开发的Launch Enclave的授权,并获得einit token,否则用户无法运行自己开发的普通enclave(严格讲是无法运行产品级的普通enclave,debug级的普通enclave还是可以运行的)。
这就是利用Launch Control达成的控制效果:谁掌握Launch Enclave,谁控制普通enclave的运行授权。
相反,如果处理器支持FLC且Bios没有锁死IA32_SGXLEPUBKEYHASH,IA32_SGXLEPUBKEYHASH MSRs对系统软件不仅可见而且可写,配合SGX in-tree驱动就可以实现如下功能:每当加载任意enclave时,都无条件将其MRSIGNER写入到IA32_SGXLEPUBKEYHASH中,从而绕过Launch Control机制,也就是说所有普通enclave都能像Launch Enclave那样无需提供合法的einit token。FLC中的F,指的就是IA32_SGXLEPUBKEYHASH寄存器在某些情况下是可写的。 至于要不要利用它绕过Launch Control机制,则是具体的实现策略问题,而SGX in-tree驱动就恰恰采取了绕过Launch Control的策略,原因是Linux kernel不希望提供对配置锁定的系统提供支持。
至于这种策略是否正确,我们暂先不讨论。先休息下,听听故事。
故事脉络
故事的导火索出自v22 SGX in-tree驱动。这里作者Jarkko定义了处理器是否支持FLC的bit,并对FLC的作用进行了说明。留意作者的最后一段话

“内核不会对某种被锁定的配置提供支持,因为这夺走了内核(对启动enclave)的启动控制权。”结合前面关于FLC的技术原理讲解,这里的锁定指的就是如果BIOS锁死了IA32_SGXLEPUBKEYHASH,那么普通enclave的运行方式就要被Intel的Launch Enclave的授权策略所控制。这段描述引起了Reviewer Borislav的警觉,并给出了硬核回复:如果FEATURE_CONTROL_SGX_LE_WR位决定了IA32_SGXLEPUBKEYHASH是否被锁死,那么谁控制的FEATURE_CONTROL_SGX_LE_WR位?内核能够控制吗?我可不想让该死的BIOS去控制,真出点啥问题我们自己能搞定,用不着看OEM的脸色。
这时候另一个作者Sean站出来回答了reviewer的问题:

“是的,就是BIOS控制着FEATURE_CONTROL_SGX_LE_WR位。这个我们都想好了,FEATURE_CONTROL_SGX_LE_WR位如果为0,那我们就把SGX功能完全禁止掉。这个想法在第四个补丁里有具体实现。”到目前看起来还是正常的社区review流程,大家也比较平和,直到reviewer看过了第四个补丁的内容。首先我们自己先看下第4个补丁到底干了什么:
+static void __maybe_unused detect_sgx(struct cpuinfo_x86 *c)
+{
+ unsigned long long fc;
+
+ rdmsrl(MSR_IA32_FEATURE_CONTROL, fc);
...
+ if (!(fc & FEATURE_CONTROL_SGX_ENABLE)) {
+ pr_err_once("sgx: SGX is not enabled in IA32_FEATURE_CONTROL MSR\\n");
+ goto err_unsupported;
+ }
+
+ if (!cpu_has(c, X86_FEATURE_SGX1)) {
+ pr_err_once("sgx: SGX1 instruction set is not supported\\n");
+ goto err_unsupported;
+ }
+
+ if (!(fc & FEATURE_CONTROL_SGX_LE_WR)) {
+ pr_info_once("sgx: The launch control MSRs are not writable\\n");
+ goto err_msrs_rdonly;
+ }
+
+ return;
+
+err_unsupported:
+ setup_clear_cpu_cap(X86_FEATURE_SGX);
+ setup_clear_cpu_cap(X86_FEATURE_SGX1);
+ setup_clear_cpu_cap(X86_FEATURE_SGX2);
+
+err_msrs_rdonly:
+ setup_clear_cpu_cap(X86_FEATURE_SGX_LC);
+}
一句话描述这段代码的含义就是:如果FEATURE_CONTROL_SGX_LE_WR位为0(一种情况是BIOS锁死了IA32_SGXLEPUBKEYHASH,另一种情况是平台不支持FLC)的话,意味着MSR_IA32_SGXLEPUBKEYHASH{0, 1, 2, 3}这四个MSR寄存器对内核来说就是只读或者不可见的,那么内核也就无法控制普通enclave的启动,这是Linux upstream不想看到的情况。对此,代码会简单地清楚掉FLC的cpu feature flag,但会保留其他SGX相关的cpu feature flag。
Borislav此刻的心情肯定是:(⇀‸↼‶) 这和你前面说的不一样啊?这哪里是你所谓的“把SGX功能完全禁止掉”了??你明明只是清除了FLC cpu feature flag,没有完全禁止SGX功能啊!!!难道是我的理解有问题吗 (⊙_⊙)?

作者Sean应该是知道自己说错话了,没有回复这个问题;而Borislav此刻只想要一个东西:MSR_IA32_SGXLEPUBKEYHASH{0, 1, 2, 3}这四个MSR寄存器对内核来说必须可写!!!!


然后作者Sean开始摆事实讲道理:还有好多不支持FLC或者禁用FLC(即BIOS可能非故意地锁死了IA32_SGXLEPUBKEYHASH)的SGX的平台啊!

Sean说这句话的时候是在2019年9月25日,其实如今来看这句话依旧正确。
Borislav没有被说服,并且开始谈起BIOS是多么的“糟糕”,并多次提到不想提供对带有配置锁定的系统的支持:
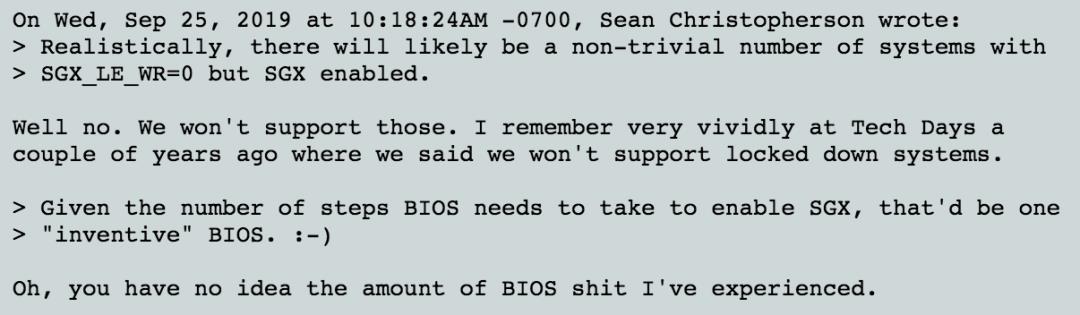


Linux以及开源社区一向反感各种配置锁定和DRM。笔者印象中早些年Win7刚出来时强行默认开UEFI Secure Boot且BIOS setup中不提供关闭选项导致无法安装Linux,这让开源社区非常不爽,经过Linux Foundation、Intel和微软的交涉,才最终有了今天的shim bootloader。当然,终端用户不用自己去找微软签名bootloader,这是每个Linux发行版本自己找微软签名的事情了,而且这个默契也已经持续很久了。
最后作者Sean认了,并且说我们本来就是那么想的:

一口老血喷了出来!合着前面的迷之发言逗我们玩呢???显然作者Sean的逻辑出现了矛盾,他说他的本意其实是这样的:

“即使MSR_IA32_SGXLEPUBKEYHASH不可写,但我们依旧保留其他SGX cpu feature flag,好让用户明白到底是我的系统不支持SGX硬件能力,还是因为缺少FLC功能导致无法运行普通的enclave,现在看起来可能是我想多了。” 关于Sean的这个结论,需要这样理解:虽然在不支持FLC或禁用FLC的平台上仍旧能够运,debug级的普通enclave,但是debug级的enclave是能够被sgx-gdb通过特殊的enclave debug指令访问到enclave中的敏感数据的,因此debug级的enclave不适合于生产环境;要运行不能被debug的产品级enclave,就必须要遵守Intel的Launch Enclave的授权策略,但这需要实施一些对常人来说不具可实施性的操作,这与一般用户想简单地就能运行普通enclave的需求确实相悖,因此大多数情况下,不支持FLC或禁用FLC就等价于用户无法运行普通enclave,而cpu feature flag可以反映出原因。
最终,从v25开始,如果处理器不支持FLC,所有SGX特性都将无法使用:
+update_sgx:
+ if (!cpu_has(c, X86_FEATURE_SGX) || !cpu_has(c, X86_FEATURE_SGX_LC)) {
+ clear_sgx_caps();
+ } else if (!(msr & FEAT_CTL_SGX_ENABLED) ||
+ !(msr & FEAT_CTL_SGX_LC_ENABLED)) {
+ if (IS_ENABLED(CONFIG_INTEL_SGX))
+ pr_err_once("SGX disabled by BIOS\\n");
+ clear_sgx_caps();
+ }
不过这个做法真的对么?难道不支持FLC或禁用FLC的平台就不应该得到SGX in-tree驱动的支持吗?
思考
回答这个问题前,我们先看下目前Intel对SGX驱动的支持情况。
除了SGX in-tree驱动,Intel在开源社区还提供了SGX Legacy驱动。这个SGX驱动是由于漫长的review流程而逐渐兴盛起来的副产物,目的是在标准内核尚不支持SGX的情况下满足用户对SGX平台的支撑需求。这个SGX Legacy驱动支持没有FLC的平台,也是目前支持SGX1平台的唯一选择。可以预见,在SGX in-tree驱动合入到upstream后,这个驱动会逐步退出历史的舞台,那么问题也来了。
首先,即使具备大量EPC内存的SGX2机器已经上线了(可以参考阿里云的SGX2邀测申请链接:https://pages.aliyun.com/aliyunpage/activity/alibabacloud-pilot.html ),但是仍有一批存量SGX1平台正在服役;此外,采用Intel client platform的CPU很多都支持SGX但不支持FLC,难道这些平台的用户将来就只能用着缺少新特性支持的SGX Legacy驱动吗?
其次,有些人一定已经提前考虑到需要将现有业务应用拿到基于SGX in-tree驱动的环境里跑一跑,测一测SGX in-tree驱动本身的性能和稳定性,因此在缺乏SGX2平台的情况下,也需要SGX in-tree驱动能够支持SGX1平台。
最后,不支持FLC和禁用FLC其实是两码事。被社区真正诟病的是老的SGX1平台不支持FLC,进而只能被逼实施不具可实施性的Launch Enclave运行授权;到了支持FLC平台特性的时代,即便禁用了FLC,但只要锁定的内容是用户可控的,或者是实施一种更为宽松的Launch Enclave运行授权,那么这种配置锁定也是有益的。 就拿云租户使用裸金属服务器的场景为例:即使CSP在BIOS里禁用了FLC,只要CSP在自己定制的Launch Enclave中确保合法的云租户能正常运行该租户自己签的enclave就可以了,而这其实这反倒是为租户多增加了一重保护。如果像现在SGX in-tree驱动的这种实现方式,包括成功入侵到系统的攻击者都可以任意运行自己编写的恶意Enclave了。
那我们该怎么办呢?
解决方案
我们的观点还是想大家之所想,急大家之所急。根据目前的实际情况,Inclavare Containers开源项目组( https://github.com/alibaba/inclavare-containers )编写了几个补丁,目的就是让不支持FLC或禁用FLC的系统能够运行SGX in-tree驱动。补丁的使用和验证方法详见:https://github.com/alibaba/inclavare-containers/tree/master/hack/no-sgx-flc
目前我们已经在SGX1机型中成功部署了这种运行方式,并实际应用于Inclavare Containers开源项目的CI/CD测试中。
此外,Inclavare Containers开源项目会研发一个支持用户自定义策略的Launch Enclave;目的是提升用户控制的平台的安全性,即只允许运行用户预期的普通enclave,杜绝攻击者在用户平台上运行恶意enclave的情况出现。
最后有几个关键概念的关系要再次澄清,重点提醒下大家:
1. 是否支持FLC和CPU是否支持SGX1/2没有关系;SGX1/2是处理器SGX架构的指令集特性;FLC是平台特性。
2. 之所以强调SGX1和FLC的关系,是因为FLC是在SGX1和SGX2之间出现的平台特性,因此很多SGX1平台都缺少FLC特性。
3. 即使是在支持FLC的平台,只要在BIOS中禁用了FLC(不管是出于安全原因禁用,还是BIOS不支持FLC,或是被CSP锁定),都会像不支持FLC的SGX1平台那样遇到相同的问题。也许到了我们能把这个问题像上面提到的那样做到真正的精细化处理,即能够明确区分出“平台控制权民主化”和“非预期的平台配置锁定”并为前者提供实在的安全解决方案的时候,我们会再给社区发送一组patch,以允许SGX in-tree驱动支持那些用户明确希望禁用FLC的平台。(完)
原文链接
本文为阿里云原创内容,未经允许不得转载。
以上是关于谁来拯救存量SGX1平台?又一个内核特性合并的血泪史的主要内容,如果未能解决你的问题,请参考以下文章
Linux 内核Linux 内核特性 ( 组织形式 | 进程调度 | 内核线程 | 多平台虚拟内存管理 | 虚拟文件系统 | 内核模块机制 | 定制系统调用 | 网络模块架构 )