数据结构 双链表的简单理解和基本操作
Posted 林慢慢i
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据结构 双链表的简单理解和基本操作相关的知识,希望对你有一定的参考价值。
前言:本章主要内容是双向循环链表(即双链表)的概念,和其基本操作:包括定义、创建、初始化、判空、尾插、头插、尾删、头删、插入、查找、销毁等操作的具体实现。
文章目录
1.为什么需要双链表?
单链表的中间结点、尾结点查找麻烦,如果想对这些结点进行修改,就不得不进行遍历操作,增加了算法复杂度。
1.1双链表的概念
第一个结点属于多开辟的空间,为了方便头插头删,后续结点为真正的链表内容。
1.2双链表一个结点的内容
一个指向前面结点的指针
一个存储数据的空间
一个指向后面结点的指针

2.双链表的项目实现
| 程序名 | 功能 |
|---|---|
| List.h | 创建双链表,完成一些函数的声明 |
| List.c | 实现双链表各个函数的定义 |
| test.c | 测试双链表所需函数是否正确 |
2.1 双链表的定义
代码实现
typedef int LTDataType;
typedef struct ListNode
{
struct ListNode* prev;
LTDataType data;
struct ListNode* next;
}LTNode;
思考下为何使用typedef?
如果一开始我们就确定了结构体中的变量类型,后续在项目过程中如果需要对这个变量类型进行调整,那么所需的操作是很繁琐的。故使用typedef,后续若是需要修改,改动typedef就足够了。
2.2 双链表的创建
代码实现
LTNode* BuyListNode(LTDataType elem)
{
LTNode* newnode = (LTNode*)malloc(sizeof(LTNode));
if(newnode == NULL)
{
perror("错误原因:");
exit(-1);
}
newnode->data = elem;
newnode->prev = NULL;
newnode->next = NULL;
return newnode;
}
2.3 双链表的初始化
需要改变phead,因为实参是一个一级指针,如果形参也只是一级指针,就属于值传递了,函数内pphead的值改变并不会影响外面的实参。而初始化是需要修改实参的,所以传二级指针
代码实现
void ListInit(LTNode** pphead)
{
assert(pphead); //pphead一定不能是空指针
(*pphead) = BuyListNode(1); //随机给一个值用来创建结点
(*pphead)->prev = *pphead;
(*pphead)->next = *pphead;
}
2.4 双链表的判空操作
头结点放的是无效数据,不需要判断,只需要判断就是头结点之后(
phead->next)的结点值是不是phead,原因:当链表为空时候,就只剩下一个无效头结点,即
phead->next = phead(自己指向自己)。当链表不为空时候,就有有效结点,即
phead->next != phead。
代码实现
bool ListEmpty(LTNode* phead)
{
assert(phead); //phead不能为空
return phead->next == phead;
}
2.5 双链表的元素数量查询操作
代码实现
size_t ListSize(LTNode* phead)
{
assert(phead);
size_t sum = 0;
LTNode* cur = phead->next; //从头结点之后开始遍历(头结点不存放数据)
while(cur != phead) //当cur再次为phead时候,说明链表已经遍历完毕.
{
sum++;
cur = cur->next;
}
return sum;
}
2.6 双链表的打印操作
结束条件就是到了最后一个元素,而最后一个元素的next指向首元素
代码实现
void ListPrint(LTNode* phead)
{
assert(phead);
LTNode* cur = phead->next;
while (cur != phead)//到了最后就是指向首元素
{
printf("%d--->", cur->data);
cur = cur->next;
}
printf("|完毕|\\n");
}
2.7 双链表的尾插
在尾插方面双链表拥有对比单链表而言极大的优势,不需要进行遍历,只需通过改变**
phead->prev**的指向即可。仔细看下图理解一下为什么?
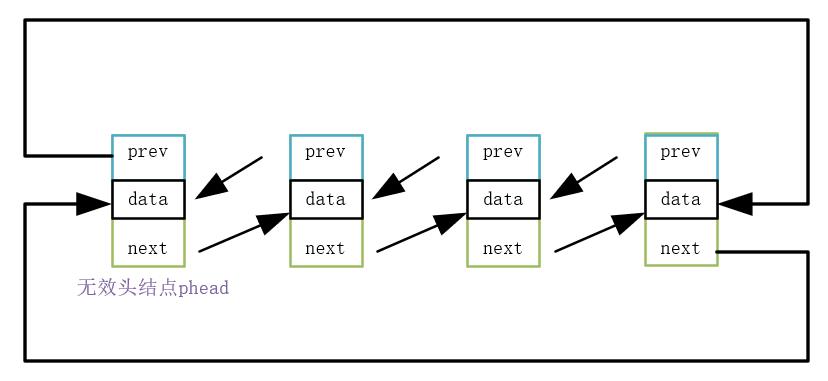
因为在双向循环链表结构中,**
phead->prev**指向的就是尾结点的data,所以不需要遍历!
实现思路:
1.创建新结点存储数据
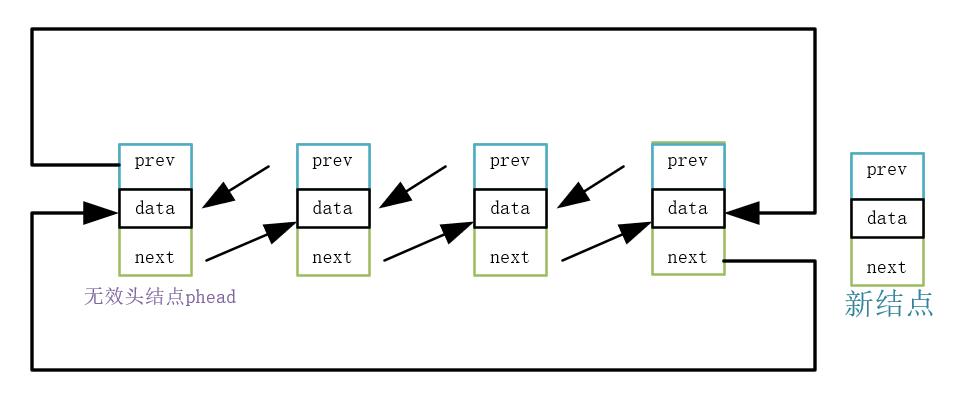
2.原尾结点与新结点进行相互链接

3.新结点与头结点相互链接
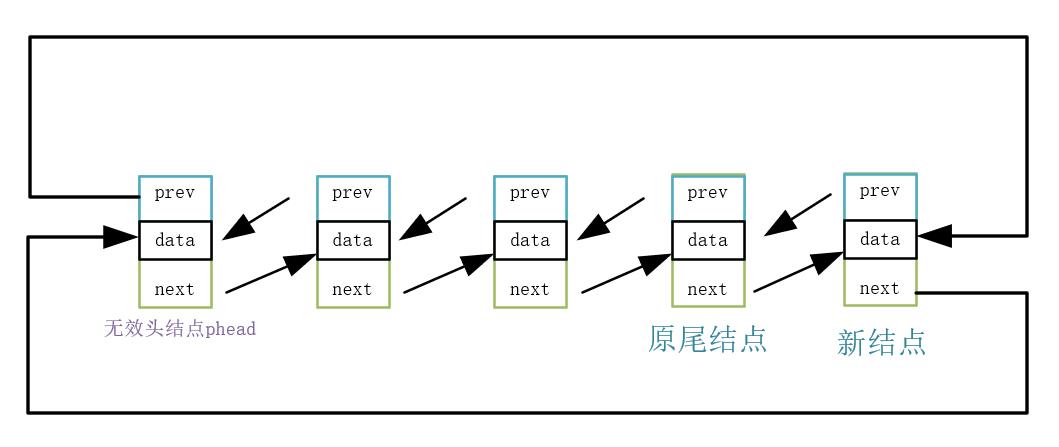
代码实现
void ListPushBack(LTNode* phead, LTDataType* elem)
{
assert(phead);
LTNode* tail = phead->prev; //找到尾结点
LTNode* newnode = BuyListNode(elem); //创建新结点
//原来尾结点和现在新结点链接
tail->next = newnode;
newnode->prev = tail;
//新结点和头结点链接
phead->prev = newnode;
newnode->next = phead;
}
2.8 双链表的尾删
有了尾插的基础,思考尾删就更容易了,步骤如下:
1.找到尾结点和倒数第二个结点
2.释放尾结点
3.头结点和倒数第二个结点链接
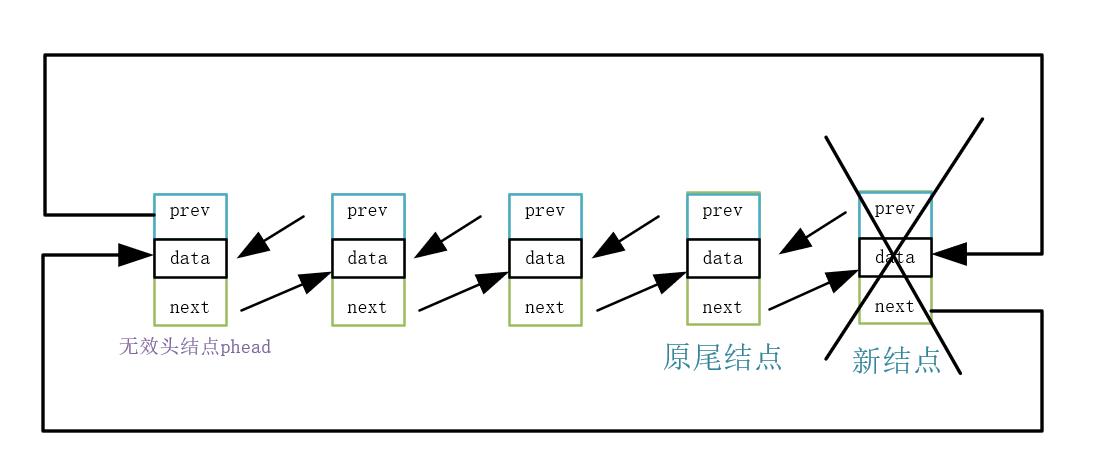

代码实现
void ListPopBack(LTNode* phead)
{
assert(phead);
assert(ListEmpty(phead)); //如果链表为空就不能删除.
LTNode* tail = phead->prev;//尾结点
LTNode* tail_prev = tail->prev;//倒数第二个结点
free(tail);//释放尾结点
tail = NULL;
tail_prev -> next = phead; //头结点和倒数第二个结点连接
phead->prev = tail_prev;
}
2.9 双链表的头插
这里注意一点,头插,仍然不改变之前的phead,头插是从第二个结点开始(即双链表中第一个有效存储数据的结点开始)。
1.创建新结点存储数据

2.新结点与头结点后的第一个结点链接
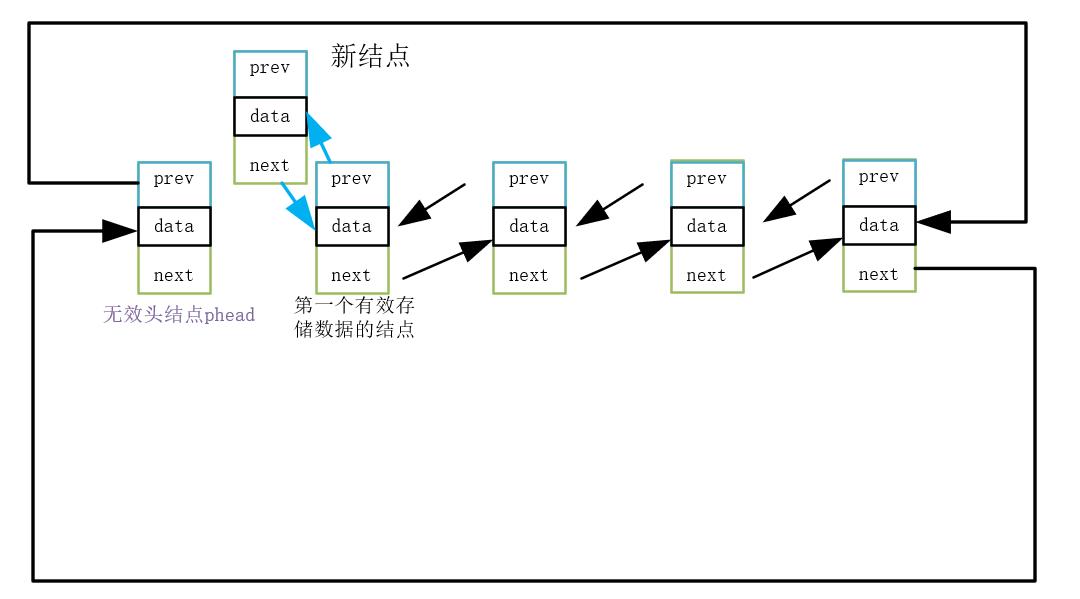
3.第三步,新结点与头结点链接
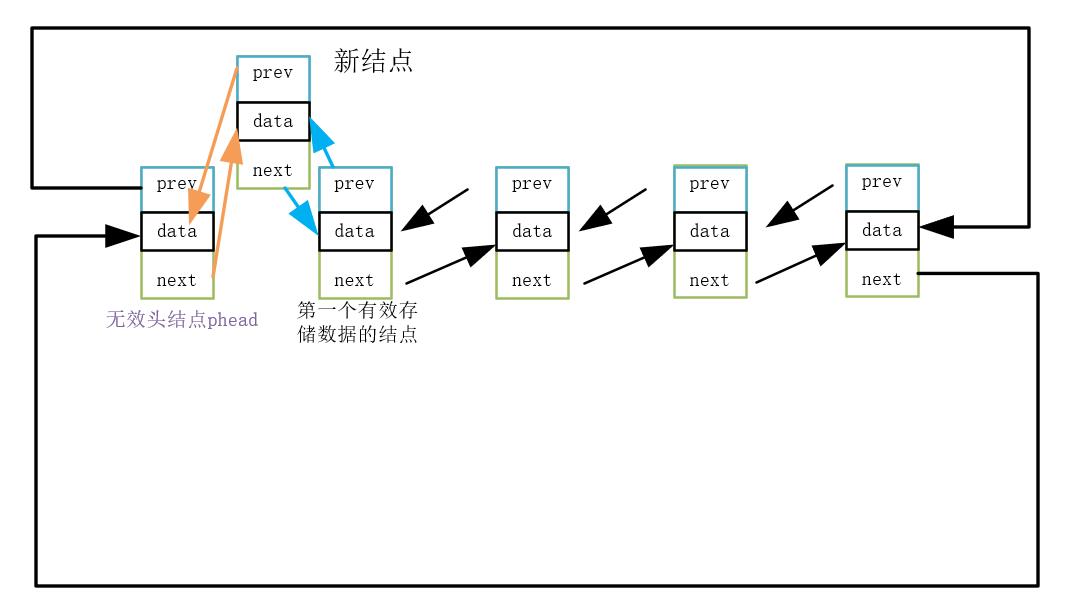
代码实现
void ListPushFront(LTNode* phead, LTDataType* elem)
{
assert(phead);
LTNode* newnode = BuyListNode(elem); //创建新结点存储数据
LTNode* Second_first = phead->next; //头结点后的首结点.
//新结点 与 头结点后的首结点 链接
Second_first ->prev = newnode;
newnode->next = Second_first;
//新结点与头结点链接
phead->next = newnode;
newnode->prev = phead;
}
2.10 双链表的头删
这里注意一点,头删,仍然不改变之前的phead,头删是从第二个结点开始(即双链表中第一个有效存储数据的结点开始)。
1.头结点与头删结点后的结点链接
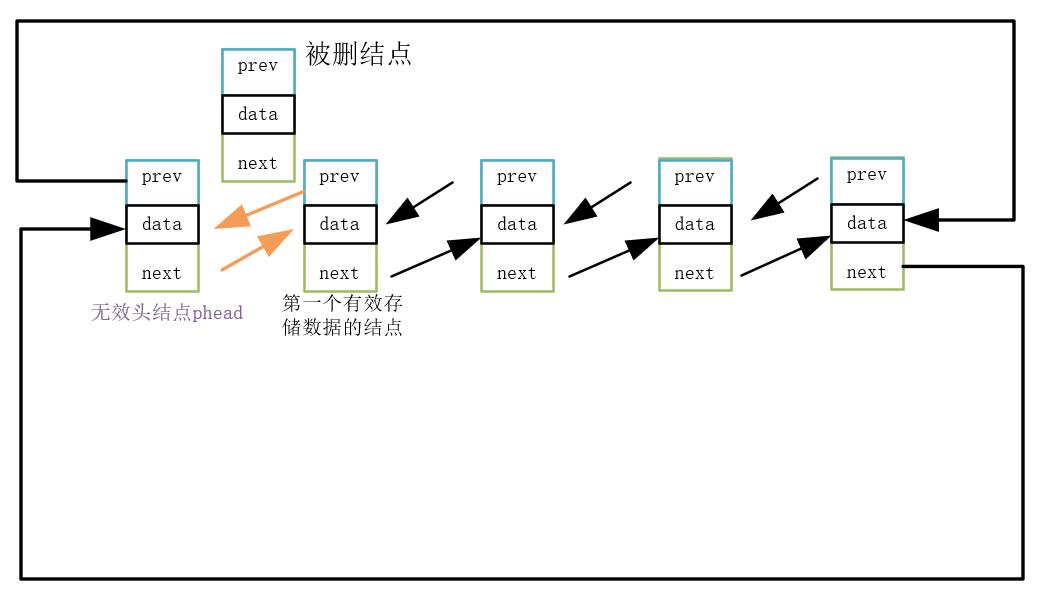
2.释放头删结点
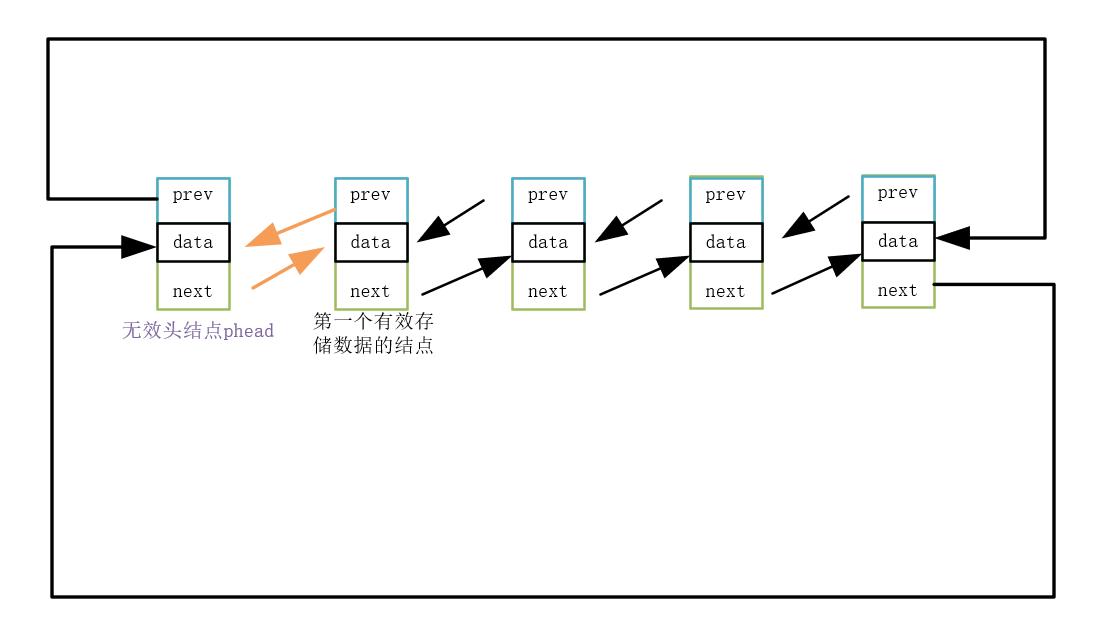
代码实现
void ListPopFront(LTNode* phead)
{
assert(phead);
assert(!ListEmpty(phead)); //如果为空就无法删除
LTNode* Front_second = phead->next->next;//头删结点后的结点
LTNode* front = phead->next; //头删结点
//连接
phead->next = Front_second;
Front_second->prev = phead;
//释放头删结点
free(front);
front = NULL;
}
2.11 双链表的查找值操作
与单链表类似,直接遍历
代码实现
LTNode* ListFind(LTNode* phead,LTDataType elem)
{
assert(phead);
LTNode* cur = phead->next;
while(cur != phead)
{
if(cur->data == elem)
{
return cur;
}
cur = cur->next;
}
return NULL;
}
2.12 双链表的插入操作
与之前的头插类似,只是头插特定是在头结点后的第一个结点前进行插入,而任意位置前插入是在给定的
pos结点之前插入。
代码实现
void ListInsert(LTNode* pos,LTDataType elem)
{
assert(pos);
LTNode* pos_prev = pos->prev; //保存pos结点之前的结点
LTNode* newnode = BuyListNode(elem); //创建新结点
//新结点与pos链接
newnode->next = pos;
pos->prev = newnode;
//新结点与原来pos之前的结点连接
pos_prev->next= newnode;
newnode->prev = pos_prev;
}
2.13 双链表的删除操作
与之前的尾删类似,只是尾删删除的是尾结点,而任意位置删除的是我们给的结点
pos。
代码实现
void ListErease(LTNode* pos)
{
assert(pos);
LTNode* prev = pos-> prev; //保存pos 之前结点
LTNode* next = pos->next; //保存pos 之后结点
free(pos);
pos = NULL;
prev->next = next;
next->prev = prev;
}
2.14 双链表的销毁操作
遍历进行释放就行
代码实现
void ListDestroy(LTNode* phead)
{
assert(phead);
LTNode* cur = phead->next;
while(cur != phead)
{
LTNode* next = cur->next;
free(cur);
cur = next;
}
free(cur);
cur = NULL;
}
3.源码链接
数据结构的双链表内容到此设计结束了,感谢您的阅读!!!如果内容对你有帮助的话,记得给我三连(点赞、收藏、关注)——做个手有余香的人。
以上是关于数据结构 双链表的简单理解和基本操作的主要内容,如果未能解决你的问题,请参考以下文章