ELK日志分析平台之kibana数据可视化
Posted S4061222
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ELK日志分析平台之kibana数据可视化相关的知识,希望对你有一定的参考价值。
目录
kibana简介
Kibana 核心产品搭载了一批经典功能:柱状图、线状图、饼图、旭日图,等等。
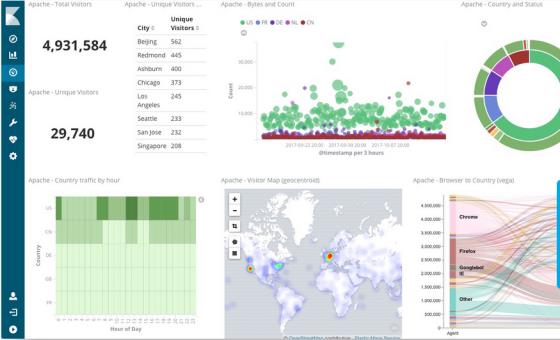
将地理数据融入任何地图
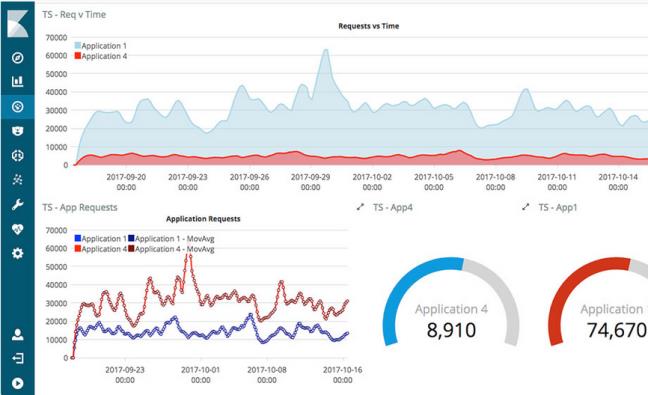
精选的时序性 UI,对您Elasticsearch 中的数据执行高级时间序列分析。
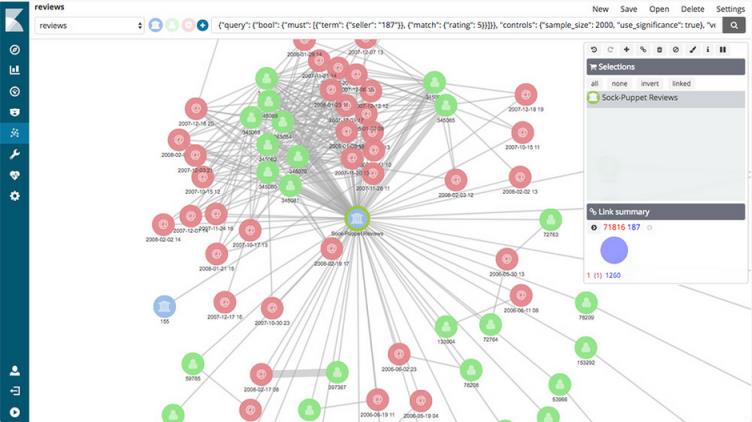
利用 Graph 功能分析数据间的关系
Kibana 开发工具为开发人员提供了多种强大方法来帮助其与 Elastic Stack 进行交互。
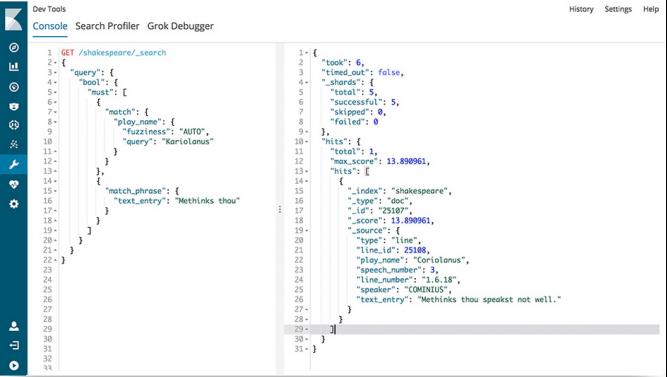
一 kibana安装与配置
!!!动态变更:kibana+logstack+ES,kibana为内置的集成工具,与ES可以结合。
ES(数据处理) logstash(数据采集,给ES) kibana(从ES加载出来,展示)
实验环境:
kibana+logstack放在同一台主机:server10
ES集群:server7,server8,server9
kibana下载(ELK的三个版本都要一致!!!)
官网:https://elasticsearch.cn/download/
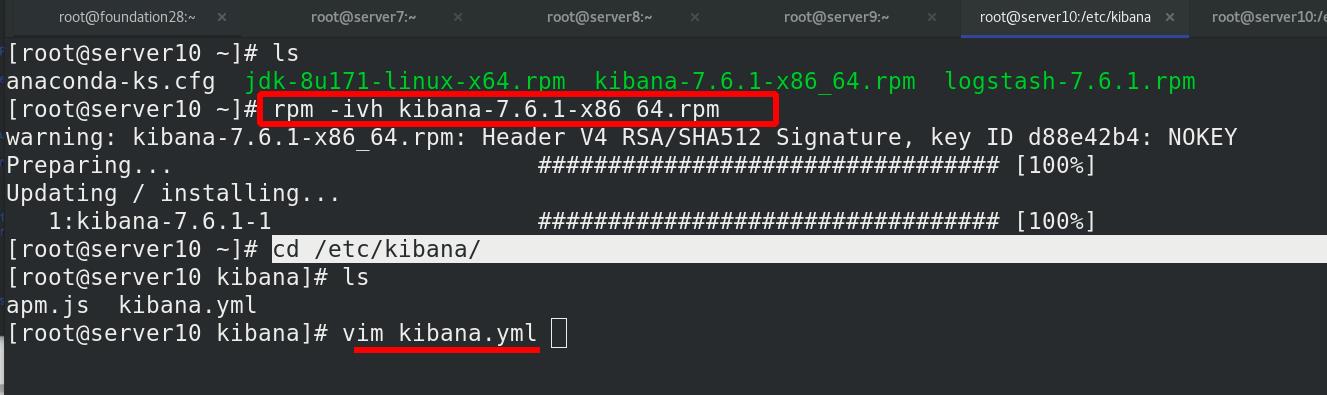
编辑配置文件,指定端口kibana的开放端口为5601,kibana主机ip为172.25.28.10
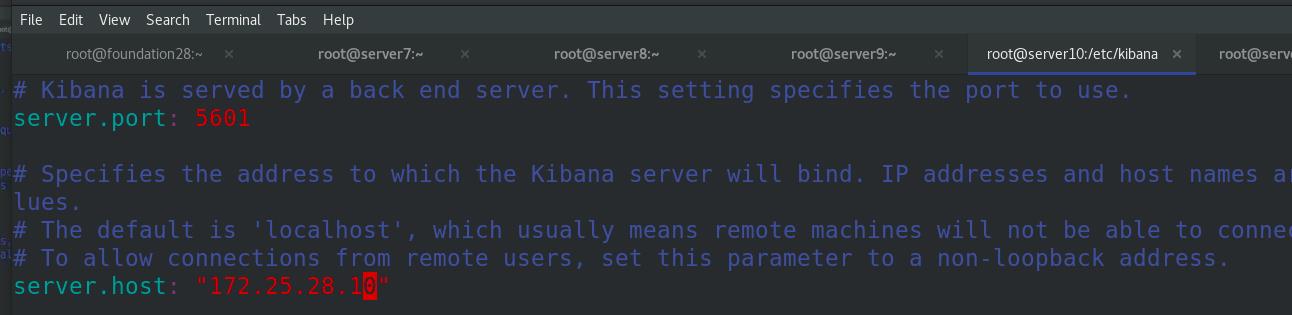
指定es集群的主机ip,指定kibana的索引
设置为中文

开启kibana服务,查看开放了5601端口
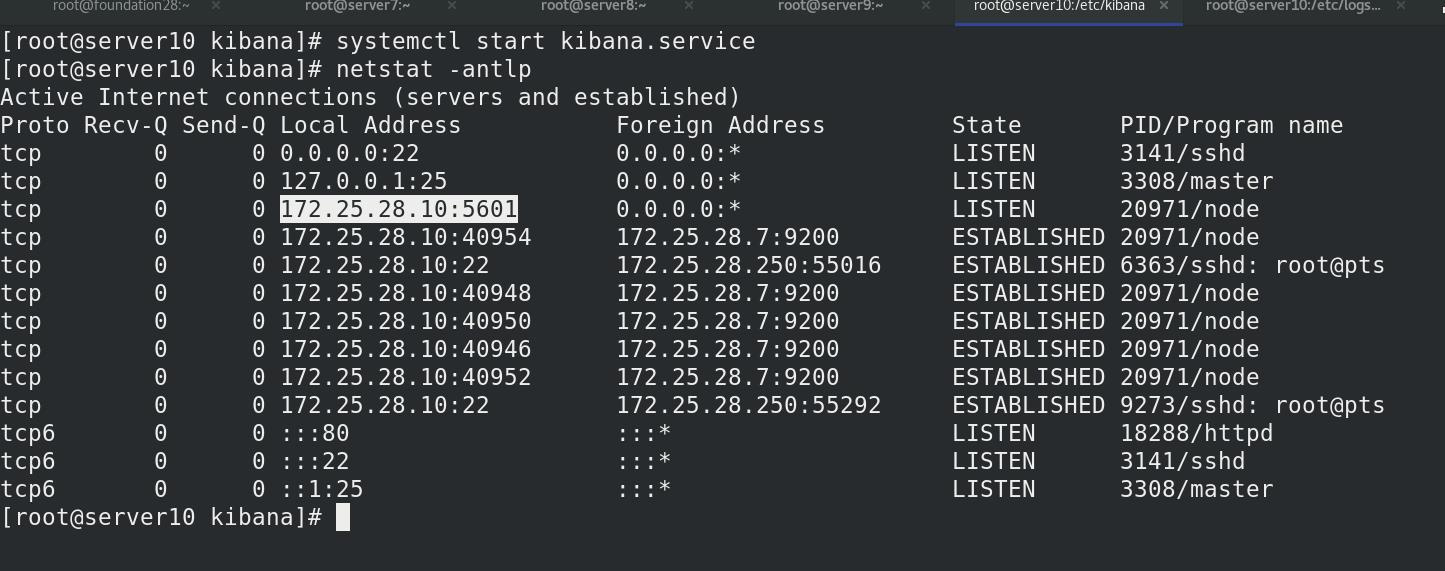
外部访问:
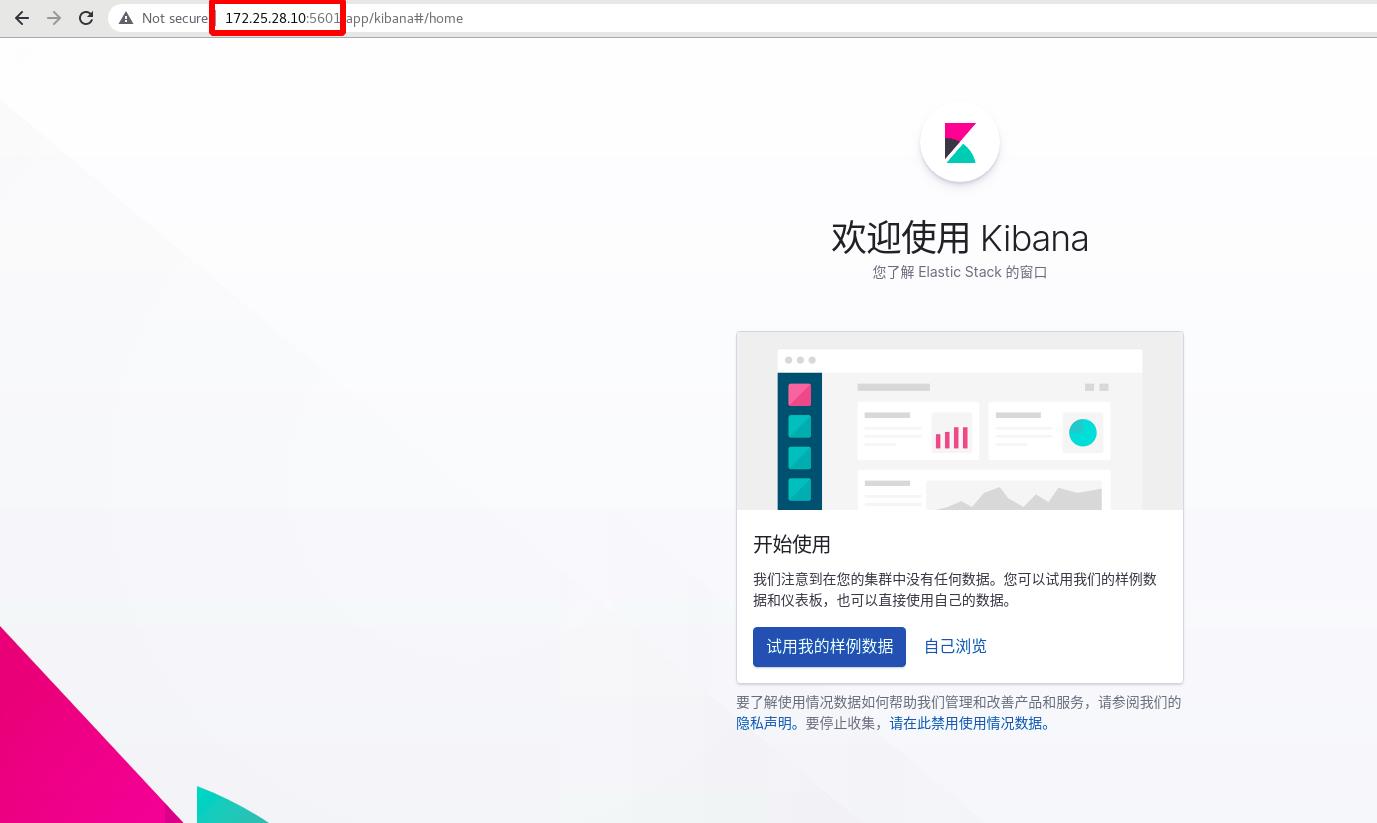
试用样例数据
添加样例数据
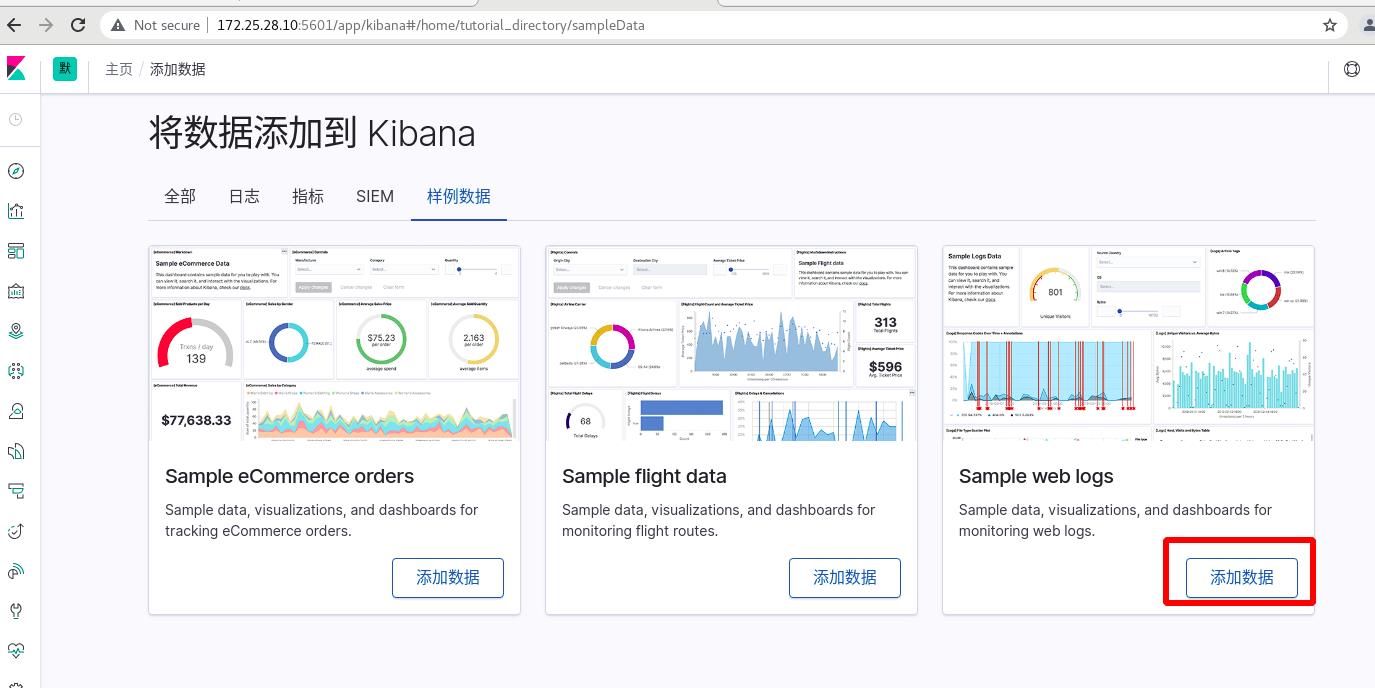
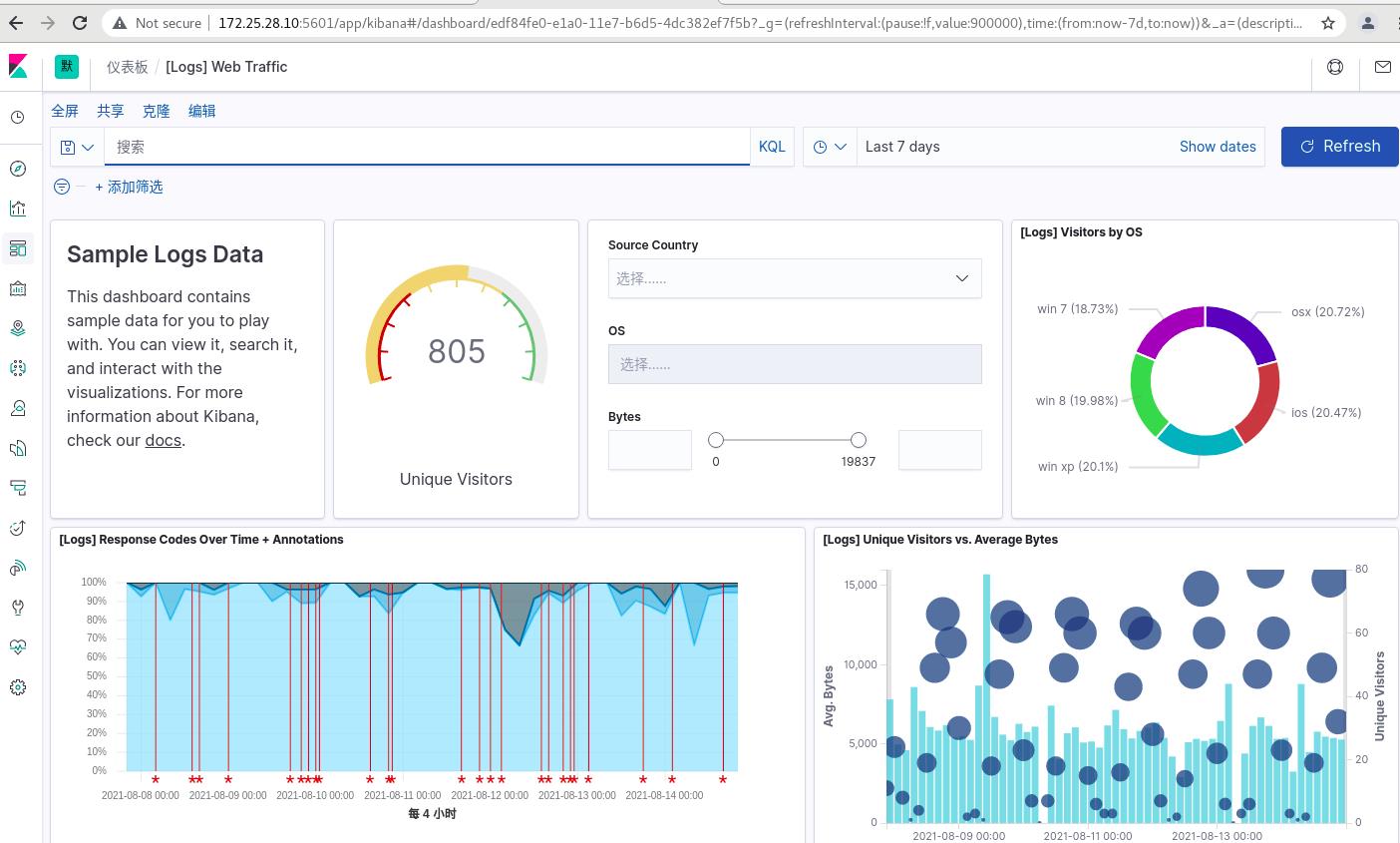
查看数据—>仪表盘
Es也相应的产生了几个新的索引
二 创建apache访问量的指标
创建索引
选择 apachelog索引 ----> 下一步
创建索引模式中选择时间戳
可视化 ----> 创建可视化,指标,选择apachelog
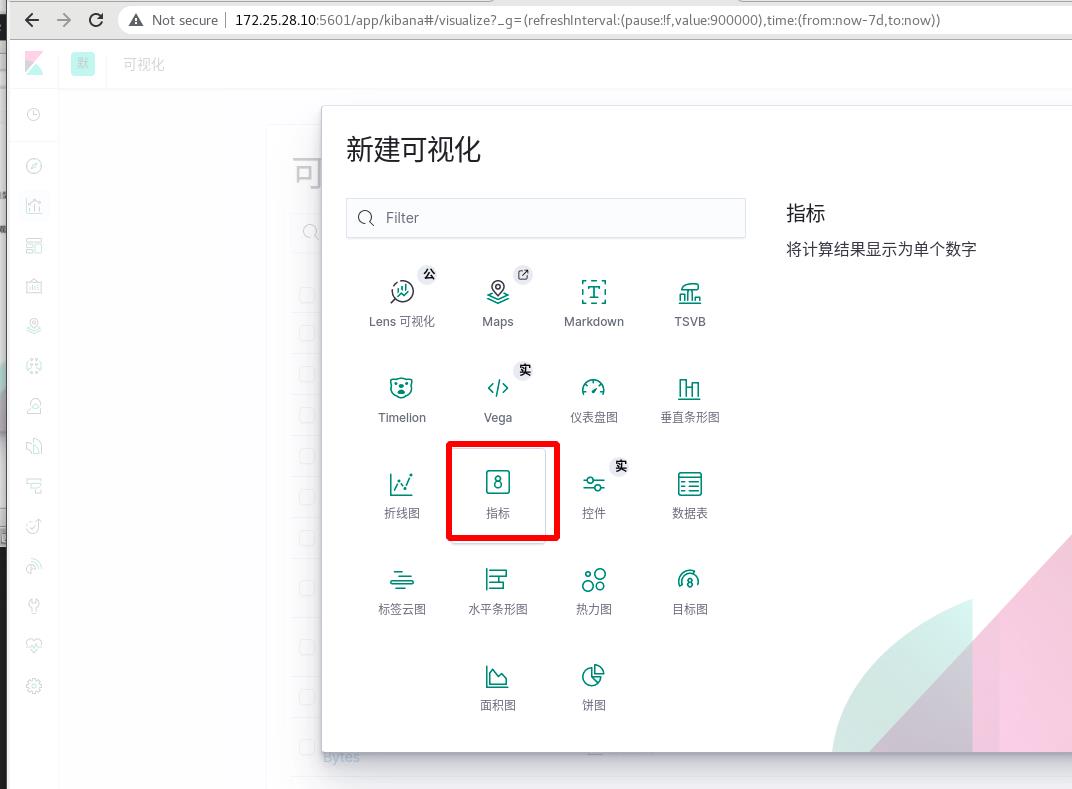
可以看到访问次数为1394,注意时间范围的选择,默认是过去15分钟的数据
保存
执行grok.conf文件,运行logstash,才能采集数据,输入给es

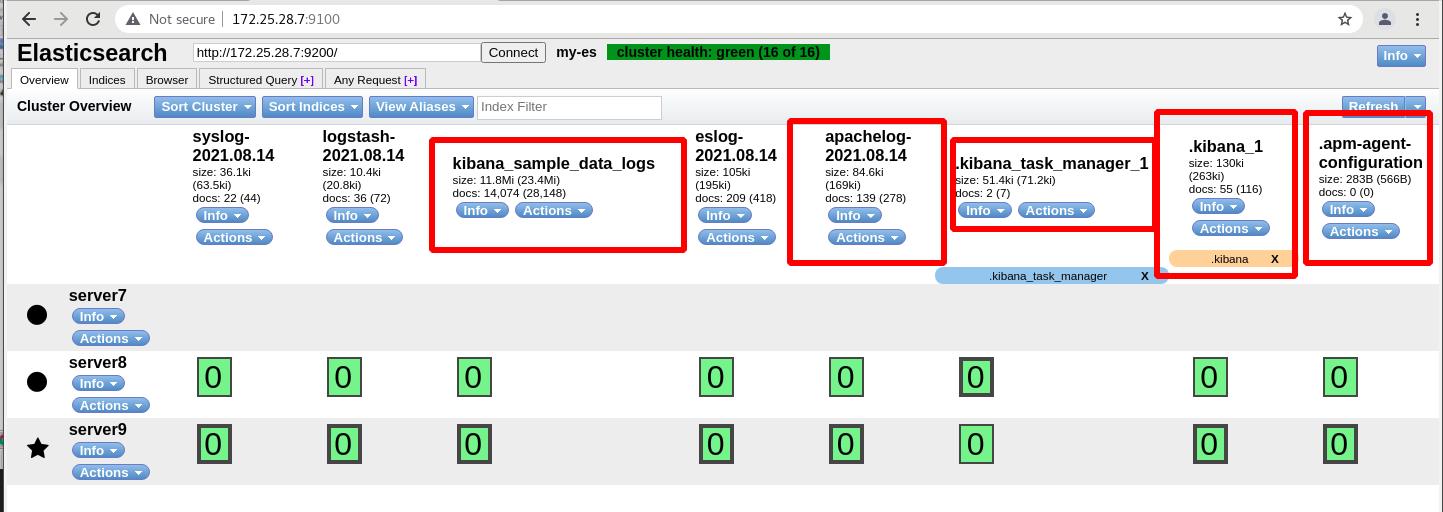
此时ES中可以看到新增的apachelog的索引,其他为样例数据
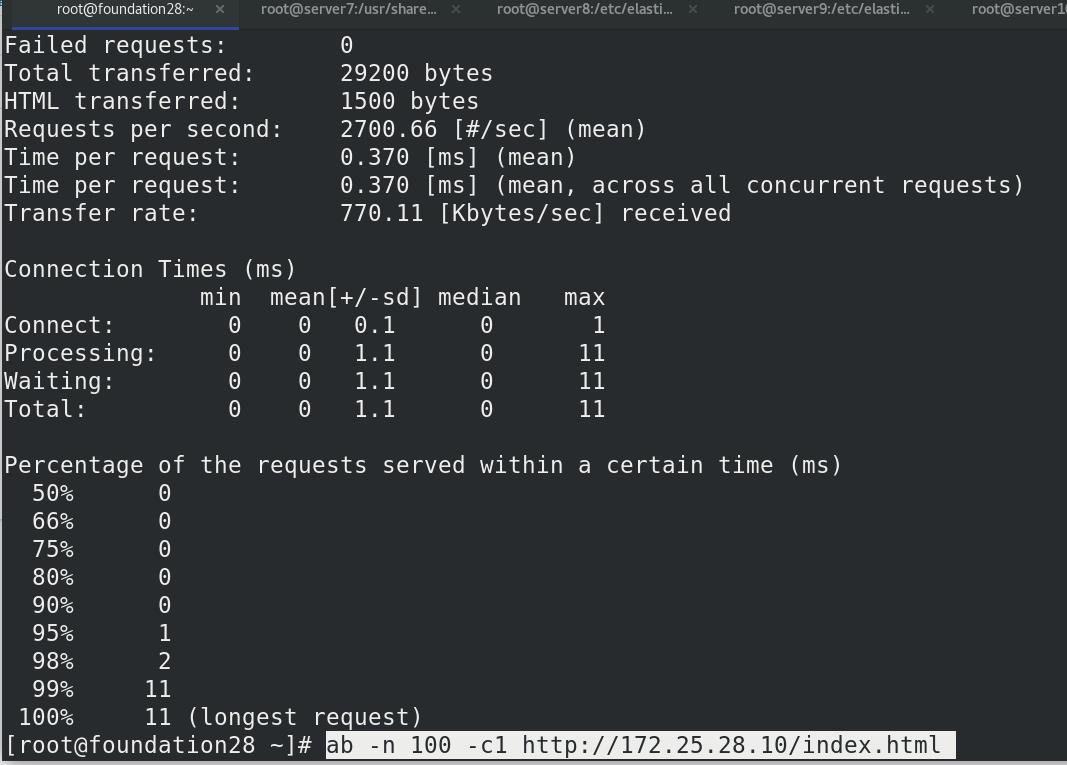
真机压力测试,访问100次172.25.28.10/index.html,并发数为1
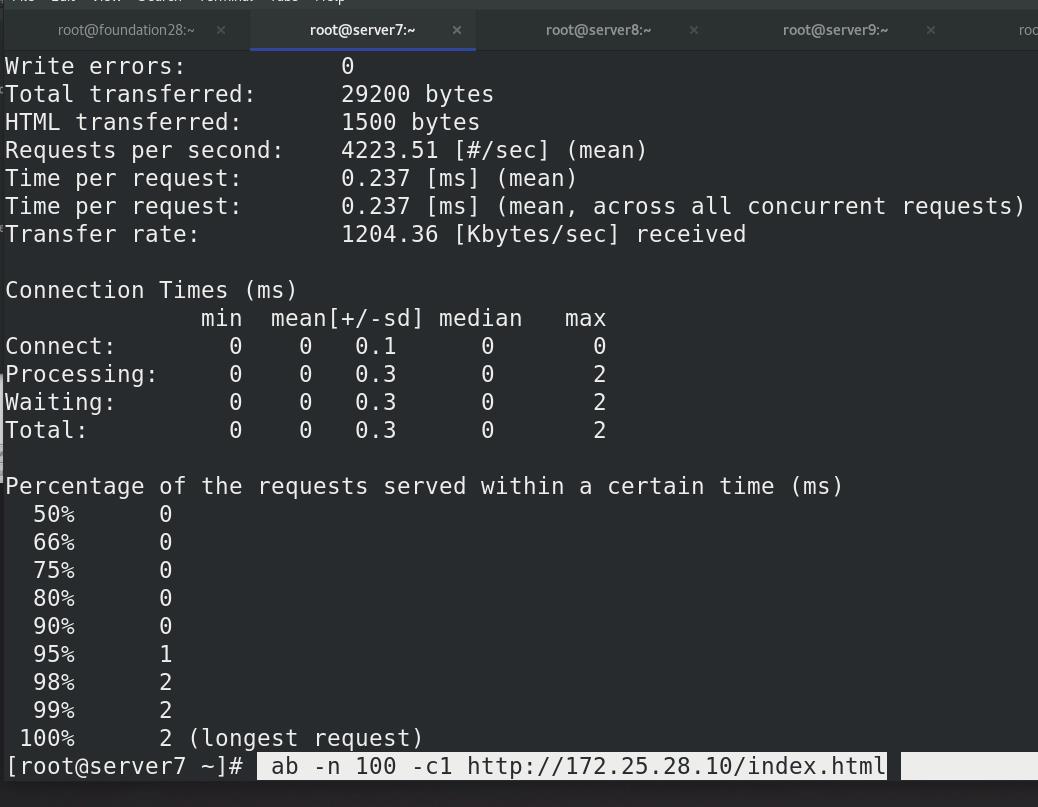
点击右上角的refresh刷新,可以看到kibana变为了242
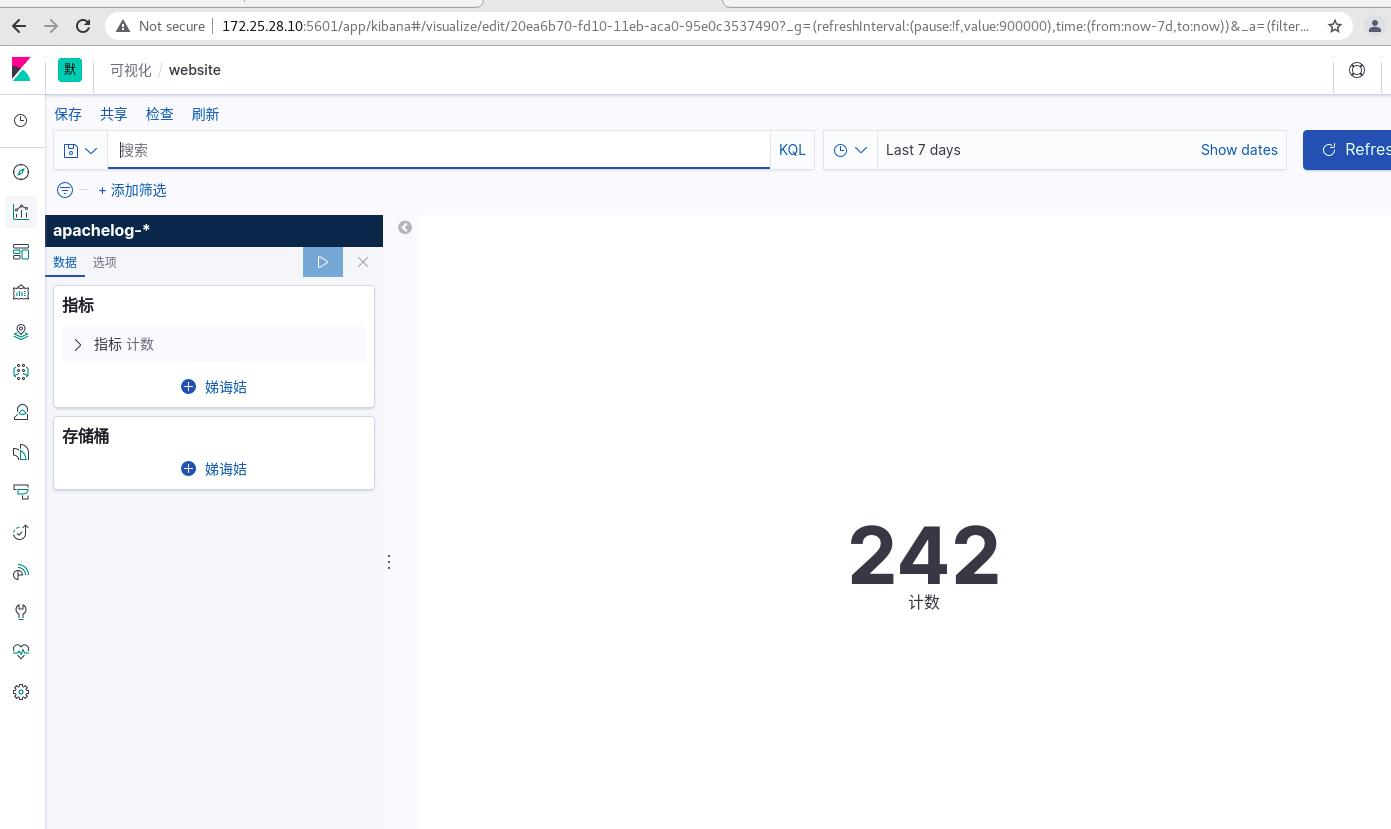
同理server8也可以压力测试
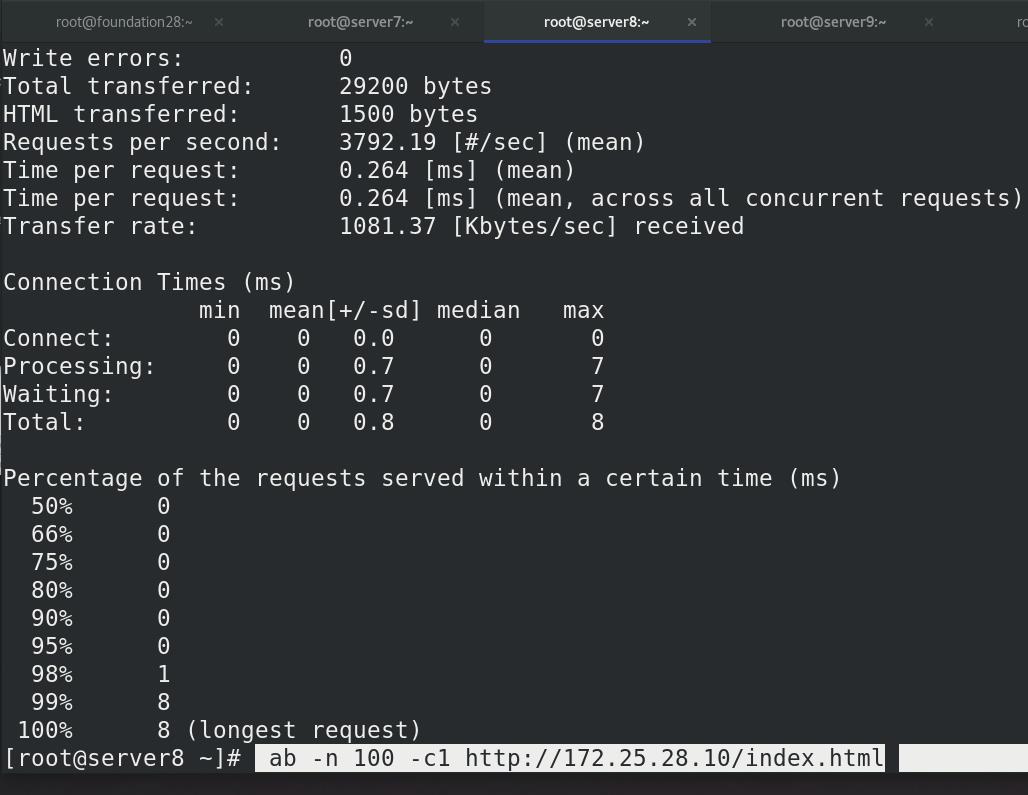
点击右上角的refresh刷新,可以看到kibana变为了342
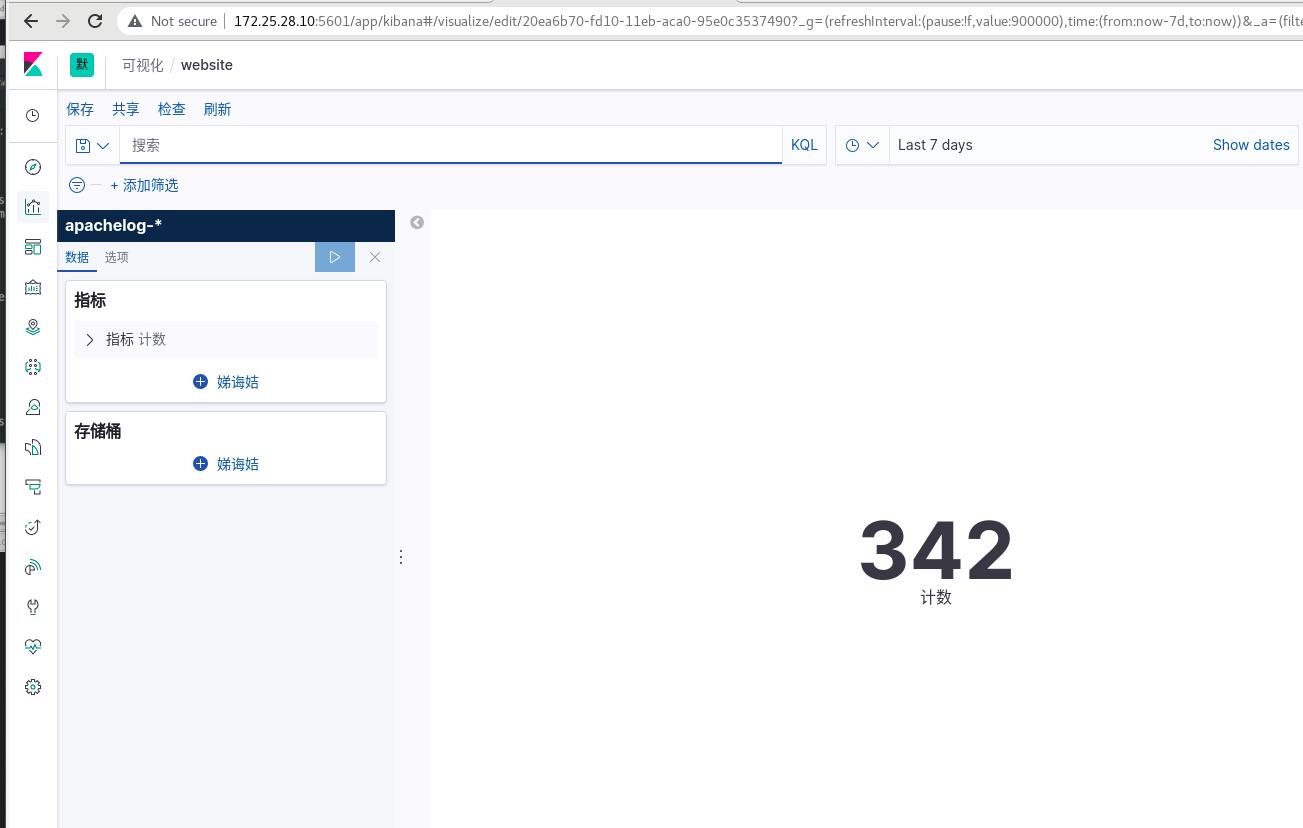
创建可视化访问量的垂直条形图
可视化 ----> 创建可视化
选择垂直条形图,选择apachelog
Y轴是访问的次数,默认没有X轴,添加X轴
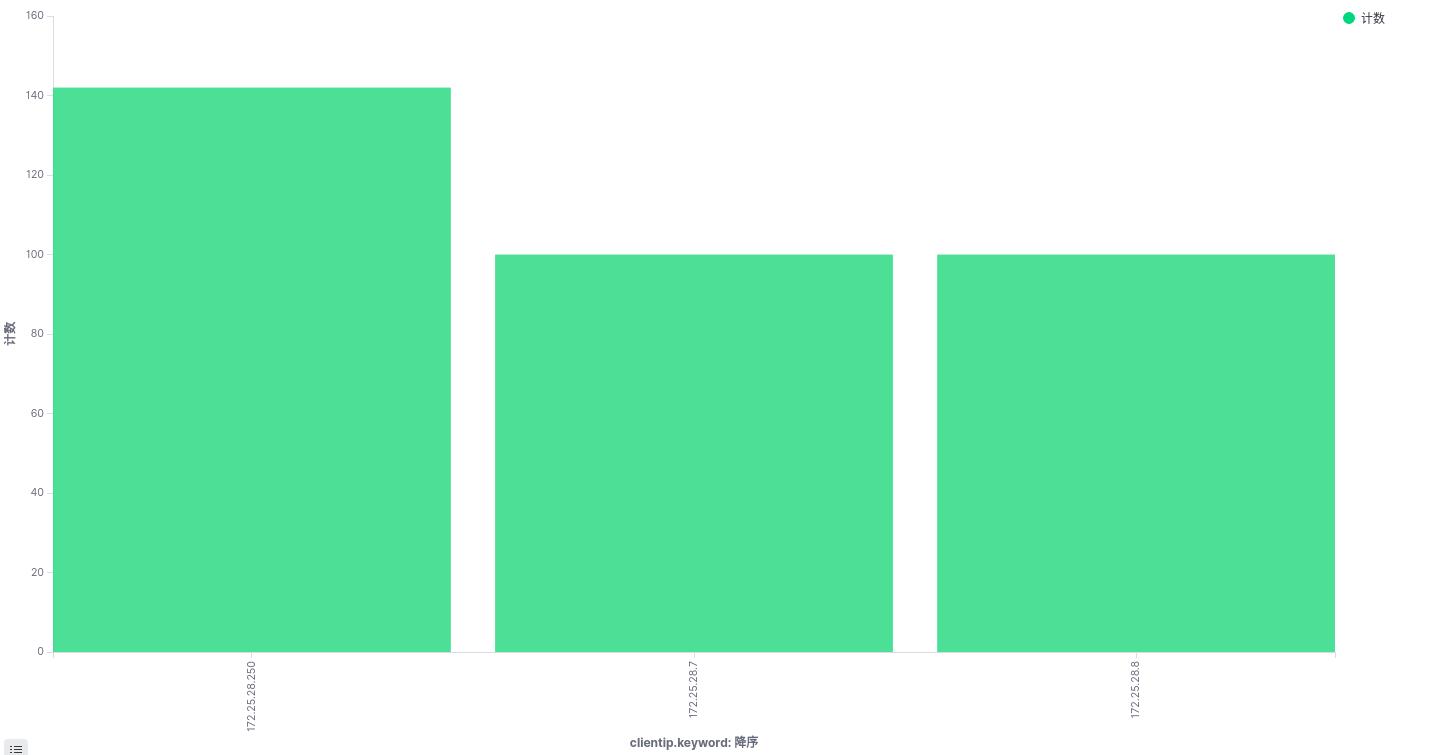
选择词来定义,使用客户ip作为X轴,降序排列,top5看最高的前五名,点击执行
注意时间范围!!!
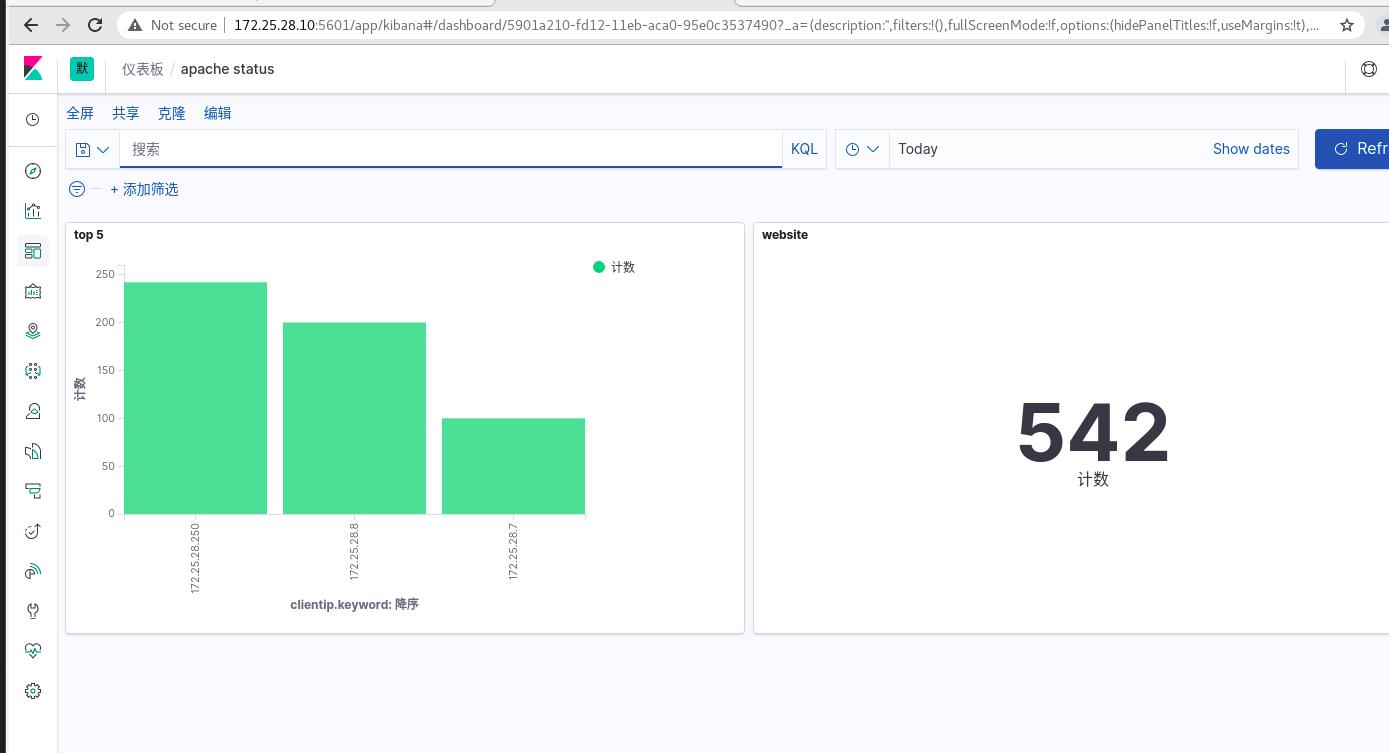
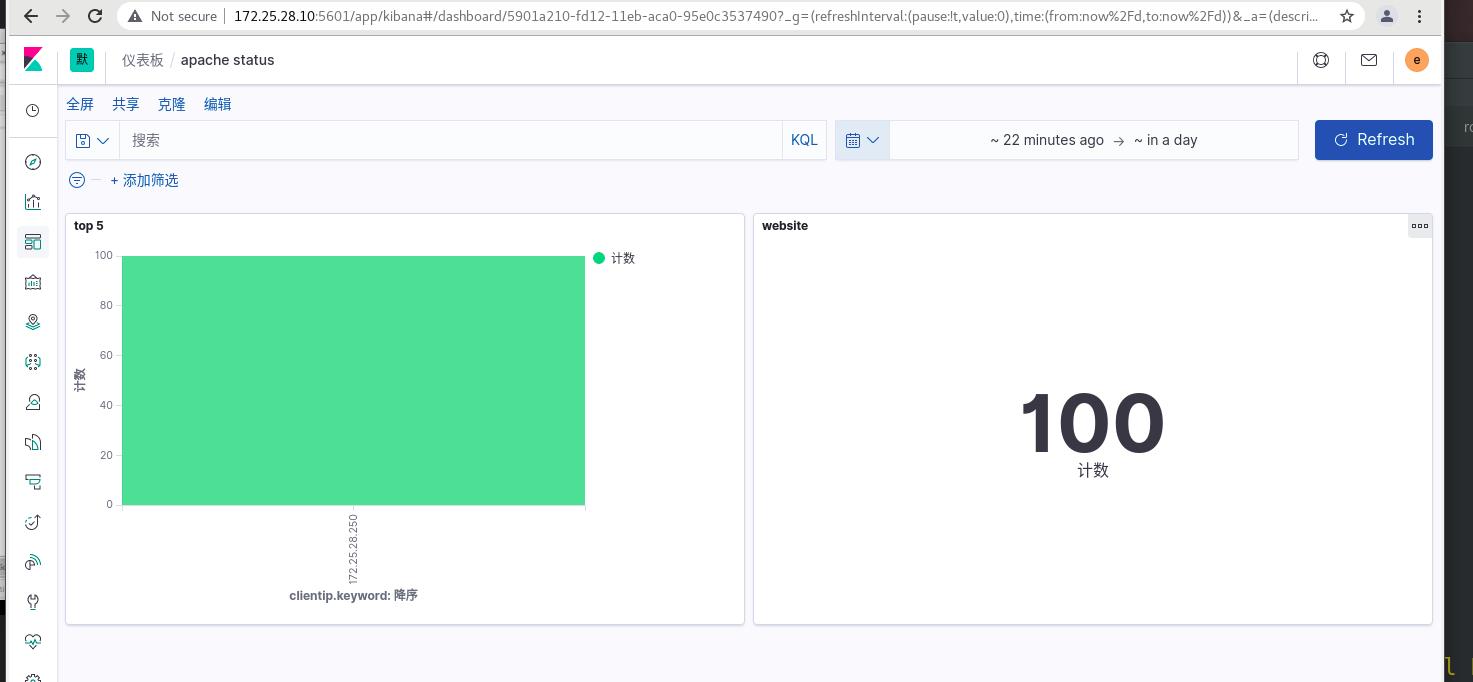
可以看到条形图,可以不同主机访问的次数!!!
保存
将条形图与总次数添加在一起,
仪表板 ----> 添加
添加websit和top5
可以看到访问总次数和媚态主机的访问次数,可以实时监控数据信息
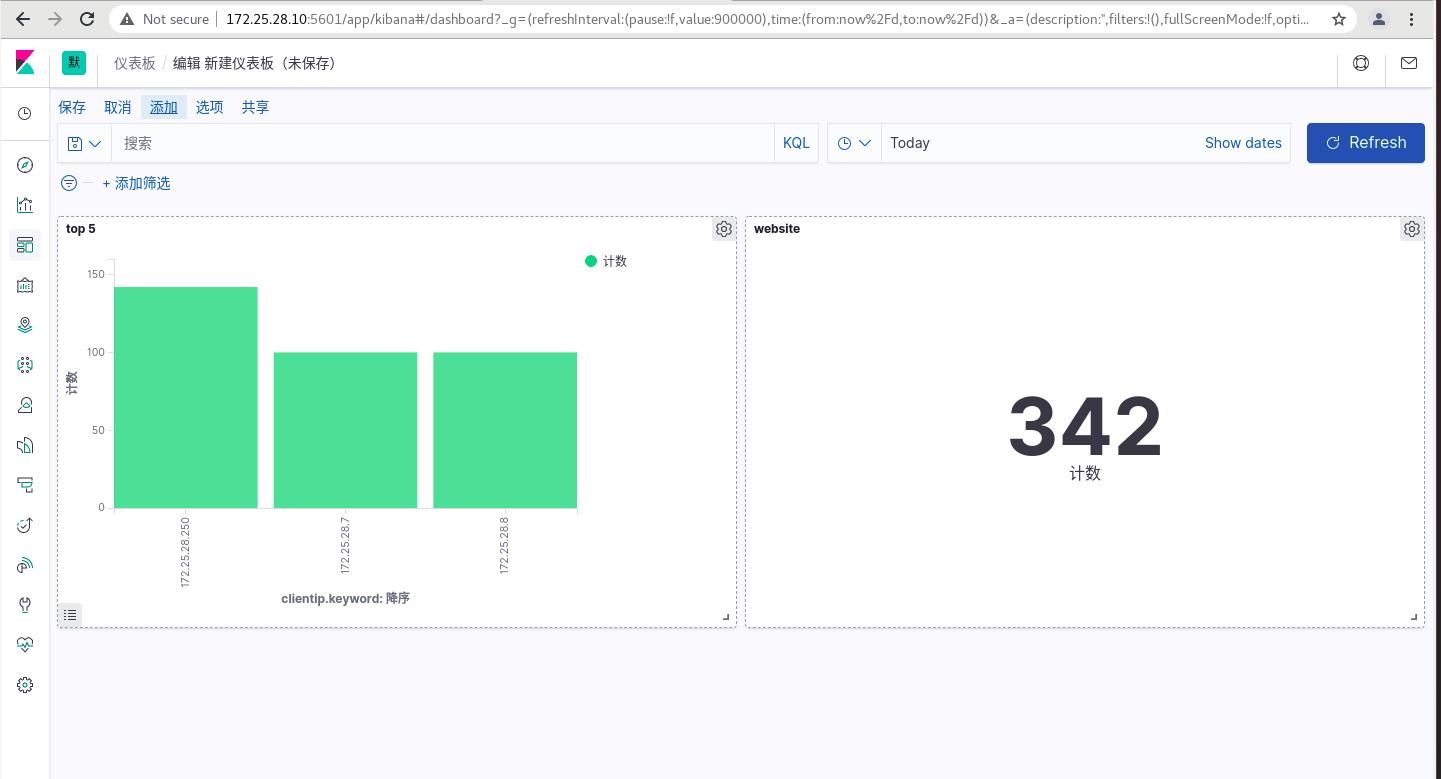
保存
server8再次压力测试
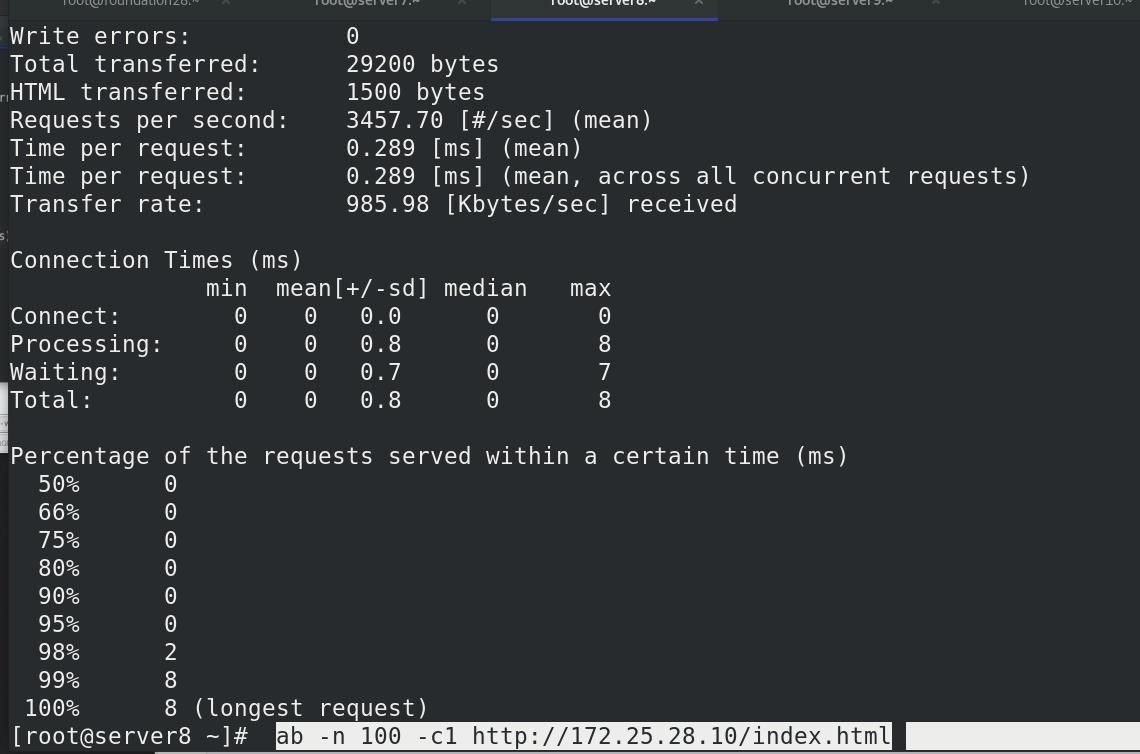
实时数据监测!!!

真机再次压力测试
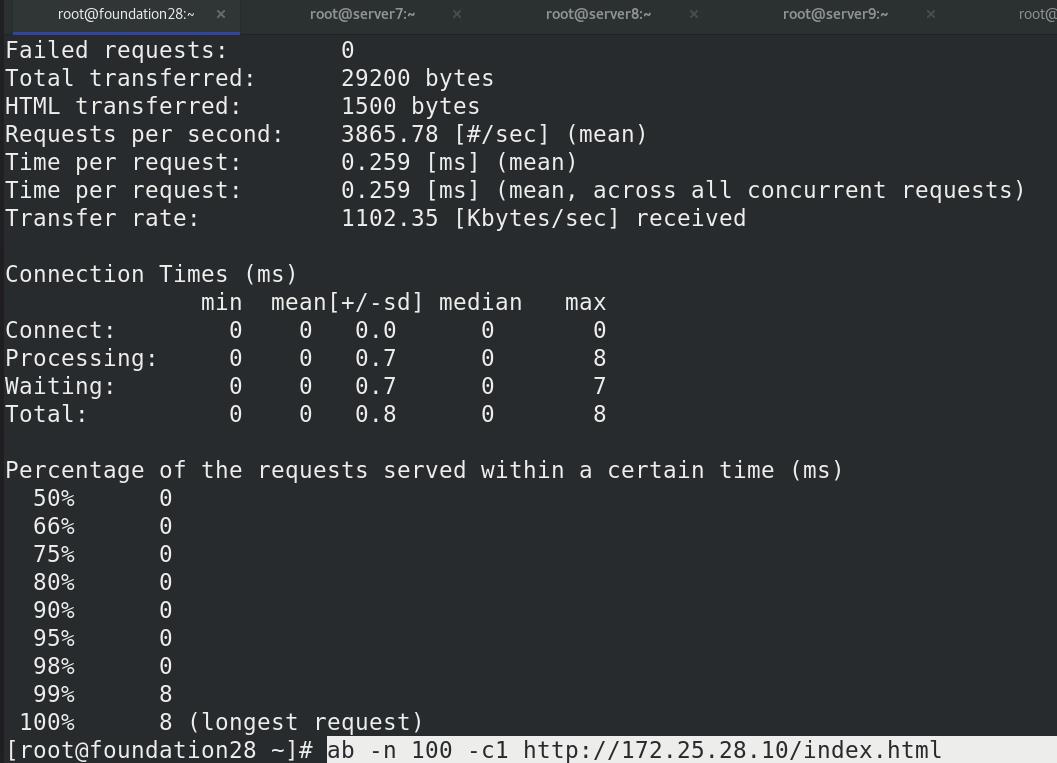
实时数据监测!!!
ES集群采集指标的一些方式:
1 普通ELK架构 :logstash--->ES --> kibanna
2 企业ELK架构:filebeat(所有节点都要部署)---> kafka/redis ----> ES --> kibanna
3:很多filebeat(所有节点都要部署):filebeat---> logstash---> ES --> kibanna
4:filebeat(所有节点都要部署)---kafaka(消息队列,作缓冲)--->(多加几个消费者,从kafaka消费)logstash----> ES --> kibanna
用到消息队列redis/kafka作为缓存使用。通过logstash搜集日志数据存入redis/kafka,再通过logstash对数据格式转化处理后储存到Elasticsearch中。
三 集群内部采集 xpack
获取ES集群的监测数据,内置监控xpack,ES集群启用xpack安全验证
首次进入会报错,原因是未开启xpack安全验证
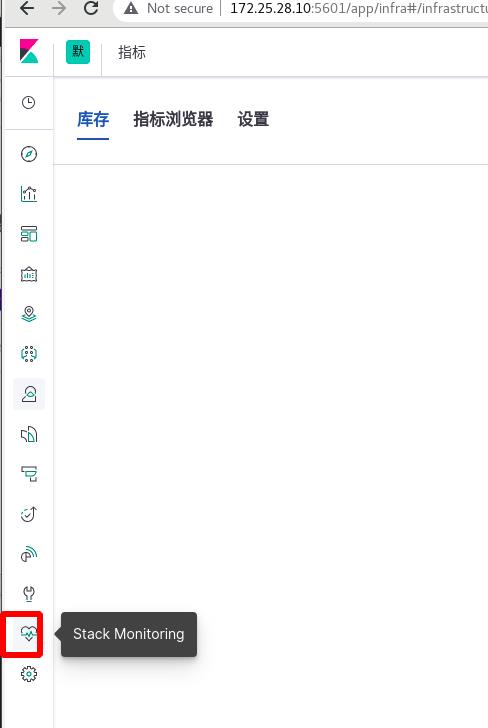
要求ES集群支持xpark,每个节点都需要!!!
集群模式需要先创建证书,/usr/share/elasticsearch/,使用elasticsearch-certutil工具生成ca,全部回车,方便
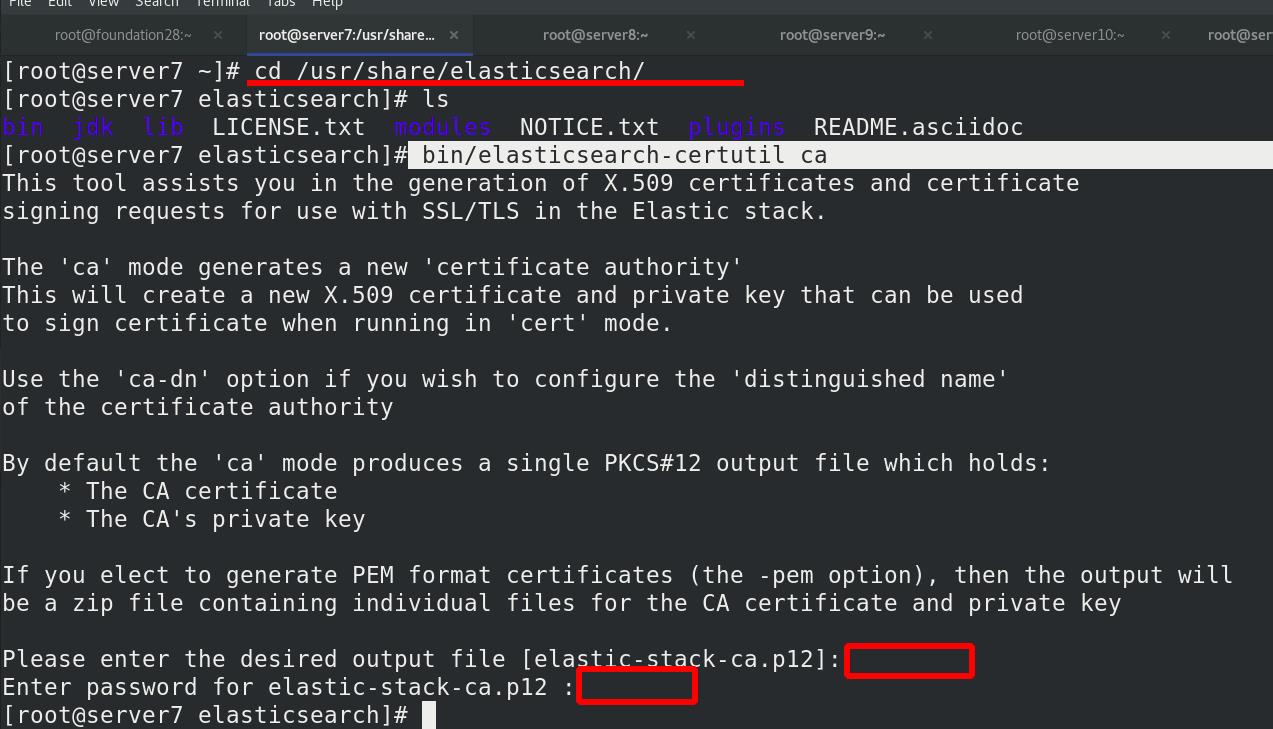

申请证书,全部回车
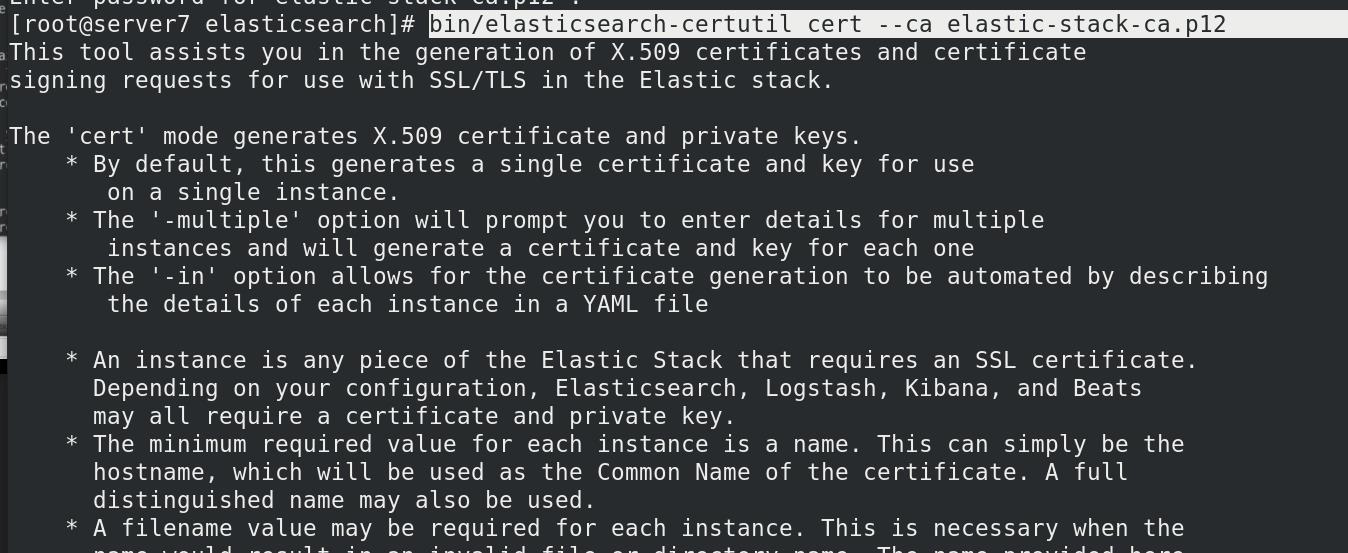
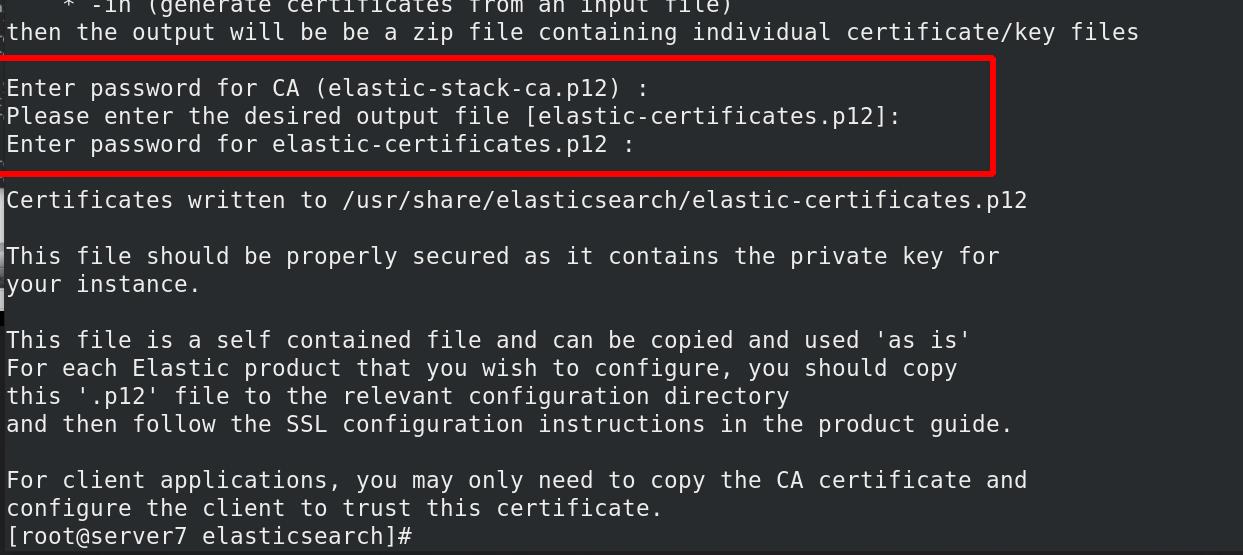
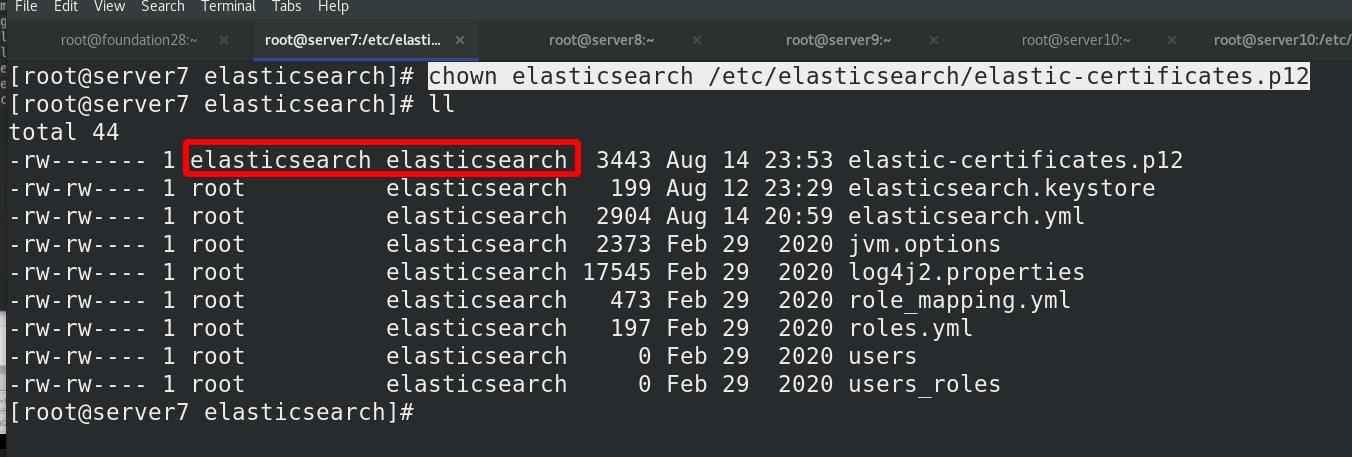
证书属性交给elasticsearch,修改权限,owner可读
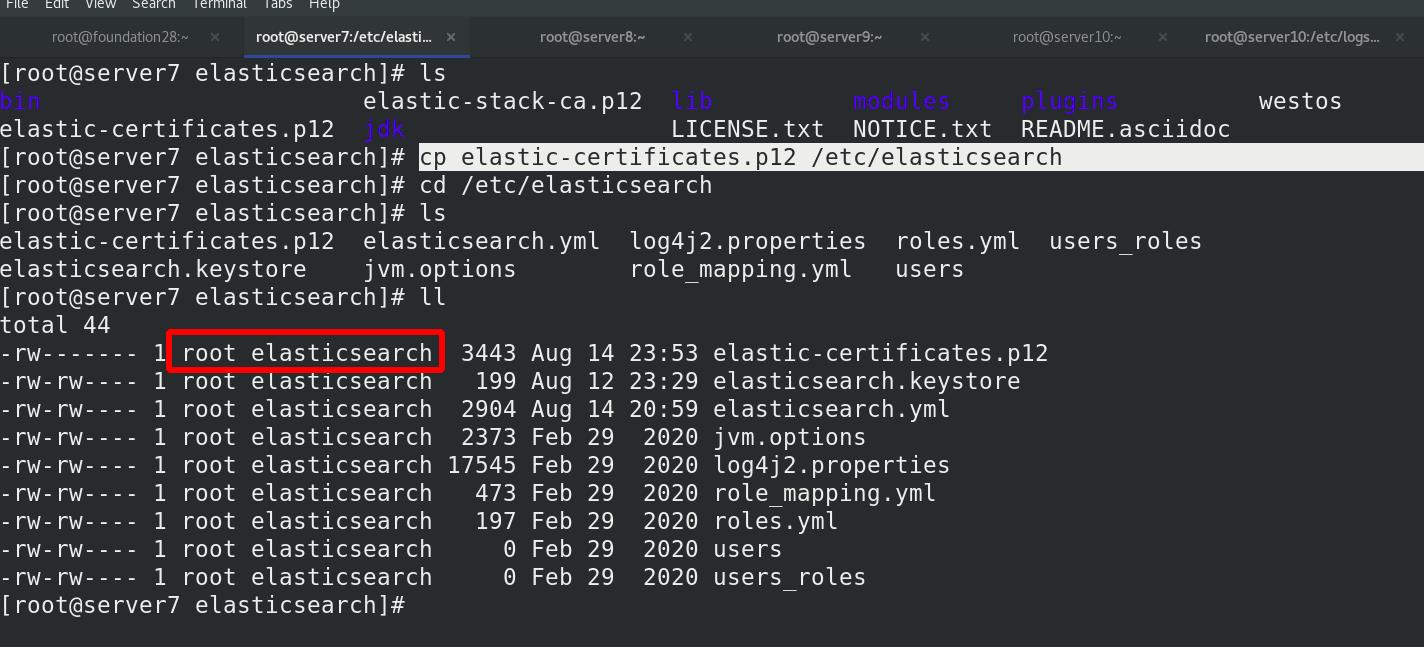
将证书复制其他ES集群节点,也可以手动创建证书
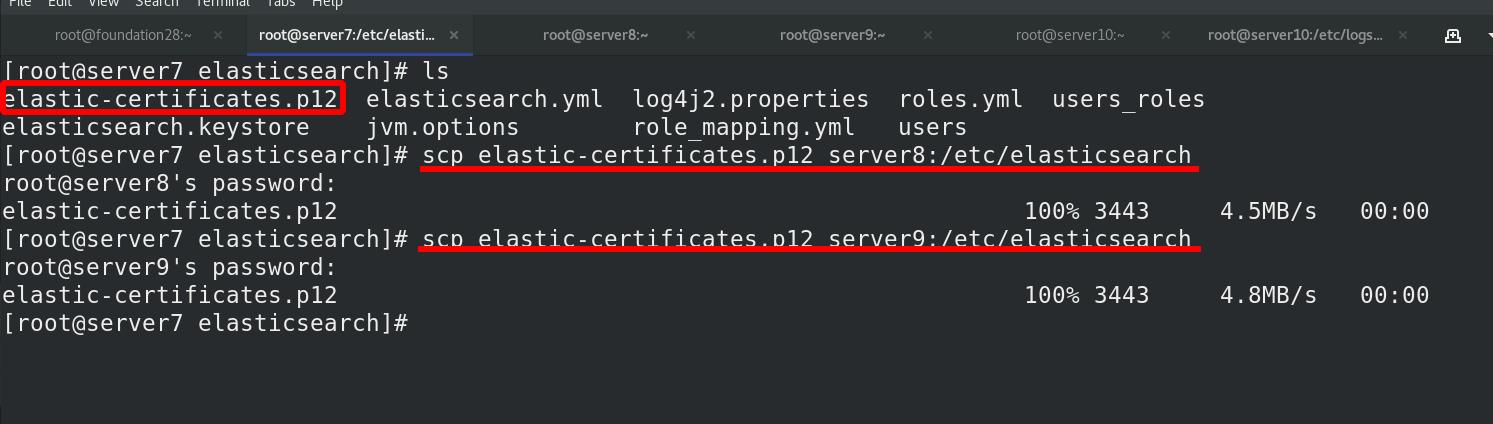

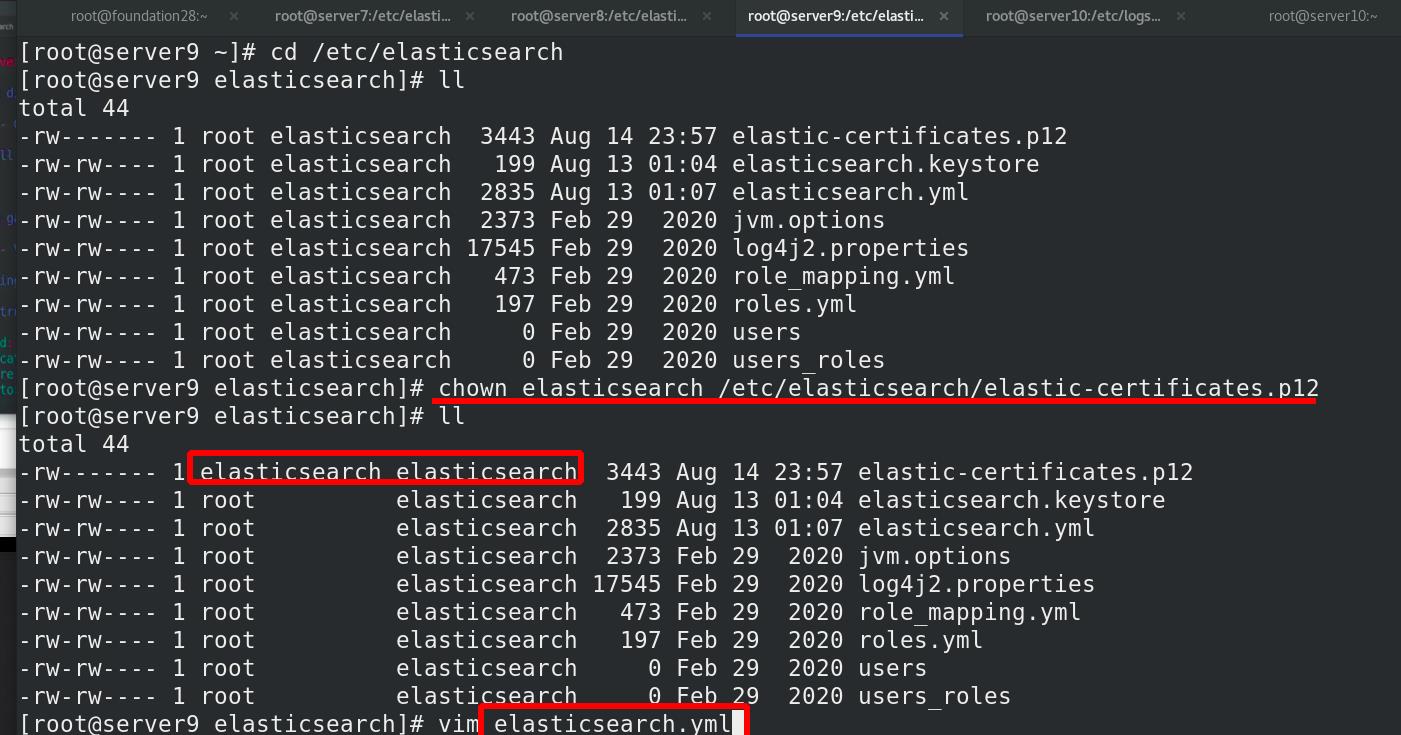
配置所有的elasticsearch集群节点,同步所有节点,被elasticsearch识别
修改elasticsearch的主配置文件



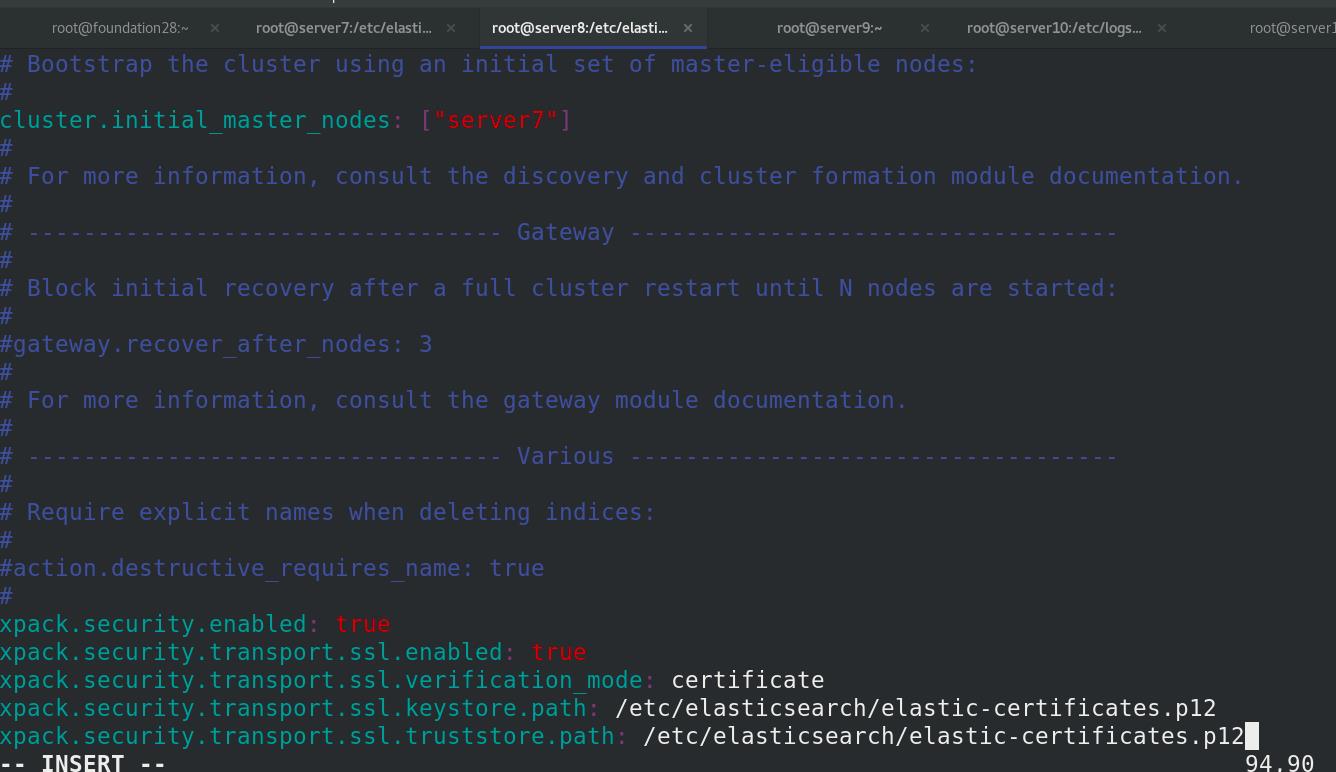
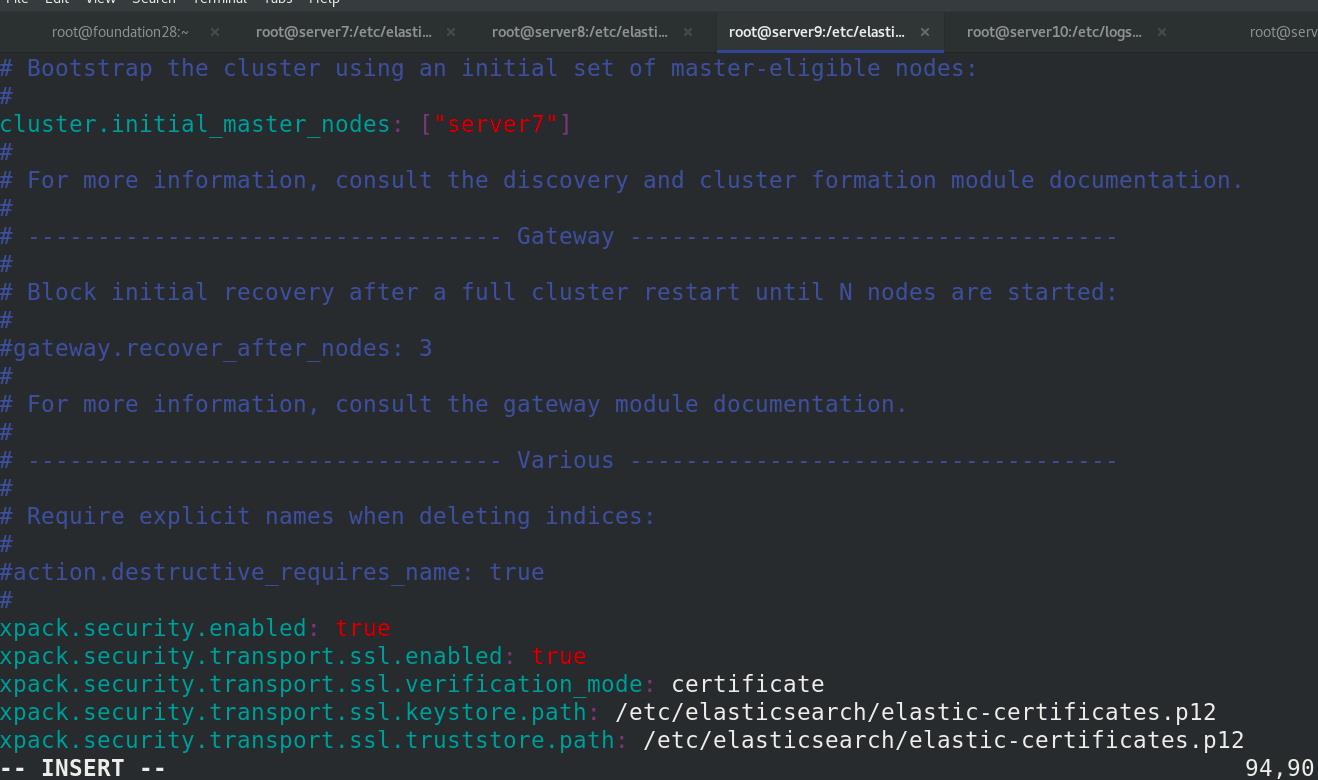
ES集群重启



查看9200端口正常启动,es集群正常



设置用户密码
交互auto默认随机密码和非交互interactive
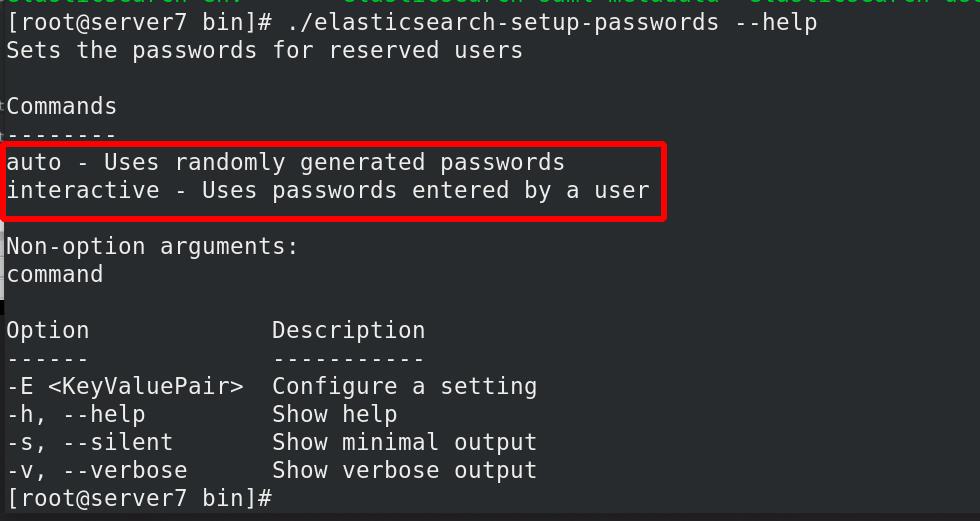
设定交互式设置用户密码全部为westos
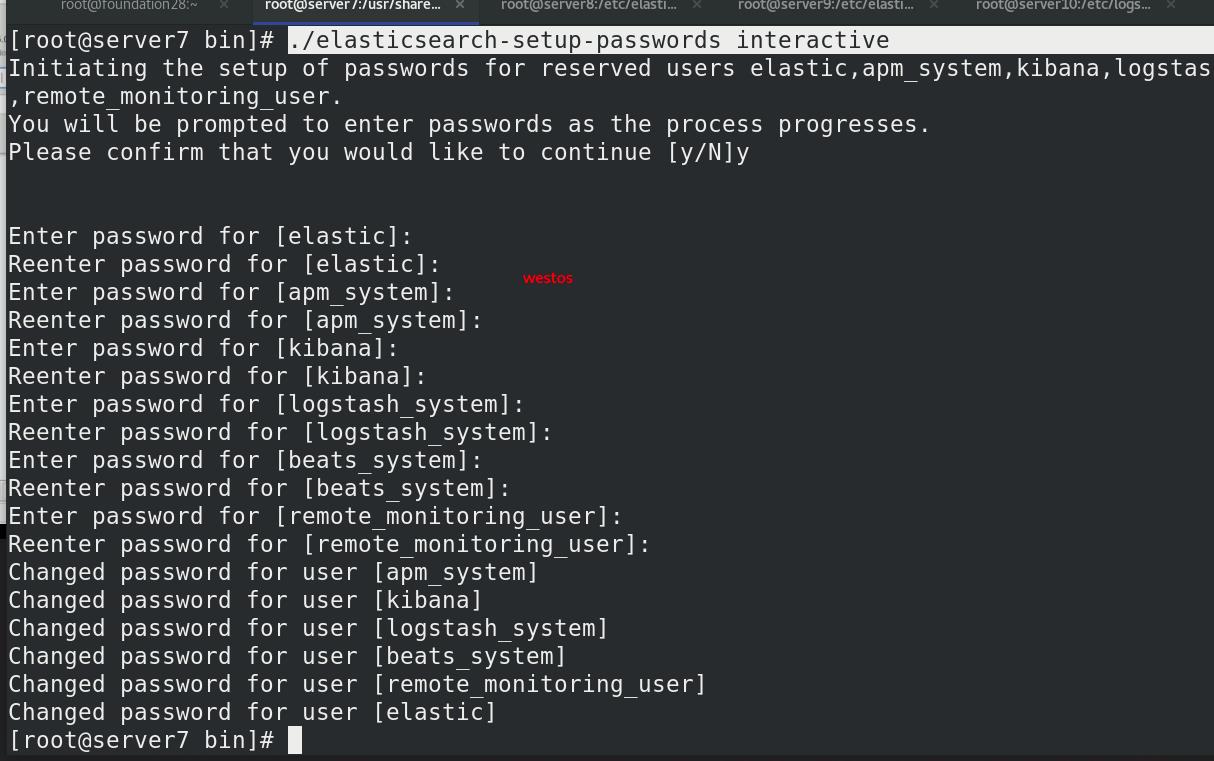
设定kibana
kibana连接es集群的用户密码写入kibana主配文件
 重启kibana,5601端口正常
重启kibana,5601端口正常
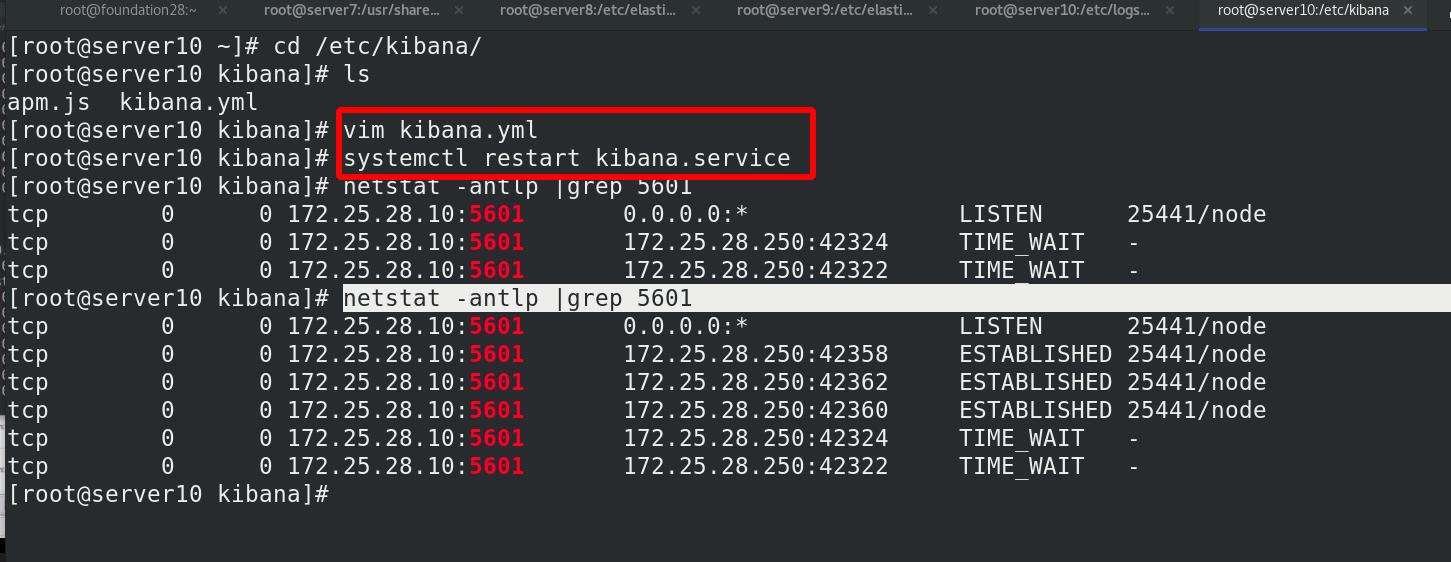
设定logstash
设置Logstash连接ES用户密码:
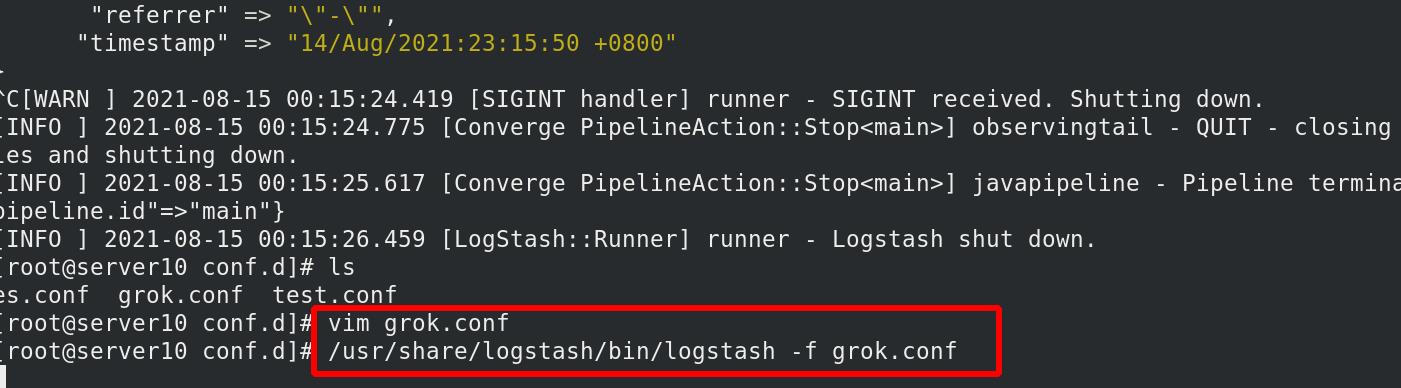
设定es集群监控访问
(1) es-head访问,无法连接
添加参数到es配置

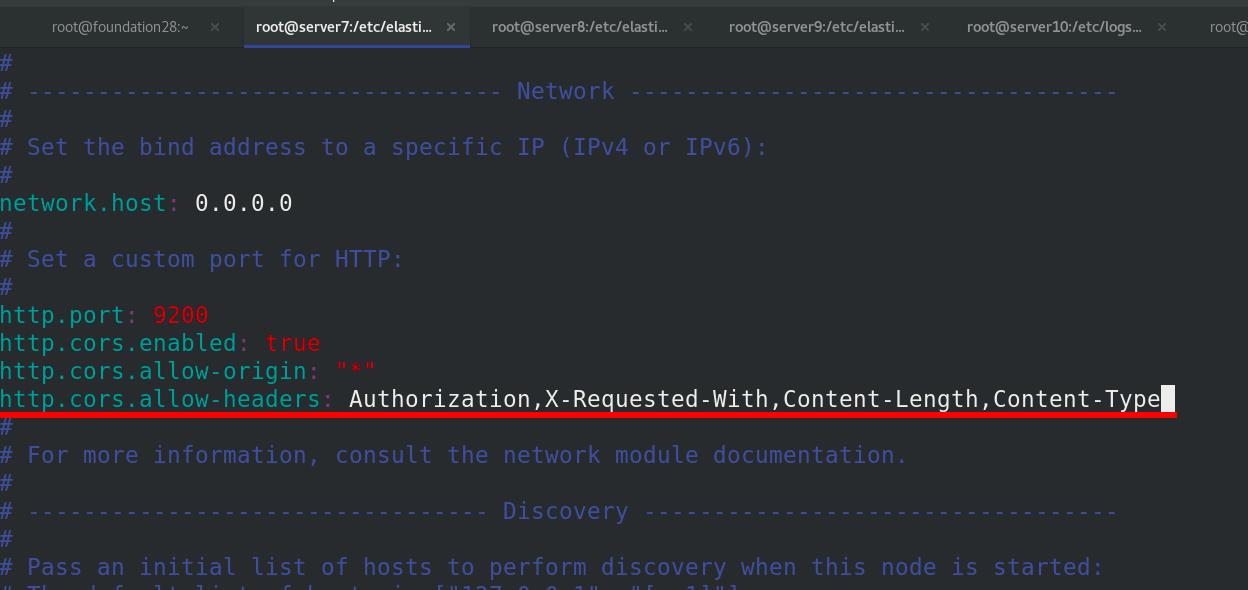
监控访问需要认证http://172.25.28.7:9100/?auth_user=elastic&auth_password=westos
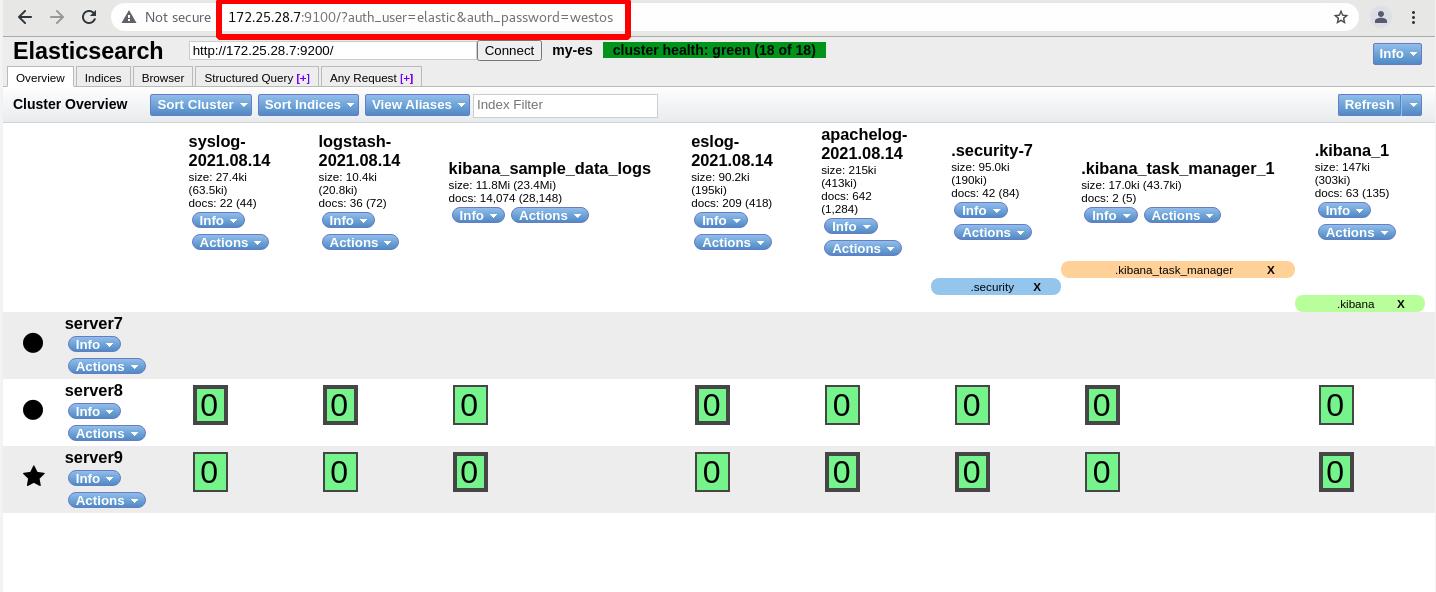
(2) podman方式监控访问:
不要加参数,直接加认证就可以

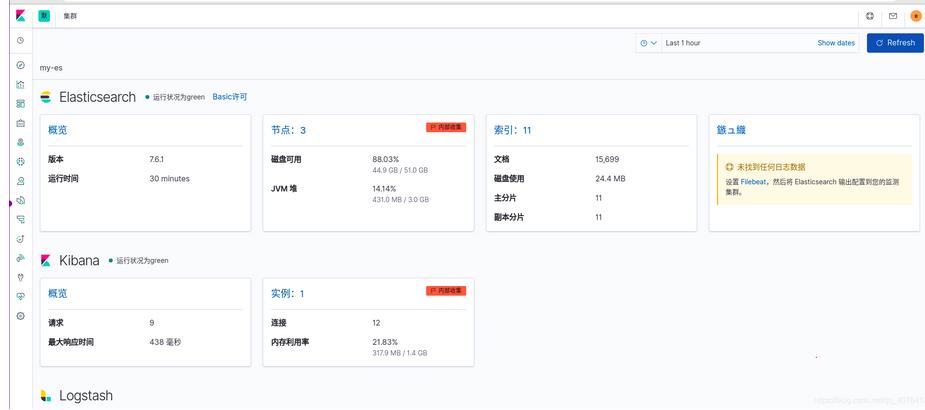
kibanna正常采集到数据
选择apachelog
压力测试
产生新的访问量apachelog
由于之前仪表板未保存成功,是新的数据
内部采集方式重新查看
可以实时看到监控的apache访问量的数据
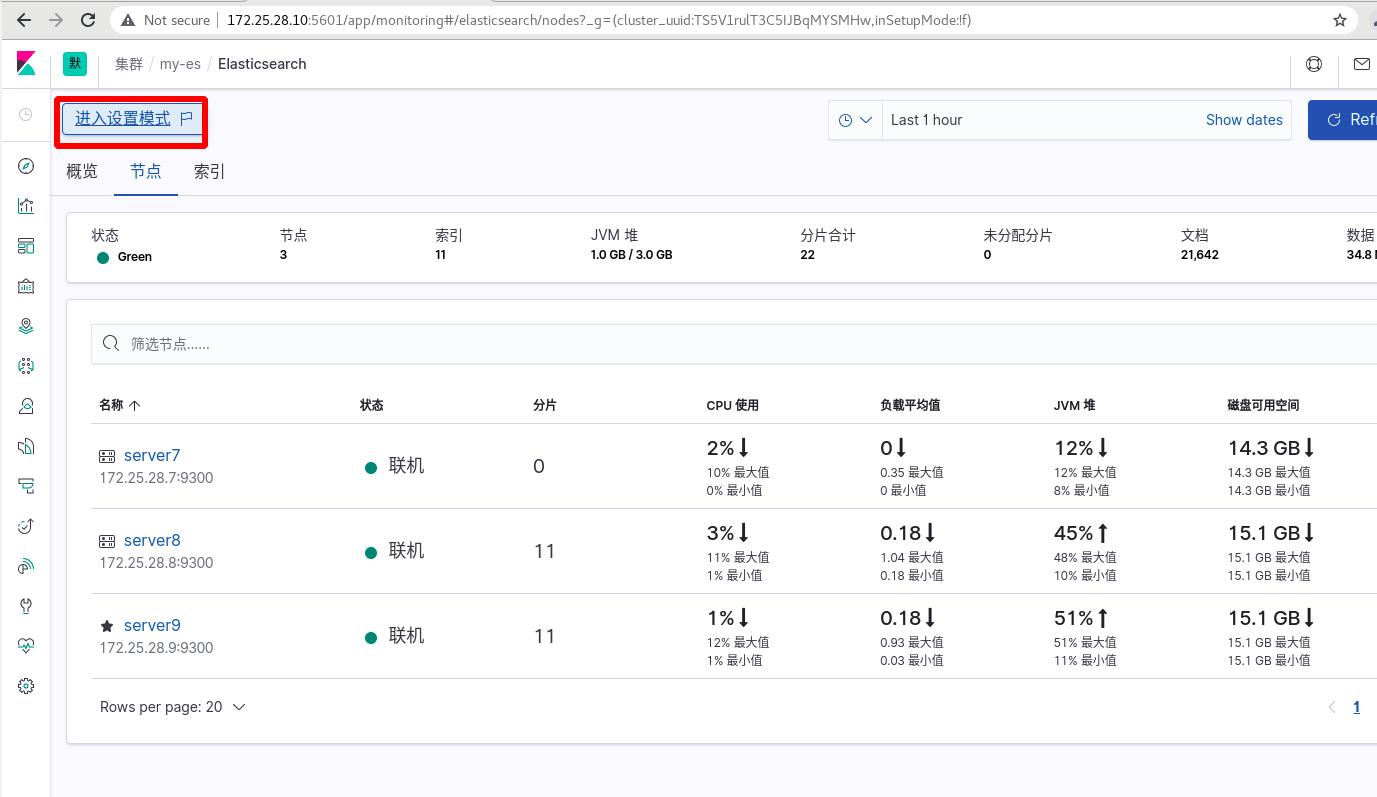
四 集群信息采集之插件采集(轻量级)
1 metricsbeat
metrics监测ES集群,跳过logstash,直接监测集群
实验环境:
server7,8,9为业务集群
写另外的ES集群,需要重新搭建,此处我们还是使用原来的集群
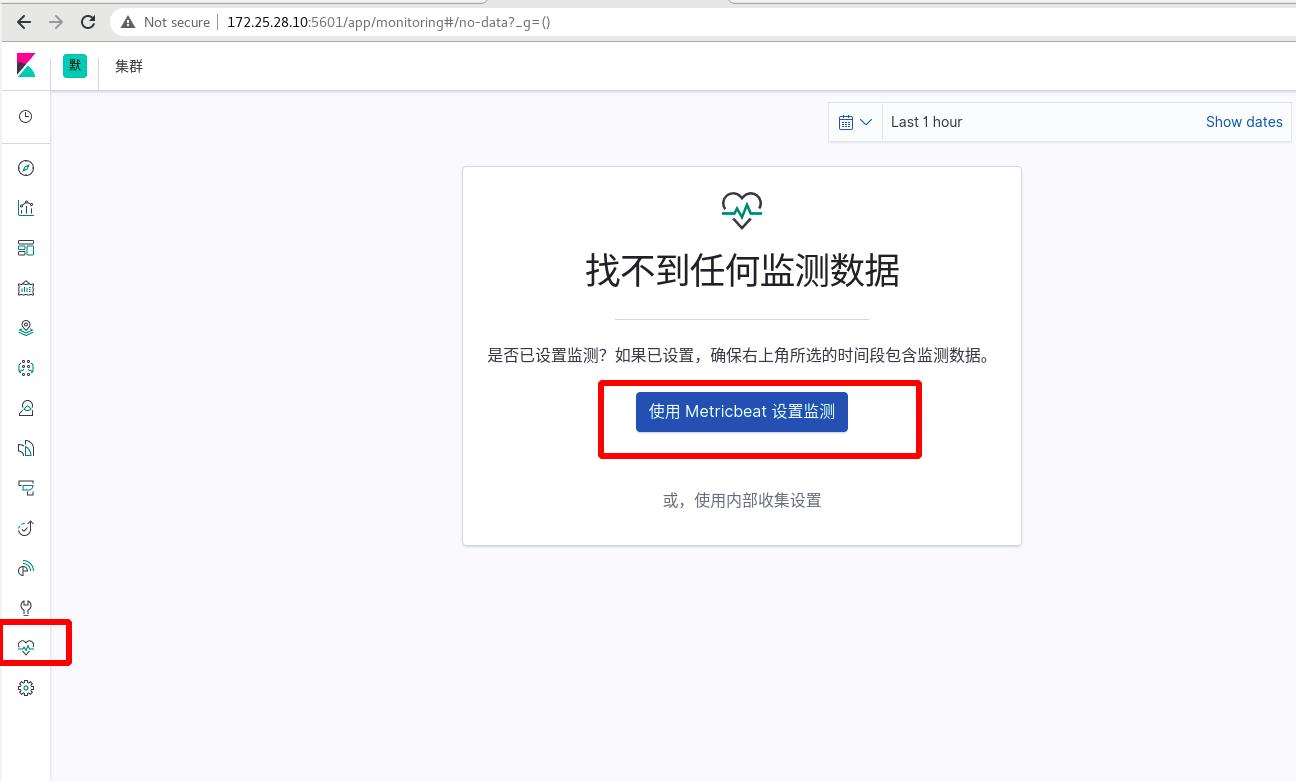
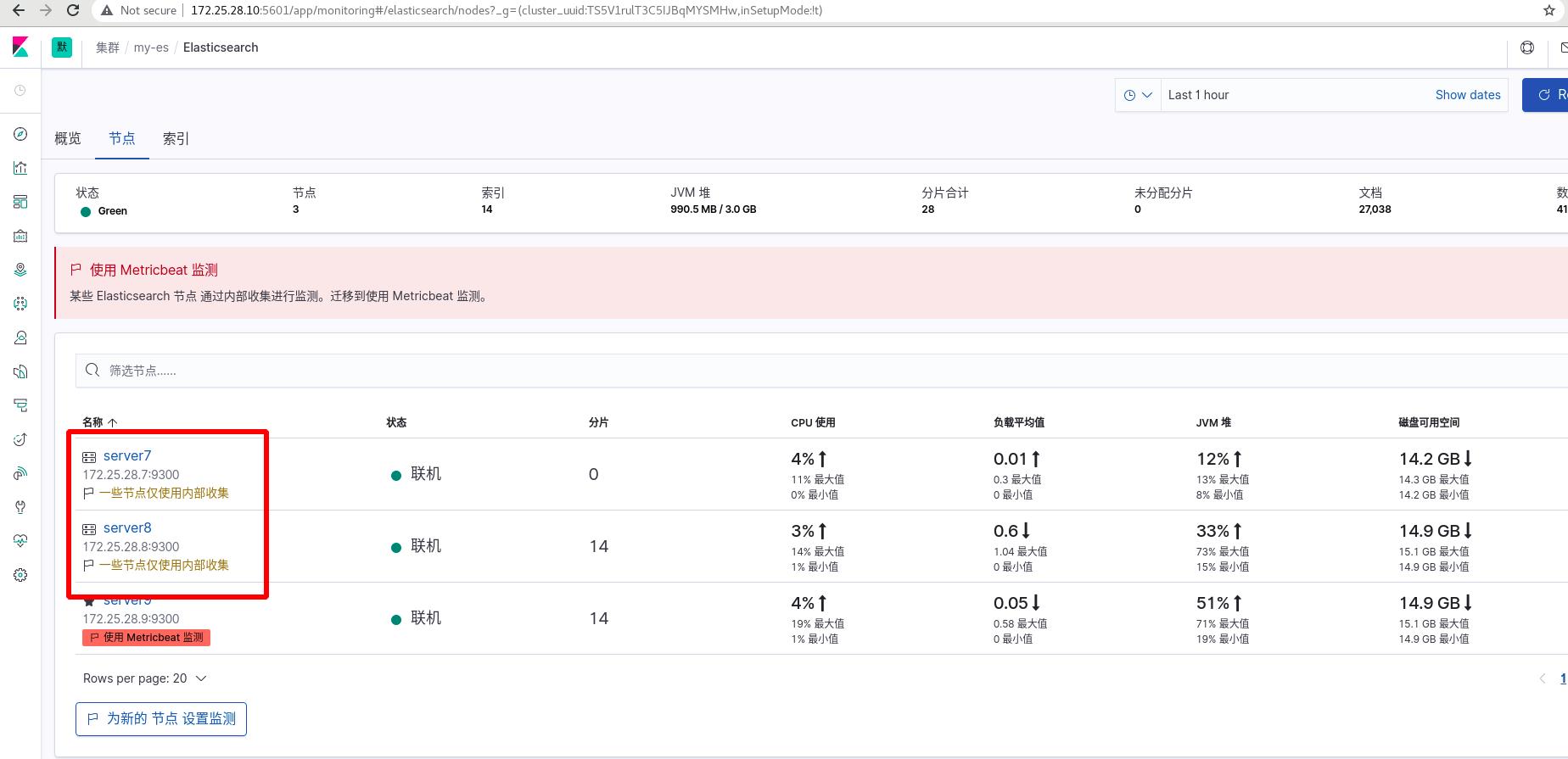
点击使用metricbeat,现在是红色的,还不可用,输入监测集群URLhttp://172.25.28.7:9200,会出现提示操作
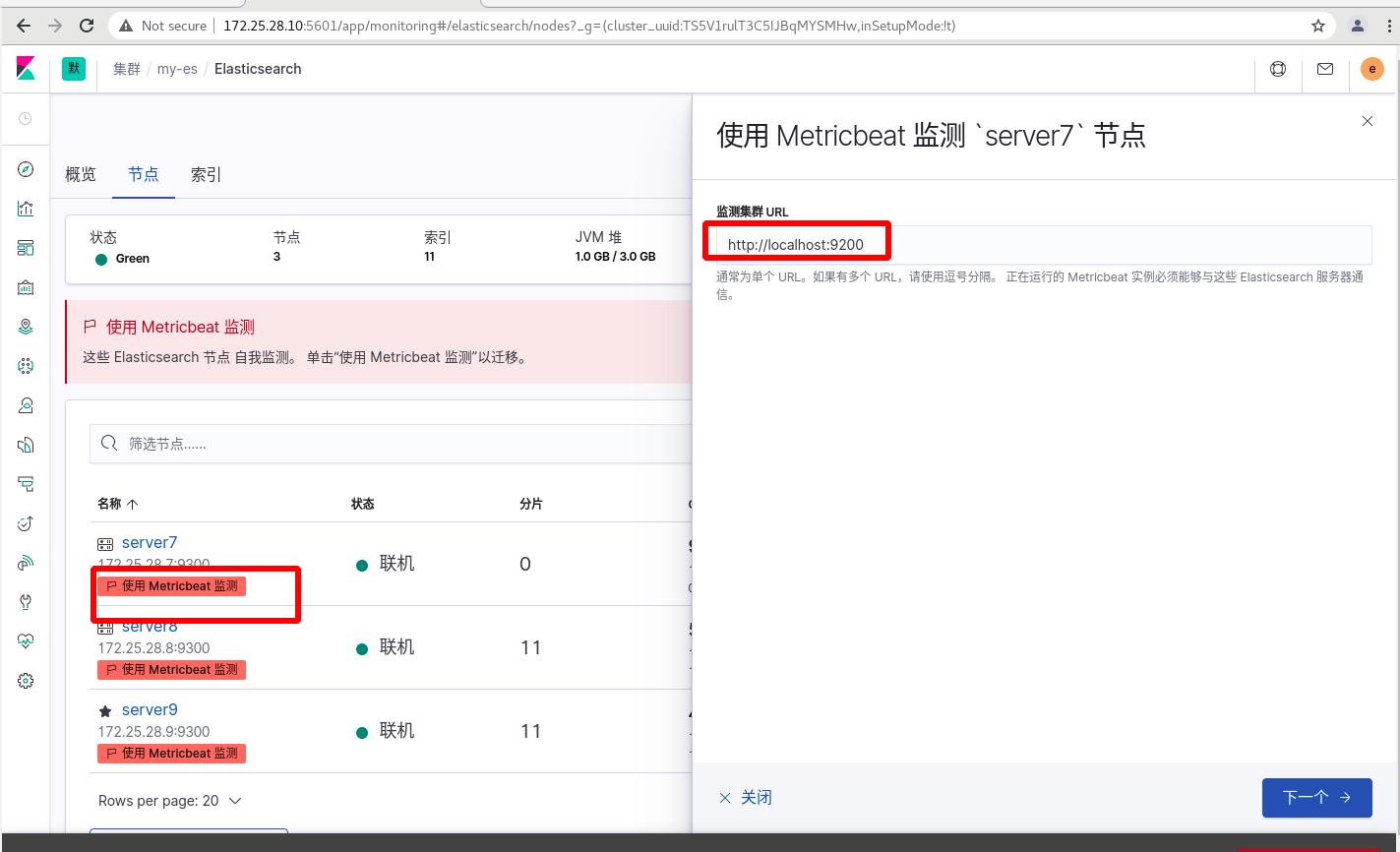
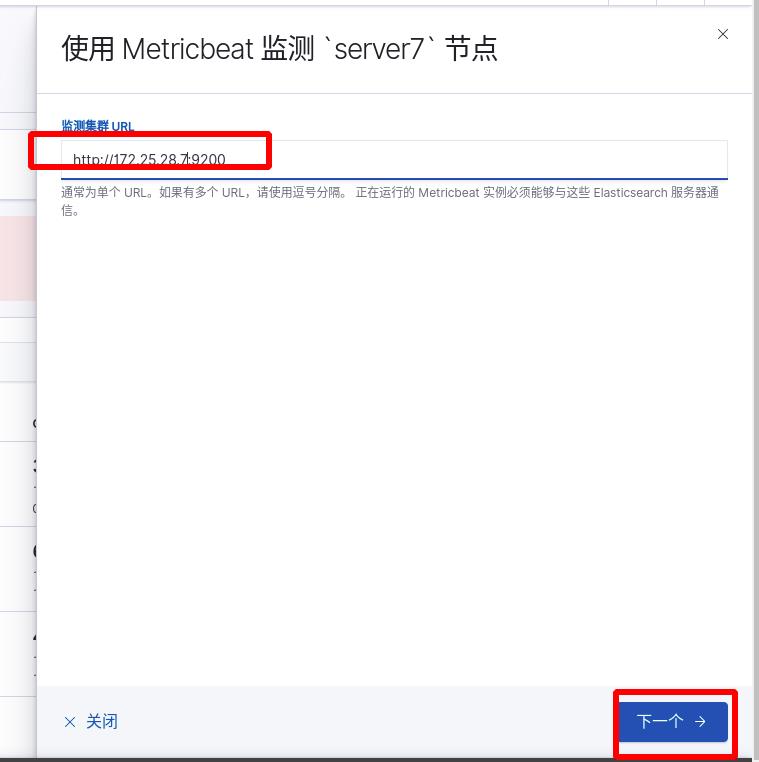
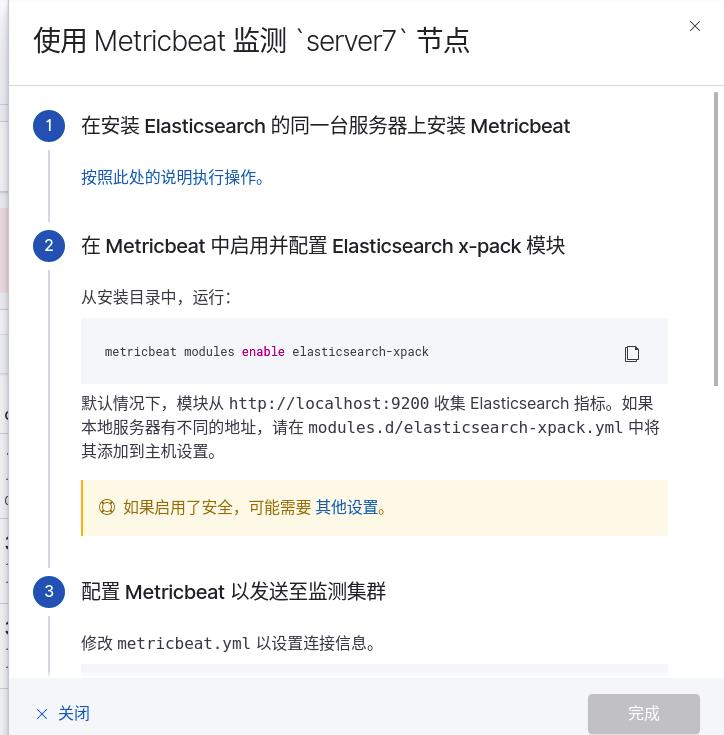
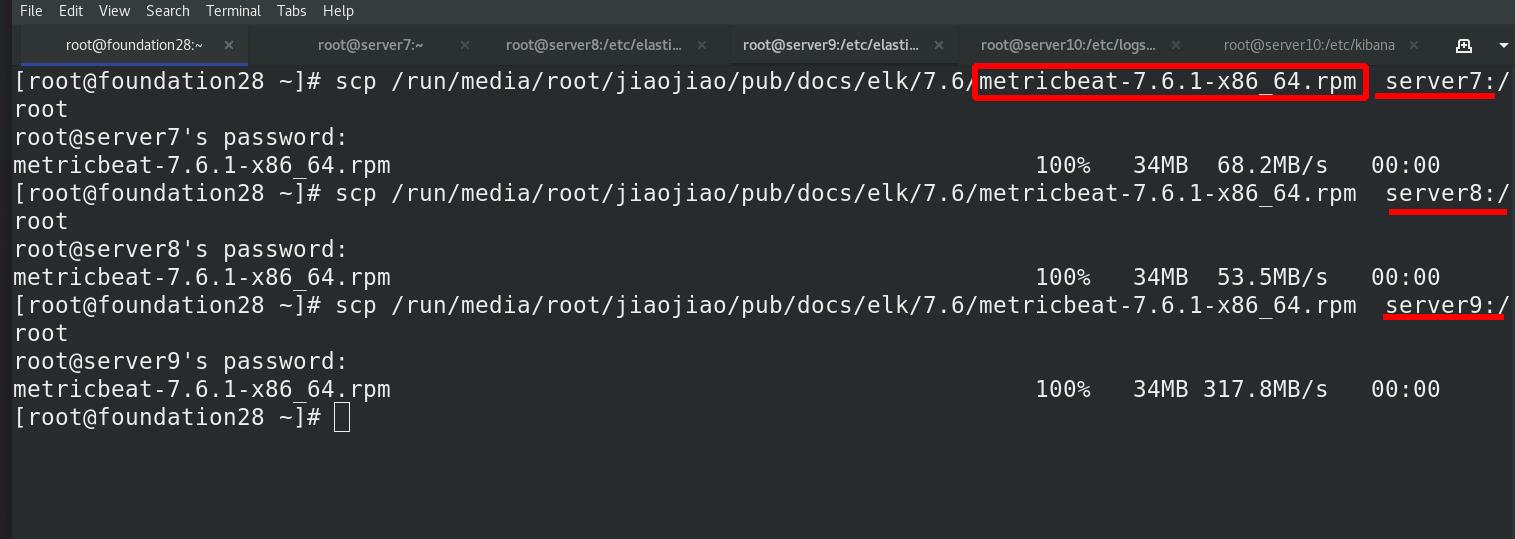
所有ES集群节点均需要安装metricbeat
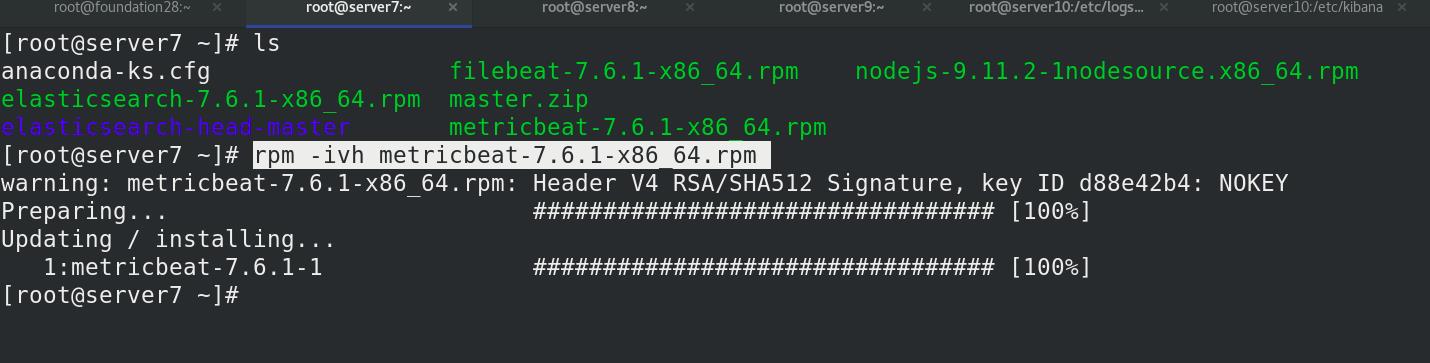
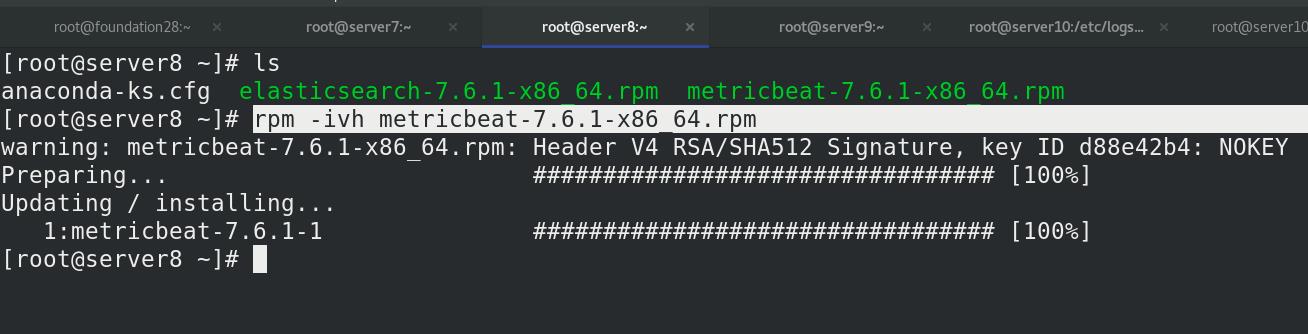
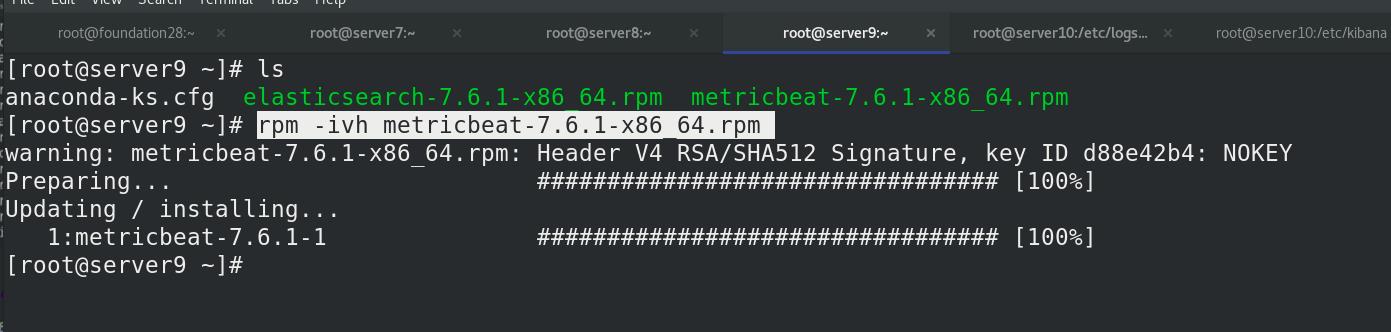
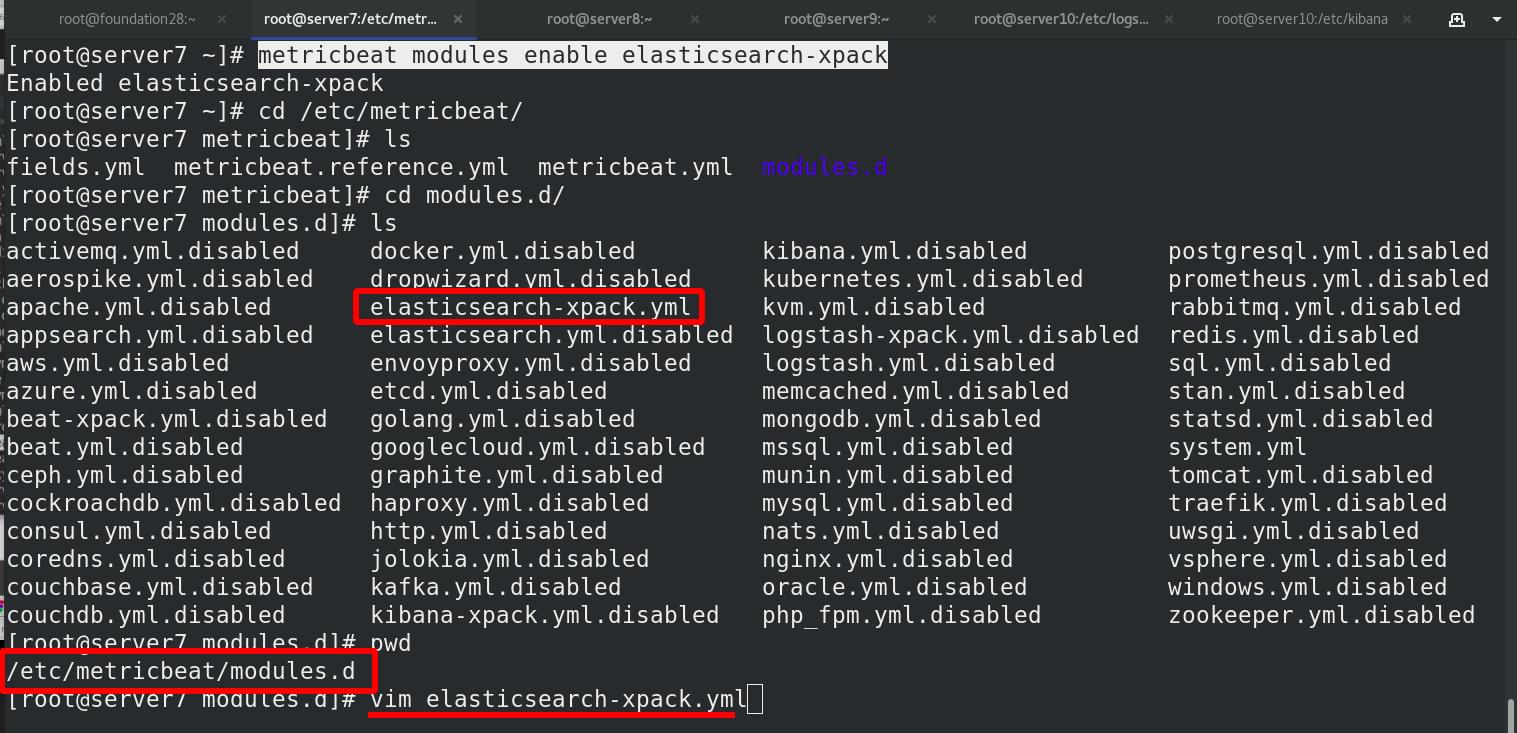
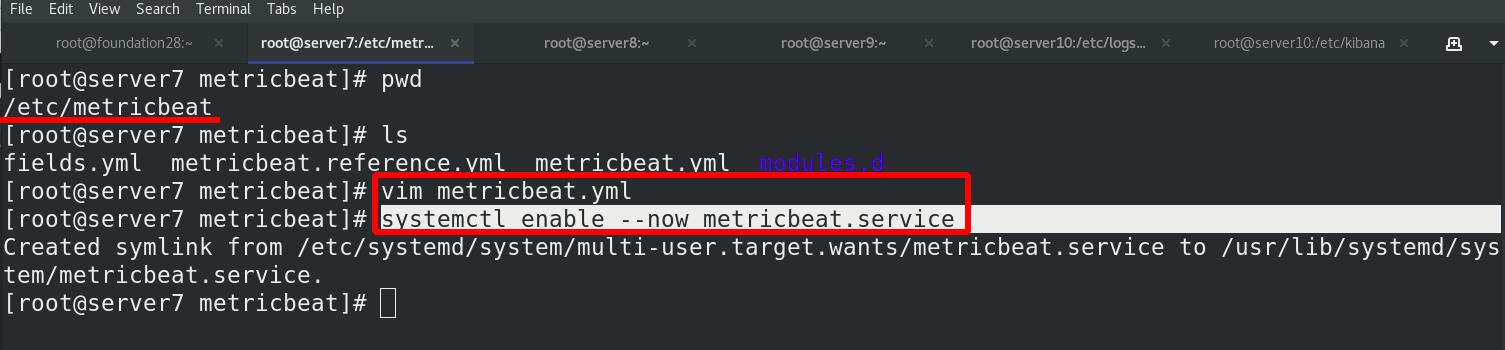
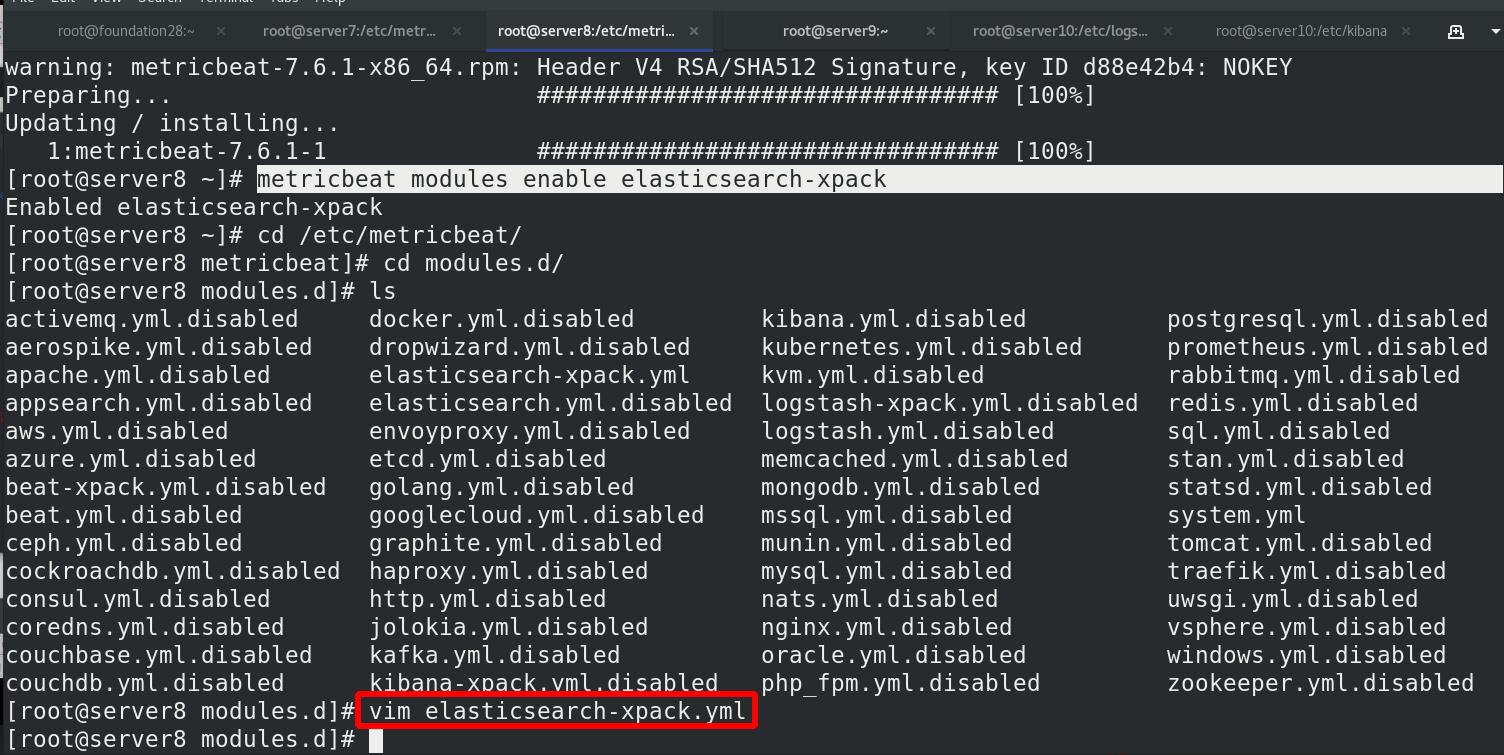
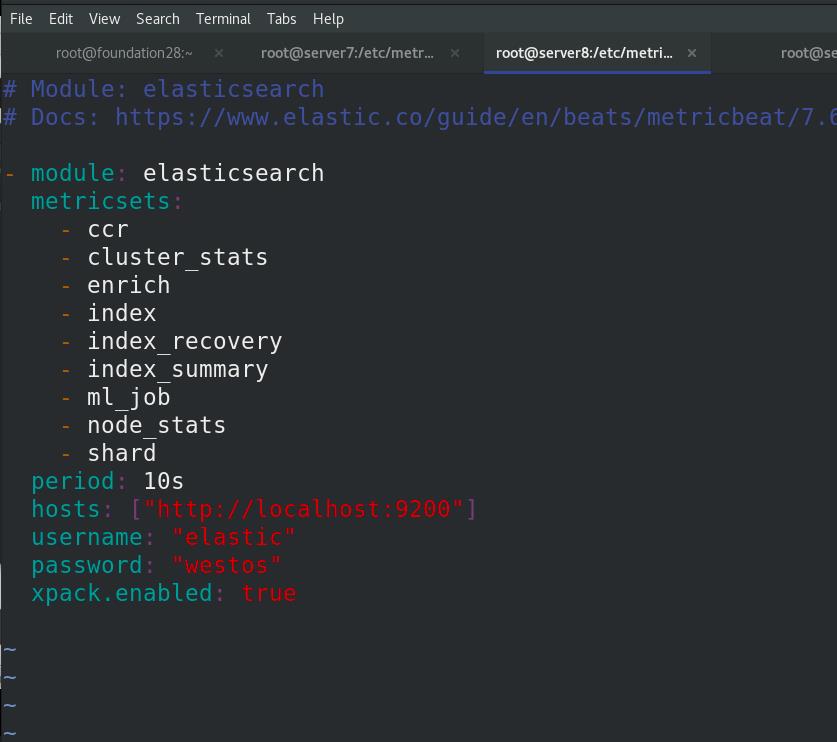
server7 激活elasticsearch-xpack模块,进入/etc/metricbeat/modules.d查看全部模块,可以看到很多文件后面带个disable表示未激活,elasticsearch-xpack已被激活,其实激活命令本质上就是改文件的名字,编辑elasticsearch-xpack.yml文件
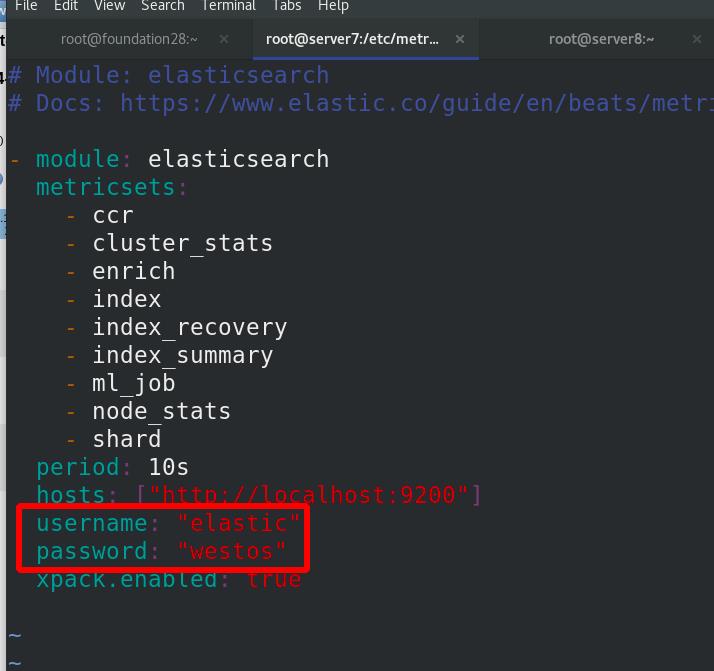
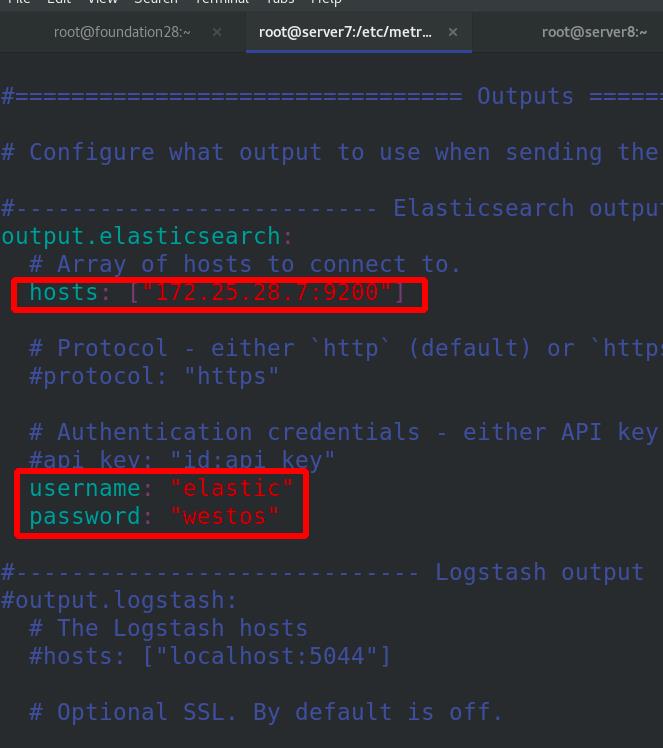
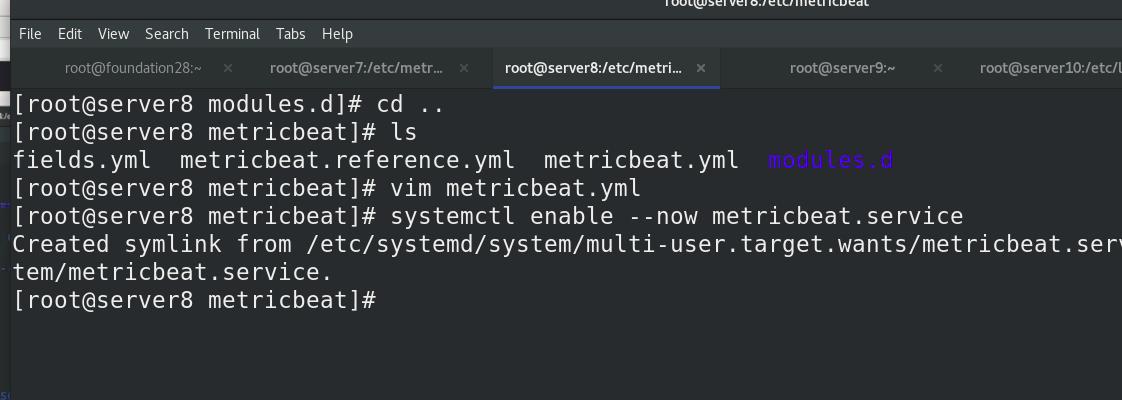
编辑metricbeat主配置文件,启动metricbeat
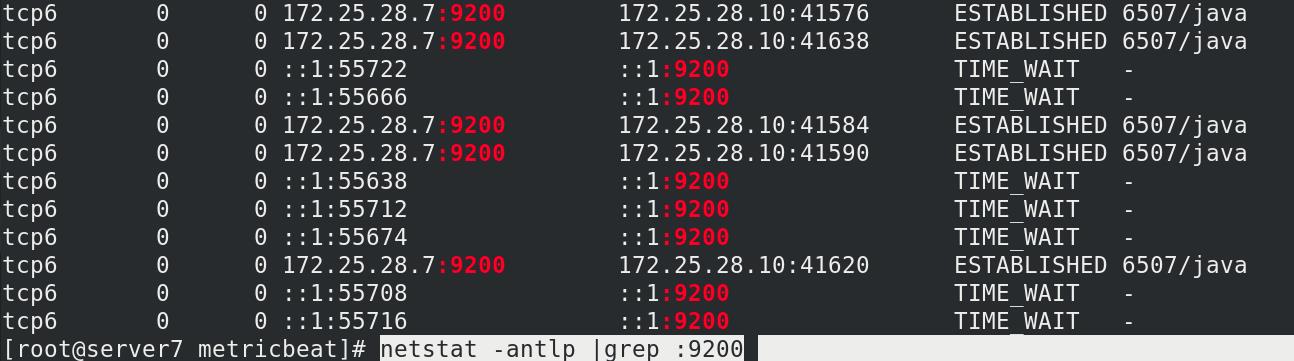
查看9200端口
此时server7可以使用metricsbeat插件进行监控
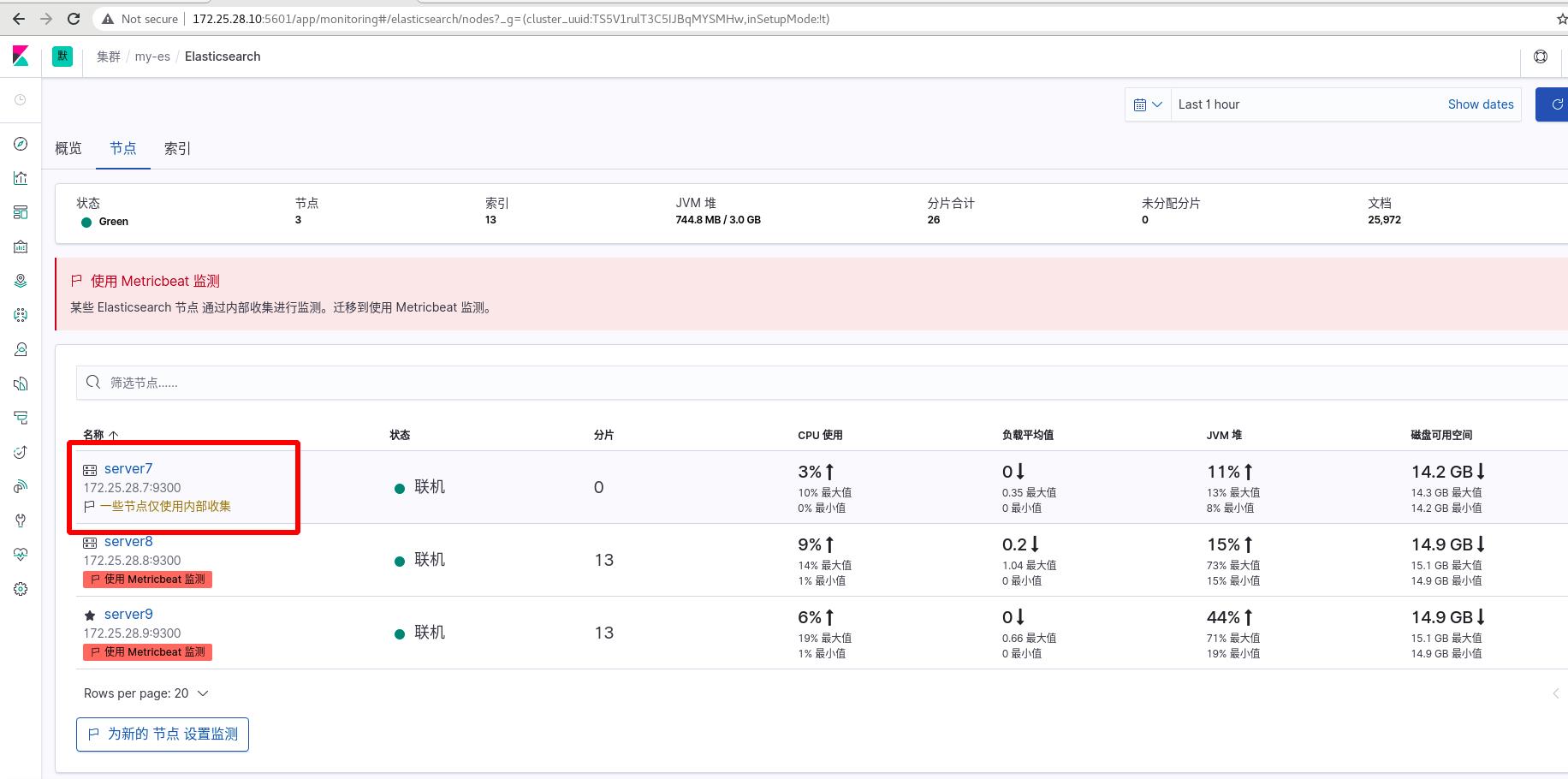
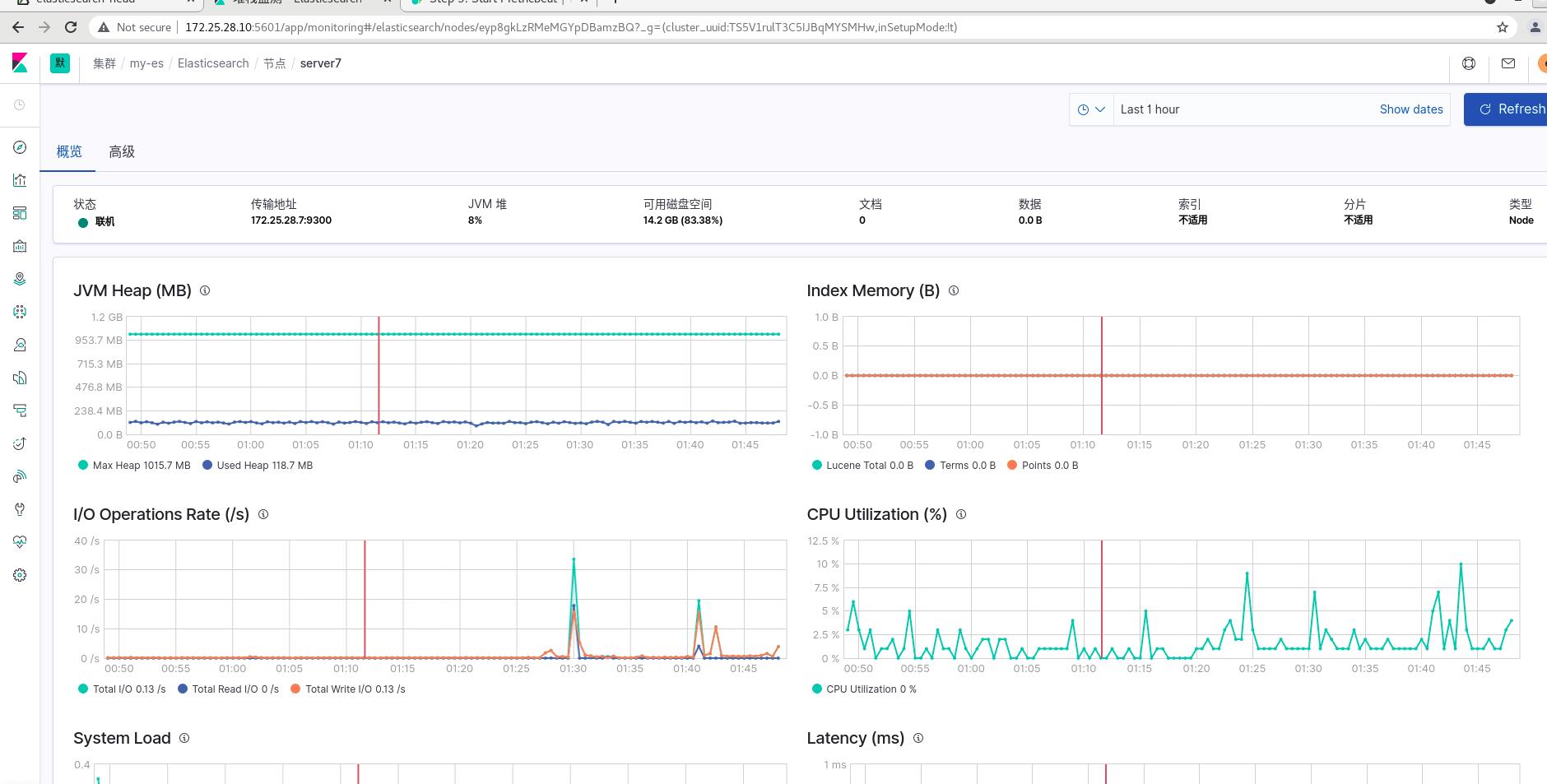
server8和server9同样操作
server9设定
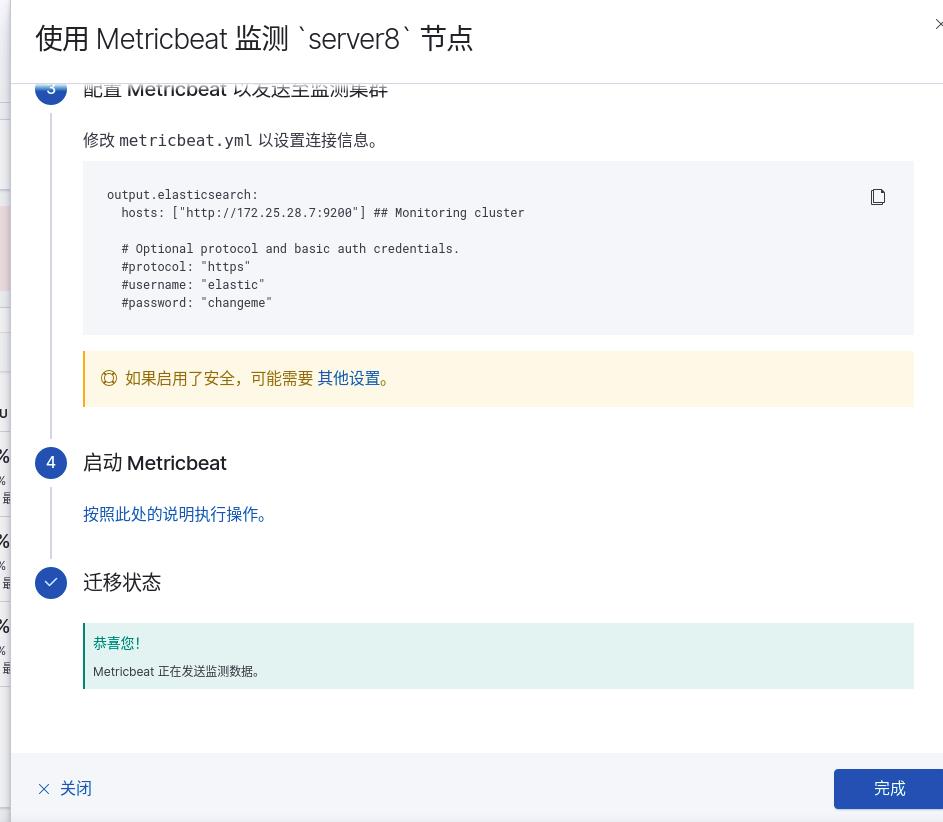
server9设定
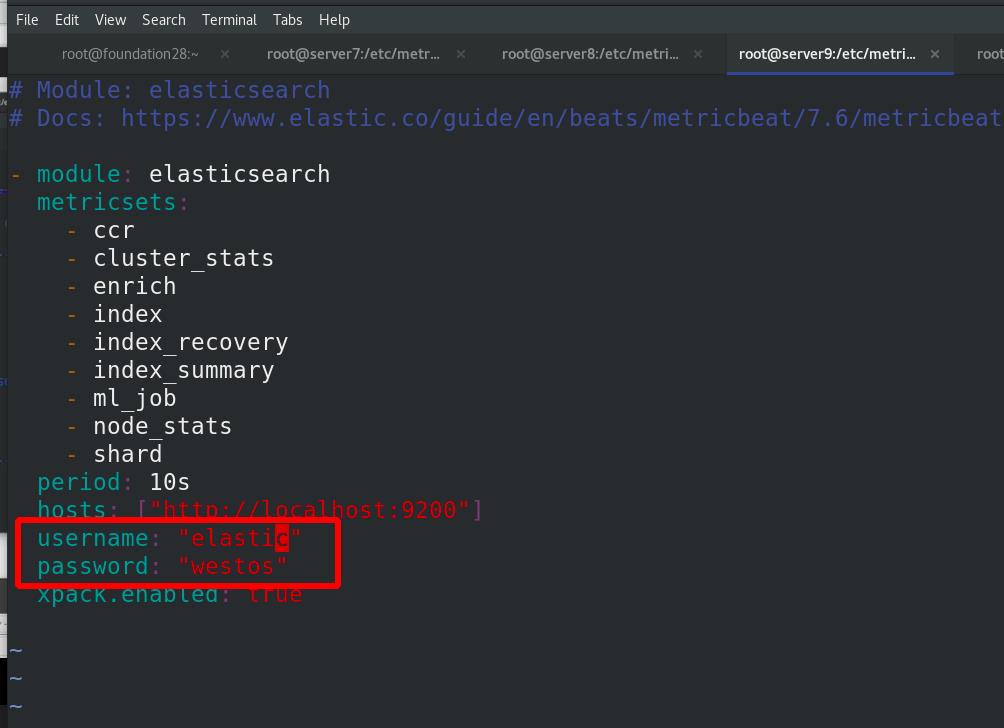
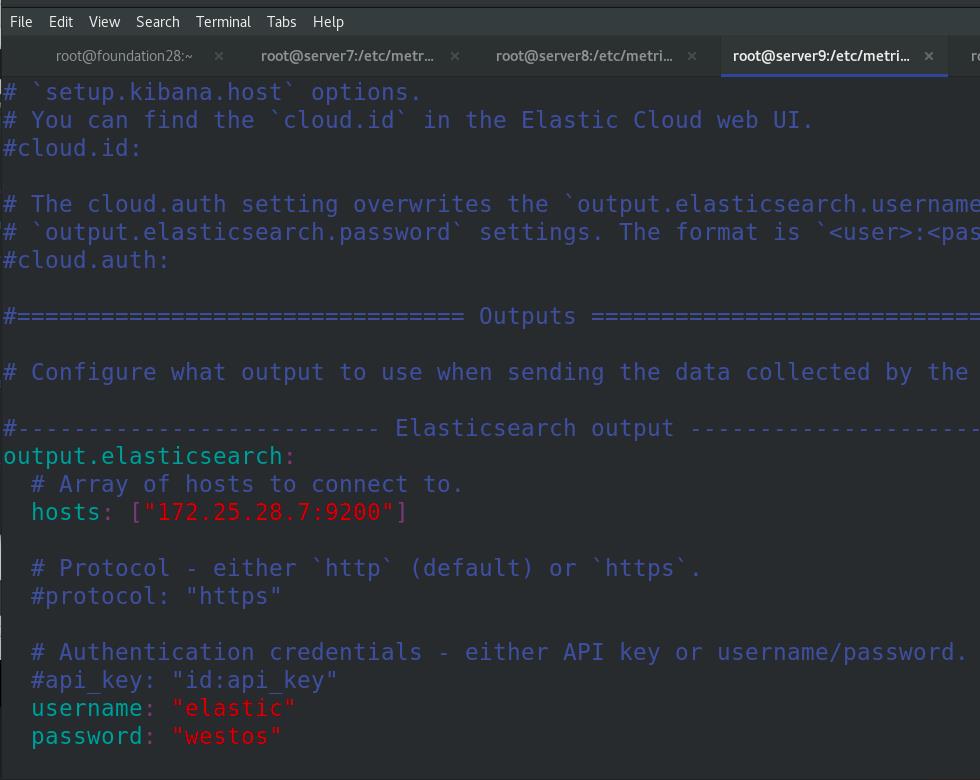
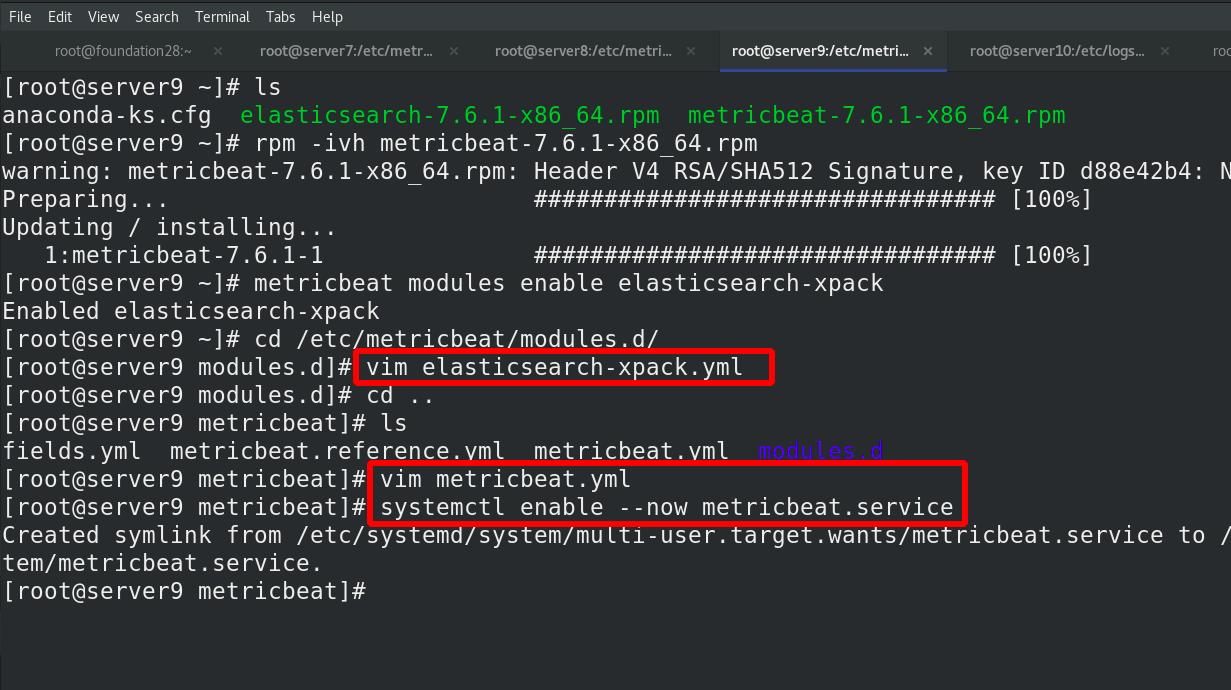
注意:所有ES集群都需要上述操作,完成后监控查看
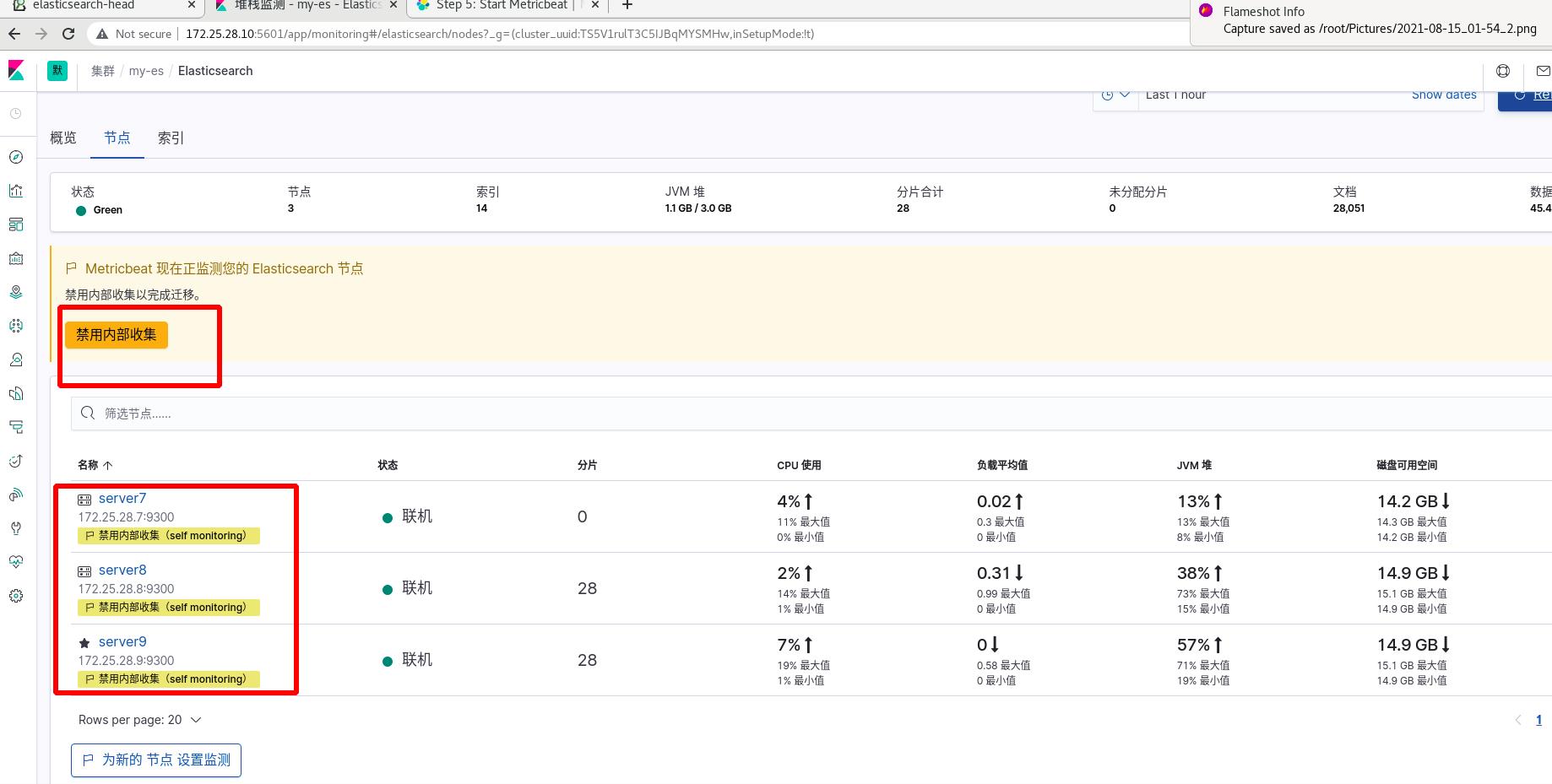
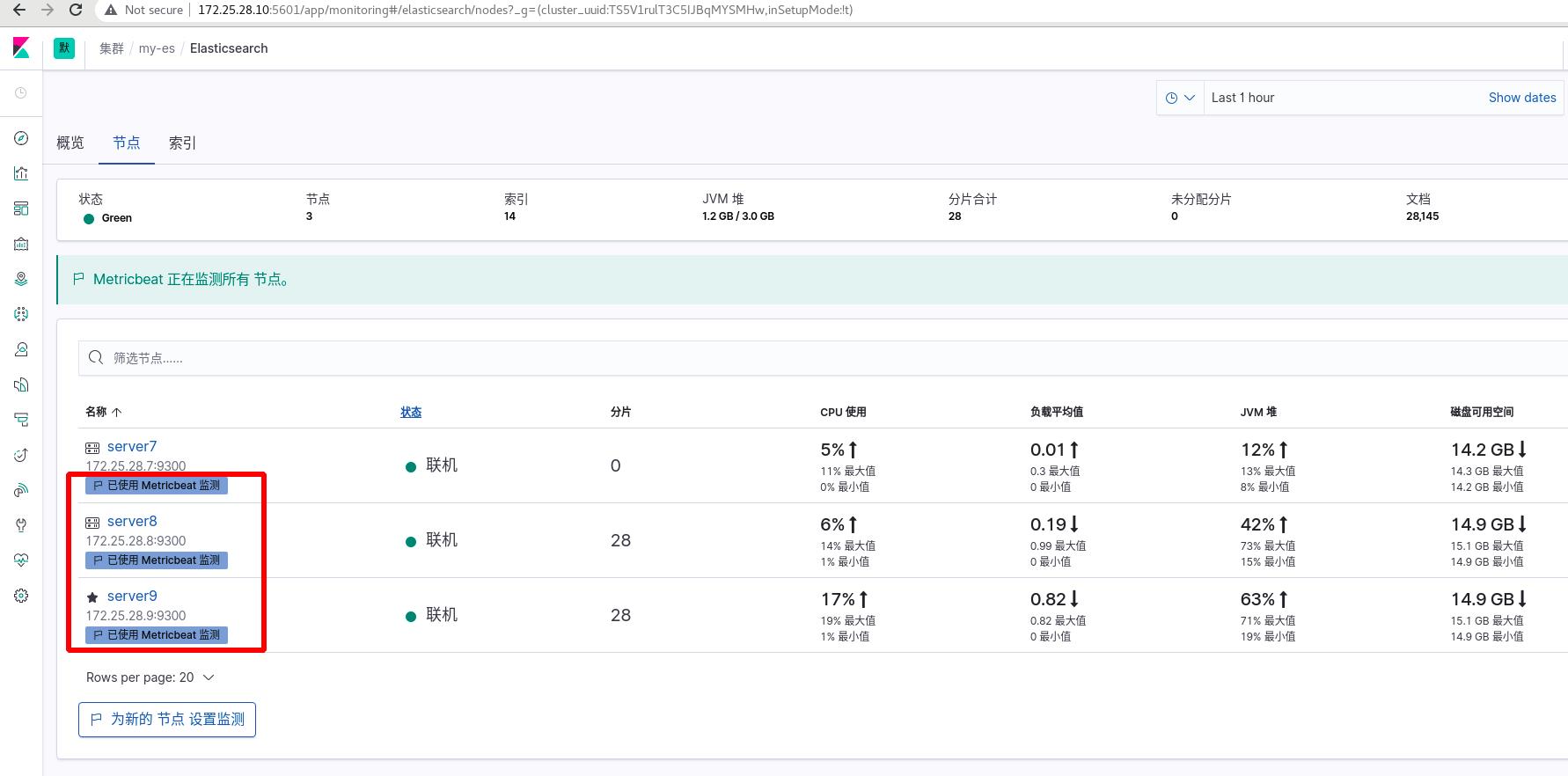
2 filebeat
参考文档:
https://www.elastic.co/guide/en/beats/filebeat/7.6/filebeat-module-elasticsearch.html
所有ES集群节点均需要安装filebeat,ES集群节点配置相同操作
安装rpm包
rpm -ivh filebeat-7.6.1-x86_64.rpm
激活模块
filebeat modules enable elasticsearch
编辑模板文件
cd /etc/filebeat/modules.d/
vim elasticsearch.yml
# Module: elasticsearch
# Docs: https://www.elastic.co/guide/en/beats/filebeat/7.6/filebeat-module-elasticsearch.html
- module: elasticsearch
# Server log
server:
enabled: true
# Set custom paths for the log files. If left empty,
# Filebeat will choose the paths depending on your OS.
var.paths:
- /var/log/elasticsearch/*.log
- /var/log/elasticsearch/*_server.json
gc:
enabled: true
# Set custom paths for the log files. If left empty,
# Filebeat will choose the paths depending on your OS.
var.paths:
- /var/log/elasticsearch/gc.log.[0-9]*
- /var/log/elasticsearch/gc.log
audit:
enabled: true
# Set custom paths for the log files. If left empty,
# Filebeat will choose the paths depending on your OS.
var.paths:
- /var/log/elasticsearch/*_access.log
- /var/log/elasticsearch/*_audit.json
slowlog:
enabled: true
# Set custom paths for the log files. If left empty,
# Filebeat will choose the paths depending on your OS.
var.paths:
- /var/log/elasticsearch/*_index_search_slowlog.log
- /var/log/elasticsearch/*_index_indexing_slowlog.log
- /var/log/elasticsearch/*_index_search_slowlog.json
- /var/log/elasticsearch/*_index_indexing_slowlog.json
deprecation:
enabled: true
# Set custom paths for the log files. If left empty,
# Filebeat will choose the paths depending on your OS.
var.paths:
- /var/log/elasticsearch/*_deprecation.log
- /var/log/elasticsearch/*_deprecation.json
编辑filebeat主配文件
vim filebeat.yml
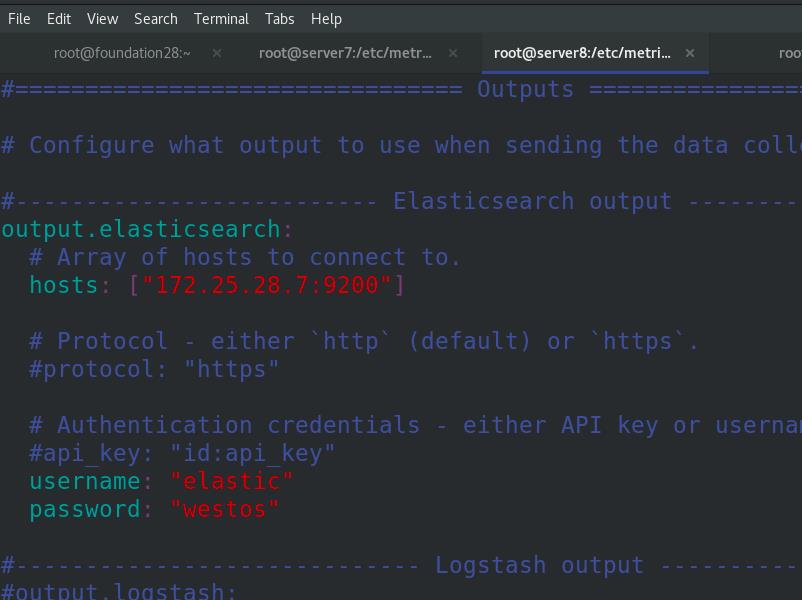
output.elasticsearch:
# Array of hosts to connect to.
hosts: ["172.25.28.7:9200"]
# Protocol - either `http` (default) or `https`.
#protocol: "https"
# Authentication credentials - either API key or username/password.
#api_key: "id:api_key"
username: "elastic"
password: "westos"
启动filebeat服务
systemctl enable --now filebeat.service
kibanan可视化查看日志数据
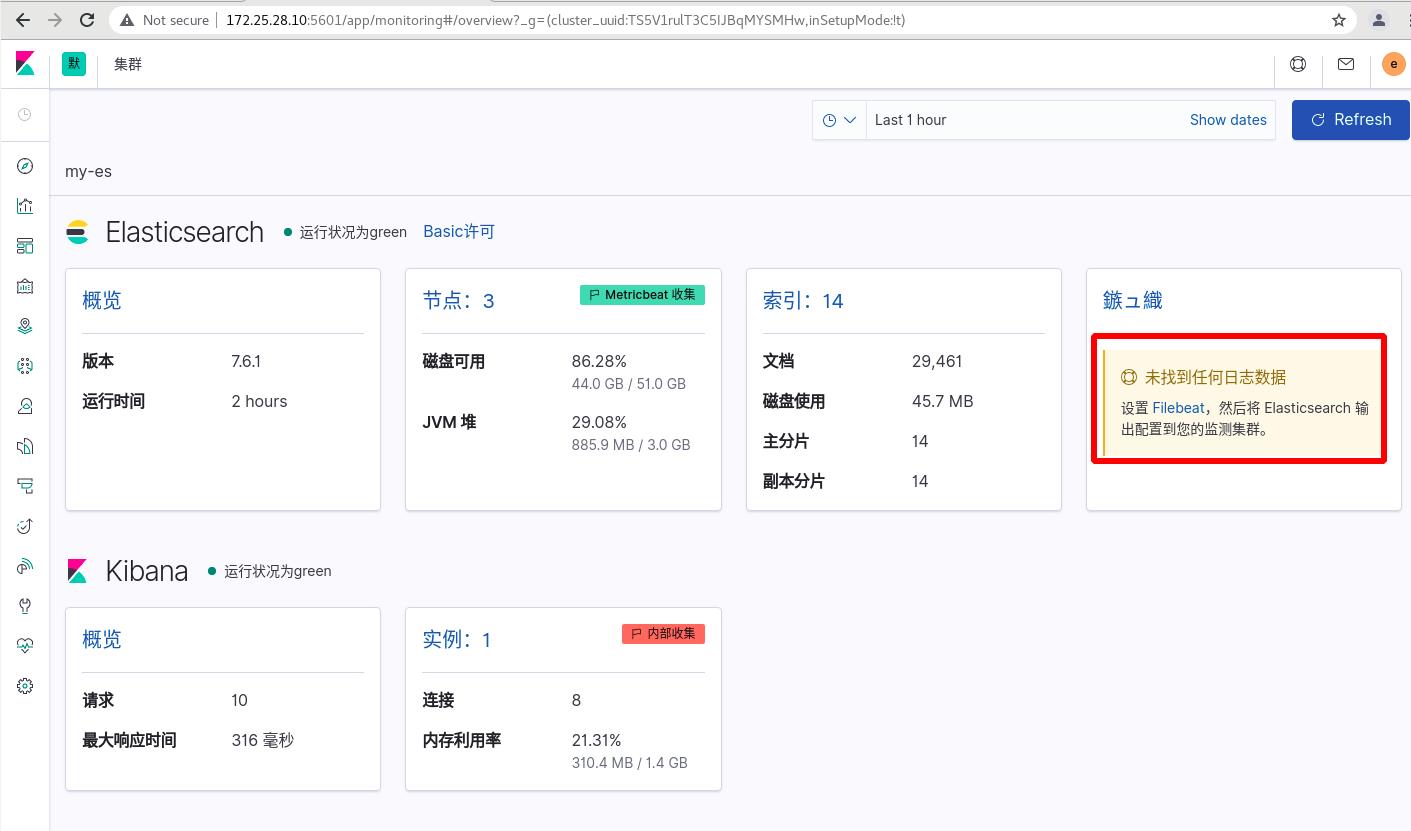
可以通过流式传输关键字数据

五 查询集群节点的健康状况
1 控制台(xpark开启后,不需要认证)
控制台插件提供一个用户界面来和 Elasticsearch 的 REST API 交互。控制台有两个主要部分: editor ,用来编写提交给 Elasticsearch 的请求; response 面板,用来展示请求结果的响应。
查询API:
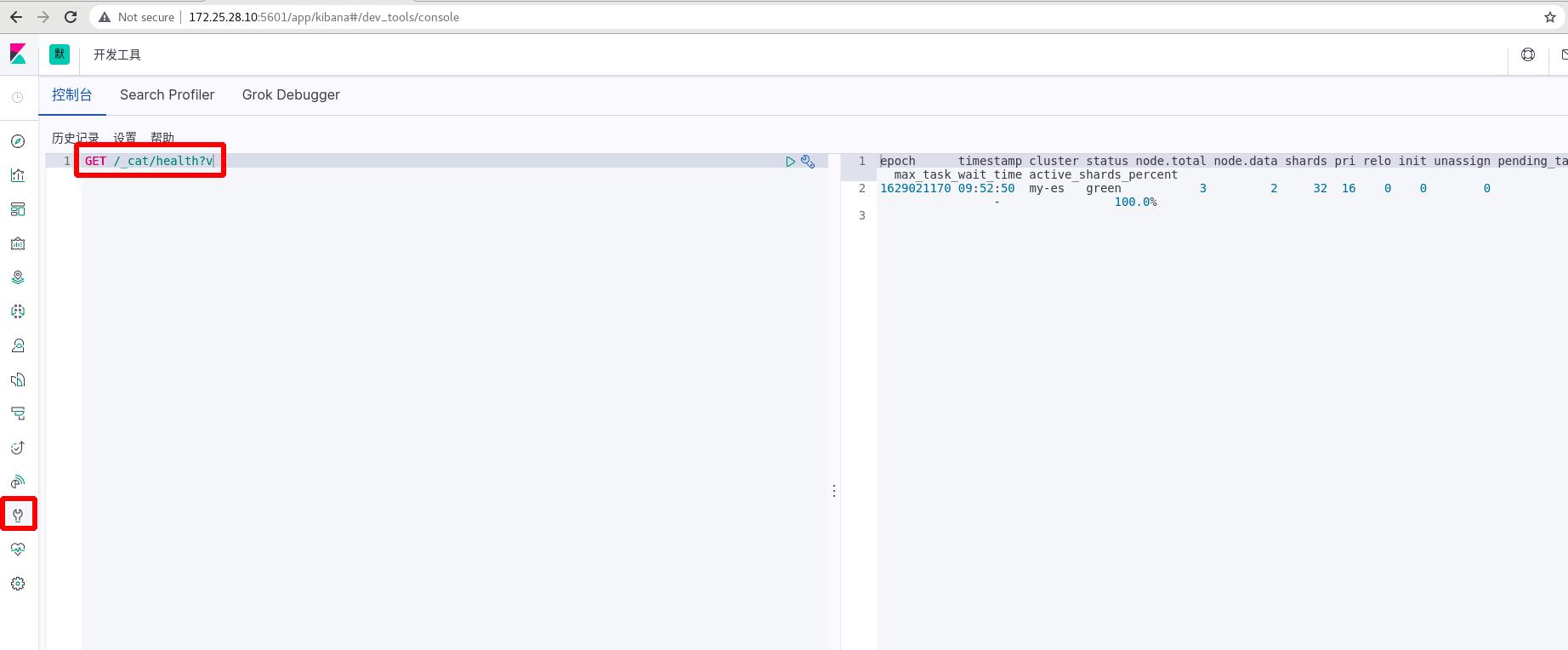

2 curl(xpark开启后,需要加认证)

六 补充
shard分片
主分片和辅助分片不能分配到同节点 ;
分片到节点,数据到分片;
主分片和辅助分片,只有辅助分片存活,可顶替为主分片;
分片推荐30G



延时shard分配:
控制台中输入或者curl(注意xpark是否启动,启动需要curl时加入认证)


滚动重启集群

索引生命周期管理ILM(冷热分离)

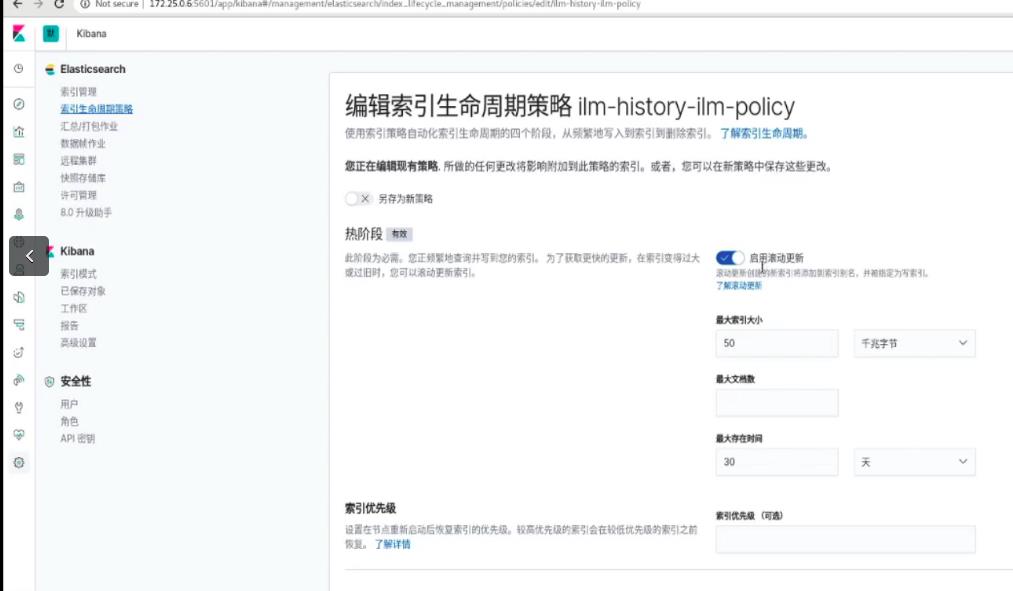


注意ELK是实时监测数据的,虽然有数据库的功能,但是完全和数据库不一样,实时监测非常消耗资源,如果只当数据库,纯属大材小用。建议使用ELK存储热数据,hadoop存储冷数据
一般要把数据冷热分离,刚刚采集到数据可以理解为热数据(hot),实时写入ELK分析;过一段时间,数据变为温数据(warm),可以用来查询,不再写入;再过一段时间变为冷数据(cold),查询也很少了,我们可以考虑把他放到数据库中存储,或者从硬件方面来说,从高性能的节点存储换为普通性能的节点,把高性能的节点留给热数据;再过很久,会删除数据。
想要实现上面的冷热分离,进行生命周期管理,必须有
1、节点标签。区分冷热节点
2、生命周期策略。定义热阶段的大小,最长时间,存在时长等等
3、索引模板引用索引模板策略。模板创建索引,加载生命周期策略
4、索引模板指定调度节点。将新建索引分片分配到热节点
ES数据备份与恢复

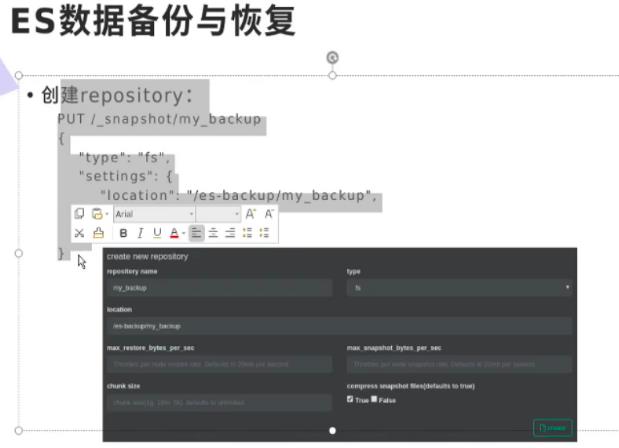



SLM自动备份

搜索速度优化
为了提高es搜索速度,可以考虑下面几种方法:
1、为文件系统cache留有足够内存,内存越大,速度越快
2、提升i/o,使用固态硬盘
3、减少层层嵌套

常见问题解决






监控及故障定位

以上是关于ELK日志分析平台之kibana数据可视化的主要内容,如果未能解决你的问题,请参考以下文章