GPU结构与CUDA系列1GPU与CPU比较:GPU介绍设计差异计算流程
Posted 呆呆象呆呆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了GPU结构与CUDA系列1GPU与CPU比较:GPU介绍设计差异计算流程相关的知识,希望对你有一定的参考价值。
1 GPU的介绍
1.1 CPU到GPU
CPU是人们熟知的,它具有高速的内部寄存器和高速缓冲器(Cache),现代CPU又加入了多级流水线,猜测、乱序执行,超线程等技术,加速其指令吞吐能力,具有快速的响应能力,但是对于大量数据的处理却相对还是不够用。
举个例子:
要做的事情简单概括一下,就是通过对数据进行相应的计算,把数据转换成一个又一个图片上的像素,然后将这张图片显示在屏幕上。整个流程中的计算并不复杂,但是数量大,且计算流程重复,如果全盘交给
CPU的话会给其造成很大的性能负担。
1.2 GPU的概述
当然,这就是GPU崛起的契机。全称是Graphics Processing Unit。
在最开始的时候,它的功能与名字一致,GPU本身是用来做图像渲染、绘制图像和处理图元数据的特定芯片。,图像渲染这种工作的特点就是逻辑简单,计算量大,内存存储时间短。在没有GPU的时候,人们想将计算机中的数据显示在屏幕上,是使用CPU来进行相关运算的。
下图是传统的GPU工作流程,首先从CPU拿到高度压缩的几何信息,然后GPU经过一些固定的处理逻辑把几何信息解码得到图像信息呈现给屏幕。这个给人的感觉GPU就是电脑的一个外设(device)(后面会有介绍一般在CPU上运行的称为Host程序,在GPU上运行的称为Device程序)。从这个角度看,GPU编程就是比较有意思的东西了,本质上是对电脑外设进行编程。

当然我们可以从中看到GPU工作的高度并行性能,这正好符合我们并行编程的需要,于是就有人开始在GPU中增加编程特性,来满足工作需要。但是GPU的编程目的与CPU显然是不同的,CPU的目的是能够控制复杂的逻辑,GPU目的在于高吞吐量的计算。从下图我们看到GPU的cache小,control小,但是ALU很多,所以难以实现复杂的逻辑,但是可以实现高通量的计算。

GPU天生为数据的批量处理而生,它擅长的是在大量数据上同时做同样或几乎一致(这点很重要)的计算。
1.3 为什么要求一样的计算
这一点可以从很多个角度来回答。
-
第一方面:
-
现实世界中应用在大规模数据上的计算,通常都涵盖在这一计算模式之中,因而考虑更复杂的所有的模式本质上是不必要的。
比如计算大气的流动,每一点的风速仅仅取决于该点邻域上的密度和压强分布;
比如计算图像的卷积,每一个输出像素都仅是对应源点邻域和一个卷积核的内积。
-
从这些例子中我们可以看到,除了各个数据单元上进行的计算是一样的,计算中数据之间的相互影响也具有某种“局域性”,一个数据单元上的计算最多需要它某个邻域上的数据。这一点意味着线程之间是弱耦合的,邻近线程之间会有一些共享数据(或者是计算结果),远距离的线程间则独立无关。
这个性质反映在
CUDA里,就是Block划分的两重天地:Block内部具有Shared Memory,线程间可以共享数据、通讯和同步,Block外部则完全独立,Block间没有通讯机制,相互执行顺序不影响计算结果。这一划分使得我们既可以利用线程间通讯做一些复杂的应用和算法加速,又可以在
Block的粒度上自由调度计算任务,在不同计算能力的硬件平台上自适应的调整任务安排。(这里看不懂没关系后面的软件抽象部分会重新叙述这个问题)
-
-
第二方面:
- 多个线程同步执行一致的运算,使得我们可以用单路指令流对多个执行单元进行控制,大幅度减少了控制器的个数和系统的复杂度(设想成千上万的线程各自做不同的事情,如果再有线程间通讯/同步,将会是怎样的梦魇)。
-
第三方面:
- 把注意力放在“几乎一致”这里。最简单的并行计算方案是多路数据上同时进行完全一致的计算,即
SIMD(单指令多数据流)。这种方案是非常受限的。事实上我们可以看出,“完全一致”是不必要的。只要这些计算在大多数时候完全一致,就可以对它们做类似于SIMD的加速,不同点是在计算分叉时候,各个线程不一致的特殊情况下,只需要分支内并行,分支间串行执行即可,毕竟这些只是很少出现的情况。 这样,把“完全一致”这个限制稍微放松,就可以得到更广阔的应用范围和不输于SIMD的计算性能,即SIMT(单指令流多线程)的一个重要环节,这是GPU强大处理能力的原因。
- 把注意力放在“几乎一致”这里。最简单的并行计算方案是多路数据上同时进行完全一致的计算,即
2 GPU计算流程(CPU协同GPU计算)
一个典型的计算流程是这样的:
- 数据从
CPU的内存拷贝到GPU的内存 CPU把计算指令传送给GPUGPU把计算任务分配到各个CUDA core并行处理- 计算结果写到
GPU内存里, 再拷贝到CPU内存里.
3 GPU计算能力参数
除了时钟的速度,衡量GPU计算能力的其它几个重要参数是:
- 并行计算的核心处理器的数目(CUDA cores), 类似轮船的吨位
- 内存大小,类似港口的大小
- 内存带宽(Bandwidth),指数据传输的速度,类似轮船装卸货的速度
- GPU/CPU之间通讯的带宽,类似从港口到火车/卡车上的装卸货的速度
4 CPU和GPU最主要的目标差异
这里的差异不是后面几篇文章中所说的内部的硬件资源,软件抽象,内存架构的差异,这几个差异是因为这里的设计目标的不同导致的具体实现
所以最根本的目标差异我们可以概括为两个点:延迟和吞吐量
CPU要求低延迟、可以介绍较小的吞吐量GPU要求较大吞吐量,但是可以接受较大延迟
这也是在硬件发展极限的妥协,如果硬件资源无限,(存储器速度无限,容量无限,运算速度也很快,并且成本低廉,功耗较低)可能就不需要GPU了,直接CPU暴力解决
这也就产生了目前典型的两种计算模式:
CPU式的高速低延迟、小吞吐量的串行计算GPU式的高延迟、大吞吐量的大规模并行计算
5 目标差异所带来的不同
总结一下主要的不同分为如下几个方面
| CPU | GPU | |
|---|---|---|
| 延迟Latency | 对于延迟不耐受Latency Intolerance | 对于延迟可以容忍Latency Tolerance |
| 吞吐量Throughput | 低吞吐量low throughput | 高吞吐量high throughput |
| 并行Parallelism | 基于任务并行Task Parallelism | 基于数据并行Data Parallelism |
| 核心Cores | 多线程核心Multi-threaded Cores | 同指令多线程核心SIMT (Single Instruction Multiple Thread) Cores |
| 线程Threads | 数十个线程10s of Threads | 数万个线程10,000s of Threads |
CPU
(1) 有强大的ALU,时钟频率很高;
(2) 容量较大的cache,一般包括L1、L2和L3三级高速缓存;L3可以达到8MB,这些cache占据相当一部分片上空间;
(3) 有复杂的控制逻辑,例如:复杂的流水线(pipeline)、分支预测(branch prediction)、乱序执行(Out-of-order execution)等;
这些设计使得真正进行计算的ALU单元只占据很小一部分片上空间。
GPU
(1) 有大量的ALU;
(2) cache很小;缓存的目的不是保存后面需要访问的数据的,这点和CPU不同,而是为thread提高服务的;
(3) 没有复杂的控制逻辑,没有分支预测等这些组件;
5.1 延迟、吞吐量方面
CPU着眼点在于低延迟(low latency),最大程度上的降低延迟,最大程度上的利用缓存进行各种指令的运行
为此付出的代价可能是无法实现很大的吞吐量
eg. 鼠标键盘的输入,指令的预分配,乱序执行,流控制
GPU着眼点是大吞吐量(high throughput),需要大批量的并行操作
为此付出的代价可能是无法实现很低的延迟(low latency),因为所运行的程序或者任务有一定的延迟容忍度
eg. Graphics in a game (simplified scenario)
eg. processing millions of pixels in a single frame(for effectiveness)
5.2 资源分布
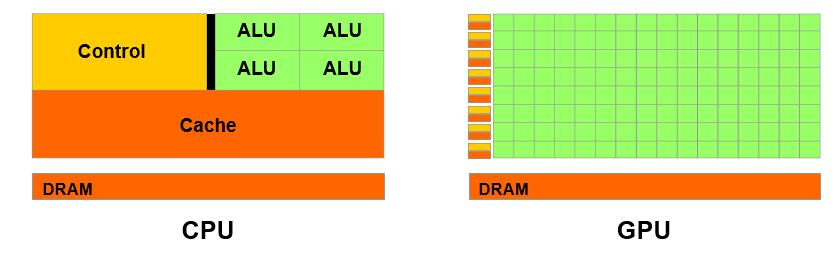
CPU
CPU不仅被Cache占据了大量空间,而且还有复杂的控制逻辑和诸多优化电路,因为需要很强的通用性来处理各种不同的数据类型,同时又要逻辑判断又会引入大量的分支跳转和中断的处理。这些都使得CPU的内部结构异常复杂。相比之下计算能力只是CPU很小的一部分。同时CPU需要大量的高级缓存(多级缓存机制)资源去实现低延时。
GPU
GPU采用了数量众多的计算单元和超长的流水线,但只有非常简单的控制逻辑和指令集并省去了Cache。可以实现更多的寄存器分配给计算单元,实现算力的提升。同时也可以有更多的计算单元,这样就可以并行更多的线程。可以相对轻松地向GPU添加更多处理核心,从而实现提高吞吐量。而GPU面对的则是类型高度统一的、相互无依赖的大规模数据和不需要被打断的纯净的计算环境。所以相比CPU而言,GPU更加适合处理高并行性,计算量大的运算(例如人工智能相关运算),不过,考虑到GPU仍然有大量多余的电路和大量多余的指令集对人工智能的运算而言卵用没有,所以设计专属计算矩阵的处理器对AI运算会有更大的助益。
nvidia图灵架构专门添加了Tensor Core运算单元一样,就是这个专属计算矩阵的处理器
同时还是用各种优化来提高吞吐量:
-
一些片上内存和本地缓存,以减少外部内存的带宽
-
批处理线程组,以最大限度地减少不一致的内存访问
错误的访问模式将导致更高的延迟和/或线程暂停。
通过退出或终止线程消除不必要的操作(示例:Z消隐和早期Z消隐不会显示的像素)
5.3 并行与线程
CPU
- 不同任务会运行不同的指令,多任务会映射到多指令,每个线程都需要被单独编写和精确规划,线程数和核心数基本属于相同数量级
GPU
- 可以并行的数据图形,图片,视频,物理,科学计算。数据越多,GPU在这些算法中的效率就越高。
- 使用流处理,设计了Grid、Block、Thread、Warp这些软件抽象,实现了到硬件资源SM、SP的映射,这么做的目的是:
- 减少调度、缓存等方面的硬件开销。迅速处理、调度、缓存和上下文切换多个线程
- 避免这么多线程之间的同步问题
- 可以实现一条指令对多线程的调度(SIMT),实现统一的比较便利的一组线程warp的安排调度,里面的若干线程只会做相同的事情,一些轻量级的线程可以在较少的核心上实现
- 线程是通过硬件规划部署的,不需要针对每个线程进行规划编写
5.4 总结
GPU 通过流处理和相应的硬件设计实现了非常高的吞吐量
由于可以容忍较高的延迟,实现了非常小的高速缓冲器的需求,从而有更多的面积分配给计算单元
更多的计算单元对应同步并行执行更多的线程,实现高吞吐量
6 用多线程掩盖延迟
Global Memory访存延迟可以达到数百个时钟周期,即便是最快的Shared Memory和寄存器在有写后读依赖时也需要数十个时钟周期。这似乎和CUDA强大的处理能力完全相悖。
为什么GPU具有这么高的计算能力?如果连寄存器都这么慢,怎么会有高性能呢?难道这不会成为最大的瓶颈吗?
因为这个高延迟的开销被掩盖了,掩盖在大量线程之下。更清楚的说,控制单元(Warp Scheduler)在多组线程之间快速切换,当一组线程Warp(类似于SIMD的核心思想,一个线程组,在CUDA里叫做Warp)因为访存或其他原因出现等待时,就将其挂起,转而执行另一组线程,GPU的硬件体系允许同时有大量线程存活于GPU的SM(流多处理器)之中,这种快速切换保证资源的最大利用率——控制单元始终有指令可以发放,执行单元始终有任务可以执行,仍然可以保持最高的指令吞吐,每个单元基本都能保持充分的忙碌。
这就是GPU硬件设计中非常有特色的基本思想:用多线程掩盖延迟。这一设计区别于CPU的特点是:大量高延迟寄存器取代了少量低延迟寄存器,寄存器的数量保证了可以有大量线程同时存活,且可以在各组线程间快速切换。尽管每个线程是慢的,但庞大的线程数加上与之匹配的虽然低速但是数量很大的寄存器成就了GPU的数据吞吐能力。
下面图片可以说明:GPU用多个Warp掩盖延迟 / 与CPU计算模式的对比
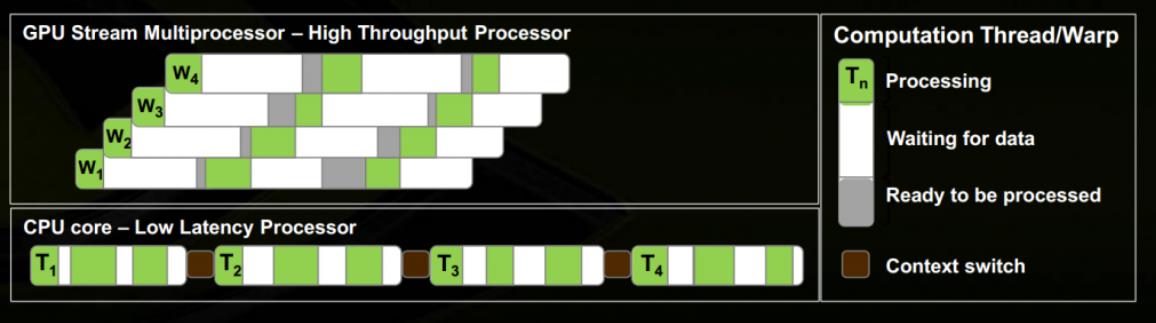
GPU用多个Warp快速切换来掩盖延迟,而CPU用快速的寄存器来减小延迟。两者的重要区别是寄存器数目,CPU的寄存器快但少,因此Context Switch代价高;GPU寄存器多而慢,但寄存器数量保证了线程Context Switch非常快。同时也是因为GPU对高延迟的容忍度比较高,他只追求在长时间内比较稳定的较大吞吐量,而不在意响应时间。
6.1 多少线程才能够掩盖掉常见的延迟呢?
对于GPU,最常见的延迟大概要数寄存器写后读依赖,即一个局域变量被赋值后接着不久又被读取,这时候会产生大约24个时钟周期的延迟。为了掩盖掉这个延迟,我们需要至少24个Warp轮流执行,一个Warp遇到延迟后的空闲时间里执行其余23个Warp,从而保持硬件的忙碌。在Compute Capability 2.0,SM中有32个CUDA核心,平均每周期发射一条指令的情况下,我们需要
24
∗
32
=
768
24*32 = 768
24∗32=768个线程来掩盖延迟。
保持硬件忙碌,用CUDA的术语来说,就是保持充分的Occupancy,这是CUDA程序优化的一个重要指标。
Last 参考文献
(3条消息) gpu的单位表示_GPU中的基本概念_weixin_39717121的博客-CSDN博客
CUDA的thread,block,grid和warp - 知乎
以上是关于GPU结构与CUDA系列1GPU与CPU比较:GPU介绍设计差异计算流程的主要内容,如果未能解决你的问题,请参考以下文章
GPU结构与CUDA系列3GPU软件抽象:Grid,Block,Thread,Warp定义说明与硬件的映射执行细节
GPU结构与CUDA系列2GPU硬件结构及架构分析:流多处理器SM,流处理器SP,示例架构分析
GPU结构与CUDA系列4GPU存储资源:寄存器,本地内存,共享内存,缓存,显存等存储器细节