比用Pytorch框架快200倍!0.76秒后,笔记本上的CNN就搞定了MNIST | 开源
Posted 程序员大咖
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了比用Pytorch框架快200倍!0.76秒后,笔记本上的CNN就搞定了MNIST | 开源相关的知识,希望对你有一定的参考价值。
????????关注后回复 “进群” ,拉你进程序员交流群????????
博雯 发自 凹非寺
量子位 报道 | 公众号 QbitAI
在MNIST上进行训练,可以说是计算机视觉里的“Hello World”任务了。
而如果使用PyTorch的标准代码训练CNN,一般需要3分钟左右。
但现在,在一台笔记本电脑上就能将时间缩短200多倍。
速度直达0.76秒!
那么,到底是如何仅在一次epoch的训练中就达到99%的准确率的呢?
八步提速200倍
这是一台装有GeForce GTX 1660 Ti GPU的笔记本。
我们需要的还有Python3.x和Pytorch 1.8。
先下载数据集进行训练,每次运行训练14个epoch。
这时两次运行的平均准确率在测试集上为99.185%,平均运行时间为2min 52s ± 38.1ms。
接下来,就是一步一步来减少训练时间:
一、提前停止训练
在经历3到5个epoch,测试准确率达到99%时就提前停止训练。
这时的训练时间就减少了1/3左右,达到了57.4s±6.85s。
二、缩小网络规模,采用正则化的技巧来加快收敛速度
具体的,在第一个conv层之后添加一个2x2的最大采样层(max pool layer),将全连接层的参数减少4倍以上。
然后再将2个dropout层删掉一个。
这样,需要收敛的epoch数就降到了3个以下,训练时间也减少到30.3s±5.28s。
三、优化数据加载
使用data_loader.save_data(),将整个数据集以之前的处理方式保存到磁盘的一个pytorch数组中。
也就是不再一次一次地从磁盘上读取数据,而是将整个数据集一次性加载并保存到GPU内存中。
这时,我们只需要一次epoch,就能将平均训练时间下降到7.31s ± 1.36s。
四、增加Batch Size
将Batch Size从64增加到128,平均训练时间减少到4.66s ± 583ms。
五、提高学习率
使用Superconvergence来代替指数衰减。
在训练开始时学习率为0,到中期线性地最高值(4.0),再慢慢地降到0。
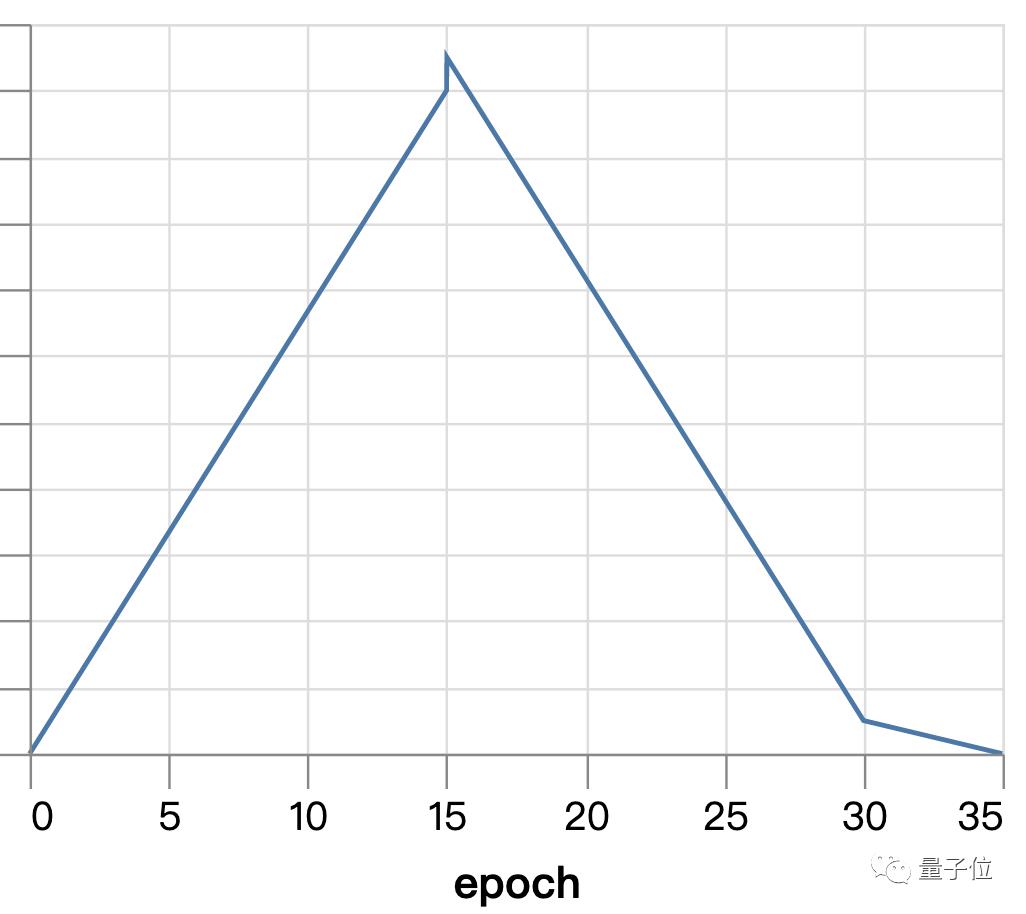
这使得我们的训练时间下降到3.14s±4.72ms。
六、再次增加Batch Size、缩小缩小网络规模
重复第二步,将Batch Size增加到256。
重复第四步,去掉剩余的dropout层,并通过减少卷积层的宽度来进行补偿。
最终将平均时间降到1.74s±18.3ms。
七、最后的微调
首先,将最大采样层移到线性整流函数(ReLU)激活之前。
然后,将卷积核大小从3增加到5.
最后进行超参数调整:
使学习率为0.01(默认为0.001),beta1为0.7(默认为0.9),bata2为0.9(默认为0.999)。
到这时,我们的训练已经减少到一个epoch,在762ms±24.9ms的时间内达到了99.04%的准确率。

“这只是一个Hello World案例”
对于这最后的结果,有人觉得司空见惯:
优化数据加载时间,缩小模型尺寸,使用ADAM而不是SGD等等,都是常识性的事情。
我想没有人会真的费心去加速运行MNIST,因为这是机器学习中的“Hello World”,重点只是像你展示最小的关键值,让你熟悉这个框架——事实上3分钟也并不长吧。

而也有网友觉得,大多数人的工作都不在像是MNIST这样的超级集群上。因此他表示:
我所希望的是工作更多地集中在真正最小化训练时间方面。

GitHub:
https://github.com/tuomaso/train_mnist_fast
参考链接:
[1]https://www.reddit.com/r/MachineLearning/comments/p1168k/p_training_cnn_to_99_on_mnist_in_less_than_1/
-End-
最近有一些小伙伴,让我帮忙找一些 面试题 资料,于是我翻遍了收藏的 5T 资料后,汇总整理出来,可以说是程序员面试必备!所有资料都整理到网盘了,欢迎下载!

点击????卡片,关注后回复【面试题】即可获取
在看点这里 好文分享给更多人↓↓
好文分享给更多人↓↓
以上是关于比用Pytorch框架快200倍!0.76秒后,笔记本上的CNN就搞定了MNIST | 开源的主要内容,如果未能解决你的问题,请参考以下文章
比用 Pytorch 框架快 200 倍!0.76 秒后,笔记本上的 CNN 就搞定了 MNIST | 开源
《PyTorch 版 EfficientDet 比官方 TF 实现快 25 倍?》
《PyTorch 版 EfficientDet 比官方 TF 实现快 25 倍?》
PyTorch宣布支持苹果M1芯片GPU加速!训练快6倍,推理提升21倍!
AI求解偏微分方程新基准登NeurIPS,发现JAX计算速度比PyTorch快6倍,LeCun转发:这领域确实很火...