数据结构一篇文章学懂并查集+LRU Cache,拿来吧你!
Posted ^jhao^
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据结构一篇文章学懂并查集+LRU Cache,拿来吧你!相关的知识,希望对你有一定的参考价值。
并查集 -- LRU Cache
好文建议收藏!!
并查集的概念
并查集作为一种数据结构在处理需要将n个元素划分成不相交的集合,在逐步按照某一种规律将某些元素给合并,并在这个过程中要反复查询某一种元素归属于哪个集合的运算,称之为并查集
一、并查集的用途
这道题讲述就是有一组元素,他们相互之间产生某种关系,形成了集合,面对这种问题,常规的解法弄来弄去可能都会觉得做的不太对,但有了并查集我们解决这类问题是较简单的。
并查集的结构解释
注释:双亲节点或父节点:若一个节点含有子节点,则这个节点称为其子节点的父节点
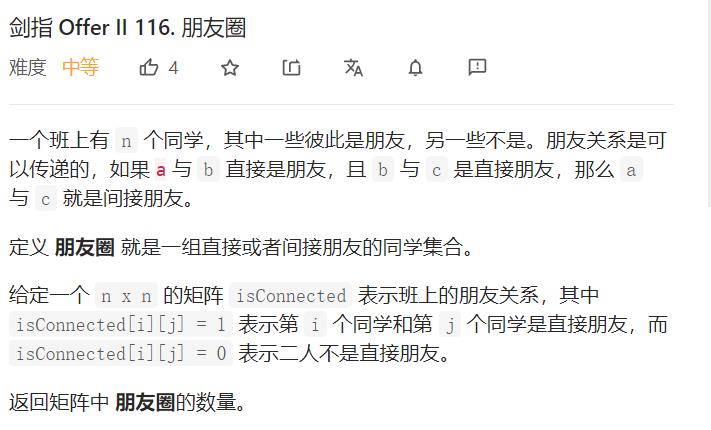
我们简要的举个例子,这里我们有5人,他们的编号为 0 - 4,假设他们是一群准大一的学生,他们刚开始各自为一个集合。
我们这里用负数表示自己为整体,索引指向的内容若为正数表示该索引存放的值为集合当中的双亲结点。
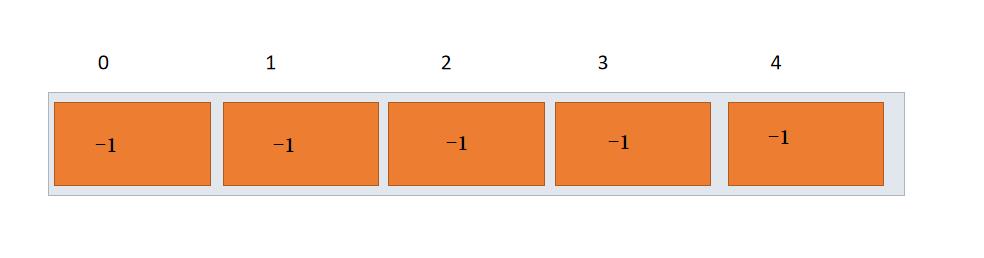
假设过了一段时间后,编号为0,2,4的同学形成了一个集合。编号为1,3的同学形成了一个集合。,如下图所示
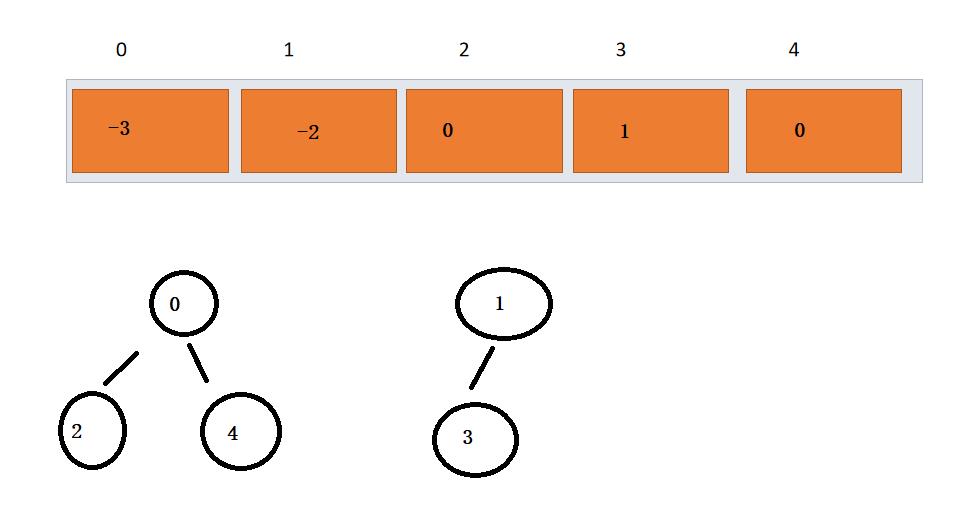 这里的0,1分别是一个集合,索引对应的值是集合中的元素个数的相反数
这里的0,1分别是一个集合,索引对应的值是集合中的元素个数的相反数
解释: 此时父节点中存放的是集合大小的负值,子节点存放的是父节点的索引,倘若这时编号为4 与编号为3的结点因为一场比赛结识成为了朋友,我们要如何做呢? - -实际上,当4与3结合成朋友,自然两个集合中的每一个人都成了朋友,我们这时只需要让其中一个集合成为父节点,两个集合便成了一个集合了 。
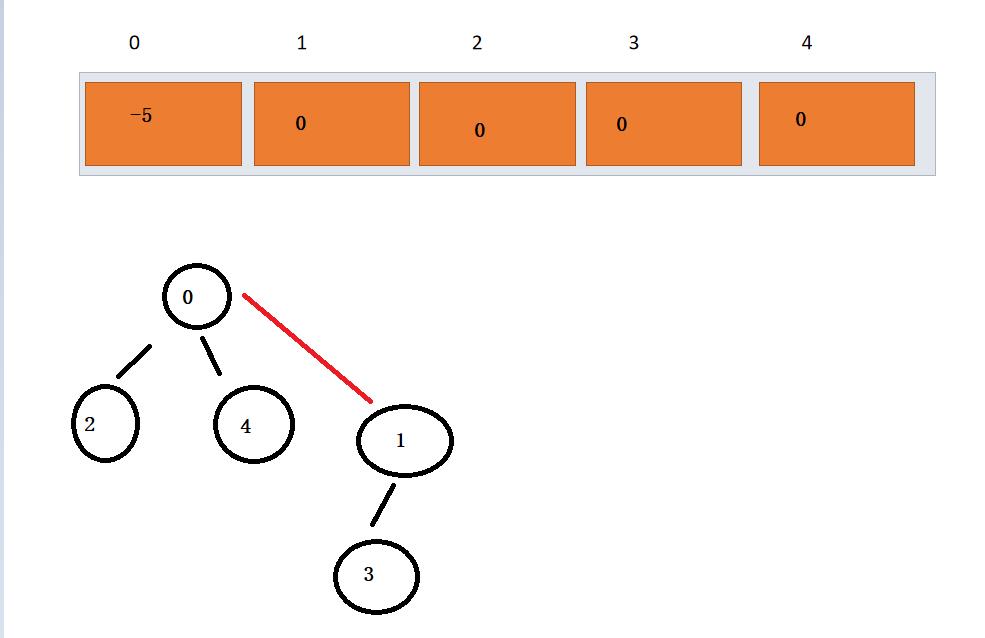
此时我们的人形成了一个整体,每个子节点的存放的都是父节点的下标(0),0位置存放结点的个数的负值(因为我们用负数来区分是否为根)
我们也可以看出来一个并查集所需要具备哪些结论?
1.数组的下标对应集合中的元素下标
2.负数代表根,数字代表该集合中的元素个数
3.若数组中为非负数,则为父节点在数组当中的下标
我们也可以看出来一个并查集所需要具备哪些功能?
1.查找元素属于哪一个集合
2.查找两个元素是否为一个集合
3.两个元素合并成一个集合
4.集合的个数
并查集的实现
注释中有解释,详情请看注释,并结合下面的两道习题,其实就是实现了上面概括的四个接口
#include<iostream>
using namespace std;
#include<vector>
#include<assert.h>
class UnionFindSet
{
public:
//构造函数,初始化开空间
UnionFindSet(int x)
{
_ufs.resize(x, -1);
//初始化的时候讲x个空间初始化成-1
}
//合并两个元素为集合
bool Union(int x1,int x2)
{
int root1 = FindRoot(x1);
int root2 = FindRoot(x2);
if (root1 == root2)
return false;
else
{
//将root1成为新集合的头,并计算他的元素个数,root2的内容则指向root1的索引
_ufs[root1] += _ufs[root2];
_ufs[root2] = root1;
return true;
}
}
int FindRoot(int x)
{
assert(x < _ufs.size());
while (_ufs[x] >= 0)
{
x = _ufs[x];
}
return x;
}
//算出数组当中有多少个集合
int Size()
{
int count = 0;
for (int i = 0; i < _ufs.size(); ++i)
{
//计算数组中有几个集合
if (_ufs[i] < 0)
count++;
}
return count;
}
private:
vector<int> _ufs;
};
并查集相关习题
习题1.leetcode 朋友圈

分析: 这题其实就是给了我们一个二维矩阵,然后让我们确定有多少个朋友圈,这个就很简单了,我们可以遍历一遍数组,用我们的Union的接口将两个人合并成一个集合,最后在用Size接口来计算集合的个数。
class UnionFindSet
{
public:
UnionFindSet(int x)
{
_ufs.resize(x, -1);
//初始化的时候讲x个空间初始化成-1
}
bool Union(int x1,int x2)
{
int root1 = FindRoot(x1);
int root2 = FindRoot(x2);
if (root1 == root2)
return false;
else
{
//将root1成为新集合的头,并计算他的元素个数,root2的内容则指向root1的索引
_ufs[root1] += _ufs[root2];
_ufs[root2] = root1;
return true;
}
}
int FindRoot(int x)
{
assert(x < _ufs.size());
while (_ufs[x] >= 0)
{
x = _ufs[x];
}
return x;
}
int Size()
{
int count = 0;
for (int i = 0; i < _ufs.size(); ++i)
{
if (_ufs[i] < 0)
count++;
}
return count;
}
private:
vector<int> _ufs;
};
class Solution {
public:
int findCircleNum(vector<vector<int>>& isConnected) {
UnionFindSet ufs(isConnected.size());
for(int i =0;i<isConnected.size();++i)
{
for(int j =0;j<isConnected.size();++j)
{
//遍历二维数组,将 i==j自己与自己的情况过滤
if(i == j)
continue;
//将为朋友的弄成集合
if(isConnected[i][j]==1)
ufs.Union(i,j);
}
}
int ret = ufs.UfsSize();
return ret;
}
};
习题2.leetcode 等式方程的可满足性

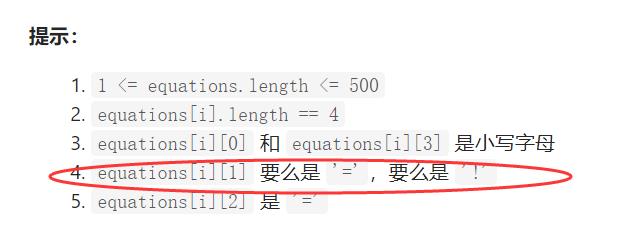
分析:这道题目也是用并查集实现为最优解,我们这道题可以先遍历一遍数组,将所有string中的第二个位置为 ‘=’先放入并查集当中,在遍历一遍从第二个位置’!'查看是否有重复的错误逻辑放入
class UnionFindSet
{
public:
UnionFindSet(int x)
{
_ufs.resize(x, -1);
//初始化的时候讲x个空间初始化成-1
}
bool Union(int x1,int x2)
{
int root1 = FindRoot(x1);
int root2 = FindRoot(x2);
if (root1 == root2)
return false;
else
{
//将root1成为新集合的头,并计算他的元素个数,root2的内容则指向root1的索引
_ufs[root1] += _ufs[root2];
_ufs[root2] = root1;
return true;
}
}
int FindRoot(int x)
{
assert(x < _ufs.size());
while (_ufs[x] >= 0)
{
x = _ufs[x];
}
return x;
}
int Size()
{
int count = 0;
for (int i = 0; i < _ufs.size(); ++i)
{
if (_ufs[i] < 0)
count++;
}
return count;
}
private:
vector<int> _ufs;
};
class Solution {
public:
bool equationsPossible(vector<string>& equations) {
UnionFindSet ufs(26);
//先遍历一遍,将所有==的情况的集合都找出来,再第二次遍历将!=看==的情况是否存在
for(auto& e: equations)
{
//第一次遍历,建立映射
if(e[1] =='=')
ufs.Union(e[0]-'a',e[3]-'a');
}
for(auto& e:equations)
{
if(e[1] =='!')
{
//第二次遍历,查错
//若他们的头结点为同一个,说明在一个集合,则与逻辑错误
if(ufs.FindRoot(e[0]-'a') == ufs.FindRoot(e[3]-'a'))
return false;
}
}
//当走到这里的时候,表示并查集中没有出现逻辑错误的
return true;
}
};
并查集的思考与提升
这里大家思考一下,朋友圈这样的题型,倘若他给我们的不是编号,而是人名,那么我们如何利用我们的并查集呢,我们的并查集都是通过下标来实现的。
我们这里可以用vector< string > nameV={“小明”,“小红”,“小绿”…},这样子我们就可以通过下标找到对应的人。
我们用人找下标就可以用map<string,int> nameIndexmap 来通过人名找到对应下标,这样我们的并查集就可以实现通用了

通用分析:
map 可以由名字找到下标_ufs[下标] 可以找到对应的头结点
vector 可以由下标找到人
我们想要进行人名对应查找头节点的时候,map(人名)首先可以找到下标,vector[下标]可以找到对应的双亲结点的人,相当于找到了对应的双亲结点的名字,我们就可以利用这种结构对_ufs这个数组进行更改
二、LRU Cache的介绍
1.什么是LRU Cache
LRU是Least Recently Used的缩写,意思是最近最少使用。Cache则是CPU和主存间的快速RAM,而且因为Cache的容量有限,当我们呢容量用完之后,需要加入新的内容,我们就要删除掉部分已经存入的数据,从而腾出空间,LRU Cache的替换原则就是将最近最少使用的内容进行替换
习题. LRU 缓存机制
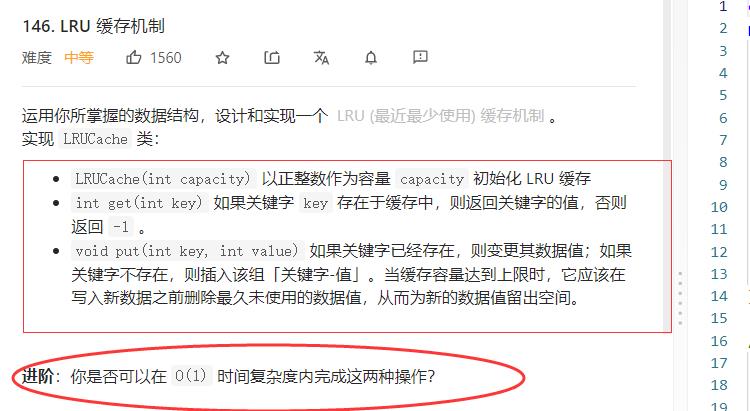
仔细观察题意,我们可以得知,他要求我们设计一种数据结构来实现O(1)的时间复杂度去完成get和put这两个接口。
思路1:我们要实现get相对简单一些,我们都知道哈希表中的查找就是O(1)的时间复杂度,但是每次get数据时,相当于我们也调用了一次这个数据,这个数据的优先级就会提高
怎么去实现呢,我们可以用一个vector用来开固定大小的空间,我们规定数据尾为优先级高的,每次get数据时我们将数据拿出来放到最后。
put数据的时候我们先检查是否存在相同的key,存在的话就更新一下list的value,不存在则检查容量,容量不够的时候我们就删除最久未使用的,够的话就直接尾插。 -
但是如何把数据找到并且放到后面,并且保证删除数据保持时间复杂度为O(1),所以我们拿到这个位置的时间复杂度必须是O(1),删除数据的时候用 vector(顺序表) 的时间复杂度是O(N),所以思路一可以实现,但是不符合题目要求。于是我们有了下面的思路二。
思路2:
get: 使用list,把最近访问的放在尾上,最久不访问的放在头上, list在一个位置的删除是O(1)的时间复杂度,因为他底层是一个带头循环双向链表,但是我们要删除数据的时候要有这个位置的信息吧,所以我们这里哈希表的value存储这个list迭代器,我们的哈希表可以在key位置存储pair<first,second>,value位置就可以存储list的迭代器了,这样我们通过哈希表找到要删除的key之后,可以直接找到list中的迭代器位置,删除之后再到链表尾插,删除了之后迭代器失效了,所以我们要更新哈希表中存储的迭代器位置。
put:put数据的时候我们也是先在哈希表中查找是否存在,存在的话更新pair的second,不存在的话我们就可以头部删除,再到尾上插入。
上述结构就能实现O(1)的时间复杂度,也是LRU Cache常用的搭配,哈希表+链表的组合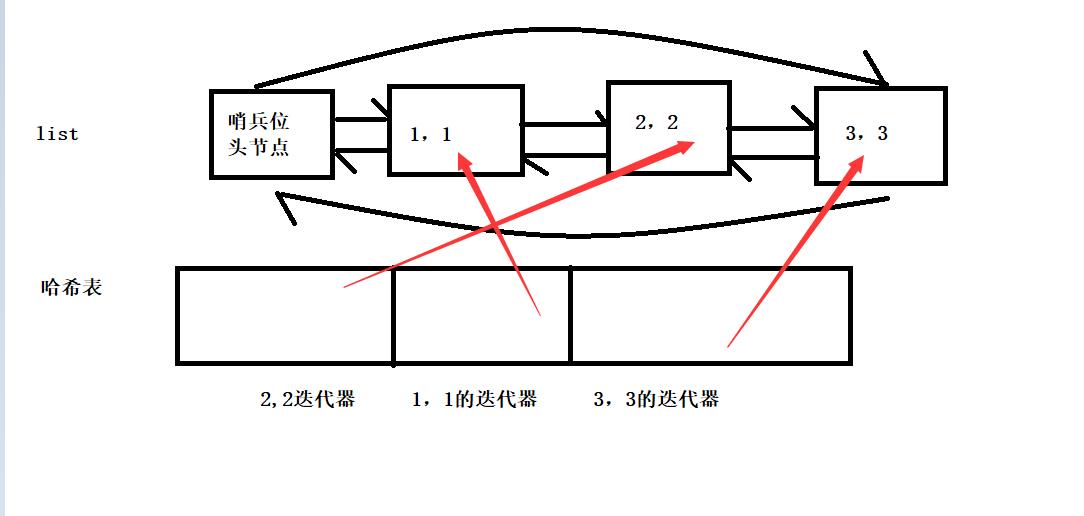
代码逻辑是利用_size,_capacity来控制链表的长度_size初始化给0,_capacity就给capacity,其中get逻辑就是哈希表有对应的key值的时候我们就在list当中删除他,在尾插,在哈希表更新,没有对应的key值就在list中尾插,在哈希表中添加这个key和list的迭代器
put的逻辑我们先复用get的接口,当put的数据已经在list中,我们可以很好的使用get的逻辑,就是记得要将list的pair的second更新。当不存在的时候就需要判断链表大小和容量是否相等,当_size和_capacity相等的时候,list头删,在尾插,在哈希表更新迭代器。(这里的_size其实也可以用list.size(),但是这是一个O(N)的接口,他是遍历一遍,所以我们成员变量给多一个_size),当_size和_capacity不相等的时候就直接在list当中尾插,在哈希表中也插入。详细请看代码解析。
class LRUCache {
public:
LRUCache(int capacity)
:_size(0),
_capacity(capacity)
{}
int get(int key) {
//找的时候在哈希表中,若存在就更改在list的位置,更改哈希表的迭代器值
if(um.find(key) != um.end())
{
//这里现在list后面插入后再删除,防止迭代器失效
list<pair<int,int>>::iterator it = um[key];
int value = it->second;
lt.push_back(make_pair(it->first,it->second));
lt.erase(it);//erase 可以给一个迭代器的位置iterator erase (iterator position);
//更新之后对应的key的迭代器就是再最后一个位置
um[key] = (--lt.end());
return value;
}
else
{
return -1;//找不到
}
}
void put(int key, int value) {
//若改变了list的迭代器位置还要更新哈希表中的迭代器值,若已经存在的会在get的逻辑中处理好,只需要将list的value更新
int ret = get(key);
if(ret != -1)
{
//表示已经在list中有了,我们要把这个放在list的最后,并且更新list的value就可以了
um[key]->second = value;
}
else
{
//表示没有找到
//要考虑是否容量是否有满
if(_size >=_capacity)
{
//list中删除最久未使用的,并且在哈希表中删除这个值
um.erase((lt.front()).first);//删除掉list第一个位置的迭代器
//再将list位置的第一个位置删除
lt.pop_front();
}
//list当中放入新的值,并且在哈希表中也放入list的映射
lt.push_back(make_pair(key,value));
um[key] = (--lt.end());
++_size;
}
}
private:
int _size;//链表当前大小
int _capacity;//链表最大容量
list<pair<int,int>> lt;//链表
unordered_map<int,list<pair<int,int>>::iterator> um;//哈希表
};
get的写法2: 可以使用list当中的一个接口splice来实现,他的实现方式也就是拿出一个结点之后,往另一个迭代器的position这个位置前面插入,改变了list的链接关系,list的迭代器其实也只是封装了一下结点,模拟成指针的基本使用,结点没有被释放,迭代器就不会失效,所以这样子是可行的!

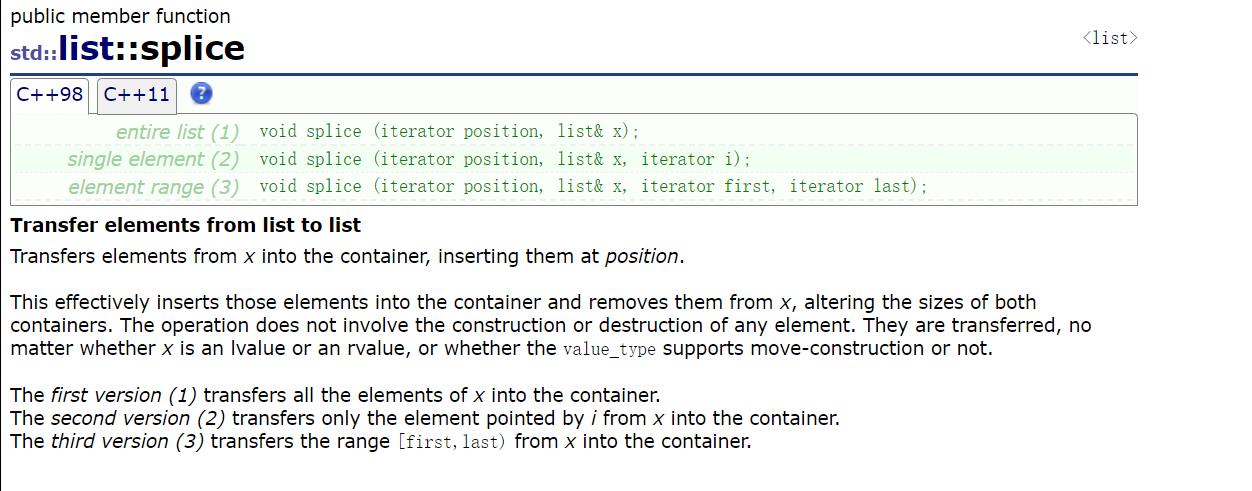
接口get的代码就可以进行简单的更改代码如下:
int get(int key) {
if(um.find(key) != um.end())
{
//倘若哈希表中存在key,就用splice放到list的尾
list<pair<int,int>>::iterator it = um[key];
int value = it->second;
lt.splice(lt.end(),lt,it);//将第二个参数的it这个位置放到第一个参数的前面
return value;
}
else
{
return -1;//找不到
}
}
总结
并查集,LRU Cache的讲解就到这里了,其中的并查集其实结构比较简单,但是后面的LRU Cache大家仔细看我的分析过程,其实也还好,大家如果发现有什么错误欢迎指正。
文章制作不易,一键三连!
以上是关于数据结构一篇文章学懂并查集+LRU Cache,拿来吧你!的主要内容,如果未能解决你的问题,请参考以下文章