怎么操作以kudu为引擎的hive数据库,使用IMPALA方式操作
Posted 吃素的哈士奇
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了怎么操作以kudu为引擎的hive数据库,使用IMPALA方式操作相关的知识,希望对你有一定的参考价值。
KUDU引擎的HIVE数据库
KUDU引擎的HIVE数据库
到底什么是kudu引擎的hive数据库呢?
首先KUDU只是引擎,不是一个库,其实本质的数据还是hive数据库。
原本的HIVE引擎是mr、tez、spark,那么现在改了,改成了kudu引擎。
kudu引擎的好处
kudu适用于公司内部做分析用,涉及的数据量大但是并发量小,而且响应迅速
怎么使用IMPALA操作kudu引擎的数据库呢
首先了解原理
hive的库里面,原本就有一个表TEST,那现在想要用kudu的引擎操作这个表怎么操作呢?
首先就kudu就不是操作当前的表,而是在自己的空间里面建立了一个新的表test_1,然后映射到IMPALA的TEST表上。这一幕是不是似曾相识view(视图)!;对就像是对一个表进行了view(视图)的创建
实操
impala语句
首先是impala的shell语句进入
impala-shell
kudu中建立表TEST1
// 这个是kudu的 master ip以及端口
192.168.1.110:7051
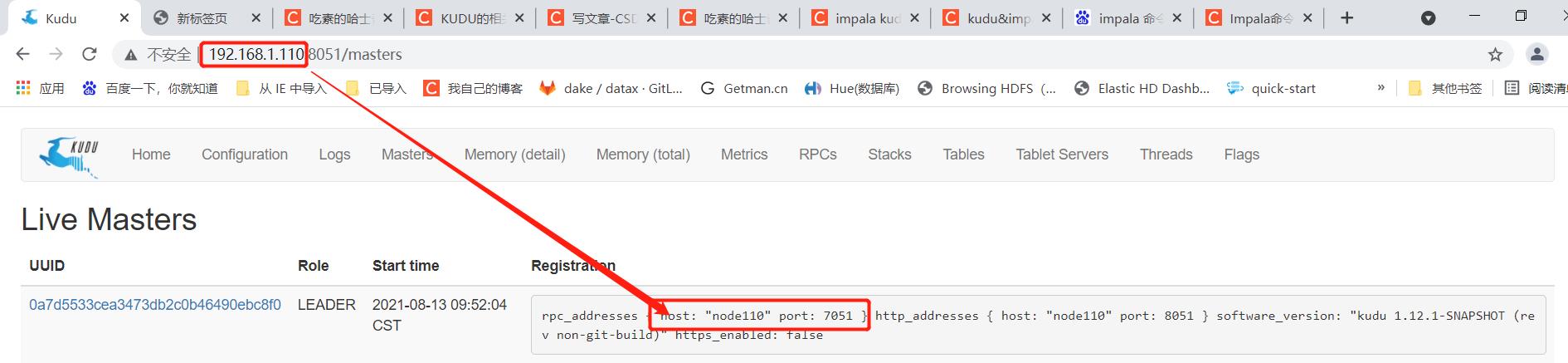
直接贴入impala-shell语句回车后的框子
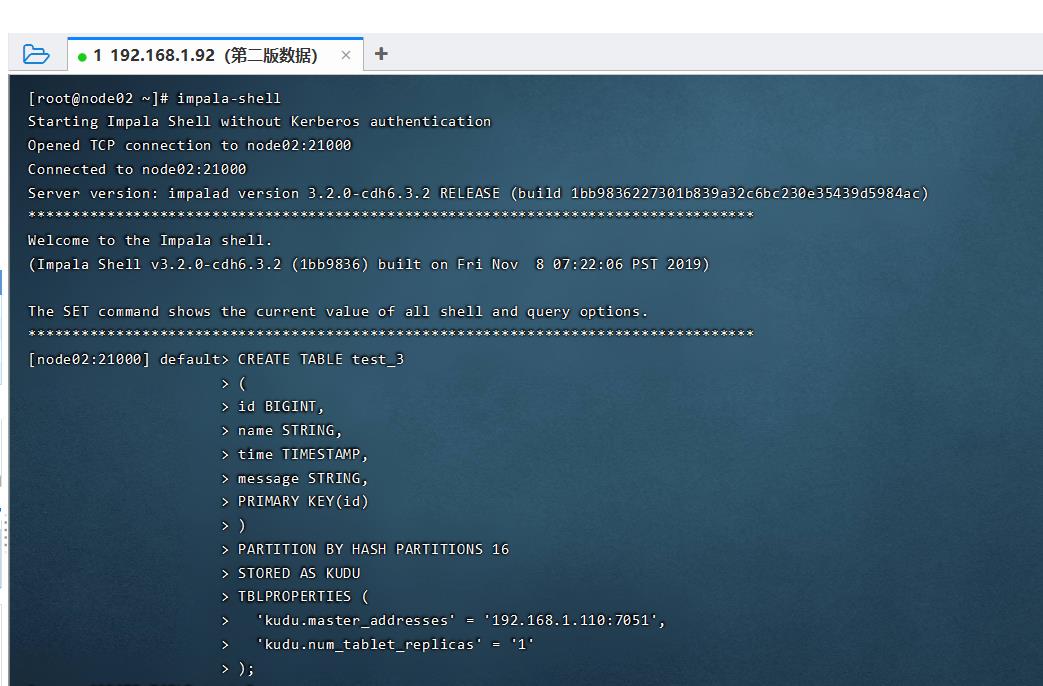
CREATE TABLE test_3
(
id BIGINT,
name STRING,
age BIGINT,
message STRING,
PRIMARY KEY(id)
)
PARTITION BY HASH PARTITIONS 16
STORED AS KUDU
TBLPROPERTIES (
'kudu.master_addresses' = '192.168.1.110:7051',
'kudu.num_tablet_replicas' = '1'
);
kudu的TEST1映射到impala(hive)中
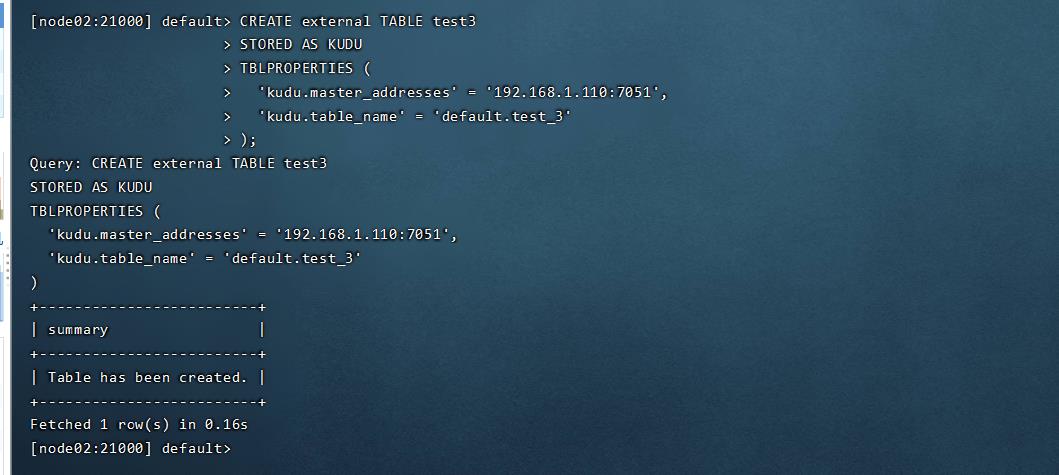
// 将kudu的表映射到impala上
CREATE external TABLE test3
STORED AS KUDU
TBLPROPERTIES (
'kudu.master_addresses' = '192.168.1.110:7051',
'kudu.table_name' = 'default.test_3'
);
删除kudu表
impala的链接删除
drop table datatech.test_3;
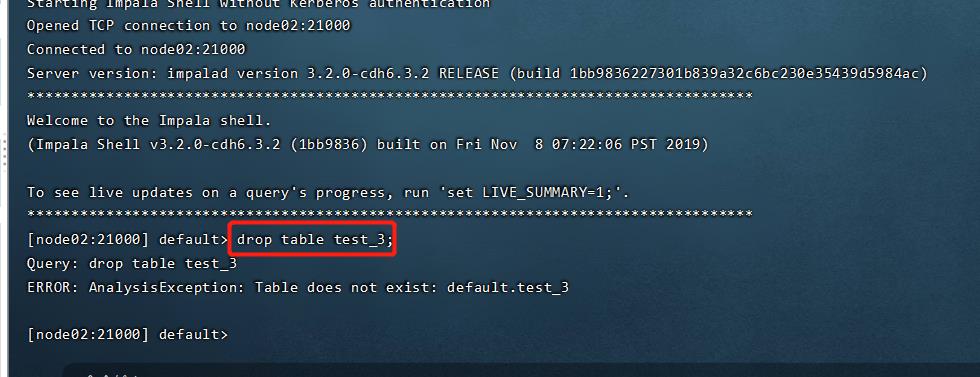
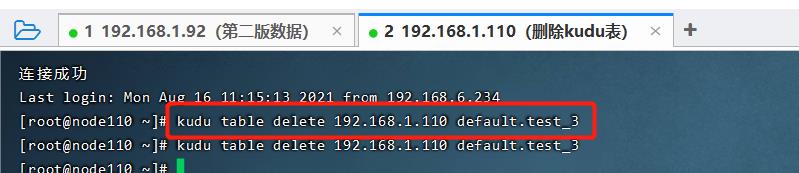
登录KUDU的服务器,使用KUDU语句删除表
kudu table delete 192.168.1.110 default.test_3
特别注意
用户名一定要看清楚:我这里是default,你们一定要确定好自己的数据库用户
执行sql语句一定要以“;”分号结尾
以上是关于怎么操作以kudu为引擎的hive数据库,使用IMPALA方式操作的主要内容,如果未能解决你的问题,请参考以下文章