Apache Beam 剖析
Posted 哥不是小萝莉
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Apache Beam 剖析相关的知识,希望对你有一定的参考价值。
1.概述
在大数据的浪潮之下,技术的更新迭代十分频繁。受技术开源的影响,大数据开发者提供了十分丰富的工具。但也因为如此,增加了开发者选择合适工具的难度。在大数据处理一些问题的时候,往往使用的技术是多样化的。这完全取决于业务需求,比如进行批处理的MapReduce,实时流处理的Flink,以及SQL交互的Spark SQL等等。而把这些开源框架,工具,类库,平台整合到一起,所需要的工作量以及复杂度,可想而知。这也是大数据开发者比较头疼的问题。而今天要分享的就是整合这些资源的一个解决方案,它就是 Apache Beam。
2.内容
Apache Beam 最初叫 Apache Dataflow,由谷歌和其合作伙伴向Apache捐赠了大量的核心代码,并创立孵化了该项目。该项目的大部分大码来自于 Cloud Dataflow SDK,其特点有以下几点:
- 统一数据批处理(Batch)和流处理(Stream)编程的范式
- 能运行在任何可执行的引擎之上
那 Apache Beam到底能解决哪些问题,它的应用场景是什么,下面我们可以通过一张图来说明,如下图所示:
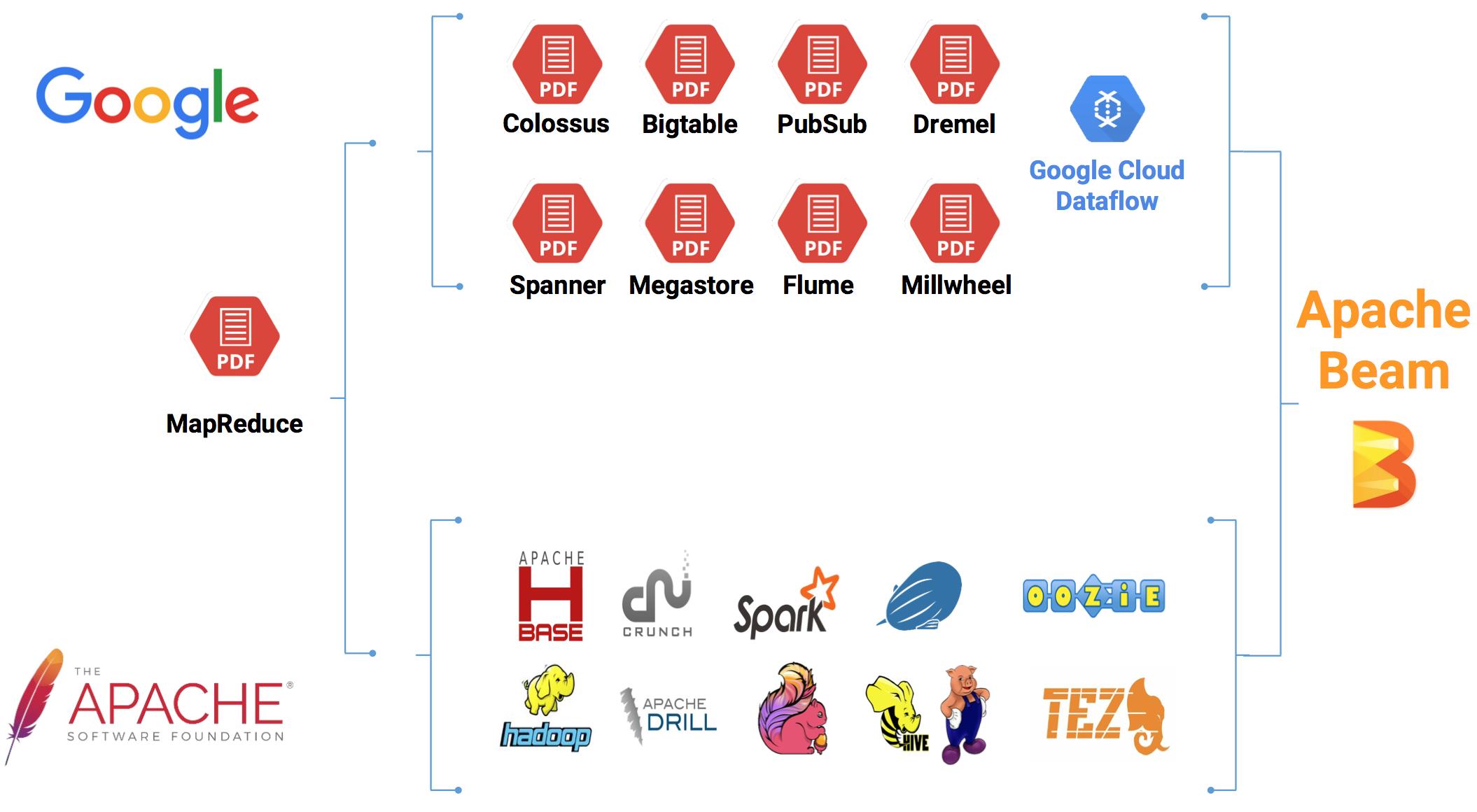
通过改图,我们可以很清晰的看到整个技术的发展流向;一部分是谷歌派系,另一部分则是Apache派系。在开发大数据应用时,我们有时候使用谷歌的框架,API,类库,平台等,而有时候我们则使用Apache的,比如:HBase,Flink,Spark等。而我们要整合这些资源则是一个比较头疼的问题,Apache Beam 的问世,整合这些资源提供了很方便的解决方案。
2.1 Vision
下面,我们通过一张流程图来看Beam的运行流程,如下图所示:
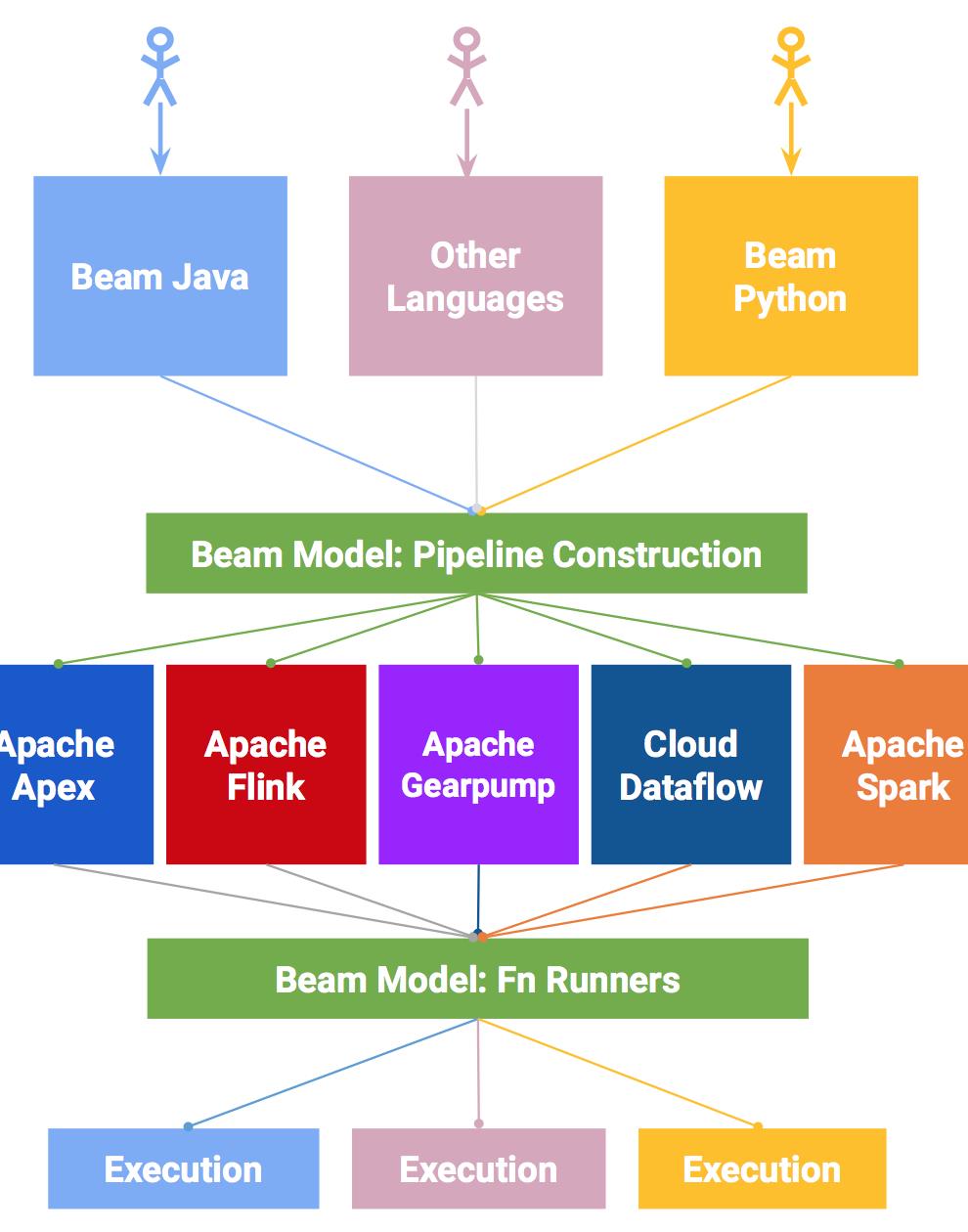
通过上图,我们可以清楚的知道,执行一个流程分以下步骤:
- End Users:选择一种你熟悉的编程语言提交应用
- SDK Writers:该编程语言必须是 Beam 模型支持的
- Library Writers:转换成Beam模型的格式
- Runner Writers:在分布式环境下处理并支持Beam的数据处理管道
- IO Providers:在Beam的数据处理管道上运行所有的应用
- DSL Writers:创建一个高阶的数据处理管道
2.2 SDK
Beam SDK 提供了一个统一的编程模型,来处理任意规模的数据集,其中包括有限的数据集,无限的流数据。Apache Beam SDK 使用相同的类来表达有限和无限的数据,同样使用相同的转换方法对数据进行操作。Beam 提供了多种 SDK,你可以选择一种你熟悉的来建立数据处理管道,如上述的 2.1 中的图,我们可以知道,目前 Beam 支持 Java,Python 以及其他待开发的语言。
2.3 Pipeline Runners
在 Beam 管道上运行引擎会根据你选择的分布式处理引擎,其中兼容的 API 转换你的 Beam 程序应用,让你的 Beam 应用程序可以有效的运行在指定的分布式处理引擎上。因而,当运行 Beam 程序的时候,你可以按照自己的需求选择一种分布式处理引擎。当前 Beam 支持的管道运行引擎有以下几种:
- Apache Apex
- Apache Flink
- Apache Spark
- Google Cloud Dataflow
3.示例
本示例通过使用 Java SDK 来完成,你可以尝试运行在不同的执行引擎上。
3.1 开发环境
- 下载安装 JDK 7 或更新的版本,检测 JAVA_HOME环境变量
- 下载 Maven 打包环境。
关于上述的安装步骤,并不是本篇博客的重点,这里笔者就不多赘述了,不明白的可以到官网翻阅文档进行安装。
3.2 下载示例代码
Apache Beam 的源代码在 Github 有托管,可以到 Github 下载对应的源码,下载地址:https://github.com/apache/beam
然后,将其中的示例代码进行打包,命令如下所示:
$ mvn archetype:generate \\ -DarchetypeRepository=https://repository.apache.org/content/groups/snapshots \\ -DarchetypeGroupId=org.apache.beam \\ -DarchetypeArtifactId=beam-sdks-java-maven-archetypes-examples \\ -DarchetypeVersion=LATEST \\ -DgroupId=org.example \\ -DartifactId=word-count-beam \\ -Dversion="0.1" \\ -Dpackage=org.apache.beam.examples \\ -DinteractiveMode=false
此时,命令会创建一个文件夹 word-count-beam,里面包含一个 pom.xml 和相关的代码文件。命令如下所示:
$ cd word-count-beam/ $ ls pom.xml src $ ls src/main/java/org/apache/beam/examples/ DebuggingWordCount.java WindowedWordCount.java common MinimalWordCount.java WordCount.java
3.3 运行 WordCount 示例代码
一个 Beam 程序可以运行在多个 Beam 的可执行引擎上,包括 ApexRunner,FlinkRunner,SparkRunner 或者 DataflowRunner。 另外还有 DirectRunner。不需要特殊的配置就可以在本地执行,方便测试使用。
下面,你可以按需选择你想执行程序的引擎:
- 对引擎进行相关配置
- 使用不同的命令:通过 --runner=<runner>参数指明引擎类型,默认是 DirectRunner;添加引擎相关的参数;指定输出文件和输出目录,当然这里需要保证文件目录是执行引擎可以访问到的,比如本地文件目录是不能被外部集群访问的。
- 运行示例程序
3.3.1 Direct
$ mvn compile exec:java -Dexec.mainClass=org.apache.beam.examples.WordCount \\ -Dexec.args="--inputFile=pom.xml --output=counts" -Pdirect-runner
3.3.2 Apex
$ mvn compile exec:java -Dexec.mainClass=org.apache.beam.examples.WordCount \\ -Dexec.args="--inputFile=pom.xml --output=counts --runner=ApexRunner" -Papex-runner
3.3.3 Flink-Local
$ mvn compile exec:java -Dexec.mainClass=org.apache.beam.examples.WordCount \\ -Dexec.args="--runner=FlinkRunner --inputFile=pom.xml --output=counts" -Pflink-runner
3.3.4 Flink-Cluster
$ mvn package exec:java -Dexec.mainClass=org.apache.beam.examples.WordCount \\ -Dexec.args="--runner=FlinkRunner --flinkMaster=<flink master> --filesToStage=target/word-count-beam-bundled-0.1.jar \\ --inputFile=/path/to/quickstart/pom.xml --output=/tmp/counts" -Pflink-runner
然后,你可以通过访问 http://<flink master>:8081 来监测运行的应用程序。
3.3.5 Spark
$ mvn compile exec:java -Dexec.mainClass=org.apache.beam.examples.WordCount \\ -Dexec.args="--runner=SparkRunner --inputFile=pom.xml --output=counts" -Pspark-runner
3.3.6 Dataflow
$ mvn compile exec:java -Dexec.mainClass=org.apache.beam.examples.WordCount \\ -Dexec.args="--runner=DataflowRunner --gcpTempLocation=gs://<your-gcs-bucket>/tmp \\ --inputFile=gs://apache-beam-samples/shakespeare/* --output=gs://<your-gcs-bucket>/counts" \\ -Pdataflow-runner
3.4 运行结果
当程序运行完成后,你可以看到有多个文件以 count 开头,个数取决于执行引擎的类型。当你查看文件的内容的时候,每个唯一的单词后面会显示其出现次数,但是前后顺序是不固定的,也是分布式引擎为了提高效率的一种常用方式。
3.4.1 Direct
$ ls counts* $ more counts* api: 9 bundled: 1 old: 4 Apache: 2 The: 1 limitations: 1 Foundation: 1 ...
3.4.2 Apex
$ cat counts* BEAM: 1 have: 1 simple: 1 skip: 4 PAssert: 1 ...
3.4.3 Flink-Local
$ ls counts* $ more counts* The: 1 api: 9 old: 4 Apache: 2 limitations: 1 bundled: 1 Foundation: 1 ...
3.4.4 Flink-Cluster
$ ls /tmp/counts* $ more /tmp/counts* The: 1 api: 9 old: 4 Apache: 2 limitations: 1 bundled: 1 Foundation: 1 ...
3.4.5 Spark
$ ls counts* $ more counts* beam: 27 SF: 1 fat: 1 job: 1 limitations: 1 require: 1 of: 11 profile: 10 ...
3.4.6 Dataflow
$ gsutil ls gs://<your-gcs-bucket>/counts* $ gsutil cat gs://<your-gcs-bucket>/counts* feature: 15 smother\'st: 1 revelry: 1 bashfulness: 1 Bashful: 1 Below: 2 deserves: 32 barrenly: 1 ...
4.总结
Apache Beam 主要针对理想并行的数据处理任务,并通过把数据集拆分多个子数据集,让每个子数据集能够被单独处理,从而实现整体数据集的并行化处理。当然,也可以用 Beam 来处理抽取,转换和加载任务和数据集成任务(一个ETL过程)。进一步将数据从不同的存储介质中或者数据源中读取,转换数据格式,最后加载到新的系统中。
5.结束语
这篇博客就和大家分享到这里,如果大家在研究学习的过程当中有什么问题,可以加群进行讨论或发送邮件给我,我会尽我所能为您解答,与君共勉!
以上是关于Apache Beam 剖析的主要内容,如果未能解决你的问题,请参考以下文章
Apache Beam WordCount编程实战及源代码解读
通过代码从 Apache Beam 应用程序向 Google Cloud 进行身份验证
在 python Apache Beam 中打开一个 gzip 文件
无法使用 Apache Beam(Python SDK)读取 Pub/Sub 消息