openGauss数据库源码解析系列文章—— 执行器解析
Posted Gauss松鼠会
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了openGauss数据库源码解析系列文章—— 执行器解析相关的知识,希望对你有一定的参考价值。
本篇我们开启第七章执行器解析中“7.1 执行器整体架构及代码概览”、“7.2 执行流程”及“7.3 执行算子”的相关精彩内容介绍。
执行器在数据库整个体系结构中起到承上启下的作用,对上承接优化器产生的最优执行计划,并按照执行计划进行流水线式的执行,对底层的存储引擎中的数据进行操作。openGauss数据库将执行的过程抽象成了不同类型的算子,同时结合编译执行、向量化执行、并行执行等方式,组成了全面、高效的执行引擎。本章着重介绍执行器的整体架构、执行模型、各类算子、表达式,以及编译执行和向量化引擎等全新的执行引擎。
7.1 执行器整体架构及代码概览
本节整体介绍执行器的架构和代码。
7.1.1 执行器整体结构
在SQL引擎将用户的查询解析优化成可执行的计划之后,数据库进入查询执行阶段。执行器基于执行计划对相关数据进行提取、运算、更新、删除等操作,以达到用户查询想要实现的目的。
openGauss在行计算引擎的基础上,增加了编译执行引擎和向量化执行引擎,执行器模块架构如图7-1所示。openGauss的执行器采用的是火山模型(volcano model),这是一种经典的流式迭代模型(pipeline iterator model),目前主流的关系型数据库大多采用这种执行模型。
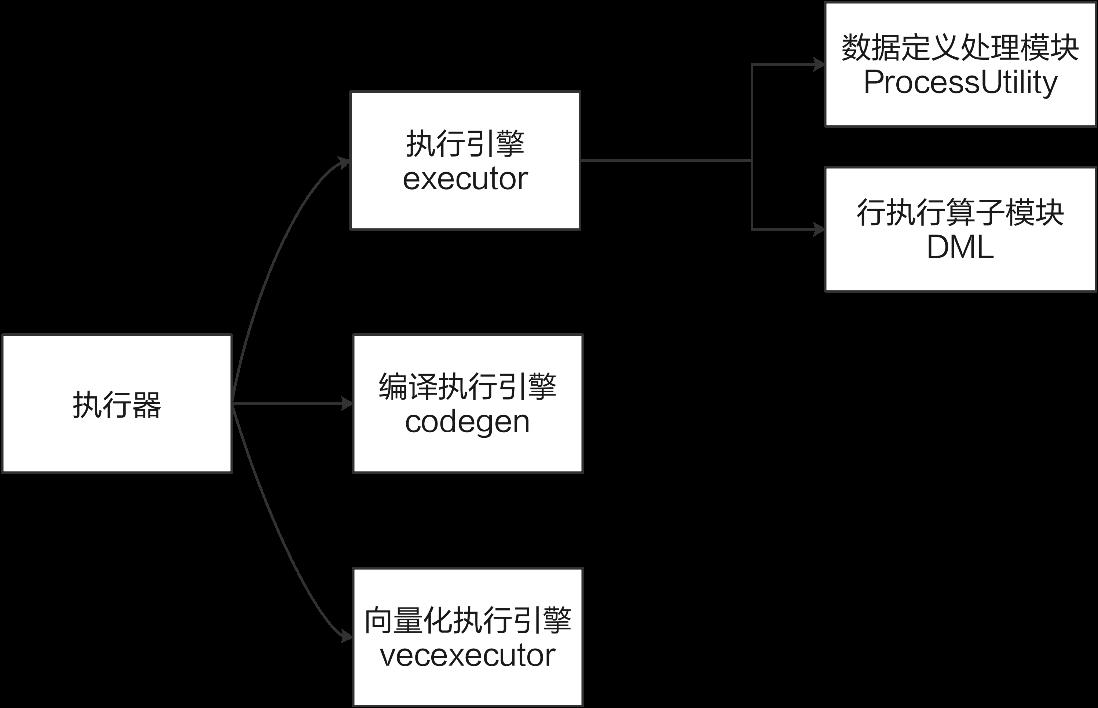
执行器包括四个主要的子模块:Portal、ProcessUtility、executor和特定功能子模块。首先在Portal模块中根据优化器的解析结果,选择相应的处理策略和处理模块(ProcessUtility和executor)。其中executor主要处理用户的增删改查等DML(Data Manipulation Language,数据操作语言)操作。然后ProcessUtility处理增删改查之外的其他各种情况,例如各类DDL(data definition language,数据定义语言)语句、游标操作、事务相关操作、表空间操作等。
7.1.2 火山模型
执行器(executor)的输入是优化器产生的计划树(plan tree),计划树经过执行器转换成执行状态树。执行状态树的每一个节点对应一个独立算子,每个算子都完成一项单一功能,所有算子组合起来,实现了用户的查询目标。在火山模型中,多个算子组成了一个由一个根节点、多个叶子节点和多个中间节点组成的查询树。
每个算子有统一的接口(迭代器模式),从下层的一个或者多个算子获得输入,然后将运算结果返回给上层算子。整个查询执行过程主要是两个流,驱动流和数据流。
驱动流是指上层算子驱动下层算子执行的过程,这是一个从上至下、由根节点到叶节点的过程,如图7-2中的向下的箭头所示。从代码层面来看,即上层算子会根据需要调用下层算子的函数接口,去获取下层算子的输入。驱动流是从跟节点逐层传递到叶子节点。
数据流是指下层算子将数据返回给上层算子的过程,这是一个从下至上,从叶节点到跟节点的过程,如图7-2中的向上的箭头所示。在openGauss中,所有的叶子节点都是都是表数据扫描算子,这些节点是所有计算的数据源头。数据从叶子节点,通过逐层计算,然后从根节点返回给用户。
7.1.3 代码概览
执行器在项目中的源代码路径为:src/gausskernel/runtime。下面是执行器的源码目录。
1) 执行器源码目录
执行器源码目录如表7-1所示。
模块 | 功能 |
|---|---|
Makefile | 编译脚本 |
codegen | 计划编译,加速热点代码执行 |
executor | 执行器核心模块,包括表达式计算、数据定义处理以及行级执行算子 |
vecexecutor | 向量化执行引擎 |
2) 执行器源码文件
执行器源码目录为:src/gausskernel/runtime/模块名。文件如表7-2所示。
模块名 | 源码文件 | 功能 |
|---|---|---|
codegen | codegenutil | 编译执行辅助工具 |
executor | 执行器 | |
llvmir | llvm表达式生成 | |
vecexecutor | 向量化引擎 | |
Makefile | 编译配置文件 | |
executor | Makefile | 编译配置文件 |
execAmi.cpp | 执行器路由算子 | |
execCurrent.cpp | 节点控制 | |
execGrouping.cpp | 支持分组、哈希和聚集操作 | |
execJunk.cpp | 伪列的支持 | |
execMain.cpp | 顶层执行器接口 | |
execMerge.cpp | 处理MERGE指令 | |
execProcnode.cpp | 分发函数按节点调用相关初始化等函数 | |
execQual.cpp | 评估资质和目标列表的表达式 | |
execScan.cpp | 通用的关系扫描 | |
execTuples.cpp | 元组相关的资源管理 | |
execUtils.cpp | 多种执行相关工具函数 | |
functions.cpp | 执行SQL语言函数 | |
instrument.cpp | 计划执行工具 | |
lightProxy.cpp | 轻量级执行代理 | |
nodeAgg.cpp | 聚合算子 | |
nodeAppend.cpp | 添加算子 | |
nodeBitmapAnd.cpp | 位图与算子 | |
nodeBitmapHeapsScan.cpp | 位图堆扫描算子 | |
nodeBitmapIndexScan.cpp | 位图扫描算子 | |
nodeBitmapOr.cpp | 位图或算子 | |
nodeCtescan.cpp | 通用表达式扫描算子 | |
... | ... | |
README | 说明文件 | |
vecnode/vecagg.cpp | 向量聚合算子 | |
vecnode/vecappend.cpp | 向量添加算子 | |
vecnode/vecconstraints.cpp | 约束检查 | |
vecnode/veccstore.cpp | 列存扫描算子 | |
vecnode/veccstoreindexand.cpp | 列存索引扫描算子 | |
vecnode/veccstoreindextidscan.cpp | 列存tid扫描算子 | |
... | ... | |
vecnode/Readme.md | 说明文件 | |
vecprimitive/date.inl | 基础数据类型 | |
vecprimitive/float.inl | 浮点数据类型 | |
vecprimitive/int4.inl | 4字节整数类型 | |
vecprimitive/int8.inl | 8字节整数类型 | |
vecprimitive/numeric.inl | 数值类型 | |
... | ... | |
vecprimitive/Readme.md | 说明文件 | |
vectorsonic/vsonicfilesource.cpp | 读写加速 | |
vectorsonic/vsonicchash.cpp | Hash加速 | |
vectorsonic/vsonichashagg.cpp | Hash聚合 | |
vectorsonic/vsonichashjoin.cpp | Hash连接 |
7.2 执行流程
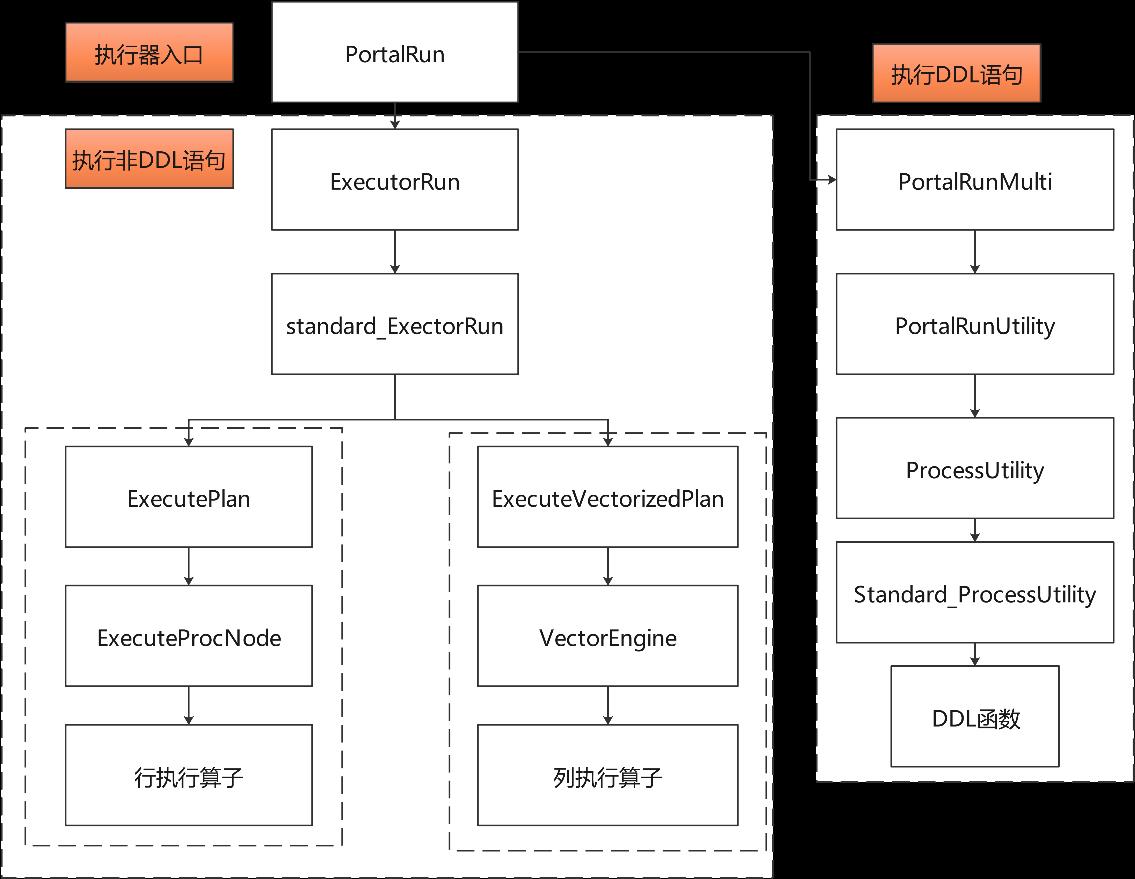
整个执行器的执行流程主要包括了策略选择模块Portal、执行组件executor和ProcessUtility,如图7-3所示。下面逐个进行介绍。
7.2.1 Portal策略选择模块
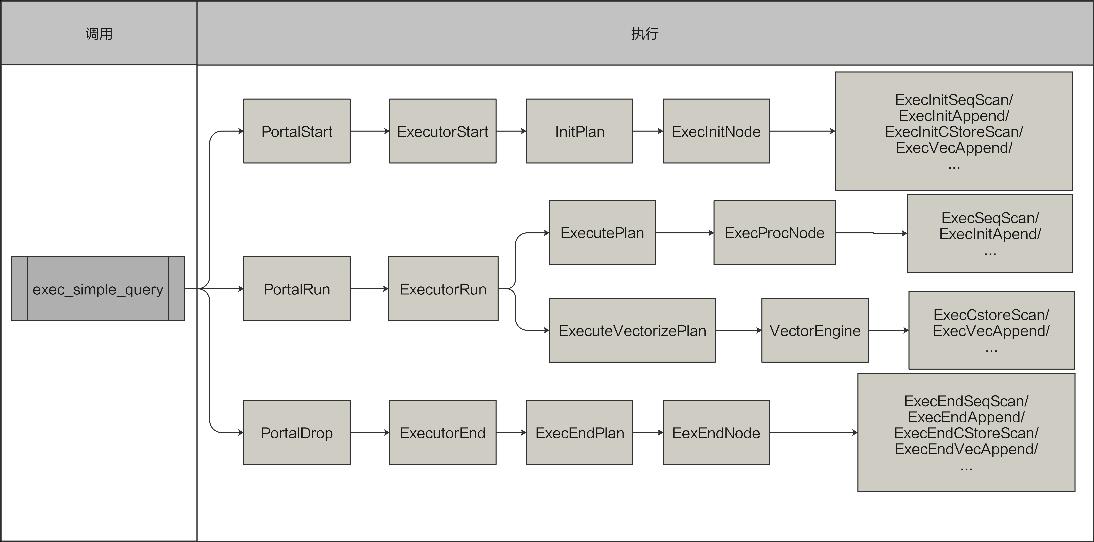
Portal是执行SQL语句的载体,每一条SQL对应唯一的Portal,不同的查询类型对应的Portal类型也有区别,如表7-3所示。SQL语句经过查询编译器处理后会生成优化计划树或非优化计划树,是执行器执行的“原子”操作,执行策略根据需要选择SQL的类型、调用相应的模块。Portal的生命周期管理在exec_simple_query函数中实现,该函数负责Portal创建、执行和清理。Portal执行的主要执行流程包括PortalStart函数、PortalRun函数、PortalDrop函数几个部分。其中PortalStart函数负责进行Portal结构体初始化工作,包括执行算子初始化、内存上下文分配等;PortalRun函数负责真正的执行和运算,它是执行器的核心;PortalDrop函数负责最后的清理工作,主要是数据结构、缓存的清理。
Portal类别 | SQL类型 |
|---|---|
PORTAL_ONE_SELECT | SQL语句包含单一的SELECT查询 |
PORTAL_ONE_RETURNING | INSERT/UPDATE/DELETE语句包含Returning |
PORTAL_ONE_MOD_WITH | 查询语句包含With |
PORTAL_UTIL_SELECT | 工具类型查询语句,如explain |
PORTAL_MULTI_QUERY | 所有其他类型查询语句 |
数据库中的查询主要分为两大类,DDL(CREATE、DROP、ALTER等)查询和DML(SELECT、INSERT、UPDATE、DELETE)查询。这两类查询在执行器中的执行路径存在一定的差异。下面分别介绍这两类查询的主要函数调用关系。
7.2.2 ProcessUtility模块
除了DML之外的所有查询,都通过ProcessUtility模块来执行,包括了各类DDL语句、事务相关语句、游标相关语句等。
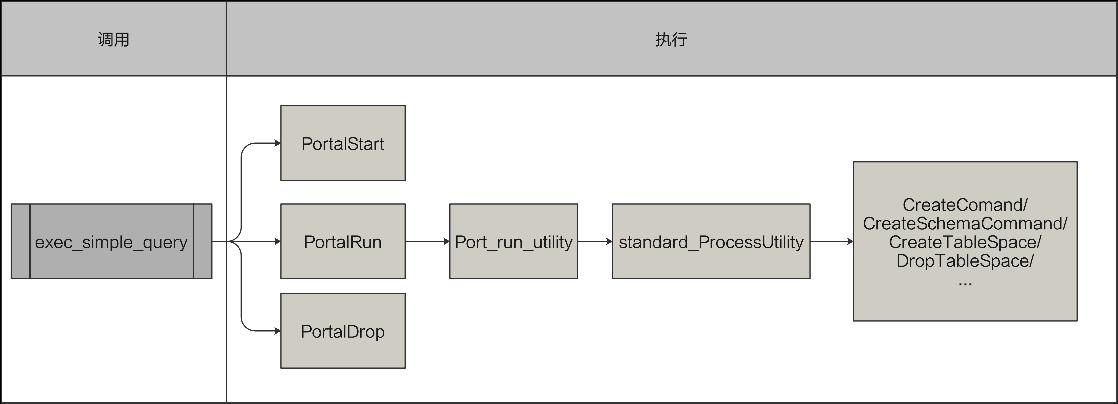
DDL查询的上层函数调用为exec_simple_query函数,其中PortalStart函数和PortalDrop函数部分较为简单。核心函数是PortalRun函数下层调用的standard_ProcessUtility函数,该函数通过switch case语句处理了各种类型的查询语句,调用关系如图7-4所示。包括事务相关查询、游标相关查询、schema相关操作、表空间相关操作、表定义相关操作等。
7.2.3 executor模块
DML会被优化器解析并产生成计划树。在执行阶段的上层函数调用和DDL类似,也是exec_simple_query函数。其中PortalStart函数会遍历整个查询计划树,对每个算子进行初始化。算子初始化函数的命名一般是“ExecInit+算子名”的形式,通过这种方式可以方便的查找到对应算子的初始化函数。初始化函数中首先会根据对应的Plan结构初始化一个对应的PlanState结构,这个结构是执行过程中的核心数据结构,包含了在执行过程中需要用的一些数据存储空间以及执行信息。
在PortalRun函数中会实际执行相关的DML查询,对数据进行计算和处理。在执行过程中,所有执行算子分为2大类,行存储算子和向量化算子。这两类算子分别对应行存储执行引擎和向量化执行引擎。行存储执行引擎的上层入口是ExecutePlan函数,向量化执行引擎的上层入口是ExecuteVectorizedPlan函数。其中向量化引擎是针对列存储表的执行引擎,会在7.6小节详细介绍。如果存在行存储表和列存储表的混合计算,那么行存储执行引擎和向量化执行引擎直接可以通过VecToRow和RowToVec算子进行相互转换。行存储算子执行入口函数的命名规则一般为“Exec+算子名”的形式,向量化算子执行入口函数的命名规则一般为“ExecVec+算子名”的形式;通过这样的命名规则,可以快速地找到对应算子的函数入口。
在PortalDrop函数中会调用ExecEndPlan函数对各个算子进行递归清理,主要是清理在执行过程中产生的内存。各个算子的清理函数入口命名规则是“ExecEnd+算子名”以及“ExecEndVec+算子名”,调用关系如图7-5所示。
7.3 执行算子
执行算子模块包含多种计划执行算子,算子类型如表7-4所示,是计划执行的独立单元,用于实现具体的计划动作。执行计划包含4类算子,分别是控制算子、扫描算子、物化算子和连接算子,如表7-4所示。这些算子统一使用节点(node)表示,具有统一的接口,执行流程采用递归模式。整体执行流程是:首先根据计划节点的类型初始化状态节点(函数名为“ExecInit+算子名”),然后再回调执行函数(函数名为“Exec+算子名”),最后是清理状态节点(函数名为“ExecEnd+算子名”)。本节主要介绍行执行算子,面向列存储的算子在后续章节(向量化引擎)介绍。
算子类型 | 说明 |
|---|---|
控制算子 | 处理特殊执行流程,如Union语句 |
扫描算子 | 用于扫描表对象,从表中获取数据 |
物化算子 | 缓存中间执行结果到临时存储 |
连接算子 | 用于实现SQL中的各类join操作,通常包含nested loop join、hash join、merge-sort join等 |
7.3.1 控制算子
控制算子主要用于执行特殊流程,这类流程通常包含两个以上输入,如Union操作,需要把多个子结果(输入),合并成一个。控制算子有多种,如表7-5所示。
算子名称 | 说明 |
|---|---|
Result算子 | 处理只有一个结果或过滤条件是常量 |
Append算子 | 处理包含一个或多个子计划的链表 |
BitmapAnd算子 | 对结果做And位图运算 |
BitmapOr算子 | 对结果做Or位图运算 |
RecursionUnion算子 | 递归处理UNION语句 |
1. Result算子
Result算子对应的代码源文件是“nodeResult.cpp”,用于处理只有一个结果(如通过SELECT调用可执行函数或表达式,或者INSERT语句只包含Values字句)或者WHERE表达式中的结果是常量(如“SELECT * FROM emp WHERE 2 > 1”,过滤条件“2 > 1”是常量只需要计算一次即可)的流程。由于openGauss没有提供单独的投影算子(Projection)和选择算子(Selection),Result算子也可以起到类似的作用。
Result算子提供的主要函数如表7-6所示。
主要函数 | 说明 |
|---|---|
ExecInitResult | 初始化状态机 |
ExecResult | 迭代执行算子 |
ExecEndResult | 结束清理 |
ExecResultMarkPos | 标记扫描位置 |
ExecResultRestrPos | 重置扫描位置 |
ExecReScanResult | 重置执行计划 |
ExecInitResult函数初始化Result状态节点,主要执行流程如下。
(1) 构造状态节点,构造ResultState状态结构。
(2) 初始化元组表。
(3) 初始化子节点表达式(生成目标列表的表达式、过滤表达式和常量表达式)。
(4) 初始化左子节点(右子节点是空)。
(5) 初始化元组类型和投影信息。
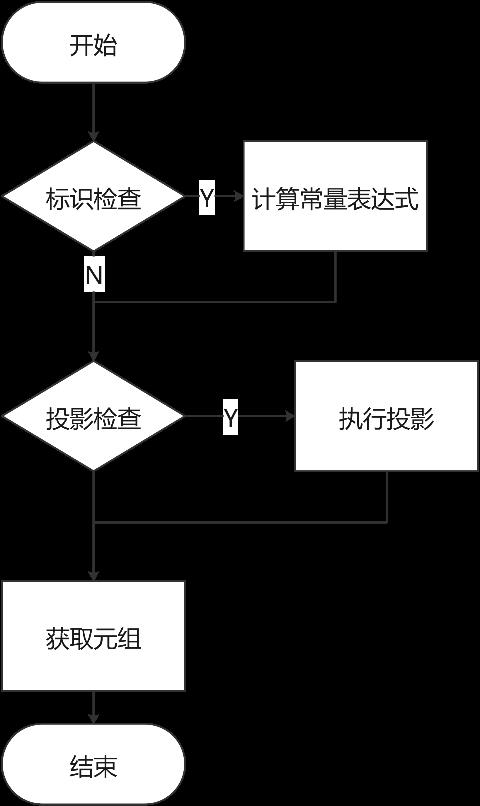
ExecResult函数迭代输出元组,流程图如图7-6所示,主要执行流程如下。
(1) 检查是否需要做常量表达式计算,如果之前没有做常量表达式计算则需要计算表达式并设置检查标识(如果常量表达式计算结果为false,则设置约束检查标识位)。
(2) 判断是否需要做投影处理,如果返回结果是集合,则把投影结果直接返回。
(3) 执行元组获取。
ExecEndResult函数是在执行计划执行结束时调用,用于释放执行过程申请的资源(存储空间)。
2. Append算子
Append算子对应的代码源文件是“nodeAppend.cpp”,用于处理包含一个或多个子计划的链表。Append遍历子计划链表逐个执行子计划,当子计划返回全部结果后,迭代执行下一个子计划。Append算子通常用于SQL中的集合操作中,例如多个Union All操作,可以对多个子查询的结果取并集;另外Append算子还可以用来实现继承表的查询功能。
Append算子提供的主要函数如表7-7所示。
主要函数 | 说明 |
|---|---|
ExecInitAppend | 初始化Append节点 |
ExecAppend | 迭代获取元组 |
ExecEndAppend | 关闭Append节点 |
ExecReScanAppend | 重新扫描Append节点 |
exec_append_initialize_next | 为下一个扫描节点设置状态 |
ExecInitAppend函数初始化Append状态节点,主要执行流程如下。
(1) 初始化Append执行状态节点(AppendState)。
(2) 迭代初始化子计划链表(初始化每一个子计划)。
(3) 设置初始迭代子计划。
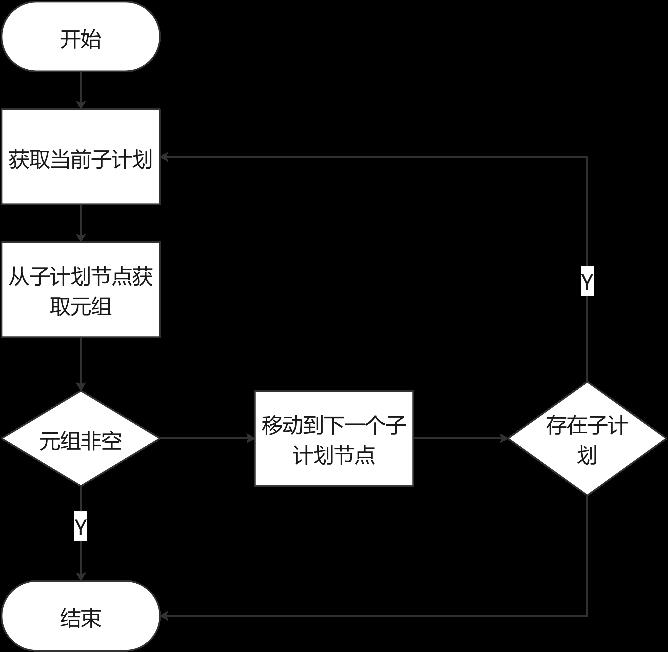
ExecAppend函数迭代输出元组,是Append算子主体函数。每次从子计划中获取一条元组,直到返回元组为空,则移到下一个子计划(使用as_whichplan标记),直至所有子计划都全部执行完。执行流程如图7-7所示。
ExecEndAppend函数负责Append节点清理,遍历子计划数组,逐一释放子计划对应的资源。
3. BitmapAnd算子
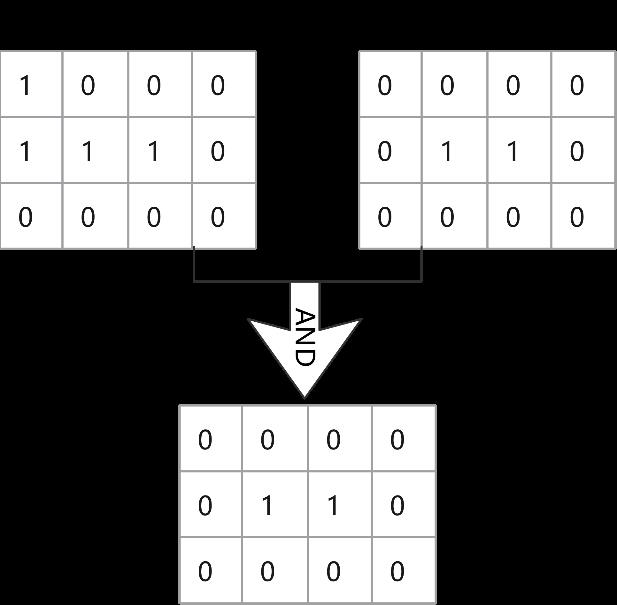
BitmapAnd算子对应的代码源文件是“nodeBitmapAnd.cpp”,用于对多个属性约束都有索引,且属性约束是And运算,对结果做And位图运算。例如:(colA约束条件)AND (colB约束条件),且colA,colB建有索引,colA对应的位图是Bitmap A,colB对应的位图是Bitmap B。位图运算如图7-8所示。
BitmapAnd算子提供的主要函数如表7-8所示。
主要函数 | 说明 |
|---|---|
ExecInitBitmapAnd | BitmapAnd节点初始化 |
MultiExecBitmapAnd | 获取Bitmap节点 |
ExecEndBitmapAnd | 关闭BitmapAnd节点 |
ExecReScanBitmapAnd | 重新扫描BitmapAnd节点 |
ExecInitBitmapAnd函数主要执行流程:首先创建Bitmapand状态节点;然后再逐一初始化子计划状态节点。
MultiExecBitmapAnd函数是BitmaAnd计划节点的主体函数,通过迭代方式做求交运算,结果集是一个新的节点。
ExecEndBitmapAnd函数是计划节点退出函数,负责关闭BitmapAnd子计划节点。
4. BitmapOr算子
BitmapOr节点同BitmapAnd节点类似,主要差异是BitmapAnd对子计划结果做求交计算(tbm_intersect),而BitmapOr是对子计划结果做并集计算(tbm_union)。BitmapOr算子提供的主要函数如表7-9所示。
主要函数 | 说明 |
|---|---|
ExecInitBitmapOr | BitmapOr节点初始化 |
MultiExecBitmapOr | 获取Bitmap节点 |
ExecEndBitmapOr | 关闭BitmapOr节点 |
ExecReScanBitmapOr | 重新扫描BitmapOr节点 |
5. RecursiveUnion算子
RecursiveUnion算子对应的代码源文件是“nodeRecursiveUnion.cpp”,用于递归处理UNION语句。
下面给出一个例子,用SQL实现1到10递归求和,语句如下:
/* 递归求和 */
WITH RECURSIVE t_recursive_union(i)AS(
VALUES (0)
UNION ALL
SELECT i + 1 FROM t_recursive_union WHERE i < 10)
SELECT sum(i) FROM t_recursive_union;
/* 查询计划 */
Aggregate
CTE t_recursive_union
-> Recursive Union
-> Values Scan on "*VALUES*"
-> WorkTable Scan on t_recursive_union
Filter: (i < 10)
-> CTE Scan on t_recursive_union
上述例子由RecursiveUnion算子处理,初始数据是VALUSE (0),然后再递归部分处理输出,即“SELECT i + 1 FROM t_recursive_union WHERE i < 10”。
RecursiveUnion使用左子树获取初始元组(初始迭代种子),使用右子树递归输出其余元组。RecursiveUnion算子提供的主要函数如表7-10所示。
主要函数 | 说明 |
|---|---|
ExecInitRecursiveUnion | 初始化RecursiveUnion状态节点 |
ExecRecursiveUnion | 迭代输出元组 |
ExecEndRecursiveUnion | 清理RecursiveUnion节点 |
ExecReScanRecursiveUnion | 重置RecursiveUnion节点 |
ExecReScanRecursivePlanTree | 重置RecursiveUnion计划树 |
RecursiveUnion算子对应的关键结构体代码如下:
typedef struct RecursiveUnion
{
Planplan;
intwtParam;/* 对应的工作表ID */
intnumCols;/* 去重属性个数 */
AttrNumber *dupColIdx;/* 去重判断属性编号 */
Oid *dupOperators;/* 去重判断函数 */
Oid *dupCollations;
longnumGroups;/* 元组树估算 */
} RecursiveUnion;
ExecInitRecursiveUnion函数的主要执行流程如下。
(1) 构造递归合并状态节点,并初始化工作表(working_table)和缓存表(intermediate_table),如果需要去除重复则需要构造哈希表上下文。
(2) 初始化左子节点(用于输出初始元组作为迭代种子)和右子节点(用于迭代输出其他满足迭代条件的元组)。
(3) 创建用于去重的哈希表。
ExecRecursiveUnion函数是RecursiveUnion节点的主体函数,它的主要执行流程是:
(1) 执行左子节点,将获取元组直接返回(左子节点用于输出初始迭代种子);如需要去重则把元组加入哈希表中。
(2) 当处理完左节点(所有的初始种子已经输出),则执行右子节点获取其余元组,在执行右子节点时会逐一从工作表(working_table)获取迭代输入,并把非空的元组放入缓存表(intermediate_table)。
(3) 当工作表为空时,则把缓存表作为新的工作表,直至所有的元组都输出(缓存表和工作表都为空),如需要去重则把元组加入哈希表中。
ExecEndRecursiveUnion是清理函数,负责释放执行过程申请的存储资源(用于去重的哈希表),并关闭左子节点和右子节点。
7.3.2 扫描算子
扫描算子用于表、结果集、链表子查询等结果遍历,每次获取一条元组作为上层节点的输入。控制算子中的BitmapAnd/BitmapOr函数所需的位图与扫描算子(索引扫描算子)密切相关。主要包括顺序扫描(SeqScan)、索引扫描(IndexScan)、位图扫描(BitmapHeapScan)、位图索引扫描(BitmapIndexScan)、元组TID扫描(TIDScan)、子查询扫描(SubqueryScan)、函数扫描(FunctionScan)等。扫描算子如表7-11所示。
算子名称 | 说明 |
|---|---|
SeqScan算子 | 用于扫描基础表 |
IndexScan算子 | 对表的扫描使用索引加速元组获取 |
BitmapIndexScan算子 | 通过位图索引做扫描操作 |
TIDScan算子 | 遍历元组的物理存储位置获取一个元组 |
SubqueryScan算子 | 子查询生成的子执行计划 |
FunctionScan算子 | 用于从函数返回的数据集中获取元组 |
ValuesScan算子 | 用于处理“Values (…),(…), …”类型语句,从值列表中输出元组 |
CteScan算子 | 用于处理With表达式对应的子查询 |
WorkTableScan算子 | 用于递归工作表元组输出 |
PartIterator算子 | 用于支持分区表的wise join |
IndexOnlyScan算子 | 如索引的键值满足了查询中所有表达式的需求,可以通过只对索引扫描获得元组,避免对堆表(Heap)的访问 |
ForeignScan算子 | 扫描外部数据表 |
1. SeqScan算子
SeqScan算子是最基本的扫描算子,对应SeqScan执行节点,对应的代码源文件是“nodeSeqScan.cpp”,用于对基础表做顺序扫描。算子对应的主要函数如表7-12所示。
主要函数 | 说明 |
|---|---|
ExecInitSeqScan | 初始化SeqScan状态节点 |
ExecSeqScan | 迭代获取元组 |
ExecEndSeqScan | 清理SeqScan状态节点 |
ExecSeqMarkPos | 标记扫描位置 |
ExecSeqRestrPos | 重置扫描位置 |
ExecReScanSeqScan | 重置SeqScan |
InitScanRelation | 初始化扫描表 |
ExecInitSeqScan函数初始化SeqScan状态节点,负责节点状态结构构造,并初始化用于存储结果的元组表。
ExecSeqScan函数是SeqScan算子执行的主体函数,用于迭代获取每一个元组。ExecSeqScan函数通过回调函数调用SeqNext函数、HbktSeqSampleNext函数、SeqSampleNext函数实现获取元组。非采样获取元组时调用SeqNext函数;如果需要采样且对应的表采用哈希桶方式存储则调用HbktSeqSampleNext函数,否则调用SeqSampleNext函数。
2. IndexScan算子
IndexScan算子是索引索引扫描算子,对应IndexScan计划节点,相关的代码源文件是“nodeIndexScan.cpp”文件。如果过滤条件涉及索引,查询计划对表的扫描使用IndexScan算子,利用索引加速元组获取。算子对应的主要函数如表7-13所示。
主要函数 | 说明 |
|---|---|
ExecInitIndexScan | 初始化IndexScan状态节点 |
ExecIndexScan | 迭代获取元组 |
ExecEndIndexScan | 清理IndexScan状态节点 |
ExecIndexMarkPos | 标记扫描位置 |
ExecIndexRestrPos | 重置扫描位置 |
ExecReScanIndexScan | 重置IndexScan |
ExecInitIndexScan函数负责初始化IndexScan状态节点。主要执行流程如下。
(1) 创建IndexScanState节点。
(2) 初始化子节点,初始化目标列表、索引过滤条件、原始过滤条件。
(3) 打开对应表。
(4) 打开索引。
(5) 构建索引扫描Key。
(6) 处理ORDER BY对应的Key。
(7) 启动索引扫描(返回索引扫描描述符IndexScanDesc)。
(8) 把过滤Key传递给索引器。
ExecIndexScan函数负责迭代获取元组,通过回调函数的形式调用IndexNext函数获取元组。IndexNext函数首先按照扫描Key获取元组,然后再执行表达式indexqualorig判断元组是否满足过滤条件,如果不满足则需要继续获取。
ExecEndIndexScan函数负责清理IndexScanState节点。主要执行流程如下。
(1) 清理元组占用的槽位。
(2) 关闭索引扫描描述子。
(3) 关闭索引(如果是分区表则需要关闭分区索引及分区映射)。
(4) 关闭表。
3. BitmapIndexScan算子
BitmapIndexScan算子通过位图索引做扫描操作,利用位图记录元组在存储页面的偏移位置,对应BitmapIndexScan计划节点。BitmapIndexScan算子相关的代码源文件是“nodeBitmapIndexScan.cpp”。BitmapIndexScan执行的结果是位图,该算子配合BitmapHeapScan算子获取位图对应的元组。算子对应的主要函数如表7-14所示。
主要函数 | 说明 |
|---|---|
ExecInitBitmapIndexScan | 初始化BitmapIndexScan状态节点 |
MultiExecBitmapIndexScan | 获取所有元组位图 |
ExecEndBitmapIndexScan | 清理BitmapIndexScan状态节点 |
ExecReScanIndexScan | 重置BitmapIndexScan |
ExecInitPartitionForBitmapIndexScan | 初始化分区表类型 |
BitmapIndexScan算子对应的状态节点代码如下:
typedef struct BitmapIndexScanState {
ScanState ss; /* 节点状态标识 */
TIDBitmap* biss_result; /* 位图:扫描结果集 */
ScanKey biss_ScanKeys; /* 索引扫描过滤表达式 */
int biss_NumScanKeys; /* 索引扫描键数量 */
IndexRuntimeKeyInfo* biss_RuntimeKeys; /* 索引扫描运行时求值表达式 */
int biss_NumRuntimeKeys; /* 运行时索引扫描键数量 */
IndexArrayKeyInfo* biss_ArrayKeys;/* 扫描键数组 */
int biss_NumArrayKeys; /* 数组长度 */
bool biss_RuntimeKeysReady; /* 运行时扫描键已经计算标识 */
ExprContext* biss_RuntimeContext; /* 求值表达式上下文 */
Relation biss_RelationDesc; /* 索引描述 */
List* biss_IndexPartitionList; /* 分区表对应索引 */
LOCKMODE lockMode; /* 锁模式 */
Relation biss_CurrentIndexPartition; /* 当前对应分区索引 */
} BitmapIndexScanState;
ExecInitBitmapIndexScan函数初始化BitmapIndexScan状态节点(BitmapIndexScanState)。主要执行流程如下。
(1) 创建BitmapIndexScanState节点用于存储状态信息。
(2) 打开索引。
(3) 构建索引扫描Key。
(4) 启动索引扫描(返回索引扫描描述符IndexScanDesc)。
(5) 把过滤Key传递给索引器。
MultiExecBitmapIndexScan函数返回所有元组位图。主要执行流程如下。
(1) 准备Bitmap结果集,用于存储元组ID。
(2) 步循环批量获取元组并存储于Bitmap结果集。如果有多组过滤Key(使用函数ExecIndexAdvanceArrayKeys判断)则继续循环批量获取元组。
4. BitmapHeapScan算子
BitmapHeapSan算子通过位图(BitmapIndexScan的输出)获取实际的元组,对应的代码源文件是“BitmapHeap.cpp”。算子对应的主要函数如表7-15所示。
主要函数 | 说明 |
|---|---|
ExecInitBitmapHeapScan | 初始化BitmapHeapScan状态节点 |
ExecBitmapHeapScan | 迭代获取元组 |
ExecEndBitmapHeapScan | 清理BitmapHeapScan状态节点 |
ExecReScanBitmapHeapScan | 重置BitmapHeapScan |
BitmapHeapScan算子对应的状态节点代码如下:
typedef struct BitmapHeapScanState {
ScanState ss; /* 节点标识 */
List* bitmapqualorig; /* 元组过滤条件 */
TIDBitmap* tbm; /* 位图:来自BitmapIndexScan节点输出 */
TBMIterator* tbmiterator; /* 位图迭代器 */
TBMIterateResult* tbmres; /* 迭代结果 */
TBMIterator* prefetch_iterator; /* 预抓取迭代器 */
int prefetch_pages; /* 预获取页面数量 */
int prefetch_target; /* 当前获取页面 */
} BitmapHeapScanState;
ExecInitBitmapHeapScan函数负责初始化BitmapHeapScan状态节点(BitmapHeapScanState)。主要执行流程如下。
(1) 创建BitmapHeapScanState状态节点。
(2) 初始化子节点,初始化目标列表、索引过滤条件、原始过滤条件。
(3) 打开对应表。
(4) 初始化元组槽位并设置元组迭代获取函数。
(5) 启动表扫描(返回表扫描描述符TableScanDesc)。
(6) 初始化左子节点(左子节点负责执行位图索引扫描,并返回位图)。
ExecBitmapHeapScan函数负责迭代输出元组。使用回调函数获取元组,依照表的类型调用BitmapHeapTblNext函数或BitmapHbucketTblNext(哈希桶类型)函数。BitmapHeapTblNext函数的主要执行流程是:首先初始化位图,然后使用位图迭代器tbmres获取元组偏移位置,最后从缓冲区获取元组slot。
ExecEndBitmapHeapScan函数负责清理BitmapHeapScan状态节点,清理流程类似于ExecEndIndexScan函数。
5. TIDScan算子
TIDScan算子用于通过遍历元组的物理存储位置获取每一个元组(TID由块编号和偏移位置组成),对应TIDScanState计划节点,相应的代码源文件是“nodeTIDScan.cpp”。算子对应的主要函数如表7-16所示。
主要函数 | 说明 |
|---|---|
ExecInitTidScan | 初始化TIDScan状态节点 |
ExecTidScan | 迭代获取元组 |
ExecEndTidScan | 清理TIDScan状态节点 |
ExecReScanTidScan | 重置TIDScan |
TID扫描算子对应的状态节点代码如下:
typedef struct TidScanState {
ScanState ss; /* 节点标识 */
List* tss_tidquals; /* tid过滤表达式 */
bool tss_isCurrentOf; /* 游标同当前扫描表是否匹配 */
Relation tss_CurrentOf_CurrentPartition; /* 当前扫描分区 */
int tss_NumTids; /* tid数量 */
int tss_TidPtr; /* 当前扫描位置 */
int tss_MarkTidPtr; /* 标记扫描位置 */
ItemPointerData* tss_TidList; /* tid列表 */
HeapTupleData tss_htup; /* 堆元组 */
HeapTupleHeaderData tss_ctbuf_hdr; /* 堆元组头信息 */
} TidScanState;
ExecInitTidScan是TIDScan节点状态初始化函数。主要执行流程如下。
(1) 创建TidScanState节点。
(2) 初始化子节点,初始化目标列表、索引过滤条件、原始过滤条件。
(3) 打开对应表。
(4) 初始化结果元组;
(5) 启动表扫描(返回表扫描描述符TableScanDesc)。
ExecTidScan是元组迭代获取函数,通过调用TidNext函数实现功能。TidNext函数首先获取Tid列表,并存放到tss_TidList数组中,根据heap_relation调用TidFetchTuple函数或HbtTidFetchTuble函数(哈希桶类型)中逐一获取元组(tss_TidPtr是tid在数组中的相对偏移位置,使用函数InitTidPtr移动偏移位置)。
6. SubqueryScan算子
SubqueryScan算子以子计划为扫描对象,实际执行会
以上是关于openGauss数据库源码解析系列文章—— 执行器解析的主要内容,如果未能解决你的问题,请参考以下文章