Python|Kaggle机器学习系列之Pandas基础练习题
Posted 海轰Pro
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python|Kaggle机器学习系列之Pandas基础练习题相关的知识,希望对你有一定的参考价值。
前言
Hello!小伙伴!
非常感谢您阅读海轰的文章,倘若文中有错误的地方,欢迎您指出~
自我介绍 ଘ(੭ˊᵕˋ)੭
昵称:海轰
标签:程序猿|C++选手|学生
简介:因C语言结识编程,随后转入计算机专业,有幸拿过一些国奖、省奖…已保研。目前正在学习C++/Linux/Python
学习经验:扎实基础 + 多做笔记 + 多敲代码 + 多思考 + 学好英语!
初学Python 小白阶段
文章仅作为自己的学习笔记 用于知识体系建立以及复习
题不在多 学一题 懂一题
知其然 知其所以然!
往期推荐
【Python|Kaggle】机器学习系列之Pandas基础练习题(一)
【Python|Kaggle】机器学习系列之Pandas基础练习题(二)
【Python|Kaggle】机器学习系列之Pandas基础练习题(三)
Introduction
In these exercises we’ll apply groupwise analysis to our dataset.
Run the code cell below to load the data before running the exercises.
事先导入后面所需的数据集、库
import pandas as pd
reviews = pd.read_csv("../input/wine-reviews/winemag-data-130k-v2.csv", index_col=0)
pd.set_option("display.max_rows", 5)
from learntools.core import binder; binder.bind(globals())
from learntools.pandas.grouping_and_sorting import *
print("Setup complete.")
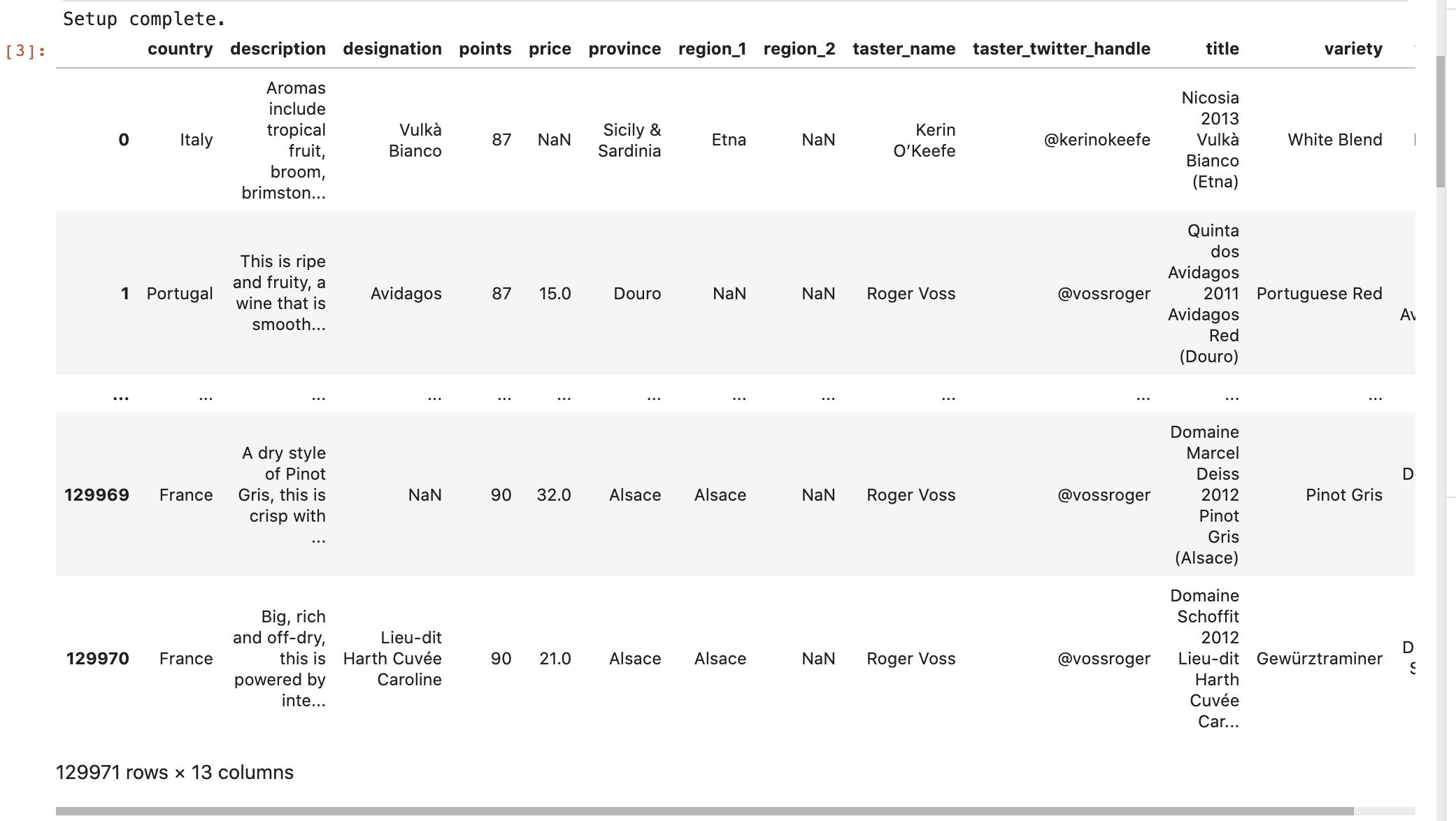
reviews
本练习使用的数据集:
Exercises
1.
题目
Who are the most common wine reviewers in the dataset? Create a Series whose index is the taster_twitter_handle category from the dataset, and whose values count how many reviews each person wrote.
解答
题目意思:
创建一个Series,其索引是数据集中的taster_twitter_handle类别,其值计算每个人写了多少评论。
也就是先对taster_twitter_handle进行分组 然后统计每一个组的size
reviews_written = reviews.groupby('taster_twitter_handle').size()

其余参考Demo:
reviews_written = reviews.groupby('taster_twitter_handle').taster_twitter_handle.count()
Note:
- size作用与dataframe
- count作用于seriers
2.
题目
What is the best wine I can buy for a given amount of money? Create a Series whose index is wine prices and whose values is the maximum number of points a wine costing that much was given in a review. Sort the values by price, ascending (so that 4.0 dollars is at the top and 3300.0 dollars is at the bottom).
解答
题目意思:
找出每个价格 对应评分中最高的一个
best_rating_per_price = reviews.groupby('price').points.max()

其余参考Demo:
best_rating_per_price = reviews.groupby('price')['points'].max().sort_index()
# best_rating_per_price = reviews.groupby('price')['points'].max() 这个也是正确的

3.
题目
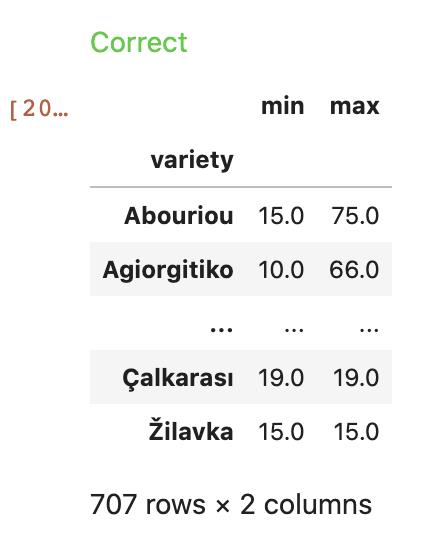
What are the minimum and maximum prices for each variety of wine? Create a DataFrame whose index is the variety category from the dataset and whose values are the min and max values thereof.
解答
题目意思:
统计出每一种酒类型(variety)对应的最高价格和最低价格
price_extremes = reviews.groupby('variety').price.agg([min,max])
4.
题目
What are the most expensive wine varieties? Create a variable sorted_varieties containing a copy of the dataframe from the previous question where varieties are sorted in descending order based on minimum price, then on maximum price (to break ties).
解答
题目意思:
统计出每一种酒(variety)对应的最高价格、最低价格 ,然后先按照最低价格进行降序排列,最低价格相同时,依据最高价格进行降序排列
sorted_varieties = price_extremes.sort_values(by=['min', 'max'], ascending=False)

5.
题目
Create a Series whose index is reviewers and whose values is the average review score given out by that reviewer. Hint: you will need the taster_name and points columns.
解答
题目意思:
统计每一个品酒师(taster_name)其所有评分(points)的平均值
reviewer_mean_ratings = reviews.groupby('taster_name').points.mean()

6.
题目
What combination of countries and varieties are most common? Create a Series whose index is a MultiIndexof {country, variety} pairs. For example, a pinot noir produced in the US should map to {"US", "Pinot Noir"}. Sort the values in the Series in descending order based on wine count.
解答
题目意思:
统计每一个国家(country)所具有不同酒种类(variety)的数量 按照降序排列(按照数量)
country_variety_counts = reviews.groupby(['country','variety']).size().sort_values(ascending=False)

结语
文章仅作为学习笔记,记录从0到1的一个过程
希望对您有所帮助,如有错误欢迎小伙伴指正~
我是 海轰ଘ(੭ˊᵕˋ)੭
如果您觉得写得可以的话,请点个赞吧
谢谢支持 ❤️

以上是关于Python|Kaggle机器学习系列之Pandas基础练习题的主要内容,如果未能解决你的问题,请参考以下文章