grep的用法(CentOS7)及有关正则表达式的使用
Posted 无为
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了grep的用法(CentOS7)及有关正则表达式的使用相关的知识,希望对你有一定的参考价值。
环境准备:alias grep="grep --color"
1、grep以整行为单位进行处理,行中有的匹配显示出来
Last中取出符合root的行:grep \'查找字符串\'
last|grep \'root\'
2、取出没有root的行:last|grep -vn \'root\'
-v:反向选择,显示出没有\'root\'行的数据;
-n: 输出行号;
3、取出查找到的\'eth0\'行和此行的前两行与后两行:dmesg|grep -n -A 2 -B 2 \'eth0\'
-A:after,显示按要求查出的行以及后#行
-B:before,显示按要求查出的行以及前#行
-C: 除了显示所匹配的那一列之外,并显示该列之前后的内容
dmesg:显示内核信息。

那么,各取出查找行的前后各三行呢?可以用上面的-A -B,当然,也可以使用-C来表示。
查找出\'eth0\'的前后各三行:dmesg |grep -n -A 3 -B 3 \'eth0\'或者 dmesg|grep -n -C 3 \'eth0\'
4、[]的使用:[]里出现的字符被查找出来,[]里面可以有多个字符,但一个[]代表一个字符。
grep -n \'t[ae]st\' regular_express.txt

[A-Z]:表示A到Z大写的26个英文字母中的一个;也可用[:upper:];
[a-z]:表示a到z小写的26个英文字母中的一个;也可用[:lower:];
[0-9]:表示0到9的10个数字中的一个数字;也可用[:digit:];
[:alpha:]:表示大小写英文字母;
grep -n \'[^g]oo\' regular_express.txt

解释:\'[^g]oo\'查找oo前面没有g的字符串。第19行,也可以组成oo前面是oo,故而符合要求。
5、行首匹配用^,行尾匹配用$
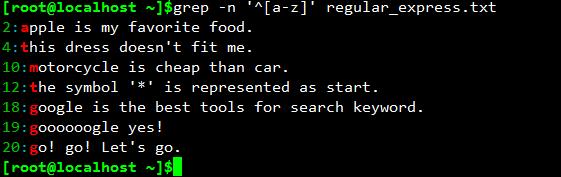
grep -n \'^[a-z]\' regular_express.txt
匹配出行首是小写字母的行。
区别:[^](^在[]里面)表示取补集,取返。
^[](^在[]外)表示在行首 。
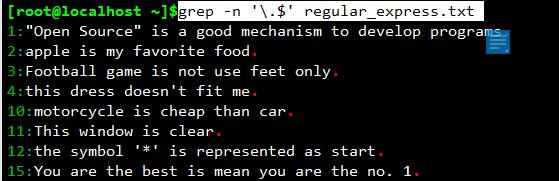
取出以.号结尾的行:grep -n \'\\.$\' regular_express.txt
转义字符的详细情况,请自行查阅 。
6、整个单词的匹配:\\bword\\b或者\\<word\\>。其中,\\b和\\<表示词首锚定,\\b和\\>表示词尾锚定。
显示用户lp默认的shell程序:cat /etc/passwd | grep \'\\blp\\b\'

7、不区分大小写匹配查找:
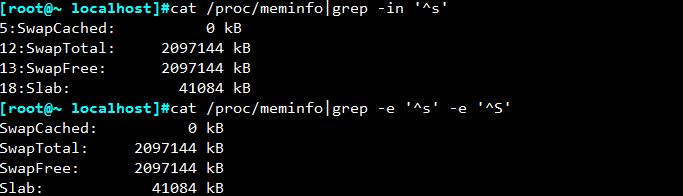
显示/proc/meminfo文件中以大小s开头的行:
cat /proc/meminfo|grep -in \'^s\'或者 cat /proc/meminfo|grep -e \'^s\' -e \'^S\'
8、仅显示匹配到的字符串
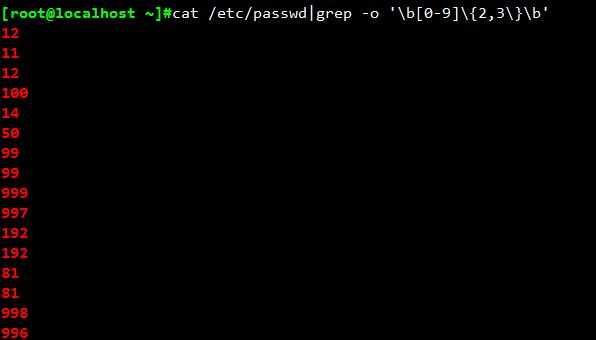
找出/etc/passwd中的两位或三位数的数字:cat /etc/passwd|grep -o \'\\b[0-9]\\{2,3\\}\\b\'
其中,-o表示仅显示匹配到的字符串。
\\{m,n\\}表示前面的字符至少出现m次,至多出现n次。此处是至少出现2位数,至多出现3位数。
9、分组的使用:
找出/etc/passwd用户名同shell名的行:cat /etc/passwd|grep \'^\\(\\b.*\\b\\):.*\\1$\'
其中:\\(\\)是分组的表示,\\1是引用分组变量。
注意:\\(\\)是分组的使用;\\{\\}是前面字符出现次数的使用;[]是匹配任意一个中括号里面指定的字符。
附:
egrep:
egrep = grep -E 可以使用基本的正则表达外, 还可以用扩展表达式. 注意区别.
扩展表达式:
+ 匹配一个或者多个先前的字符, 至少一个先前字符.
? 匹配0个或者多个先前字符.
a|b|c 匹配a或b或c
() 字符组, 如: love(able|ers) 匹配loveable或lovers.
(..)(..)\\1\\2 模板匹配. \\1代表前面第一个模板, \\2代第二个括弧里面的模板.
x{m,n} =x\\{m,n\\} x的字符数量在m到n个之间.
以上是关于grep的用法(CentOS7)及有关正则表达式的使用的主要内容,如果未能解决你的问题,请参考以下文章