pymongo实战
Posted 临风而眠
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了pymongo实战相关的知识,希望对你有一定的参考价值。
pymongo实战
文章目录
一.基础操作回顾
在前面的MongoDB操作(5)里面已经学习了使用pymongo,现在再来完整的复习一遍
1.创建数据库和集合
MongoDB 中的集合与 SQL 数据库中的表相同
import pymongo
#要创建数据库,首先要创建MongoClient 对象,然后使用正确的 IP 地址和要创建的数据库的名称指定连接 URL。
#如果数据库不存在,MongoDB 将创建数据库并建立连接
myclient = pymongo.MongoClient("mongodb://localhost:27017/")
#创建数据库"mydatabase"
mydb=myclient["mydatabase"]
#创建集合"customers"
mycol=mydb["customers"]
#返回系统中的数据库列表,此时mydatabase还不存在
print(myclient.list_database_names())
#返回数据库中所有集合的列表,此时customers还不存在
print(mydb.list_collection_names())
在 MongoDB 中,数据库在获取内容之前不会创建!在实际创建数据库(和集合)之前,MongoDB 会一直等待创建至少有一个文档(记录)的集合(表)
所以会产生如下的运行结果:
['admin', 'config', 'local', 'test1']
[]
(我原先就只有那四个数据库)

2.插入文档
在 MongoDB 中把记录或我们所称的文档插入集合,要使用insert_one()方法,该方法的第一个参数是字典,其中包含希望插入文档中的每个字段名称和值
插入一个文档
import pymongo
myclient = pymongo.MongoClient("mongodb://localhost:27017/")
#创建数据库"mydatabase"
mydb=myclient["mydatabase"]
#创建集合"customers"
mycol=mydb["customers"]
mydict={"name":"Bob","age":18}
x=mycol.insert_one(mydict)
返回_id字段
insert_one() 方法返回 InsertOneResult 对象,该对象拥有属性 inserted_id,用于保存插入文档的 id
如果
print(x)返回的是:
<pymongo.results.InsertOneResult object at 0x000001BCDE95AEC0>
print(x.inserted_id)

插入多个文档
insert_many() 方法,第一个参数是包含字典的列表,其中包含要插入的数据
方法返回 InsertManyResult 对象,该对象拥有属性
inserted_ids,用于保存被插入文档的 id
import pymongo
myclient = pymongo.MongoClient("mongodb://localhost:27017/")
#创建数据库"mydatabase"
mydb=myclient["mydatabase"]
#创建集合"customers"
mycol=mydb["customers"]
mylist = [
{"name":"Jack","age":28},
{"name":"Kane","age":15},
{"name":"Kitty","age":31},
{"name":"Alice","age":26},
{"name":"Daddy","age":19},
{"name":"Amy","age":20},
{"name":"Richard","age":14},
{"name":"Sandy","age":16},
{"name":"Betty","age":21}
]
y=mycol.insert_many(mylist)
返回_id字段
print(y.inserted_ids)
结果:
[ObjectId('611636718adbf37771fa6714'), ObjectId('611636718adbf37771fa6715'), ObjectId('611636718adbf37771fa6716'), ObjectId('611636718adbf37771fa6717'), ObjectId('611636718adbf37771fa6718'), ObjectId('611636718adbf37771fa6719'), ObjectId('611636718adbf37771fa671a'), ObjectId('611636718adbf37771fa671b'), ObjectId('611636718adbf37771fa671c')]
可以在字典里面指定_id,那样就不会自动分配了
3.查找数据
主要补充MongoDB操作(5)里面的内容
只返回某些字段
find() 方法返回选择中的所有匹配项
第一个参数是 query 对象,用于限定搜索,如:
import pymongo myclient = pymongo.MongoClient("mongodb://localhost:27017/") #创建数据库"mydatabase" mydb=myclient["mydatabase"] #创建集合"customers" mycol=mydb["customers"] myquery={"age":18} mydoc=mycol.find(myquery) for x in mydoc: print(x)
第二个参数是描述包含在结果中字段的对象
第二个参数是可选参数,省略就会返回所有字段

import pymongo
myclient = pymongo.MongoClient("mongodb://localhost:27017/")
#创建数据库"mydatabase"
mydb=myclient["mydatabase"]
#创建集合"customers"
mycol=mydb["customers"]
for x in mycol.find():
print(x)
这样子返回的是所有字段
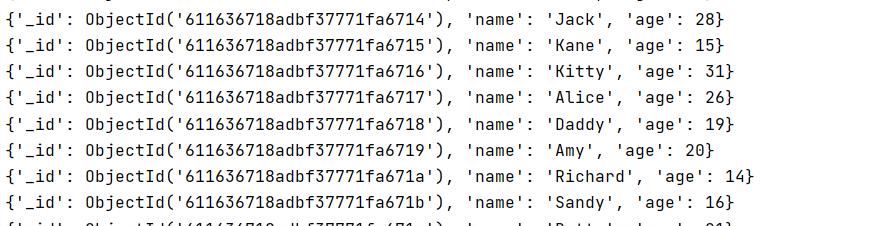
返回年龄和姓名
for x in mycol.find({},{"_id":0,"name":1,"age":1}):
print(x)
或者:
for x in mycol.find({},{"_id":0}):
print(x)
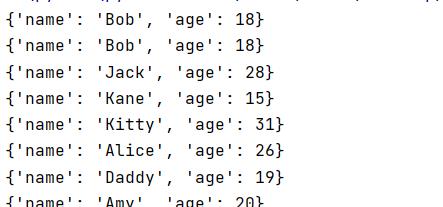
只返回年龄
for x in mycol.find({},{"_id":0,"name":1}):
print(x)
或:
for x in mycol.find({},{"_id":0,"age":0}):
print(x)
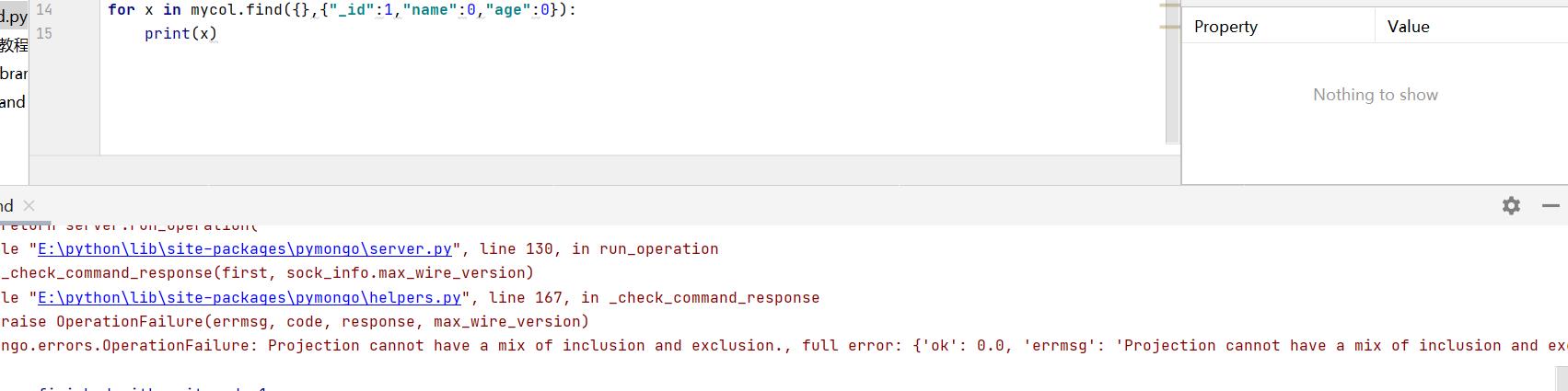
注意下面这样会报错!
for x in mycol.find({},{"_id":0,"name":1,"age":0}):
print(x)

原因:
不允许在同一对象中同时指定 0 和 1 值(除非其中一个字段是 _id 字段)。如果指定值为 0 的字段,则所有其他字段的值为 1,反之亦然
只返回姓名
for x in mycol.find({},{"_id":0,"name":1}):
print(x)
或:
for x in mycol.find({},{"_id":0,"age":0}):
print(x)
只返回_id
for x in mycol.find({},{"_id":1}):
print(x)
或:
for x in mycol.find({},{"name":0,"age":0}):
print(x)
注意下面这个也会报错!
高级查询
如找年龄大于22的:
import pymongo
myclient = pymongo.MongoClient("mongodb://localhost:27017/")
#创建数据库"mydatabase"
mydb=myclient["mydatabase"]
#创建集合"customers"
mycol=mydb["customers"]
myquery={"age":{"$gt":22}}
mydoc=mycol.find(myquery)
for x in mydoc:
print(x)

4.排序
sort(fieldname,direction)
fieldname:字段名称 direction:方向 默认升序1 ,降序为-1
import pymongo
myclient = pymongo.MongoClient("mongodb://localhost:27017/")
#创建数据库"mydatabase"
mydb=myclient["mydatabase"]
#创建集合"customers"
mycol=mydb["customers"]
myquery={"age":{"$gt":22}}
mydoc=mycol.find(myquery).sort("age",-1)
for x in mydoc:
print(x)

5.删除数据
用
["test1"]["test2"]做示范


(插播)突然好奇:
print(mydb) print(mycol)

删除一条
删除_id是13的数据
import pymongo
myclient = pymongo.MongoClient("mongodb://localhost:27017/")
#创建数据库"mydatabase"
mydb=myclient["test1"]
#创建集合"customers"
mycol=mydb["test2"]
myquery={"_id":13}
mydoc=mycol.delete_one(myquery)

删除多个
当然,如果要删除的那个数据只有一条,也可以用delete_many
删除item以字母b开头的
import pymongo
myclient = pymongo.MongoClient("mongodb://localhost:27017/")
#创建数据库"mydatabase"
mydb=myclient["test1"]
#创建集合"customers"
mycol=mydb["test2"]
myquery={"item":{"$regex":"^b"}}
x=mycol.delete_many(myquery)
print(x.deleted_count,"documents deleted.")


删除全部
import pymongo
myclient = pymongo.MongoClient("mongodb://localhost:27017/")
#创建数据库"mydatabase"
mydb=myclient["test1"]
#创建集合"customers"
mycol=mydb["test2"]
x=mycol.delete_many({})
print(x.deleted_count,"documents deleted.")


6.删除集合
.drop()
import pymongo
myclient = pymongo.MongoClient("mongodb://localhost:27017/")
#创建数据库"mydatabase"
mydb=myclient["test1"]
#创建集合"customers"
mycol=mydb["test2"]
mycol.drop()
如果成功删除集合,则 drop() 方法返回 true,如果集合不存在则返回 false,
但是我 res= mycol.drop() ; print(res),打印出来一直是None
EMM…
7.更新
用这个做示范

更新一条
.update_one(myquery, newvalues)
第一个参数是 query 对象,用于定义要更新的文档,第二个参数是定义文档新值的对象
如果查询找到多个记录,则仅更新第一个匹配项
把userid a换成A:
import pymongo
myclient = pymongo.MongoClient("mongodb://localhost:27017/")
#创建数据库"mydatabase"
mydb=myclient["test1"]
#创建集合"customers"
mycol=mydb["dist"]
myquery={"userid":"a"}
newvalues={"$set":{"userid":"A"}}
mycol.update_one(myquery,newvalues)
for x in mycol.find():
print(x)

更新多条
.update_many(myquery, newvalues)
更新国家以字母c开头的所有文档
import pymongo
myclient = pymongo.MongoClient("mongodb://localhost:27017/")
#创建数据库"mydatabase"
mydb=myclient["test1"]
#创建集合"customers"
mycol=mydb["dist"]
myquery={"country":{"$regex":"^c"}}
newvalues={"$set":{"country":"CN"}}
mycol.update_many(myquery,newvalues)
for x in mycol.find():
print(x)

二.实战:爬取蔬菜网价格信息
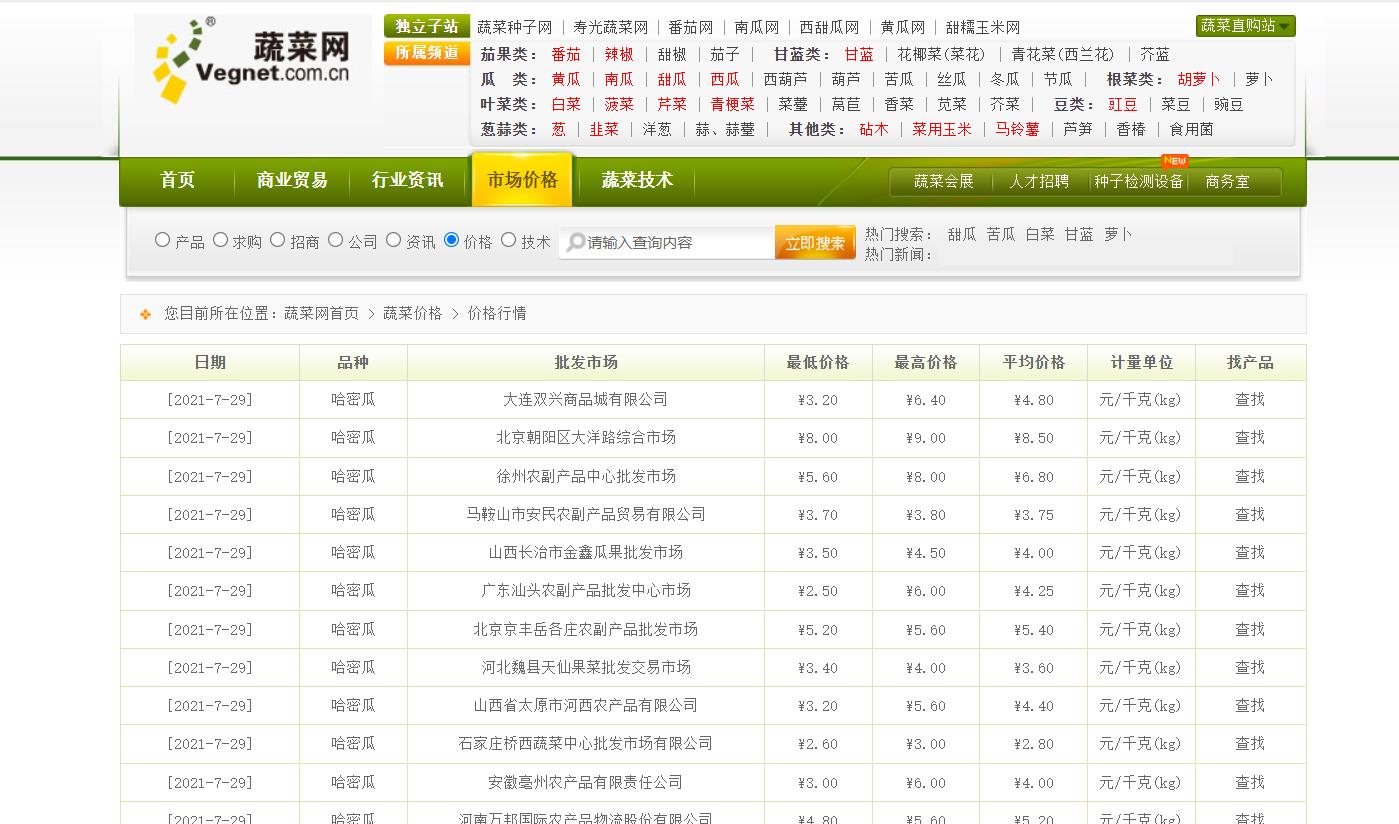
1.需求分析
需要爬取的内容有:日期、品种、批发市场…
打算用Xpath实现,先爬取先3页试试

经过观察,翻页就是p后面的数字变一下
#http://www.vegnet.com.cn/Price/List_p1.html
#页面的循环处理
#for i in range(1,4):
#f'http://www.vegnet.com.cn/Price/List_p{i}.html'
2.检验状态码
import pymongo
import requests
from lxml import etree
url="http://www.vegnet.com.cn/Price/List_p1.html"
headers={"User-Agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.164 Safari/537.36"}
resp = requests.get(url,headers=headers)
resp.encoding=resp.apparent_encoding
print(resp.status_code)
resp.close()
状态码为200,可以继续操作
3.定位
所要的数据都在这里面:
先复制一下那个<div class="pri_k">的Xpath
/html/body/div[4]/div[2]/div/div[1]
再复制看一下第一、二行数据的xml
/html/body/div[4]/div[2]/div/div[1]/p[1]
/html/body/div[4]/div[2]/div/div[1]/p[2]
那么,把索引去掉,就得到了xpath列表
/html/body/div[4]/div[2]/div/div[1]/p
这个Xpath有问题! 后文 遇到的问题 那里会讲
先不管这个xpath,往下看能用的xpath
4.先用第一页检验xpath
import requests
from lxml import etree
#用第一页检验一下xpath是否正确
url="http://www.vegnet.com.cn/Price/List_p1.html"
headers={"User-Agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.164 Safari/537.36"}
resp=requests.get(url,headers=headers)
resp.encoding=resp.apparent_encoding
#生成etree对象
pageText = etree.HTML(resp.text)
#每轮获取一行数据
rows = pageText.xpath('/html//div[@class="pri_k"]/p')
#后面的都用相对路径
for row in rows:
#日期
date=row.xpath('./span[1]/text()')
#品种
variety=row.xpath('./span[2]/text()')
#批发市场
market=row.xpath('./span[3]/a/text()')
#最低价格
min_price=row.xpath('./span[4]/text()')
#最高价格
max_price=row.xpath('./span[5]/text()')
#平均价格
mean_price=row.xpath('./span[6]/text()')
#计量单位
measure_unit=row.xpath('./span[7]/text()')
print(date,variety,market,min_price,max_price,mean_price,measure_unit)
resp.close()
成功爬取并打印:

输出优化
其中关于时间那个要去掉中括号:
用.replace('[','').replace(']','')


要注意要先左括号再右括号,先不仔细研究了,直接用,之后再看replace()方法的细节
#日期
date=row.xpath('./span[1]/text()')[0].replace('[','').replace(']','')
#品种
variety=row.xpath('./span[2]/text()')[0]
#批发市场
market=row.xpath('./span[3]/a/text()')[0]
#最低价格
min_price=row.xpath('./span[4]/text()')[0]
#最高价格
max_price=row.xpath('./span[5]/text()')[0]
#平均价格
mean_price=row.xpath('./span[6]/text()')[0]
#计量单位
measure_unit=row.xpath('./span[7]/text()')[0]
输出结果:

5.总代码(加上数据库操作)
import pymongo
import requests
from lxml import etree
import pandas as pd
myClient = pymongo.MongoClient("localhost")
myDb = myClient["vegetable"]
myCol =myDb["price"]
headers={"User-Agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.164 Safari/537.36"}
#每轮获取一页数据
for i in range(1,4):
resp = requests.get(f'http://www.vegnet.com.cn/Price/List_p{i}.html',headers=headers)
resp.encoding=resp.apparent_encoding
# 生成etree对象
pageText = etree.HTML(resp.text)
# xpath列表
rows = pageText.xpath('/html//div[@class="pri_k"]/p')
#每轮获取一行数据
for row in rows:
# 日期
date = row.xpath('./span[1]/text()')[0].replace('[', '').replace(']', '')
# 品种
variety = row.xpath('./span[2]/text()')[0]
# 批发市场
market = row.xpath('./span[3]/a/text()')[0]
# 最低价格
min_price = row.xpath('./span[4]/text()')[0]