python异步爬虫:引入+线程池实战
Posted 临风而眠
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python异步爬虫:引入+线程池实战相关的知识,希望对你有一定的参考价值。
python异步爬虫(1):引入+线程池实战
使用异步爬虫可以实现高性能高效率的数据爬取操作
文章目录
一.引入
先运行下面这个程序:
import requests
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/91.0.4472.164 Safari/537.36"
}
urls = ['https://www.sogou.com/',
'https://cn.bing.com/?mkt=zh-CN&mkt=zh-CN',
'https://www.baidu.com/']
def get_content(url):
print("正在爬取",url)
resp=requests.get(url=url,headers=headers)
if resp.status_code == 200:
return resp.content
def parse_content(content):
print("响应数据的长度为",len(content))
for url in urls:
content =get_content(url)
parse_content(content)
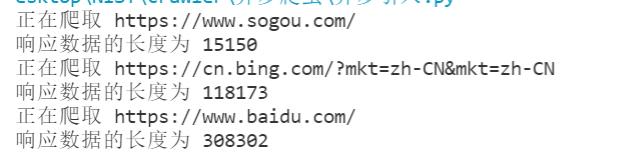
输出结果的时候,明显可以观察到爬取过程是一个阻塞操作,是耗时过程
也可以加入时间来观察:
for url in urls:
time_start=time.time()
content=get_content(url)
parse_content(content)
time_end=time.time()
time_c=time_end-time_start
print("time_cost",time_c,'s')

这是一个单线程环境,如果要爬取100个,10000个,那么…显然效率很低
那么效率高的异步爬虫有哪些 方式呢:
- 多线程、多进程
- 好处:可以为相关阻塞的操作单独开启线程或进程,阻塞操作可以异步执行
- 弊端:无法无限制开启多线程或者多进程(CPU有限制)
- 线程池、进程池
- 好处:可以降低系统对进程或线程创建和销毁的频率,从而降低系统开销
- 弊端:池中线程或进程的数量有上限
二.线程池实战
线程池的解释
★这个视频里的动画解释很生动:B站 楠哥讲解视频
插播:python response.text和response.content的区别
昨天pymongo实战那篇文章里面搜到的Xpath返回为空的那篇文章里面也提到了这个,并且更加推荐resp.content
还可以看看这个:python中的requests,response.text与response.content ,及其编码

1.简单模拟一下
单线程:
import time
def get_page(str):
print("正在爬取:",str)
time.sleep(2)
print('下载成功:',str)
name_list=['a','b','c','d']
start_time=time.time()
for i in range(len(name_list)):
get_page(name_list[i])
end_time=time.time()
print('%d second'%(end_time-start_time))

换成线程池来处理:
import time
from multiprocessing.dummy import Pool
# Pool是线程池对应的类
start_time = time.time()
def get_page(str):
print("正在爬取:", str)
time.sleep(2)
print('下载成功:', str)
name_list = ['a', 'b', 'c', 'd']
# 先实例化一个线程池对象
pool = Pool(4) # 四个线程
# 第一个参数为函数,放入会发生阻塞的操作
# 将列表中每一个列表元素传递给get_page处理
# 第二个参数是可迭代对象
# 四个线程池对象分别进行阻塞操作,map的返回值,就是get_page的返回值
# get_page的返回值会依次赋值给map的返回值,所以map的返回值是一个列表
pool.map(get_page, name_list)
end_time = time.time()
print('%d second' % (end_time-start_time))

改成%f输出的是2.029824 second
关于python的map()函数
2.实战:线程池爬取蔬菜网市场价格前200页
在pymongo实战(2)那篇博客的基础上稍作修改,加上线程池
代码
# https://www.nonghecj.com/p01
import pymongo
import requests
from lxml import etree
#引入线程池
from concurrent.futures import ThreadPoolExecutor
myClient = pymongo.MongoClient("localhost")
#新建一个叫vegetable2的数据库
myDb = myClient["vegetable2"]
myCol =myDb["price"]
headers={"User-Agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.164 Safari/537.36"}
#下载一页
def download_onepage(url,num_1):
resp = requests.get(url,headers=headers)
resp.encoding=resp.apparent_encoding
# 生成etree对象
pageText = etree.HTML(resp.text)
# xpath列表
rows = pageText.xpath('/html//div[@class="pri_k"]/p')
#每轮获取一行数据
num_2=0
for row in rows:
# 日期
date = row.xpath('./span[1]/text()')[0].replace('[', '').replace(']', '')
# 品种
variety = row.xpath('./span[2]/text()')[0]
# 批发市场
market = row.xpath('./span[3]/a/text()')[0]
# 最低价格
min_price = row.xpath('./span[4]/text()')[0]
# 最高价格
max_price = row.xpath('./span[5]/text()')[0]
# 平均价格
mean_price = row.xpath('./span[6]/text()')[0]
# 计量单位
measure_unit = row.xpath('./span[7]/text()')[0]
kv_dict={"date":date,"variety":variety,"market":market,
"min_price":min_price,"max_price":max_price,
"mean_price":mean_price,"measure_unit":measure_unit}
# myCol.insert_one(kv_dict)
myCol.update_one({"index":f"{num_1}{num_2}"},{"$set":kv_dict},upsert=True)
num_2+=1
print(f"{url}抓取完毕")
resp.close()
if __name__=="__main__":
# # 每轮获取一页数据
# for i in range(1, 4):
#准备50个线程池,提取前200页
with ThreadPoolExecutor(50) as t:
for i in range(1,201):
t.submit(download_onepage,f'http://www.vegnet.com.cn/Price/List_p{i}.html',i)
print("done!")

遇到的问题
if __name__ == '__main__':
一开始一直不运行,结果发现'__main__'前后两个下划线漏了…
数据条数
每一页是26行数据,但是运行了好几次都是4715条数据,按理说前200页应该是5200条,目前还不知道原因…

好像被封IP了…
不过好像,过一会儿又解封了…
又能继续爬取
线程池爬取不能保证数据的有序性
一方面查看的时候可以用sort解决,但是线程池会把页数打乱…
目前还没有进一步想法
以上是关于python异步爬虫:引入+线程池实战的主要内容,如果未能解决你的问题,请参考以下文章