爬虫学习笔记(二十)—— 字体反爬
Posted 别呀
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫学习笔记(二十)—— 字体反爬相关的知识,希望对你有一定的参考价值。
一、什么是字体反爬
网页开发者自己创造一种字体,因为在字体中每个文字都有其代号,那么以后在网页中不会直接显示这个文字的最终的效果,而是显示他的代号,因此即使获取到了网页中的文本内容,也只是获取到文字的代号,而不是文字本身。
简单的说,字体反爬指的就是浏览器页面上的字符和调试窗口或者源码中的内容,显示的不一样,这就是字体反爬。

二、编码原理
bit(比特):是由0或1构成的二进制位
Byte(字节):1个字节由八个连续的二进制位,或二个16进制数表示
字符:是指计算机中使用的字母、数字、字和符号
2.1、ASCII编码对照表
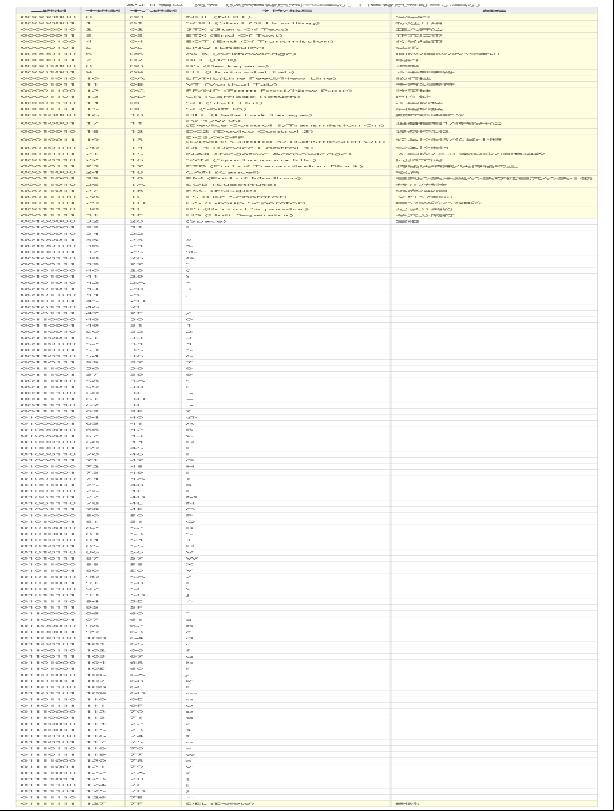
ASCII码
ASCII 码使用指定的7位或8位二进制数组合来表示128或256种可能的字符。标准ASCII码也叫基础ASCII码,使用7位二进制数(剩下的1位二进制为0)来表示所有的大写和小写字母,数字0 到9、标点符号,以及在美式英语中使用的特殊控制字符。
2.2、Unicode编号
Unicode码
Unicode为世界上所有字符都分配了一个唯一的数字编号,这个编号范围从 0x000000 到 0x10FFFF(十六进制),有110多万,每个字符都有一个唯一的Unicode编号,这个编号一般写成16进制,在前面加上U+。例如:”爬“的Unicode是U+722C。它是一种规定,Unicode本身只规定了每个字符的数字编号是多少,并没有规定这个编号如何存储。
理论上可以直接把Unicode编号直接转换成二进制进行存储,而Unicode并不是这么操作,因为除了这种直接转换成二进制的方案外,还有其他方案,主要有UTF-8,UTF-16,UTF-32,gbk。(UTF-8、UTF-16、UTF-32……都是 Unicode编码 的一种实现。)
2.3、UTF-8编码方式

UTF-8 最大的一个特点,就是它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。
UTF-8 的编码规则很简单,只有两条:
-
对于单字节的符号,字节的第一位设为
0,后面7位为这个符号的 Unicode 码。因此对于英语字母,UTF-8 编码和 ASCII 码是相同的。 -
对于
n字节的符号(n > 1),第一个字节的前n位都设为1,第n + 1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的 Unicode 码。
汉字的UTF-8编码(n字节)表示
- 获取汉字unicode编号
- 转化为二进制数
- 根据UTF-8编码格式,将二进制数据填充到指定位置
- 将填充好的新二进制数据,转换成16进制
例:
1、获取汉字unicode编号
ord('爬') =》29228
hex(29228) =》'0x722c'
2、转化为二进制数
bin(29228) =》'0b111001000101100'
3、根据UTF-8编码格式,将二进制数据填充到指定位置
(29228>2048所以选3的: 1110xxxx 10xxxxxx 10xxxxxx)
11100111 10001000 10101100
4、将填充好的新二进制数据,转换成16进制
hex(int('11100111',2)) =》'0xe7'
hex(int('10001000',2)) =》'0x88'
hex(int('10101100',2)) =》'0xac'
"爬".encode('utf-8') =》b'\\xe7\\x88\\xac' #字节编码
编号与编码

一个字的Unicode编号是固定的,但是在计算机上的字节码,取决于编码方案的实现方式。一个汉字在Unicode中的编号的16进制数,跟utf8编码后的16进制数不是一回事。
2.4、字符矢量图
字体可以理解为通过unicode编号,对应的自定义图形。

字符对应关系
传递字符 5 ,有两种方案,
第一种是传递字符4的字节码:浏览器拿到字节码,转换成unicode编号,在没有指定字体文件的前提下,通过unicode编号在到系统自带字体中寻找字符矢量图,得到 ‘5’
第二种是,传递另一个繁体字的字节码,同时,传递一个自定义的字体。浏览器拿到繁体字的字节码,转换成unicode编码,到css指定的字体文件中查找,找到字符矢量图 ‘5’。
第二种情况下,浏览器后台和爬虫拿到的繁体字的字节码,只能在正常字体中查找字符矢量图,所以只能看到 一个其他字体(如:鱀)
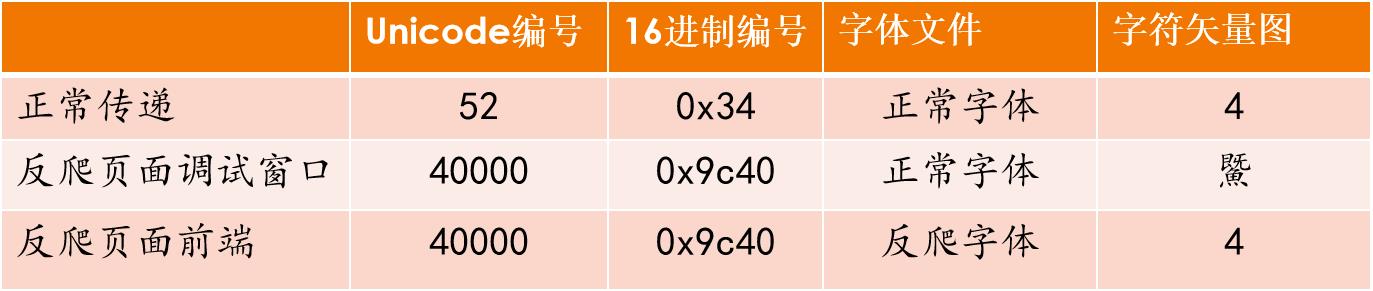
正常对应关系:unicode编号 -->正常字符集 -->正常字符
使用自定义矢量图:①unicode编号 -->正常字符集 -->难懂的字
②nunicode编号 -->自定义字符集 -->正常字符
工具:
-
FontCreator 下载exe文件,安装(下载链接:https://pan.baidu.com/s/15Bd9786YB_KcySPh2s4bXQ ,提取码:cgnb)
-
fontTools包:
pip install fontTools
字体文件存储的是unicode编号和字符矢量图的对应关系
三、案例:58同城反爬字体
首先我们先观察字体的位置:
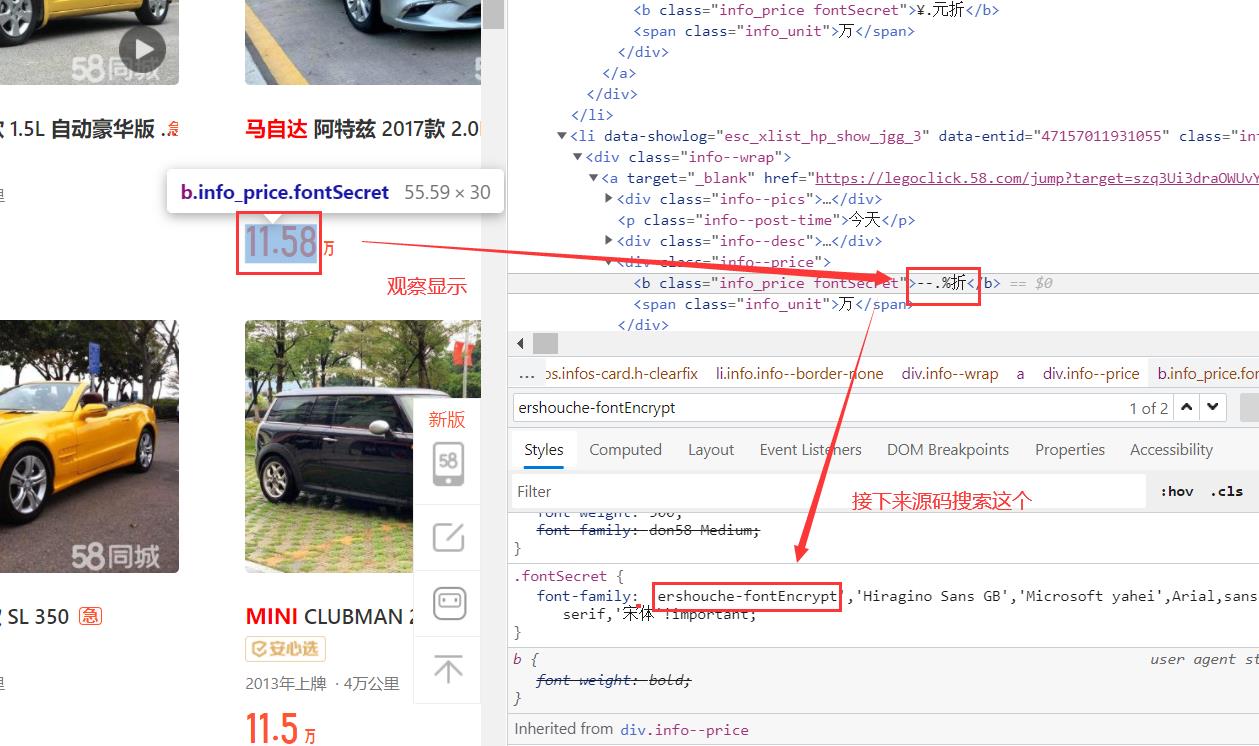
接下来就是查找自定义字符文件
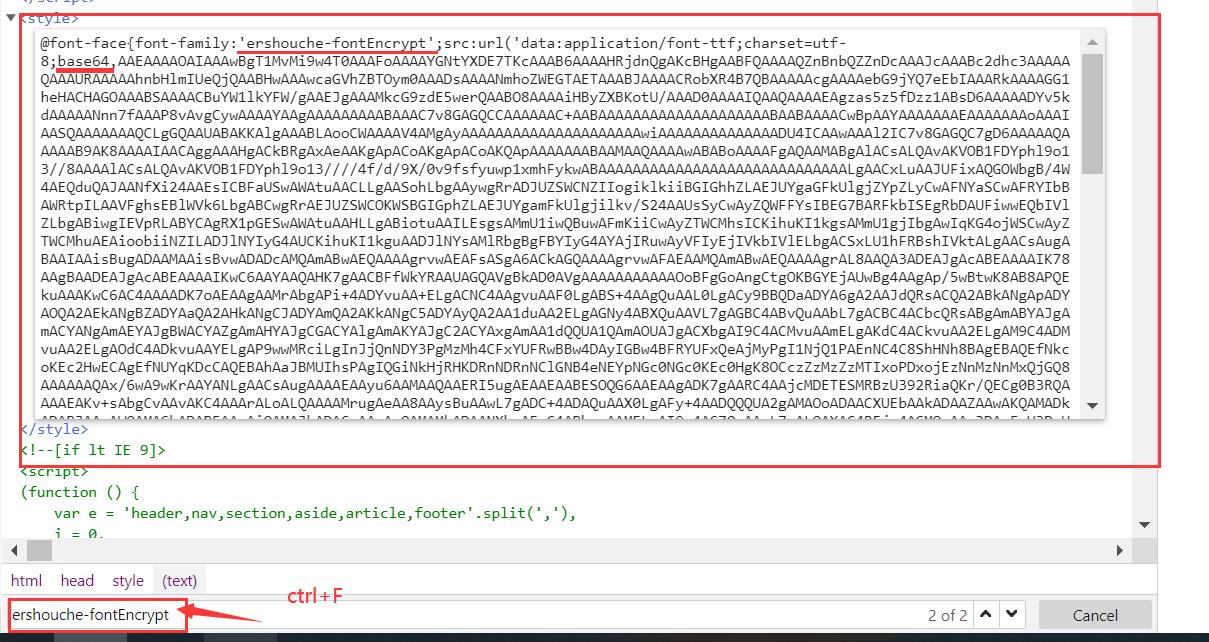
或者也可以在‘network’处找到

然后我们就可以找出它们的对应关系了
base64_content = re.findall("charset=utf-8;base64,(.*?)'",res.text)
byte_content = base64.b64decode(base64_content)
with open('58car.ttf','wb') as f:
f.write(byte_content)
font = TTFont('58car.ttf')
font.saveXML('58car.xml')
print(font.getBestCmap())
print(font.getGlyphID())
{37: 'uni0025', 43: 'uni002B', 45: 'uni002D', 47: 'uni002F', 165: 'uni00A5', 19975: 'uni4E07', 20803: 'uni5143', 25240: 'uni6298', 26102: 'uni65F6', 36215: 'uni8D77'}
{'.notdef': 0, 'uni5143': 1, 'uni002B': 2, 'uni65F6': 3, 'uni8D77': 4, 'uni002F': 5, 'uni00A5': 6, 'uni6298': 7, 'uni4E07': 8, 'uni0025': 9, 'uni002D': 10}
3.1、代码实现
import base64
import requests
import re
from lxml import etree
from fontTools.ttLib import TTFont
url = 'https://xm.58.com/ershouche/?PGTID=0d100000-0025-e7c0-f349-f6fb99ec299a&ClickID=2'
#58反爬比较强,所以我们头全写
headers = {
'authority': 'xm.58.com',
'method': 'GET',
'path': '/ershouche/?PGTID=0d100000-0025-e7c0-f349-f6fb99ec299a&ClickID=2',
'scheme': 'https',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'cache-control': 'no-cache',
'cookie': 'f=n; userid360_xml=DF790A407DD312F8230CF109530AC2BD; time_create=1631538931202; commontopbar_ipcity=zhangpu%7C%E6%BC%B3%E6%B5%A6%7C0; myLat=""; myLon=""; id58=r5k1JWEXmnttPtncoqH9+g==; mcity=zhangpu; 58tj_uuid=c72abed3-2489-4e7c-a321-691932bae8d3; wmda_uuid=d82a91d7f9f65ac837bb5b625c7b1068; wmda_new_uuid=1; als=0; xxzl_deviceid=0yvDkPJsU54k1%2BmeRC6Jp43aVt%2Bi7XJ7nI3mjoAoEaBaTbTRjvzYN%2FRqpRUawEXq; sessionid=36b1e461-0f5c-4f3b-ba5b-4eb4c7abd190; fzq_h=9db1bd518df2c5ff11e98c3775bb3bab_1628936871311_d7d3355fc4ca42a7bdb1d0a21f39d5c4_2363523693; f=n; city=xm; 58home=xm; wmda_visited_projects=%3B11187958619315%3B1731916484865%3B1732038237441%3B2385390625025; 58_ctid=606; is_58_pc=1; commontopbar_new_city_info=46%7C%E5%8E%A6%E9%97%A8%7Cxm; ctid=46; aQQ_ajkguid=7A6CE0F2-01D0-978C-9DB3-SX0814211431; sessid=7D16F3E3-652C-5EFB-AD5C-SX0814211431; __xsptplus8=8.1.1628946873.1628946873.1%234%7C%7C%7C%7C%7C%23%23t6AyIlY5mNYqNbQWgTNdey7ludWc_Aq_%23; xxzl_cid=c2bd9243c2614a22a6e811404337c8b6; xzuid=261dd2fa-dd63-49e9-b293-84c4afe5498b; wmda_session_id_1732038237441=1628961854128-e660d3fe-4be8-496b; new_uv=3; utm_source=; spm=; init_refer=https%253A%252F%252Fxm.58.com%252F%253Ffrom%253Dpc_topbar_home%2526PGTID%253D0d3090a7-0025-e161-980b-bb07e2053409%2526ClickID%253D3; new_session=0; fzq_js_usdt_infolist_car=4078e6bf9869aa309438c21d8a1fca5d_1628962005226_2',
'pragma': 'no-cache',
'referer': 'https://xm.58.com/?from=pc_topbar_home&PGTID=0d3090a7-0025-e161-980b-bb07e2053409&ClickID=3',
'sec-ch-ua': '"Chromium";v="92", " Not A;Brand";v="99", "Microsoft Edge";v="92"',
'sec-ch-ua-mobile': '?0',
'sec-fetch-dest': 'document',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'same-origin',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36 Edg/92.0.902.67'
}
res = requests.get(url=url,headers=headers)
print(res.text)
base64_content = re.findall("charset=utf-8;base64,(.*?)'",res.text)[0]
byte_content = base64.b64decode(base64_content)
with open('58car.ttf','wb') as f:
f.write(byte_content)
font = TTFont('58car.ttf')
font.saveXML('58car.xml')
#打印字符对应关系
print(font.getBestCmap())
print(font.getReverseGlyphMap())
#通过自定义字符文件,获取对应字体
def get_car_price(string, font):
unicode_glyph = font.getBestCmap()
glyph_price = font.getReverseGlyphMap()
new_str = ''
for char in string:
char_unicode = ord(char)
if char_unicode in unicode_glyph:
glyph_code = unicode_glyph[char_unicode]
price = glyph_price[glyph_code]
new_str += str(price)
return new_str
html = etree.HTML(res.text)
car_list = html.xpath('//li[@class="info"]')
for car in car_list:
#获取汽车名(无字体反爬)
car_name = car.xpath('./div/a/div/h2/span/text()')[0].strip()
#获取汽车价格(有字体反爬)
car_price = car.xpath('./div/a/div/b/text()')[0].strip()
car_price = get_car_price(car_price,font)
print('汽车:%s, 价格:%s'%(car_name,car_price))
结果演示:

以上是关于爬虫学习笔记(二十)—— 字体反爬的主要内容,如果未能解决你的问题,请参考以下文章