《Learning Stereo from Single Images》论文笔记
Posted m_buddy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《Learning Stereo from Single Images》论文笔记相关的知识,希望对你有一定的参考价值。
参考代码:stereo-from-mono
1. 概述
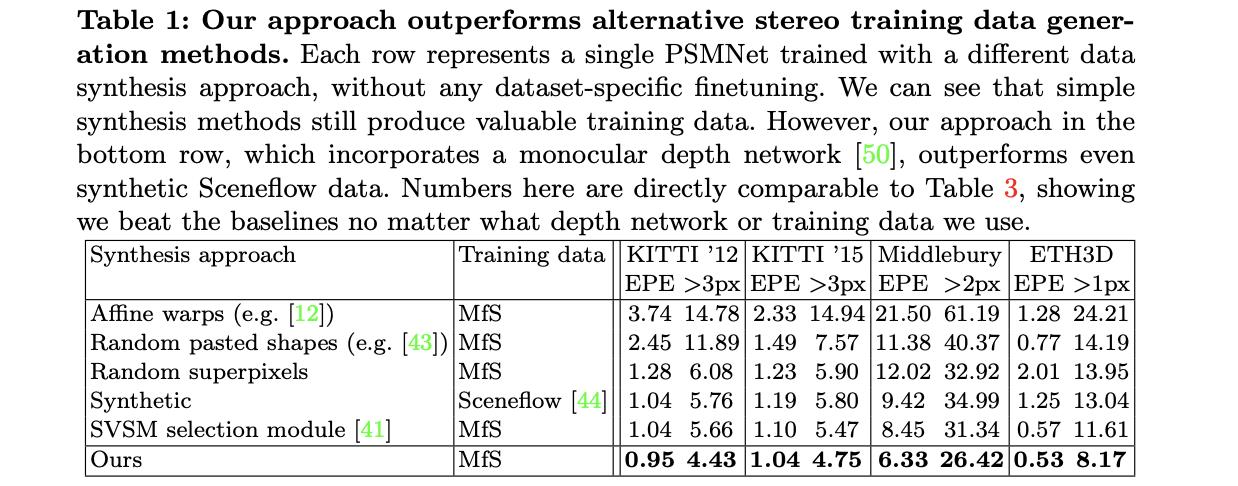
导读:在进行立体匹配的过程中成对且带标签的训练数据是很难去获取的,对此现有的很多方法都是在虚拟的合成数据(如SceneFlow、FlayingThings3D等数据集)上训练完成的,自然其在实际多样化的场景中泛化迁移能力是很弱的。对此文章通过使用MiDas对任意的输入图像进行深度估计,并将深度图转换到视差图,之后按照视差图对源图像进行变换得到另外一个视图,其中会对生成的另外一个视图进行修复和补偿优化从而构建一个双目立体图像对。自此,双目立体图像对构造完成,接下来便是使用一个双目立体匹配网络在这些数据上进行训练。正是由于训练数据的多样化文章提出的算法相比合成数据上训练得到的匹配网络更加鲁棒。
文章的算法在做立体匹配的时候并没有采用合成数据,而是在多样化真实数据基础上通过策略得到合成的图像对,从而极大增加了网络的泛化能力,下面图中展示的就是两种训练策略的对比:

文章中使用到的风格多样化数据集称之为MfS(Mono for Stereo’ dataset),其中包含的数据集有:COCO 2017 ,Mapillary Vistas,ADE20K ,Depth in the Wild,DIODE 。经过整理之后其中包含的数据总量为:597727。
2. 方法设计
2.1 算法pipline
文章算法的整体pipeline见下图所示:
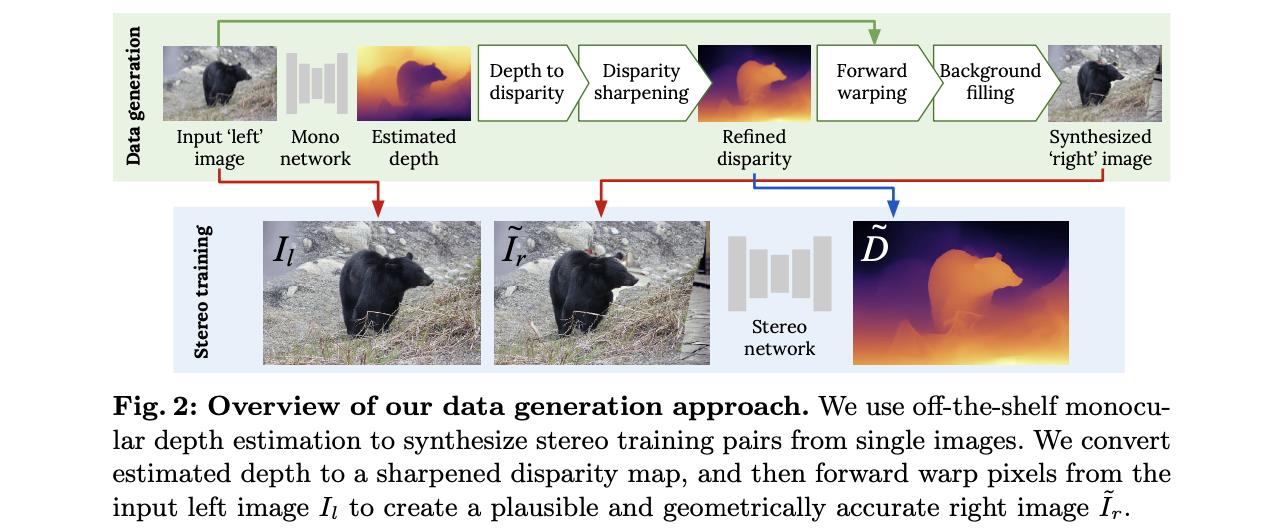
从上图可以看出对于一张输入的图像会先使用MiDas进行深度估计得到该张图的深度估计结果:
Z
=
g
(
I
)
Z=g(I)
Z=g(I)
之后结合双目视觉系统中的基线和焦距属性从深度中反推出视差,也就是下面的过程:
D
ˉ
=
s
Z
m
a
x
Z
\\bar{D}=\\frac{sZ_{max}}{Z}
Dˉ=ZsZmax
其中,参数
s
∈
[
d
m
i
n
,
d
m
a
x
]
s\\in [d_{min},d_{max}]
s∈[dmin,dmax]是为了模拟多样化的基线和焦距值,实现数据增广和增强泛化能力的。得到视差图之后就需要按照视差图
D
ˉ
\\bar{D}
Dˉ的指引将源图像
I
I
I进行forwar warping得到变换后的另外一个视角的图像
I
ˉ
\\bar{I}
Iˉ。
从上面的过程中便得到了用于训练双目立体匹配网络(文中采用的是PSMNet)的数据对 ( I l , I r ˉ , D ˉ ) (I_l,\\bar{I_r},\\bar{D}) (Il,Irˉ,Dˉ),从而实现双目立体匹配过程的训练。
2.2 数据生成优化策略
2.2.1 depth sharpening
文章使用的是一个单目深度估计网络进行深度预标注,自然其中的几何约束性比较弱,因而按照深度估计结果对原图向进行warp之后存在一些孤立的像素点(flying points),也就是下图中中间部分的效果:

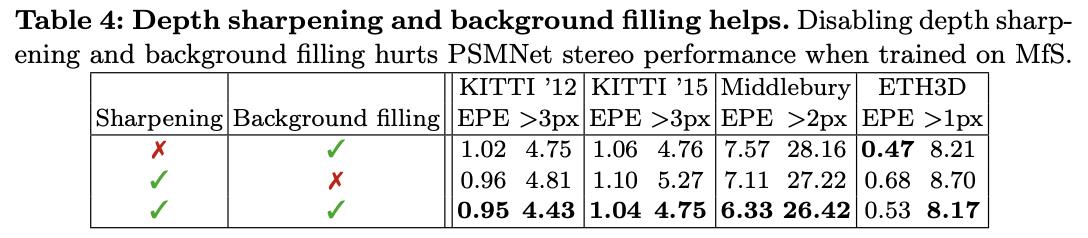
对此,文章为了解决该问题首先通过Sobel梯度算子去检测那些梯度响应大于3的区域(也就是文章说的flying points),之后将这些点的深度之设置为最近非flying points区域的值。从而实现depth sharpening,在图3中也比较了有无该策略对于做后效果的影响。这部分实现的代码可以参考:
# datasets/warp_dataset.py#L112
if not self.disable_sharpening:
# now find disparity gradients and set to nearest - stop flying pixels
edges = sobel(disparity) > 3 # 选择梯度大的区域,大概率为flying points
disparity[edges] = 0 # 将其设置为0
mask = disparity > 0 # 取出需要插值的位置
try: # 对视差图不为0的区域进行插值,重点关注的就是flying points
disparity = griddata(np.stack([self.ys[mask].ravel(), self.xs[mask].ravel()], 1),
disparity[mask].ravel(), np.stack([self.ys.ravel(),
self.xs.ravel()], 1),
method='nearest').reshape(self.feed_height, self.process_width)
except (ValueError, IndexError) as e:
pass # just return disparity
2.2.2 occlusion和collision区域处理
- 1)occlusion处理:这些artifacts代表的是存在于一张双目图像中,但是在另外一张双目图像中却不可见的像素。那么在由 I l I_l Il变换到 I r ˉ \\bar{I_r} Irˉ的过程中就会存在孔洞的区域。对此文章是通过在数据集中随机选择 I b I_b Ib,并将其通过color transform(由 I b I_b Ib到 I l I_l Il进行变换),之后对于孔洞区域按照对应位置抠取填充;
- 2)collision处理:这类artifacts代表的是在 I l I_l Il中存在,但却在 I r ˉ \\bar{I_r} Irˉ中不存在的像素。对于这类问题文章是选择 I l I_l Il对应区域中视差最大的像素,因为这是离collision像素最近的像素了;
对于这一部分的代码可以参考下面的实现过程:
# datasets/warp_dataset.py#L227
def project_image(self, image, disp_map, background_image):
image = np.array(image)
background_image = np.array(background_image)
# set up for projection
warped_image = np.zeros_like(image).astype(float)
warped_image = np.stack([warped_image] * 2, 0)
pix_locations = self.xs - disp_map # 根据视差计算新的坐标
# find where occlusions are, and remove from disparity map
mask = self.get_occlusion_mask(pix_locations) # 根据可见性准则获取occlusion mask(对应部分为0)
masked_pix_locations = pix_locations * mask - self.process_width * (1 - mask)
# do projection - linear interpolate up to 1 pixel away
weights = np.ones((2, self.feed_height, self.process_width)) * 10000
for col in range(self.process_width - 1, -1, -1): # 按照有效像素进行插值得到右视图
loc = masked_pix_locations[:, col]
loc_up = np.ceil(loc).astype(int)
loc_down = np.floor(loc).astype(int)
weight_up = loc_up - loc
weight_down = 1 - weight_up
mask = loc_up >= 0
mask[mask] = \\
weights[0, np.arange(self.feed_height)[mask], loc_up[mask]] > weight_up[mask]
weights[0, np.arange(self.feed_height)[mask], loc_up[mask]] = \\
weight_up[mask]
warped_image[0, np.arange(self.feed_height)[mask], loc_up[mask]] = \\
image[:, col][mask] / 255.
mask = loc_down >= 0
mask[mask] = \\
weights[1, np.arange(self.feed_height)[mask], loc_down[mask]] > weight_down[mask]
weights[1, np.arange(self.feed_height)[mask], loc_down[mask]] = weight_down[mask]
warped_image[1, np.arange(self.feed_height)[mask], loc_down[mask]] = \\
image[:, col][mask] / 255.
weights /= weights.sum(0, keepdims=True) + 1e-7 # normalise
weights = np.expand_dims(weights, -1)
warped_image = warped_image[0] * weights[1] + warped_image[1] * weights[0] # 按照插值权重进行融合
warped_image *= 255.
# now fill occluded regions with random background
if not self.disable_background: # occlusion部分补充
warped_image[warped_image.max(-1) == 0] = background_image[warped_image.max(-1) == 0]
warped_image = warped_image.astype(np.uint8)
return warped_image
3. 实验结果
文章提出的两种数据优化策略,其有效性对比见下表所示:
立体匹配数据生成方法在最后性能上的比较:
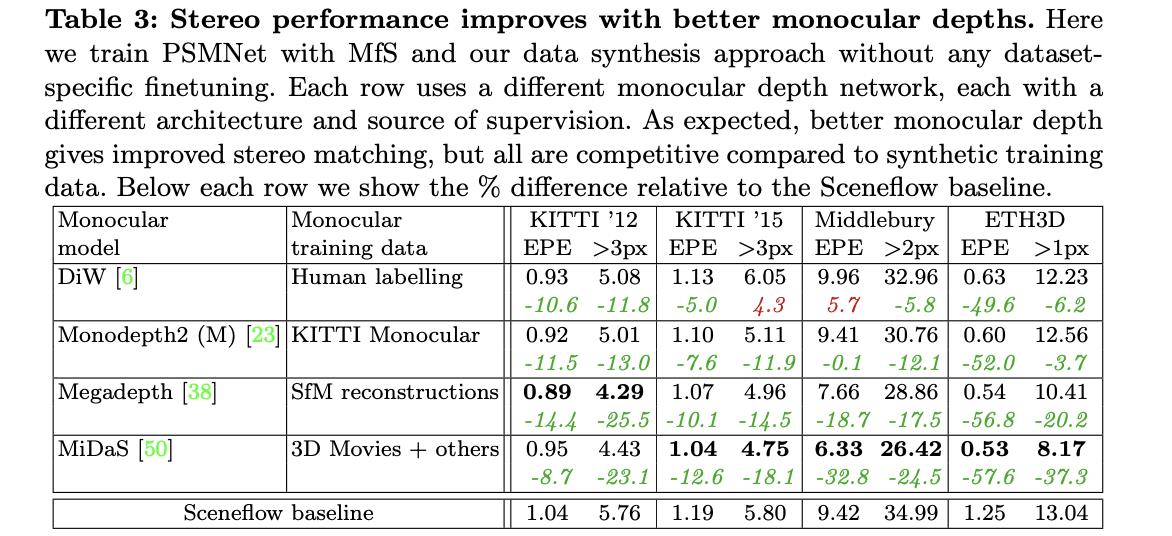
文章方法生成的数据使用基准方法进行训练与基准的对比:
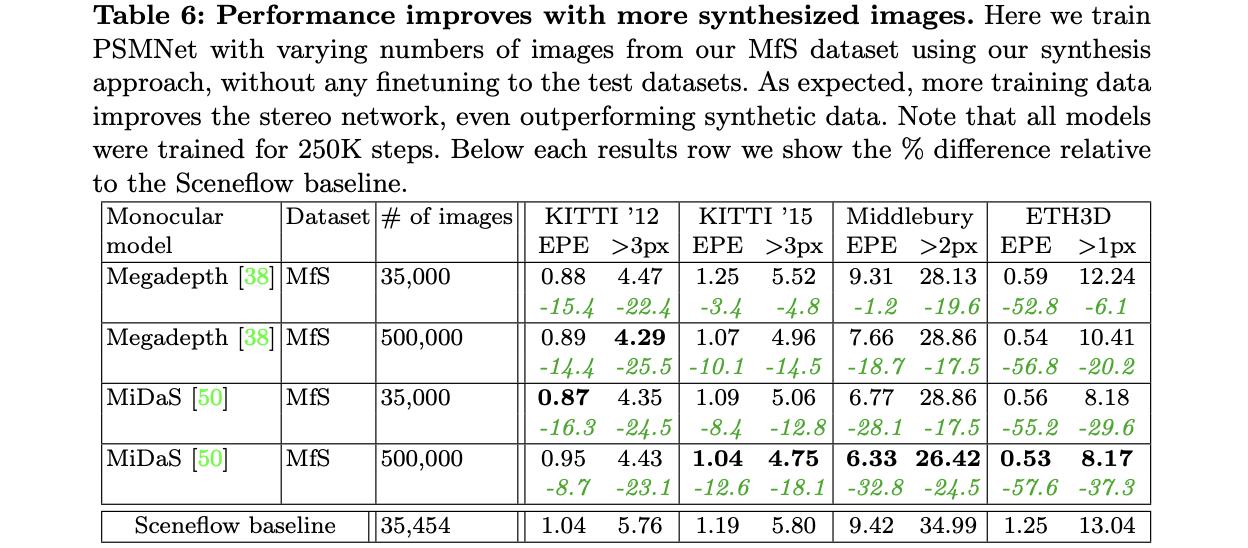
文章的方法与基准的对比:
以上是关于《Learning Stereo from Single Images》论文笔记的主要内容,如果未能解决你的问题,请参考以下文章