自用F1值
Posted 王六六的IT日常
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了自用F1值相关的知识,希望对你有一定的参考价值。
| 二分类使用Accuracy和F1-score,多分类使用Accuracy和宏F1(Macro-F1)。 |
使用 sklearn 做分类时候,用到metrics中的评价函数,其中有一个非常重要的评价函数是 F 1 F1 F1值。在sklearn中计算 F 1 F1 F1值的函数为 F 1 − s c o r e F1-score F1−score ,其中有一个 参数 a v e r a g e average average 用来控制 F 1 F1 F1 的计算方式,现在分析当参数取micro和macro时候的区别。
F1-score:是统计学中用来衡量二分类模型精确度的一种指标,用于测量不均衡数据的精度。它同时兼顾了分类模型的精确率和召回率。 F1-score 可以看作是模型精确率和召回率的一种加权平均,它的最大值是1,最小值是0。
在多分类问题中,如果要计算模型的 F1-score,则有两种计算方式,分别为 Micro-F1和 Macro-F1,这两种计算方式在二分类中与 F1-score 的计算方式一样,所以在二分类问题中,计算 micro-F1=macro-F1=F1-score, Micro-F1和 Macro-F1都是多分类 F1-score的两种计算方式;
1、准确率,查准率,查全率,F1值
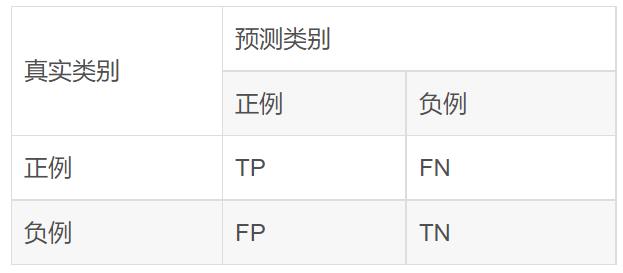
对于二分类问题,可将样例根据其真实类别和分类器预测类别划分为:
-
真正例(True Positive,TP):真实类别为正例,预测类别为正例。
-
假正例(False Positive,FP):真实类别为负例,预测类别为正例。
-
假负例(False Negative,FN):真实类别为正例,预测类别为负例。
-
真负例(True Negative,TN):真实类别为负例,预测类别为负例。
然后可以构建混淆矩阵(Confusion Matrix)如下表所示。
准确率 (Accuracy,Acc):
A
c
c
=
T
P
+
T
N
t
o
t
a
l
Acc = \\frac{TP+TN}{total}
Acc=totalTP+TN
精确率,又称查准率(Precision,P):
p
=
T
P
T
P
+
F
P
p = \\frac{TP}{TP+FP}
p=TP+FPTP
召回率,又称查全率(Recall,R):
R
=
T
P
T
P
+
F
N
R = \\frac{TP}{TP+FN}
R=TP+FNTP
F1值:
F
1
=
2
×
P
×
R
P
+
R
F1 = \\frac{2\\times P \\times R}{P+R}
F1=P+R2×P×R
F1的一般形式:
F
β
=
(
1
+
β
2
)
×
P
×
R
(
β
2
×
P
)
+
R
F_{\\beta} = \\frac{(1+\\beta^2) \\times P \\times R}{(\\beta^2 \\times P)+R}
Fβ=(β2×P)+R(1+β2)×P×R
#二分类
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
y_true = [0, 1, 1, 0, 1, 0]
y_pred = [1, 1, 1, 0, 0, 1]
Accuracy = accuracy_score(y_true, y_pred) #注意没有average参数
Precision = precision_score(y_true, y_pred, average='binary')
recall = recall_score(y_true, y_pred, average='binary')
f1score = f1_score(y_true, y_pred, average='binary')
如果只有一个二分类混淆矩阵,那么用以上的指标就可以进行评价,没有什么争议,但是当我们在n个二分类混淆矩阵上要综合考察评价指标的时候就会用到宏平均和微平均。
假设有如下的三分类结果:
根据上述公式我们可以得到一下结果(多分类中每一类都有Precision、Recall和F1-score):

2、F1_score中参数average
F1_score中关于参数average的用法描述和理解:
micro : Calculate metrics globally by counting the total true positives, false negatives and false positives.
micro : 通过先计算所有的TP,FN和FP的数量,然后再利上文提到的公式计算出F1
macro : Calculate metrics for each label, and find their unweighted mean. This does not take label imbalance into account.
macro : 先分布计算每个类别的F1,然后取平均(各类别F1的权重相同)
比如这个多分类问题,总共有1,2,3,4这4个类别,我们可以先算出1的F1,2的F1,3的F1,4的F1,然后再取平均(F1+F2+F3+F4)/4
3、多分类F1-score的计算方法
3.1 micro-F1
取值范围:(0, 1);
适用环境:多分类不平衡,若数据极度不平衡会影响结果;
计算方式:
a) 计算总的召回率
R
e
c
a
l
l
Recall
Recall:
R
e
c
a
l
l
m
i
=
T
P
1
+
T
P
2
+
T
P
3
T
P
1
+
T
P
2
+
T
P
3
+
F
N
1
+
F
N
2
+
F
N
3
Recall_{mi} = \\frac{TP_1+TP_2+TP_3}{TP_1+TP_2+TP_3+FN_1+FN_2+FN_3}
Recallmi=TP1+TP2+TP3+FN1+FN2+FN3TP1+TP2+TP3
b)计算总的准确率
P
r
e
c
i
s
i
o
n
Precision
Precision:
P
r
e
c
i
s
i
o
n
m
i
=
T
P
1
+
T
P
2
+
T
P
3
T
P
1
+
T
P
2
+
T
P
3
+
F
P
1
+
F
P
2
+
F
P
3
Precision_{mi} = \\frac{TP_1+TP_2+TP_3}{TP_1+TP_2+TP_3+FP_1+FP_2+FP_3}
Precisionmi=TP1+TP2+TP3+FP1+FP2+FP3TP1+TP2+TP3
c)计算
m
i
c
r
o
−
F
1
−
s
c
o
r
e
micro-F1-score
micro−F1−score:
m
i
c
r
o
−
F
1
−
s
c
o
r
e
=
2
×
R
e
c
a
l
l
m
i
×
P
r
e
c
i
s
i
o
n
m
i
R
e
c
a
l
l
m
i
+
P
r
e
c
i
s
i
o
n
m
i
micro-F1-score = 2\\times \\frac{Recall_{mi} \\times Precision_{mi} }{Recall_{mi} +Precision_{mi}}
micro−F1−score=2×Recallmi+PrecisionmiRecallmi×Precisionmi
TPi 是指第 i 类的 True Positive 正类判定为正类; 以上是关于自用F1值的主要内容,如果未能解决你的问题,请参考以下文章
FPi 是指第 i 类的 False Positive 负类判定为正类;
TNi 是指第 i 类的 True Negative 正类判定为负类;
FNi 是指第 i 类的 False Negative 负类判定为负类。
假设有如下的三分类结果:
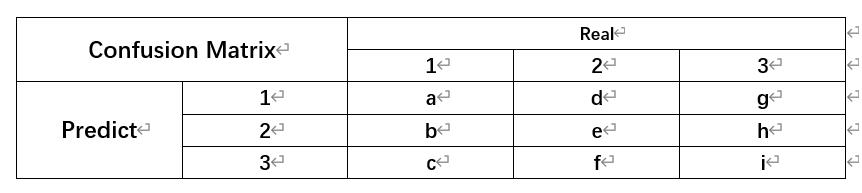
由此表我们可以得出:
对第1类:
F
P
1
=
d
+
g
;
T
P
1
=
a
;
F
N
1
=
b
+
c
;
T
N
1
=
e
+