GlusterFS-----文件分布系统+集群部署
Posted 28线不知名云架构师
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了GlusterFS-----文件分布系统+集群部署相关的知识,希望对你有一定的参考价值。
一、Gluster概述
1.1 、gluster简介
- Glusterfs是一个开源的分布式文件系统,是Scale存储的核心,能够处理千数量级的客户端.在传统的解决 方案中Glusterfs能够灵活的结合物理的,虚拟的和云资源去体现高可用和企业级的性能存储.
- Glusterfs通过TCP/IP或InfiniBand RDMA网络链接将客户端的存储资块源聚集在一起,使用单一的全局命名空间来管理数据,磁盘和内存资源.
- Glusterfs基于堆叠的用户空间设计,可以为不同的工作负载提供高优的性能.
- Glusterfs支持运行在任何标准IP网络上标准应用程序的标准客户端,用户可以在全局统一的命名空间中使用NFS/CIFS等标准协议来访问应用数据.
1.2、Glusterfs主要特征
- 扩展性和高性能
- 高可用
- 全局统一命名空间
- 弹性hash算法
- 弹性卷管理
- 基于标准协议
1.3、工作原理:
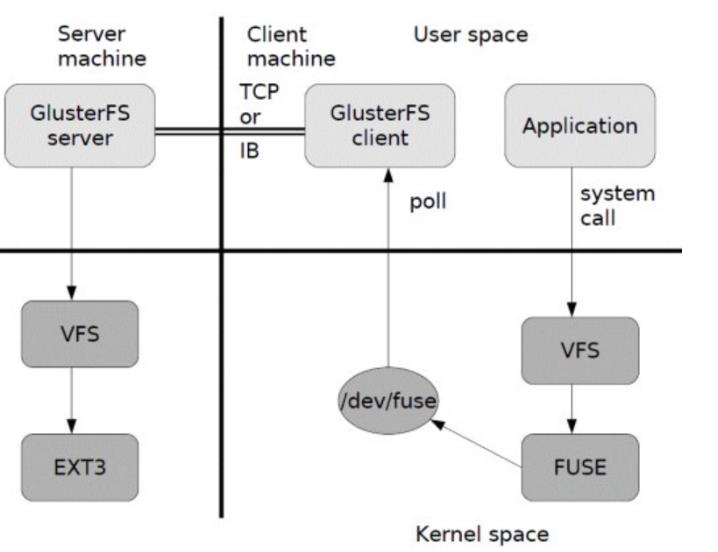
1) 首先是在客户端, 用户通过glusterfs的mount point 来读写数据, 对于用户来说,集群系统的存在对用户是完全透明的,用户感觉不到是操作本地系统还是远端的集群系统。
2) 用户的这个操作被递交给 本地linux系统的VFS来处理。
3) VFS 将数据递交给FUSE 内核文件系统:在启动 glusterfs 客户端以前,需要想系统注册一个实际的文件系统FUSE,如上图所示,该文件系统与ext3在同一个层次上面, ext3 是对实际的磁盘进行处理, 而fuse 文件系统则是将数据通过/dev/fuse 这个设备文件递交给了glusterfs client端。所以, 我们可以将 fuse文件系统理解为一个代理。
4) 数据被fuse 递交给Glusterfs client 后, client 对数据进行一些指定的处理(所谓的指定,是按照client 配置文件据来进行的一系列处理, 我们在启动glusterfs client 时需要指定这个文件。
5) 在glusterfs client的处理末端,通过网络将数据递交给 Glusterfs Server,并且将数据写入到服务器所控制的存储设备上。
1.4、常用卷类型
分布(distributed)
复制(replicate)
条带(striped)
基本卷:
(1) distribute volume:分布式卷
(2) stripe volume:条带卷
(3) replica volume:复制卷
复合卷:
(4) distribute stripe volume:分布式条带卷
(5) distribute replica volume:分布式复制卷
(6) stripe replica volume:条带复制卷
(7) distribute stripe replicavolume:分布式条带复制卷
1.5、GlusterFSt的专业术语
brick GFS中的存储单元,通过是一个受信存储池中的服务器的一个导出目录。可以通过主机名和目录名来标识
volume 本地文件系统的“分区”,卷
FUSE : 内核文件系统,是一个可加载的内核模块,其支持非特权用户创建自己的文件系统而不需要修改内核代码。
通过在用户空间运行文件系统的代码通过FUSE代码与内核进行桥接,类比EXT4,这是一个“伪文件系统”
以本地文件系统为例,用户想要读写一个文件,会借助于EXT4文件系统,
然后把数据写在磁盘上,而如果是远端的GFS,客户端的请求则应该交给FUSE(伪文件系统),
就可以实现跨界点存储在GFS上
VFS(虚拟端口):内核态的虚拟文件系统,用户是先提交请求交给VFS
然后VFS交给FUSE 再交给GFS客户端,最后由客户端交给远端的存储
Glusterd:Gluster management daemon,要在trusted storage pool中所有的服务器上运行二、分布式文件系统
2.1、文件系统
- 文件系统接口
- 对对像管理的软件集合
- 对象及属性
2.2、作用
从系统角度来看,文件系统是对文件存储设备的空间进行组织和分配,负责文件存储并对存入的文件进行保护和检索的系统。
具体地说,它负责为用户建立文件,存入、读出、修改、转储文件,控制文件的存取
2.3、挂载使用
除根文件系统以外的文件系统创建后要使用需要先挂载至挂载点后才可以被访问,挂载点即分区设备文件关联的某个目录文件,类比:NFS
三、部署 GlusterFS 群集
3.1、部署环境
| 主机 | IP地址 |
| node1 | 192.168.30.6 |
| node2 | 192.168.30.7 |
| node3 | 192.168.30.8 |
| node4 | 192.168.30.9 |
| client | 192.168.30.5 |
磁盘与挂载点相对应


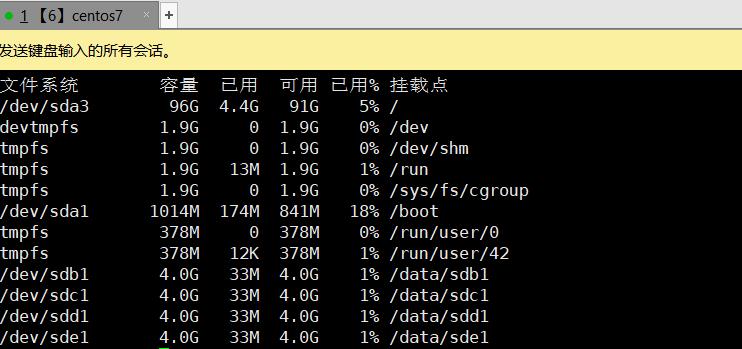
3.2、配置/etc/hosts文件
将主机名与对应IP写入文件里
3.3、安装GlusterFS并启动
[root@node1 ~]# yum -y install glusterfs glusterfs-server glusterfs-fuse glusterfs-rdma //,其他节点同样操作
已加载插件:fastestmirror, langpacks
Loading mirror speeds from cached hostfile
软件包 glusterfs-3.10.2-1.el7.x86_64 已安装并且是最新版本
软件包 glusterfs-server-3.10.2-1.el7.x86_64 已安装并且是最新版本
软件包 glusterfs-fuse-3.10.2-1.el7.x86_64 已安装并且是最新版本
软件包 glusterfs-rdma-3.10.2-1.el7.x86_64 已安装并且是最新版本
无须任何处理[root@node1 opt]# systemctl start glusterd.service //启动
[root@node1 opt]# systemctl enable glusterd.service //开机自启
Created symlink from /etc/systemd/system/multi-user.target.wants/glusterd.service to /usr/lib/systemd/system/glusterd.service.
[root@node1 opt]# systemctl status glusterd.service //查询状态
● glusterd.service - GlusterFS, a clustered file-system server
Loaded: loaded (/usr/lib/systemd/system/glusterd.service; enabled; vendor preset: disabled)
Active: active (running) since Wed 2021-08-11 19:11:03 CST; 2s ago
Main PID: 19604 (glusterd)
CGroup: /system.slice/glusterd.service
└─19604 /usr/sbin/glusterd -p /var/run/glusterd.pid --log-level INFO...
Aug 11 19:11:03 node1 systemd[1]: Starting GlusterFS, a clustered file-system.....
Aug 11 19:11:03 node1 systemd[1]: Started GlusterFS, a clustered file-system ...r.
Hint: Some lines were ellipsized, use -l to show in full.3.4、时间同步,加入存储信任池
[root@node1 opt]# ntpdate ntp1.aliyun.com //同步阿里云的ntp服务器
11 Aug 19:13:20 ntpdate[19714]: adjust time server 120.25.115.20 offset 0.003094 sec[root@node1 opt]# gluster peer probe node1 //加入存储信任池,只需要在一台节点上操作即可
peer probe: success. Probe on localhost not needed
[root@node1 opt]# gluster peer probe node2
peer probe: success.
[root@node1 opt]# gluster peer probe node3
peer probe: success.
[root@node1 opt]# gluster peer probe node4
peer probe: success. [root@node1 opt]# gluster peer status //在每个Node节点上查看群集状态
Number of Peers: 3
Hostname: node2
Uuid: a02106dc-7fed-4bf8-9968-efa2a5bc4ec7
State: Peer in Cluster (Connected)
Hostname: node3
Uuid: 038c0761-f1f6-42c3-914e-40aedbdbf720
State: Peer in Cluster (Connected)
Hostname: node4
Uuid: 6840d481-bf60-43b8-ae71-97395a0d9bcb
State: Peer in Cluster (Connected)3.5、创建卷
卷名称 卷类型 Brick
dis-volume 分布式卷 node1(/data/sdb1)、node2(/data/sdb1)
stripe-volume 条带卷 node1(/data/sdc1)、node2(/data/sdc1)
rep-volume 复制卷 node3(/data/sdb1)、node4(/data/sdb1)
dis-stripe 分布式条带卷 node1(/data/sdd1)、node2(/data/sdd1)、node3(/data/sdd1)、node4(/data/sdd1)
dis-rep 分布式复制卷 node1(/data/sde1)、node2(/data/sde1)、node3(/data/sde1)、node4(/data/sde1)3.5.1、创建分布式卷
[root@node1 opt]# gluster volume create dis-volume node1:/data/sdb1 node2:/data/sdb1 force //创建分布式卷,没有指定类型,默认创建的是分布式卷
volume create: dis-volume: success: please start the volume to access data
[root@node1 opt]# gluster volume list //查看卷列表
dis-volume
[root@node1 opt]# gluster volume start dis-volume //启动新建分布式卷
volume start: dis-volume: success
[root@node1 opt]# gluster volume info dis-volume //查看创建分布式卷信息
Volume Name: dis-volume
Type: Distribute
Volume ID: cffc4402-ec03-4a48-aebe-3158e5231dc5
Status: Started
Snapshot Count: 0
Number of Bricks: 2
Transport-type: tcp
Bricks:
Brick1: node1:/data/sdb1
Brick2: node2:/data/sdb1
Options Reconfigured:
transport.address-family: inet
nfs.disable: on3.5.2、创建条带卷
[root@node1 opt]# gluster volume create stripe-volume stripe 2 node1:/data/sdc1 node2:/data/sdc1 force //指定类型为 stripe,数值为 2,且后面跟了 2 个 Brick Server,所以创建的是条带卷
volume create: stripe-volume: success: please start the volume to access data
[root@node1 opt]# gluster volume start stripe-volume //启动新建条带卷
volume start: stripe-volume: success
[root@node1 opt]# gluster volume info stripe-volume //查看新建条带卷信息
Volume Name: stripe-volume
Type: Stripe
Volume ID: 478b8497-4c3d-4db4-b958-2abf5798aac2
Status: Started
Snapshot Count: 0
Number of Bricks: 1 x 2 = 2
Transport-type: tcp
Bricks:
Brick1: node1:/data/sdc1
Brick2: node2:/data/sdc1
Options Reconfigured:
transport.address-family: inet
nfs.disable: on
[root@node1 opt]# 3.5.3、创建复制卷
[root@node1 opt]# gluster volume create rep-volume replica 2 node3:/data/sdb1 node4:/data/sdb1 force //指定类型为 replica,数值为 2,且后面跟了 2 个 Brick Server,所以创建的是复制卷
volume create: rep-volume: success: please start the volume to access data
[root@node1 opt]# gluster volume start rep-volume //启动新建复制卷
volume start: rep-volume: success
[root@node1 opt]# gluster volume info rep-volume //查看新建复制卷信息
Volume Name: rep-volume
Type: Replicate
Volume ID: 2ae6ca8a-73af-485b-86d1-c6b0ed74a09b
Status: Started
Snapshot Count: 0
Number of Bricks: 1 x 2 = 2
Transport-type: tcp
Bricks:
Brick1: node3:/data/sdb1
Brick2: node4:/data/sdb1
Options Reconfigured:
transport.address-family: inet3.5.4、创建分布式条带卷
[root@node1 opt]# gluster volume create dis-stripe stripe 2 node1:/data/sdd1 node2:/data/sdd1 node3:/data/sdd1 node4:/data/sdd1 force //指定类型为 stripe,数值为 2,而且后面跟了 4 个 Brick Server,是 2 的两倍,所以创建的是分布式条带卷
volume create: dis-stripe: success: please start the volume to access data
[root@node1 opt]# gluster volume start dis-stripe //启动新建分布式条带卷
volume start: dis-stripe: success
[root@node1 opt]# gluster volume info dis-stripe //查看分布式条带卷信息
Volume Name: dis-stripe
Type: Distributed-Stripe
Volume ID: 54bcbe8e-f30a-4bbb-a36a-13d7cfaaab2b
Status: Started
Snapshot Count: 0
Number of Bricks: 2 x 2 = 4
Transport-type: tcp
Bricks:
Brick1: node1:/data/sdd1
Brick2: node2:/data/sdd1
Brick3: node3:/data/sdd1
Brick4: node4:/data/sdd1
Options Reconfigured:
transport.address-family: inet
nfs.disable: on3.5.5、创建分布式复制卷
[root@node1 opt]# gluster volume create dis-rep replica 2 node1:/data/sde1 node2:/data/sde1 node3:/data/sde1 node4:/data/sde1 force //指定类型为 replica,数值为 2,而且后面跟了 4 个 Brick Server,是 2 的两倍,所以创建的是分布式复制卷
volume create: dis-rep: success: please start the volume to access data
[root@node1 opt]# gluster volume start dis-rep //启动新建分布式复制卷
volume start: dis-rep: success
[root@node1 opt]# gluster volume info dis-rep //查看新建分布式复制卷信息
Volume Name: dis-rep
Type: Distributed-Replicate
Volume ID: 39a8d0e8-79e9-431f-aeca-b69254d687c5
Status: Started
Snapshot Count: 0
Number of Bricks: 2 x 2 = 4
Transport-type: tcp
Bricks:
Brick1: node1:/data/sde1
Brick2: node2:/data/sde1
Brick3: node3:/data/sde1
Brick4: node4:/data/sde1
Options Reconfigured:
transport.address-family: inet
nfs.disable: on3.5.6、查看卷列表
[root@node1 opt]# gluster volume list
dis-rep
dis-stripe
dis-volume
rep-volume
stripe-volume3.6、部署客户端
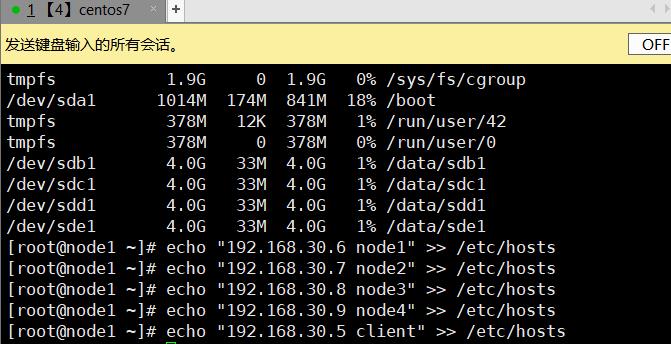
3.6.1、配置hosts文件
[root@client ~]# echo "192.168.30.6 node1" >> /etc/hosts
[root@client ~]# echo "192.168.30.7 node2" >> /etc/hosts
[root@client ~]# echo "192.168.30.8 node3" >> /etc/hosts
[root@client ~]# echo "192.168.30.9 node4" >> /etc/hosts
[root@client ~]# echo "192.168.30.5 client" >> /etc/hosts
[root@client ~]# 3.6.2、安装gfs客户端
[root@client opt]# yum -y install glusterfs glusterfs-fuse
已加载插件:fastestmirror, langpacks
Loading mirror speeds from cached hostfile
匹配 glusterfs-3.10.2-1.el7.x86_64 的软件包已经安装。正在检查更新。
匹配 glusterfs-fuse-3.10.2-1.el7.x86_64 的软件包已经安装。正在检查更新。
无须任何处理3.6.3、创建挂载点,挂载 gluster文件系统
[root@client opt]# mkdir -p /test/{dis,stripe,rep,dis_stripe,dis_rep}
[root@client opt]# ls /test
dis dis_rep dis_stripe rep stripe
[root@client opt]# mount.glusterfs node1:dis-volume /test/dis
[root@client opt]# mount.glusterfs node1:stripe-volume /test/stripe
[root@client opt]# mount.glusterfs node1:rep-volume /test/rep
[root@client opt]# mount.glusterfs node1:dis-stripe /test/dis_stripe
[root@client opt]# mount.glusterfs node1:dis-rep /test/dis_rep
[root@client opt]# df -hT
文件系统 类型 容量 已用 可用 已用% 挂载点
/dev/sda3 xfs 197G 4.5G 193G 3% /
devtmpfs devtmpfs 895M 0 895M 0% /dev
tmpfs tmpfs 910M 0 910M 0% /dev/shm
tmpfs tmpfs 910M 11M 900M 2% /run
tmpfs tmpfs 910M 0 910M 0% /sys/fs/cgroup
/dev/sda1 xfs 1014M 174M 841M 18% /boot
tmpfs tmpfs 182M 12K 182M 1% /run/user/42
tmpfs tmpfs 182M 0 182M 0% /run/user/0
node1:dis-volume fuse.glusterfs 8.0G 65M 8.0G 1% /test/dis
node1:stripe-volume fuse.glusterfs 8.0G 65M 8.0G 1% /test/stripe
node1:rep-volume fuse.glusterfs 4.0G 33M 4.0G 1% /test/rep
node1:dis-stripe fuse.glusterfs 16G 130M 16G 1% /test/dis_stripe
node1:dis-rep fuse.glusterfs 8.0G 65M 8.0G 1% /test/dis_rep
[root@client opt]# 3.7、测试
3.7.1、写入数据
[root@client opt]# ls -lh /opt
总用量 150M
-rw-r--r-- 1 root root 20M 8月 11 19:55 demo1.log
-rw-r--r-- 1 root root 20M 8月 11 19:55 demo2.log
-rw-r--r-- 1 root root 20M 8月 11 19:55 demo3.log
-rw-r--r-- 1 root root 20M 8月 11 19:55 demo4.log
-rw-r--r-- 1 root root 20M 8月 11 19:55 demo5.log
drwxr-xr-x 3 root root 8.0K 11月 20 2020 gfsrepo
-rw-r--r-- 1 root root 50M 8月 11 09:33 gfsrepo.zip
drwxr-xr-x. 2 root root 6 10月 31 2018 rh
[root@client opt]#
[root@client opt]# cp demo* /test/dis
[root@client opt]# cp demo* /test/stripe/
[root@client opt]# cp demo* /test/rep/
[root@client opt]# cp demo* /test/dis_stripe/
[root@client opt]# cp demo* /test/dis_rep/3.7.2、查看文件分布
3.7.2.1 分布式卷
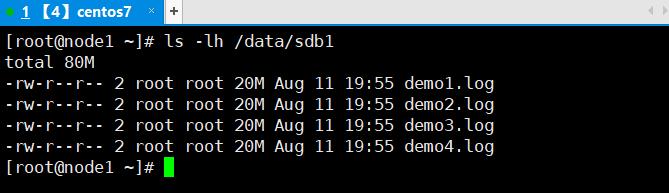
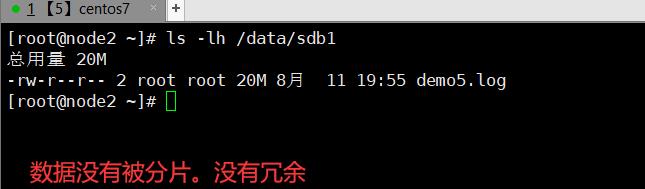
3.7.2.2、条带卷
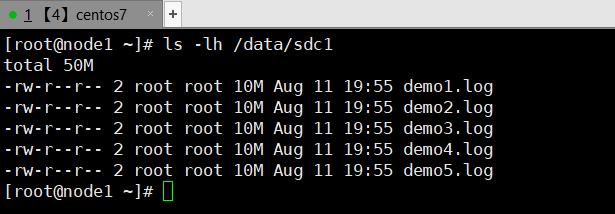
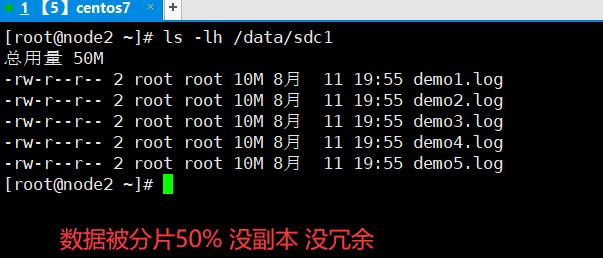
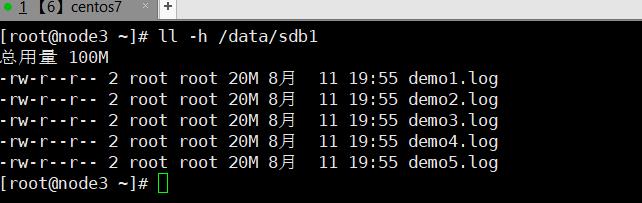
3.7.2.3、 复制卷
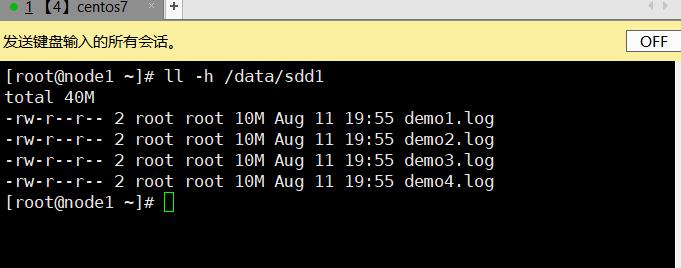
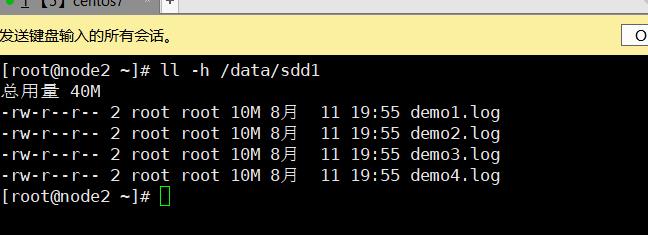
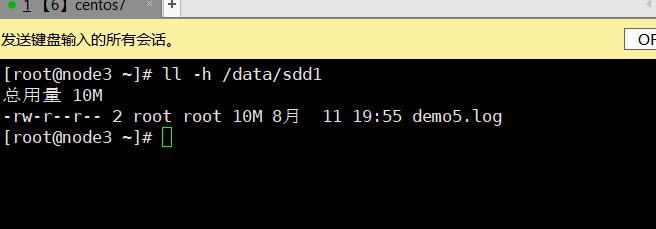
3.7.2.4、分布式条带卷
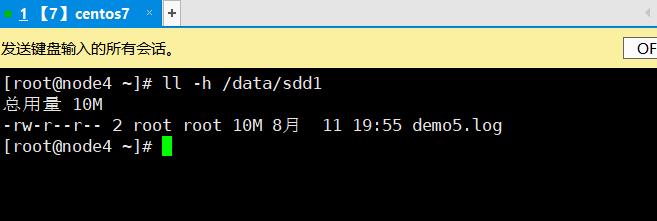
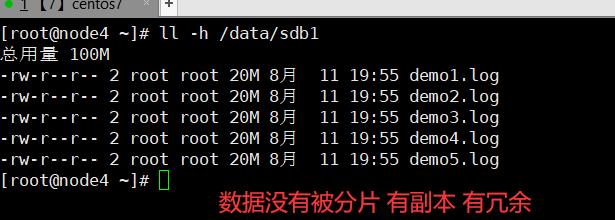
3.7.2.5、分布式复制卷
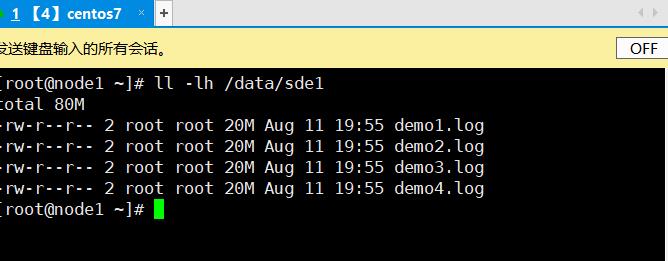
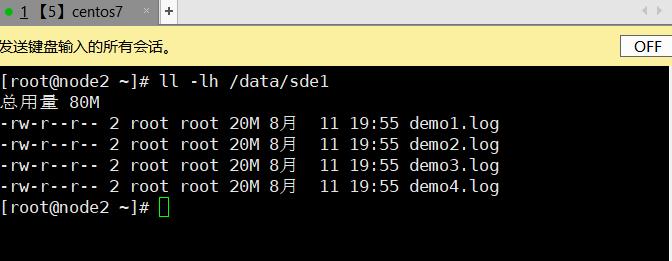
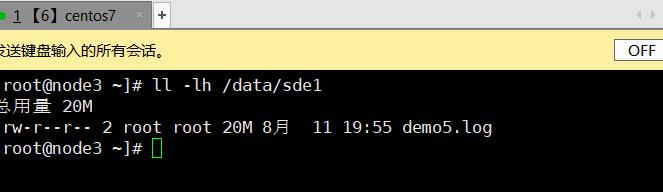
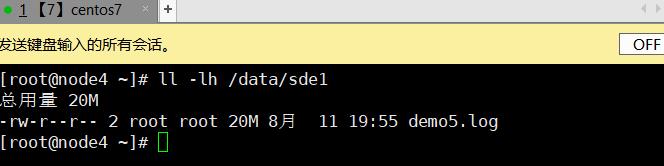
3.8、破坏性测试
3.8.1、关闭一台节点服务器
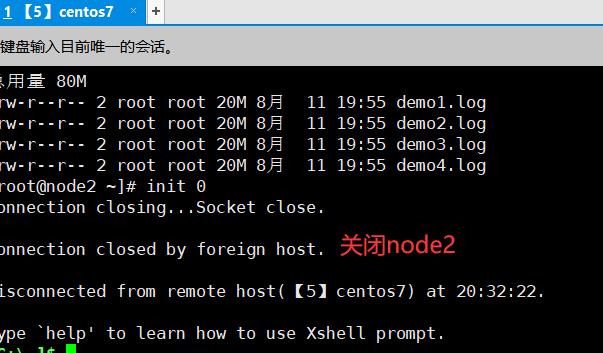
3.8.2、查看文件
[root@client test]# ls -lh dis/ stripe/ rep dis_stripe/ dis_rep/
dis/:
总用量 80M
-rw-r--r-- 1 root root 20M 8月 11 19:55 demo1.log
-rw-r--r-- 1 root root 20M 8月 11 19:55 demo2.log
-rw-r--r-- 1 root root 20M 8月 11 19:55 demo3.log
-rw-r--r-- 1 root root 20M 8月 11 19:55 demo4.log
dis_rep/:
总用量 100M
-rw-r--r-- 1 root root 20M 8月 11 19:55 demo1.log
-rw-r--r-- 1 root root 20M 8月 11 19:55 demo2.log
-rw-r--r-- 1 root root 20M 8月 11 19:55 demo3.log
-rw-r--r-- 1 root root 20M 8月 11 19:55 demo4.log
-rw-r--r-- 1 root root 20M 8月 11 19:55 demo5.log
dis_stripe/:
总用量 20M
-rw-r--r-- 1 root root 20M 8月 11 19:55 demo5.log
rep:
总用量 100M
-rw-r--r-- 1 root root 20M 8月 11 19:55 demo1.log
-rw-r--r-- 1 root root 20M 8月 11 19:55 demo2.log
-rw-r--r-- 1 root root 20M 8月 11 19:55 demo3.log
-rw-r--r-- 1 root root 20M 8月 11 19:55 demo4.log
-rw-r--r-- 1 root root 20M 8月 11 19:55 demo5.log
stripe/:
ls: 正在读取目录stripe/: 传输端点尚未连接
总用量 0小结:
- 在多个后端存储中定位文件:
- 使用弹性HASH算法来解决数据定位、索引、寻址的功能
- 先通过HASH算法对数据可以得到一个值(该值有2的32次方个组合)
- 每个数据对应了0-2的32次方的一个值
- (分布式)平均分配的好处:
- 当数据量越来越大的时候,相对每个存储节点的数据量(几率)是相等的
- 而如果考虑到单点故障问题,当数据存储在C存储节点,对此GFS是会有备份机制的(卷),默认3备份,所以GFS本身的机制会对数据产生冗余,以此解决单点故障
以上是关于GlusterFS-----文件分布系统+集群部署的主要内容,如果未能解决你的问题,请参考以下文章