Springboot整合es集群实现千万级数据量导入
Posted 爱上口袋的天空
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Springboot整合es集群实现千万级数据量导入相关的知识,希望对你有一定的参考价值。
1、创建一个mysql测试表,数据量大概6千万左右
create table big_table_test( id int(11) not null primary key, num1 double(8,2), num2 double(8,2), num3 double(8,2), num4 double(8,2), num5 double(8,2), num6 double(8,2), num7 double(8,2), num8 double(8,2), node_id VARCHAR(10) not null, create_time timestamp, create_by VARCHAR(30) );
2、准备es集群
3台机器:
192.168.56.20:9200
192.168.56.20:9200
192.168.56.20:9200
3、使用kibana在es上创建表结构
PUT big_table_test8 { "settings": { "number_of_shards": 3, "number_of_replicas": 0, "refresh_interval": "-1" }, "mappings": { "properties": { "id":{ "type": "keyword" }, "num1":{ "type": "keyword" }, "num2":{ "type": "keyword" }, "num3":{ "type": "keyword" }, "num4":{ "type": "keyword" }, "num5":{ "type": "keyword" }, "num6":{ "type": "keyword" }, "num7":{ "type": "keyword" }, "num8":{ "type": "keyword" }, "nodeId":{ "type": "keyword" }, "createTime":{ "type": "keyword" }, "createBy":{ "type": "keyword" } } } }注意:
如果我们要一次性加载大批量的数据进es,可以先禁止refresh和replia复制,将index.refresh_interval设置为-1,将index.number_of_replicas设置为0即可。这可能会导致我们的数据丢失,因为没有refresh和replica机制了。但是不需要创建segment file,也不需要将数据replica复制到其他的replica shasrd上面去。此时写入的速度会非常快,一旦写完之后,可以将refresh和replica修改回正常的状态。
4、springboot整合es集群
4.1、在application.yaml中配置es
4.2、创建ElasticsearchConfig.java
package com.kgf.es.config; import lombok.Data; import org.apache.http.HttpHost; import org.apache.http.client.config.RequestConfig; import org.elasticsearch.client.RestClient; import org.elasticsearch.client.RestClientBuilder; import org.elasticsearch.client.RestHighLevelClient; import org.springframework.boot.context.properties.ConfigurationProperties; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; @ConfigurationProperties(prefix = "elasticsearch") @Configuration @Data public class ElasticsearchConfig extends AbstractElasticsearchConfiguration{ private String[] host ; private Integer port ; //重写父类方法 @Bean(name = "restHighLevelClient") @Override public RestHighLevelClient elasticsearchClient() { RestClientBuilder builder = RestClient.builder( new HttpHost(host[0], port), new HttpHost(host[1], port), new HttpHost(host[2], port) ).setRequestConfigCallback(new RestClientBuilder.RequestConfigCallback() { @Override public RequestConfig.Builder customizeRequestConfig(RequestConfig.Builder requestConfigBuilder) { return requestConfigBuilder.setConnectTimeout(5000 * 1000) // 连接超时(默认为1秒) .setSocketTimeout(6000 * 1000);// 套接字超时(默认为30秒)//更改客户端的超时限制默认30秒现在改为100*1000分钟 } }); RestHighLevelClient restHighLevelClient = new RestHighLevelClient(builder); return restHighLevelClient; } }4.3、创建AbstractElasticsearchConfiguration.java
package com.kgf.es.config; import org.elasticsearch.client.RestHighLevelClient; import org.springframework.context.annotation.Bean; import org.springframework.data.elasticsearch.config.ElasticsearchConfigurationSupport; import org.springframework.data.elasticsearch.core.ElasticsearchOperations; import org.springframework.data.elasticsearch.core.ElasticsearchRestTemplate; import org.springframework.data.elasticsearch.core.convert.ElasticsearchConverter; /** * @author Christoph Strobl * @author Peter-Josef Meisch * @since 3.2 * @see ElasticsearchConfigurationSupport */ public abstract class AbstractElasticsearchConfiguration extends ElasticsearchConfigurationSupport { //需重写本方法 public abstract RestHighLevelClient elasticsearchClient(); @Bean(name = { "elasticsearchOperations", "elasticsearchTemplate" }) public ElasticsearchOperations elasticsearchOperations(ElasticsearchConverter elasticsearchConverter) { return new ElasticsearchRestTemplate(elasticsearchClient(), elasticsearchConverter); } }4.4、创建线程池工具类
package com.kgf.es.thread; import java.util.concurrent.*; /** * 线程池工具类: * 处理项目中需要异步处理的任务,例如日志服务,监控服务等 */ public class ThreadPoolUtil { /** 工具类,构造方法私有化 */ private ThreadPoolUtil() {super();}; // 线程池核心线程数 private final static Integer COREPOOLSIZE = Runtime.getRuntime().availableProcessors(); // 最大线程数 private final static Integer MAXIMUMPOOLSIZE = COREPOOLSIZE * 2; // 空闲线程存活时间 private final static Integer KEEPALIVETIME = 3 * 60; // 线程等待队列 private static BlockingQueue<Runnable> queue = new ArrayBlockingQueue<>(500); // 线程池对象 private static ThreadPoolExecutor threadPool = new ThreadPoolExecutor(COREPOOLSIZE, MAXIMUMPOOLSIZE, KEEPALIVETIME, TimeUnit.SECONDS, queue, new ThreadPoolExecutor.AbortPolicy()); /** * 向线程池提交一个任务,返回线程结果 * @param r * @return */ public static Future<?> submit(Callable<?> r) { return threadPool.submit(r); } /** * 向线程池提交一个任务,不关心处理结果 * @param r */ public static void execute(Runnable r) { threadPool.execute(r); } /** 获取当前线程池线程数量 */ public static int getSize() { return threadPool.getPoolSize(); } /** 获取当前活动的线程数量 */ public static int getActiveCount() { return threadPool.getActiveCount(); } }4.5、创建JDBCUtil.java工具类
package com.kgf.es.utils; import java.sql.*; /** * 当statement设置以下属性时,采用的是流数据接收方式,每次只从服务器接收部份数据,直到所有数据处理完毕,不会发生JVM OOM。 * ResultSet.TYPE_FORWORD_ONLY 结果集的游标只能向下滚动。 * ResultSet.CONCUR_READ_ONLY 不能用结果集更新数据库中的表。 * ps.setFetchSize(Integer.MIN_VALUE) */ public class JDBCUtil { //链接地址,设置编码可用且为utf-8 public static String URL="jdbc:mysql://192.168.1.13:3306/oss?userUnicode=true&characterEncoding=UTF-8&serverTimeZone=UTC"; //数据库用户名 public static String USER="root"; //数据库密码 public static String PWD="897570"; /* *进行数据库的链接 */ public static Connection getConnection(){ Connection con=null; try { //加载驱动 Class.forName("com.mysql.jdbc.Driver"); //创建链接 con= DriverManager.getConnection(URL, USER, PWD); }catch (Exception e) { e.printStackTrace(); } //返回连接 return con; } /* *数据库关闭 */ public static void Close(Connection con, PreparedStatement pstmt, ResultSet rs){ try { //判断是否被操作 if(rs!=null) rs.close(); if(pstmt!=null) pstmt.close(); if(con!=null) con.close(); } catch (SQLException e) { e.printStackTrace(); } } }4.6、创建数据导入的方法类
package com.kgf.es.thread; import com.kgf.es.model.BigTableTest; import com.kgf.es.utils.JDBCUtil; import lombok.extern.slf4j.Slf4j; import org.elasticsearch.action.DocWriteRequest; import org.elasticsearch.action.bulk.*; import org.elasticsearch.action.index.IndexRequest; import org.elasticsearch.client.RequestOptions; import org.elasticsearch.client.RestHighLevelClient; import org.elasticsearch.common.unit.ByteSizeUnit; import org.elasticsearch.common.unit.ByteSizeValue; import org.elasticsearch.common.unit.TimeValue; import org.elasticsearch.common.xcontent.XContentFactory; import org.springframework.stereotype.Component; import javax.annotation.Resource; import java.math.BigDecimal; import java.sql.Connection; import java.sql.PreparedStatement; import java.sql.ResultSet; import java.util.Date; import java.util.List; import java.util.concurrent.ConcurrentLinkedQueue; import java.util.concurrent.CountDownLatch; import java.util.concurrent.atomic.AtomicBoolean; import java.util.stream.Collectors; /** * 工作线程处理每一个线程队列中的消息 * @author KGF * */ @Slf4j @Component public class RequestQueueProcessor{ /** * ConcurrentLinkedQueue: * 一个基于链接节点的无界线程安全队列。此队列按照 FIFO(先进先出)原则对元素进行排序。 * 队列的头部 是队列中时间最长的元素。队列的尾部 是队列中时间最短的元素。 * 新的元素插入到队列的尾部,队列获取操作从队列头部获得元素。当多个线程共享访问一个公共 collection 时,ConcurrentLinkedQueue 是一个恰当的选择。 * 此队列不允许使用 null 元素。 */ private ConcurrentLinkedQueue<BigTableTest> queue = new ConcurrentLinkedQueue<>(); /*** * AtomicBoolean是一个原子boolen类,可以用于高并发场景下的标记处理,例如某个只需初始化一次的服务: */ static AtomicBoolean isInsert = new AtomicBoolean(true); /*** * 设置队列达到最大的上线数 */ private static Integer QUEUE_SIZE_TOP = 200000; //批量操作的对象 private static BulkProcessor bulkProcessor; @Resource private RestHighLevelClient restHighLevelClient; public void addDataToEs() { //获取cpu核心数 int processors = Runtime.getRuntime().availableProcessors(); //CountDownLatch可以使一个获多个线程等待其他线程各自执行完毕后再执行 CountDownLatch countDownLatch = new CountDownLatch(processors); final long t1 = System.currentTimeMillis(); //创建多个线程 for (int i = 0; i < processors; i++) { ThreadPoolUtil.execute(new Runnable() { @Override public void run() { /** * BulkProcessor是一个线程安全的批量处理类,允许方便地设置 刷新 一个新的批量请求 * (基于数量的动作,根据大小,或时间), * 容易控制并发批量的数量 * 请求允许并行执行。 */ BulkProcessor.Listener listener = new BulkProcessor.Listener() { @Override public void beforeBulk(long executionId, BulkRequest request) { log.info("1. 【beforeBulk】批次[{}] 携带 {} 请求数量", executionId, request.numberOfActions()); } /*** * // 在每次执行BulkRequest后调用,通过此方法可以获取BulkResponse是否包含错误 * @param executionId * @param request * @param response */ @Override public void afterBulk(long executionId, BulkRequest request, BulkResponse response) { if (!response.hasFailures()) { log.info("2. 【afterBulk-成功】批量 [{}] 完成在 {} ms", executionId, response.getTook().getMillis()); } else { BulkItemResponse[] items = response.getItems(); for (BulkItemResponse item : items) { if (item.isFailed()) { log.info("2. 【afterBulk-失败】批量 [{}] 出现异常的原因 : {}", executionId, item.getFailureMessage()); break; } } } } @Override public void afterBulk(long executionId, BulkRequest request, Throwable failure) { List<DocWriteRequest<?>> requests = request.requests(); List<String> esIds = requests.stream().map(DocWriteRequest::id).collect(Collectors.toList()); log.error("3. 【afterBulk-failure失败】es执行bluk失败,失败的esId为:{}", esIds, failure); } }; BulkProcessor.Builder builder = BulkProcessor.builder(((bulkRequest, bulkResponseActionListener) -> { //bulkRequest.setRefreshPolicy(WriteRequest.RefreshPolicy.IMMEDIATE);//写入后立刻刷新,效率比较低 restHighLevelClient.bulkAsync(bulkRequest, RequestOptions.DEFAULT, bulkResponseActionListener); }), listener); //设置 request 的数量,每添加10000个request,执行一次bulk操作 builder.setBulkActions(10000); // 每达到100M的请求size时,执行一次bulk操作 builder.setBulkSize(new ByteSizeValue(100L, ByteSizeUnit.MB)); // 每5s执行一次bulk操作 builder.setFlushInterval(TimeValue.timeValueSeconds(10)); // 设置并发请求数。默认是1,表示允许执行1个并发请求,积累bulk requests和发送bulk是异步的,其数值表示发送bulk的并发线程数(可以为2、3、...);若设置为0表示二者同步 builder.setConcurrentRequests(1); // 最大重试次数为3次,启动延迟为100ms。 builder.setBackoffPolicy(BackoffPolicy.constantBackoff(TimeValue.timeValueSeconds(100), 3)); BulkProcessor build = builder.build(); try { while (true){ if (!queue.isEmpty()) { BigTableTest bigTableTest = queue.poll(); if (bigTableTest==null)continue; build.add( new IndexRequest("big_table_test8") .id(bigTableTest.getId().toString()) .source(XContentFactory.jsonBuilder().startObject() .field("num1",bigTableTest.getNum1()) .field("num2",bigTableTest.getNum2()) .field("num3",bigTableTest.getNum3()) .field("num4",bigTableTest.getNum4()) .field("num5",bigTableTest.getNum5()) .field("num6",bigTableTest.getNum6()) .field("num7",bigTableTest.getNum7()) .field("num8",bigTableTest.getNum8()) .field("nodeId",bigTableTest.getNodeId()) .field("createTime",new Date(bigTableTest.getCreateTime().getTime())) .field("createBy",bigTableTest.getCreateBy()) .endObject() ) ); } if (!isInsert.get() && queue.isEmpty()) {//所有数据写入之后进行一次刷新 // 最后执行一次刷新操作 build.flush(); build.close(); break; } } } catch (Exception e) { e.printStackTrace(); }finally { countDownLatch.countDown(); } } }); } try { WriteData(); } catch (Exception e) { e.printStackTrace(); }finally { try { countDownLatch.await(); } catch (InterruptedException e) { e.printStackTrace(); } } log.info("数据写入完毕,total cost time is {}",System.currentTimeMillis()-t1); } public void WriteData() { Connection conn = null; PreparedStatement ps = null; ResultSet rs = null; Integer count = 0; try { conn = JDBCUtil.getConnection(); String sql = "select * from big_table_test WHERE num1 <= 0.17"; ps = conn.prepareStatement(sql, ResultSet.TYPE_FORWARD_ONLY, ResultSet.CONCUR_READ_ONLY); ps.setFetchSize(Integer.MIN_VALUE); rs = ps.executeQuery(); while(rs.next()) { //while控制行数 int id = rs.getInt("id"); BigDecimal num1 = rs.getBigDecimal("num1"); BigDecimal num2 = rs.getBigDecimal("num1"); BigDecimal num3 = rs.getBigDecimal("num1"); BigDecimal num4 = rs.getBigDecimal("num1"); BigDecimal num5 = rs.getBigDecimal("num1"); BigDecimal num6 = rs.getBigDecimal("num1"); BigDecimal num7 = rs.getBigDecimal("num1"); BigDecimal num8 = rs.getBigDecimal("num1"); String nodeId = rs.getString("node_id"); Date createTime = rs.getTimestamp("create_time"); String createBy = rs.getString("create_by"); BigTableTest bigTableTest = new BigTableTest(); bigTableTest.setId(id); bigTableTest.setNum1(num1); bigTableTest.setNum2(num2); bigTableTest.setNum3(num3); bigTableTest.setNum4(num4); bigTableTest.setNum5(num5); bigTableTest.setNum6(num6); bigTableTest.setNum7(num7); bigTableTest.setNum8(num8); bigTableTest.setNodeId(nodeId); bigTableTest.setCreateTime(createTime); bigTableTest.setCreateBy(createBy); queue.add(bigTableTest); count++; if(count % QUEUE_SIZE_TOP == 0){//设置当数据达到20万的倍数时进行等待 int number = queue.size(); int n = number/QUEUE_SIZE_TOP; log.info("count is {}, n is {},queue size is {}",count,n,number); while(n > 0){ try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } number = queue.size(); n = number / QUEUE_SIZE_TOP; log.info("count is {}, n is {},queue size is {}",count,n,number); } } } isInsert = new AtomicBoolean(false); } catch (Exception e) { e.printStackTrace(); } finally { JDBCUtil.Close(conn,ps,rs); } } }
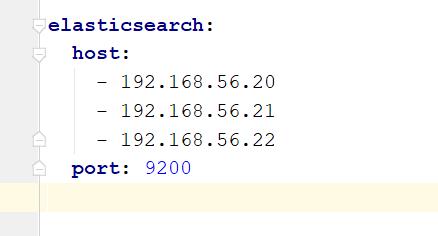
5、在项目中使用上面的方法导入一千万条数据所用的时间5分钟不到
6、事后将es的表数据刷新一下并且调整副本数和刷新时间
6.1、刷新命令
GET big_table_test8/_refresh
6.2、调整副本数
PUT /big_table_test8/_settings
{
"number_of_replicas": 1,
"refresh_interval": "1s"
}6.3、效果

以上是关于Springboot整合es集群实现千万级数据量导入的主要内容,如果未能解决你的问题,请参考以下文章