Java IO BIO NIO
Posted 爱是与世界平行
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java IO BIO NIO相关的知识,希望对你有一定的参考价值。
Java IO BIO NIO
一、Java I/O概述
Java 的I/O流是实现输入/输出的基础,它可以方便地实现数据的输入/输出操作,在 Java 中把不同的输入/输出源(键盘、文件、网络等)抽象表示为流。
IO,其实意味着:数据不停地搬入搬出缓冲区而已(使用了缓冲区)。比如,用户程序发起读操作,导致“ syscall read ”系统调用,就会把数据搬入到 一个buffer中;用户发起写操作,导致 “syscall write ”系统调用,将会把一个 buffer 中的数据 搬出去(发送到网络中 or 写入到磁盘文件)
先来看一张普通的IO处理的流程图:

I/O原理:
- input:读取外部数据(磁盘/光盘等存储设备)
- output:将程序(内存)数据写入到磁盘上
1.1 什么是流
知识科普:我们知道任何一个文件都是以二进制形式存在于设备中,计算机就只有 0 和 1,你能看见的东西全部都是由这两个数字组成,你看这篇文章时,这篇文章也是由01组成,只不过这些二进制串经过各种转换演变成一个个文字、一张张图片跃然屏幕上。
而流就是将这些二进制串在各种设备之间进行传输,如果你觉得有些抽象,我举个例子就会好理解一些:
下图是一张图片,它由01串组成,我们可以通过程序把一张图片拷贝到一个文件夹中,把图片转化成二进制数据集,把数据一点一点地传递到文件夹中 , 类似于水的流动 , 这样整体的数据就是一个数据流。

IO 流读写数据的特点:
- 顺序读写**。**读写数据时,大部分情况下都是按照顺序读写,读取时从文件开头的第一个字节到最后一个字节,写出时也是也如此(RandomAccessFile 可以实现随机读写);
- **字节数组。**读写数据时本质上都是对字节数组做读取和写出操作,即使是字符流,也是在字节流基础上转化为一个个字符,所以字节数组是 IO 流读写数据的本质。
1.2 流的分类
根据数据流向不同分类:输入流 和 输出流。
- **输入流:**从磁盘或者其它设备中将数据输入到进程中;
- **输出流:**将进程中的数据输出到磁盘或其它设备上保存。

图示中的硬盘只是其中一种设备,还有非常多的设备都可以应用在IO流中,例如:打印机、硬盘、显示器、手机······
根据处理数据的基本单位不同分类:字节流 和 字符流。
- 字节流:以字节(8 bit)为单位做数据的传输
- 字符流:以字符为单位(1字符 = 2字节)做数据的传输
字符流的本质也是通过字节流读取,Java 中的字符采用 Unicode 标准,在读取和输出的过程中,通过以字符为单位,查找对应的码表将字节转换为对应的字符。
面对字节流和字符流,很多读者都有疑惑:什么时候需要用字节流,什么时候又要用字符流?
我这里做一个简单的概括,你可以按照这个标准去使用:
字符流只针对字符数据进行传输,所以如果是文本数据,优先采用字符流传输;除此之外,其它类型的数据(图片、音频等),最好还是以字节流传输。
根据这两种不同的分类,我们就可以做出下面这个表格,里面包含了 IO 中最核心的 4 个顶层抽象类:

现在看 IO 是不是有一些思路了,不会觉得很混乱了,我们来看这四个类下的所有成员。
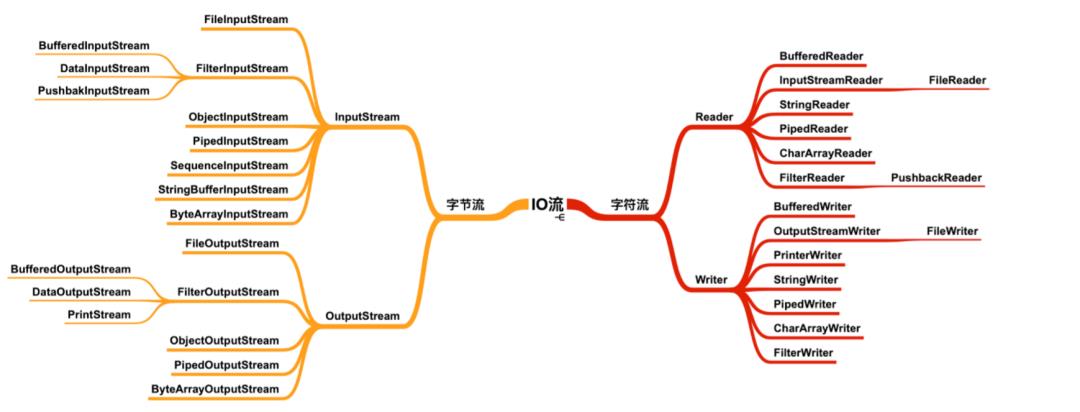
[来自于 cxuan 的 《Java基础核心总结》]
看到这么多的类是不是又开始觉得混乱了,不要慌,字节流和字符流下的输入流和输出流大部分都是一一对应的,有了上面的表格支撑,我们不需要再担心看见某个类会懵逼的情况了。
看到 Stream 就知道是字节流,看到 Reader / Writer 就知道是字符流。
这里还要额外补充一点:Java IO 提供了字节流转换为字符流的转换类,称为转换流。

注意字节流与字符流之间的转换是有严格定义的:
- 输入流:可以将字节流 => 字符流
- 输出流:可以将字符流 => 字节流
为什么在输入流不能字符流 => 字节流,输出流不能字节流 => 字符流?
在存储设备上,所有数据都是以字节为单位存储的,所以输入到内存时必定是以字节为单位输入,输出到存储设备时必须是以字节为单位输出,字节流才是计算机最根本的存储方式,而字符流是在字节流的基础上对数据进行转换,输出字符,但每个字符依旧是以字节为单位存储的。
1.3 字符流
Java 1.1对基本的I/O流类库进行了重大的修改。注意,Reader和Writer并不是为了替代InputStream和OutStream。
尽管一些原始的“流”类库不再被使用(如果使用它们,则会收到编译器的警告信息),但InputStream和OutputStream在以面向字节形式的I/O中仍可以提供极有价值的功能,Reader和Writer则提供兼容Unicode与面向字符的IO功能。
字符输入流和字节输入流的组成非常相似,字符输入流是对字节输入流的一层转换,所有文件的存储都是字节的存储,在磁盘上保留的不是文件的字符,而是先把字符编码成字节,再保存到文件中。在读取文件时,读入的也是一个一个字节组成的字节序列,而 Java 虚拟机通过将字节序列,按照2个字节为单位转换为 Unicode 字符,实现字节到字符的映射。

1.3.1 Reader
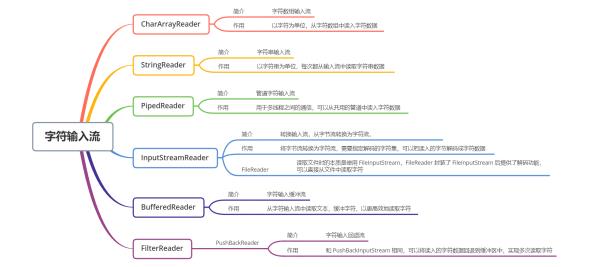
- Reader 是所有字符输入流的抽象基类
- CharArrayReader 和 StringReader 是两种基本的节点流,它们分别从读取 字符数组 和 字符串 数据,StringReader 内部是一个 String 变量值,通过遍历该变量的字符,实现读取字符串,本质上也是在读取字符数组
- PipedReader 用于多线程中的通信,从共用地管道中读取字符数据
- BufferedReader 是字符输入缓冲流,将读入的数据放入字符缓冲区中,实现高效地读取字符
- InputStreamReader 是一种转换流,可以实现从字节流转换为字符流,将字节数据转换为字符
1.3.2 Writer
Reader 是字符输出流的抽象基类,它内部的重要方法如下所示。
重要方法方法功能public void write(char cbuf[])将 cbuf 字符数组写出到输出流abstract public void write(char cbuf[], int off, int len)将指定范围的 cbuf 字符数组写出到输出流public void write(String str)将字符串 str 写出到输出流,str 内部也是字符数组public void write(String str, int off, int len)将字符串 str 的某一部分写出到输出流abstract public void flush()刷新,如果数据保存在缓冲区,调用该方法才会真正写出到指定位置abstract public void close()关闭流对象,每次 IO 执行完毕后都需要关闭流对象,释放系统资源

- Writer 是所有的输出字符流的抽象基类
- CharArrayWriter、StringWriter 是两种基本的节点流,它们分别向Char 数组、字符串中写入数据。StringWriter 内部保存了 StringBuffer 对象,可以实现字符串的动态增长
- PipedWriter 可以向共用的管道中写入字符数据,给其它线程读取。
- BufferedWriter 是缓冲输出流,可以将写出的数据缓存起来,缓冲区满时再调用 flush() 写出数据,减少 IO 次数。
- PrintWriter 和 PrintStream 类似,功能和使用也非常相似,只是写出的数据是字符而不是字节。
- OutputStreamWriter 将字符流转换为字节流,将字符写出到指定位置
1.4 字节流
在Java 1.0中,类库的设计者首先限定与输入有关的所有类读应该从InputStream继承,而与输出有关的所有类都应该从OutputStream继承。其中,InputStream的作用是用来表示从不同数据源产生输入的类。这些数据源包括:
(1) 字节数组;
(2) String对象;
(3) 文件;
(4) 管道;
(5) 一个由其他种类的流组成的序列,以便我们可以将它们收集合并到一个流内;
(6) 其他数据源。如网络传输数据。
OutputStream决定了输出所要去往的目标:字节数组、文件或管道。

1.4.1 InputStream
InputStream 是字节输入流的抽象基类,提供了通用的读方法,让子类使用或重写它们。
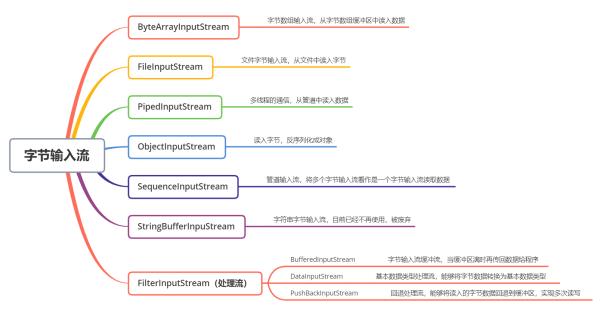
(1)ByteArrayInputStream
ByteArrayInputStream 内部包含一个 buf 字节数组缓冲区,该缓冲区可以从流中读取的字节数,使用 pos 指针指向读取下一个字节的下标位置,内部还维护了一个count 属性,代表能够读取 count 个字节。
必须保证 pos 严格小于 count,而 count 严格小于 buf.length 时,才能够从缓冲区中读取数据
(2)FileInputStream
文件输入流,从文件中读入字节,通常对文件的拷贝、移动等操作,可以使用该输入流把文件的字节读入内存中,然后再利用输出流输出到指定的位置上。
(3)PipedInputStream
管道输入流,它与 PipedOutputStream 成对出现,可以实现多线程中的管道通信。PipedOutputStream 中指定与特定的 PipedInputStream 连接,PipedInputStream 也需要指定特定的 PipedOutputStream 连接,之后输出流不断地往输入流的 buffer 缓冲区写数据,而输入流可以从缓冲区中读取数据。
(4)ObjectInputStream
对象输入流,用于对象的反序列化,将读入的字节数据反序列化为一个对象,实现对象的持久化存储。
(5)PushBackInputStream
它是 FilterInputStream 的子类,是一个处理流,它内部维护了一个缓冲数组buf。
- 在读入字节的过程中可以将读取到的字节数据回退给缓冲区中保存,下次可以再次从缓冲区中读出该字节数据。所以PushBackInputStream 允许多次读取输入流的字节数据,只要将读到的字节放回缓冲区即可。
需要注意的是如果回推字节时,如果缓冲区已满,会抛出 IOException 异常。
它的应用场景:对数据进行分类规整。
假如一个文件中存储了数字和字母两种类型的数据,我们需要将它们交给两种线程各自去收集自己负责的数据,如果采用传统的做法,把所有的数据全部读入内存中,再将数据进行分离,面对大文件的情况下,例如1G、2G,传统的输入流在读入数组后,由于没有缓冲区,只能对数据进行抛弃,这样每个线程都要读一遍文件。
使用 PushBackInputStream 可以让一个专门的线程读取文件,唤醒不同的线程读取字符:
- 第一次读取缓冲区的数据,判断该数据由哪些线程读取
- 回退数据,唤醒对应的线程读取数据
- 重复前两步
- 关闭输入流
到这里,你是否会想到 AQS 的 Condition 等待队列,多个线程可以在不同的条件上等待被唤醒。
(6)BufferedInputStream
缓冲流,它是一种处理流,对节点流进行封装并增强,其内部拥有一个 buffer 缓冲区,用于缓存所有读入的字节,当缓冲区满时,才会将所有字节发送给客户端读取,而不是每次都只发送一部分数据,提高了效率。
(7)DataInputStream
数据输入流,它同样是一种处理流,对节点流进行封装后,能够在内部对读入的字节转换为对应的 Java 基本数据类型。
(8)SequenceInputStream
将两个或多个输入流看作是一个输入流依次读取,该类的存在与否并不影响整个 IO 生态,在程序中也能够做到这种效果
(9)StringBufferInputStream
将字符串中每个字符的低 8 位转换为字节读入到字节数组中,目前已过期
InputStream 总结:
- InputStream 是所有输入字节流的抽象基类
- ByteArrayInputStream 和 FileInputStream 是两种基本的节点流,他们分别从字节数组 和 本地文件中读取数据
- DataInputStream、BufferedInputStream 和 PushBackInputStream 都是处理流,对基本的节点流进行封装并增强
- PipiedInputStream 用于多线程通信,可以与其它线程公用一个管道,读取管道中的数据。
- ObjectInputStream 用于对象的反序列化,将对象的字节数据读入内存中,通过该流对象可以将字节数据转换成对应的对象
1.4.2 OutputStream

OutputStream 中大多数的类和 InputStream 是对应的,只不过数据的流向不同而已。从上面的图可以看出:
- OutputStream 是所有输出字节流的抽象基类
- ByteArrayOutputStream 和 FileOutputStream 是两种基本的节点流,它们分别向字节数组和本地文件写出数据
- DataOutputStream、BufferedOutputStream 是处理流,前者可以将字节数据转换成基本数据类型写出到文件中;后者是缓冲字节数组,只有在缓冲区满时,才会将所有的字节写出到目的地,减少了 IO 次数。
- PipedOutputStream 用于多线程通信,可以和其它线程共用一个管道,向管道中写入数据
- ObjectOutputStream 用于对象的序列化,将对象转换成字节数组后,将所有的字节都写入到指定位置中
- PrintStream 在 OutputStream 基础之上提供了增强的功能,即可以方便地输出各种类型的数据(而不仅限于byte型)的格式化表示形式,且 PrintStream 的方法从不抛出 IOEception,其原理是写出时将各个数据类型的数据统一转换为 String 类型,我会在讲解完
1.5 字节流和字符流转换
Java虽然支持字节流和字符流,但有时必须把来自于“字节”层次结构中的类和“字符”层次结构中的类结合起来使用。为了实现这个目的,要用到“适配器”(apapter)类:InputStreamReader可以把InputStream转换为Reader,而OutputStreamWriter可以把OutputStream转换为Writer。其中:
InputSreamReader用于将一个字节流中的字节解码成字符。有两个构造方法:
// 功能:用默认字符集创建一个InputStreamReader对象
InputStreamReader(InputStream in);
// 功能:接收已指定字符集名的字符串,并用该字符创建对象
InputStreamReader(InputStream in, String CharsetName);
OutputStream用于将写入的字符编码成字节后写入一个字节流。同样有两个构造方法:
// 功能:用默认字符集创建一个OutputStreamWriter对象;
OutputStreamWriter(OutputStream out);
// 功能:接收已指定字符集名的字符串,并用该字符集创建OutputStreamWrite对象
OutputStreamWriter(OutputStream out,String CharSetName);
为了避免频繁的转换字节流和字符流,对以上两个类进行了封装。BufferedWriter类封装了OutputStreamWriter类;BufferedReader类封装了InputStreamReader类;封装格式如下:
BufferedWriter out=new BufferedWriter(new OutputStreamWriter(System.out));
BufferedReader in= new BufferedReader(new InputStreamReader(System.in);
1.6 字节流和字符流对比
设计Reader和Writer继承层次结构主要是为了国际化。老的IO流继承层次结构仅支持8位字节流,并且不能很好地处理16位Unicode字符。由于Unicode用于字符国际化,所以添加Reader和Writer继承层次结构就是为了所有的I/O操作中都支持Unicode。另外,新类库的设计使得它的操作比旧类库更快。
二、File 文件
java.ui.File类
Java 提供了 File类,它指向计算机操作系统中的文件和目录,通过该类只能访问文件和目录,无法访问内容。 它内部主要提供了 3种操作:
- 访问文件的属性:绝对路径、相对路径、文件名······
- 文件检测:是否文件、是否目录、文件是否存在、文件的读/写/执行权限······
- 操作文件:创建目录、创建文件、删除文件······
上面举例的操作都是在开发中非常常用的,File 类远不止这些操作,更多的操作可以直接去 API 文档中根据需求查找。
访问文件的属性:

文件检测:

操作文件:

多了解一些:
文件的读/写/执行权限,在 Windows 中通常表现不出来,而在 Linux 中可以很好地体现这一点,原因是 Linux 有严格的用户权限分组,不同分组下的用户对文件有不同的操作权限,所以这些方法在 Linux 下会比在 Windows 下更好理解。
下图是 redis 文件夹中的一些文件的详细信息,被红框标注的是不同用户的执行权限:
- r(Read):代表该文件可以被当前用户读,操作权限的序号是 4
- w(Write):代表该文件可以被当前用户写,操作权限的序号是 2
- x(Execute):该文件可以被当前用户执行,操作权限的序号是 1
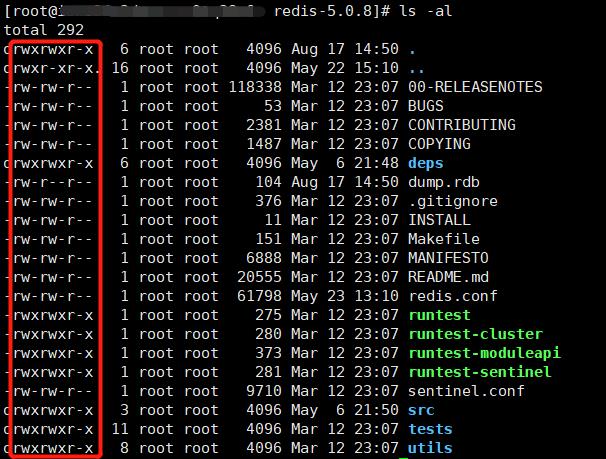
root root 分别代表:**当前文件的所有者,当前文件所属的用户分组。**Linux 下文件的操作权限分为三种用户:
- **文件所有者:**拥有的权限是红框中的前三个字母,-代表没有某个权限;
- **文件所在组的所有用户:**拥有的权限是红框中的中间三个字母;
- **其它组的所有用户:**拥有的权限是红框中的最后三个字母;
三、BIO(同步阻塞 I/O)
- 传统的 BIO 是以流为基本单位处理数据的,想象成水流,一点点地传输字节数据,IO 流传输的过程永远是以字节形式传输。
- 字节流和字符流的区别在于操作的数据单位不相同,字符流是通过将字节数据通过字符集映射成对应的字符,字符流本质上也是字节流。
BIO 和 NIO 的主要区别就可以用下面这个表格简单概括。

四、NIO(异步阻塞I/O)
它能够解决传统 BIO 的痛点:阻塞。
- BIO 如果遇到 IO 阻塞时,线程将会被挂起,直到 IO 完成后才唤醒线程,线程切换带来了额外的开销。
- BIO 中每个 IO 都需要有对应的一个线程去专门处理该次 IO 请求,会让服务器的压力迅速提高。
NIO和BIO的区别
BIO 是面向流的 IO,它建立的通道都是单向的,所以输入和输出流的通道不相同,必须建立2个通道,通道内的都是传输0101001···的字节数据。

而在 NIO 中,不再是面向流的 IO 了,而是面向缓冲区,它会建立一个通道(Channel),该通道我们可以理解为铁路,该铁路上可以运输各种货物,而通道上会有一个缓冲区(Buffer)用于存储真正的数据,缓冲区我们可以理解为一辆火车。
通道(铁路)只是作为运输数据的一个连接资源,而真正存储数据的是缓冲区(火车)。即通道负责传输,缓冲区负责存储。

理解了上面的图之后,BIO 和 NIO 的主要区别就可以用下面这个表格简单概括。
BIONIO面向流(Stream)面向缓冲区(Buffer)单向通道双向通道阻塞 IO非阻塞 IO选择器(Selectors)
缓冲区(Buffer)
缓冲区是存储数据的区域,在 Java 中,缓冲区就是数组,为了可以操作不同数据类型的数据,Java 提供了许多不同类型的缓冲区,除了布尔类型以外,其它基本数据类型都有对应的缓冲区数组对象。

缓冲区读写数据的两个核心方法:
- put():将数据写入到缓冲区中
- get():从缓冲区中读取数据
缓冲区的重要属性:
- capacity:缓冲区中最大存储数据的容量,一旦声明则无法改变
- limit:表示缓冲区中可以操作数据的大小,limit 之后的数据无法进行读写。必须满足 limit <= capacity
- position:当前缓冲区中正在操作数据的下标位置,必须满足 position <= limit
- mark:标记位置,调用 reset() 将 position 位置调整到 mark 属性指向的下标位置,实现多次读取数据
缓冲区为高效读写数据而提供的其它辅助方法:
- flip():可以实现读写模式的切换,我们可以看看里面的源码
public final Buffer flip() {
limit = position; position = 0;
mark = -1;
return this;
}
调用 flip() 会将可操作的大小 limit 设置为当前写的位置,操作数据的起始位置 position 设置为 0,即从头开始读取数据。
- rewind():可以将 position 位置设置为 0,再次读取缓冲区中的数据
- clear():清空整个缓冲区,它会将 position 设置为 0,limit 设置为 capacity,可以写整个缓冲区
来看一个简单的例子
public Class Main {
public static void main(String[] args) { // 分配内存大小为11的整型缓存区
IntBuffer buffer = IntBuffer.allocate(11);
// 往buffer里写入2个整型数据
for (int i = 0; i < 2; ++i) {
int randomNum = new SecureRandom().nextInt();
buffer.put(randomNum);
}
// 将Buffer从写模式切换到读模式
buffer.flip();
System.out.println("position >> " + buffer.position()
+ "limit >> " + buffer.limit()
+ "capacity >> " + buffer.capacity());
// 读取buffer里的数据
while (buffer.hasRemaining()) {
System.out.println(buffer.get());
}
System.out.println("position >> " + buffer.position()
+ "limit >> " + buffer.limit()
+ "capacity >> " + buffer.capacity());
}}
执行结果如下图所示,首先我们往缓冲区中写入 2 个数据,position 在写模式下指向下标 2,然后调用 flip() 方法切换为读模式,limit 指向下标 2,position 从 0 开始读数据,读到下标为 2 时发现到达 limit 位置,不可继续读。

整个过程可以用下图来理解,调用 flip() 方法以后,读出数据的同时 position 指针不断往后挪动,到达 limit 指针的位置时,该次读取操作结束。

- 介绍完缓冲区后,我们知道它是存储数据的空间,进程可以将缓冲区中的数据读取出来,也可以写入新的数据到缓冲区,那缓冲区的数据从哪里来,又怎么写出去呢?接下来我们需要学习传输数据的介质:通道(Channel)
通道(Channel)
通道是作为一种连接资源,作用是传输数据,而真正存储数据的是缓冲区。
通道是可以双向读写的,传统的 BIO 需要使用输入/输出流表示数据的流向,在 NIO 中可以减少通道资源的消耗。
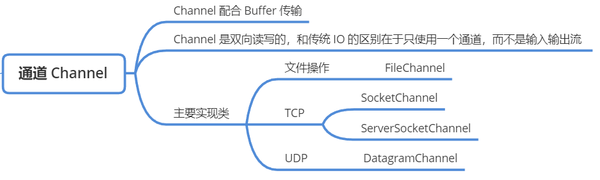
通道类都保存在 java.nio.channels 包下,我们日常用到的几个重要的类有 4 个:
- IO 通道类型具体类文件 IOFileChannel(用于文件读写、操作文件的通道)
- TCP 网络 iosocketChannel(用于读写数据的 TCP 通道)、
- ServerSocketChannel(监听客户端的连接)
- UDP 网络 IODatagramChannel(收发 UDP 数据报的通道)
可以通过 getChannel() 方法获取一个通道,支持获取通道的类如下:
- 文件 IO:FileInputStream、FileOutputStream、RandomAccessFile
- TCP 网络 IO:Socket、ServerSocket
- UDP 网络 IO:DatagramSocket
示例:文件拷贝案例
我们来看一个利用通道拷贝文件的例子,需要下面几个步骤:
- 打开原文件的输入流通道,将字节数据读入到缓冲区中
- 打开目的文件的输出流通道,将缓冲区中的数据写到目的地
- 关闭所有流和通道(重要!)
这是一张小菠萝的照片,它存在于d:\\小菠萝\\文件夹下,我们将它拷贝到 d:\\小菠萝分身\\ 文件夹下。
public class Test {
/** 缓冲区的大小 */
public static final int SIZE = 1024;
public static void main(String[] args) throws IOException {
// 打开文件输入流
FileChannel inChannel = new FileInputStream("d:\\小菠萝\\小菠萝.jpg").getChannel();
// 打开文件输出流
FileChannel outChannel = new FileOutputStream("d:\\小菠萝分身\\小菠萝-拷贝.jpg").getChannel();
// 分配 1024 个字节大小的缓冲区
ByteBuffer dsts = ByteBuffer.allocate(SIZE);
// 将数据从通道读入缓冲区
while (inChannel.read(dsts) != -1) {
// 切换缓冲区的读写模式
dsts.flip();
// 将缓冲区的数据通过通道写到目的地
outChannel.write(dsts);
// 清空缓冲区,准备下一次读
dsts.clear();
}
inChannel.close();
outChannel.close();
}
}
我画了一张图帮助你理解上面的这一个过程。

BIO和NIO拷贝文件的区别
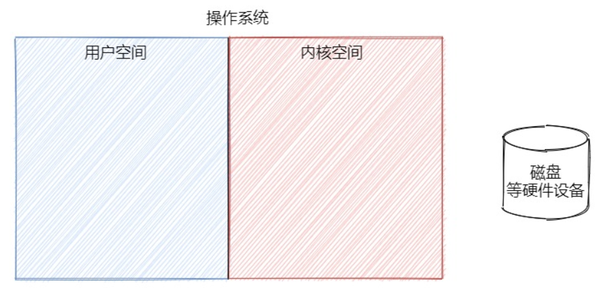
操作系统最重要的就是内核,它既可以访问受保护的内存,也可以访问底层硬件设备,所以为了保护内核的安全,操作系统将底层的虚拟空间分为了用户空间和内核空间,其中用户空间就是给用户进程使用的,内核空间就是专门给操作系统底层去使用的。
接下来,有一个 Java 进程希望把小菠萝这张图片从磁盘上拷贝,那么内核空间和用户空间都会有一个缓冲区
这张照片就会从磁盘中读出到内核缓冲区中保存,然后操作系统将内核缓冲区中的这张图片字节数据拷贝到用户进程的缓冲区中保存下来,
对应着下面这幅图

然后用户进程会希望把缓冲区中的字节数据写到磁盘上的另外一个地方,会将数据拷贝到 Socket 缓冲区中,最终操作系统再将 Socket 缓冲区的数据写到磁盘的指定位置上。
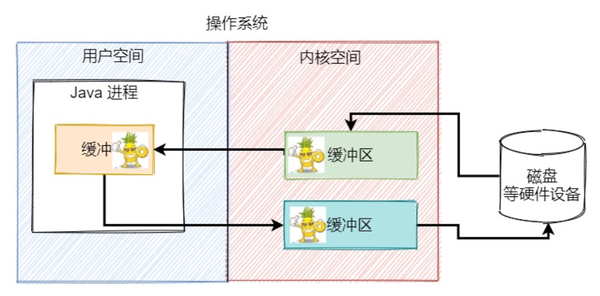
这一轮操作下来,我们数数经过了几次数据的拷贝?4 次。有 2 次是内核空间和用户空间之间的数据拷贝,这两次拷贝涉及到用户态和内核态的切换,需要CPU参与进来,进行上下文切换。而另外 2 次是硬盘和内核空间之间的数据拷贝,这个过程利用到 DMA与系统内存交换数据,不需要 CPU 的参与。
导致 IO 性能瓶颈的原因:内核空间与用户空间之间数据过多无意义的拷贝,以及多次上下文切换
操作状态用户进程请求读取数据用户态 -> 内核态操作系统内核返回数据给用户进程内核态 -> 用户态用户进程请求写数据到硬盘用户态 -> 内核态操作系统返回操作结果给用户进程内核态 -> 用户态
- 在用户空间与内核空间之间的操作,会涉及到上下文的切换,这里需要 CPU 的干预,而数据在两个空间之间来回拷贝,也需要 CPU 的干预,这无疑会增大 CPU 的压力,NIO 是如何减轻 CPU 的压力?运用操作系统的零拷贝技术。
操作系统的零拷贝
零拷贝。零拷贝指的是内核空间与用户空间之间的零次拷贝。
零拷贝可以说是 IO 的一大救星,操作系统底层有许多种零拷贝机制,我这里仅针对 Java NIO 中使用到的其中一种零拷贝机制展开讲解。
在 Java NIO 中,零拷贝是通过用户空间和内核空间的缓冲区共享一块物理内存实现的,也就是说上面的图可以演变成这个样子。

这时,无论是用户空间还是内核空间操作自己的缓冲区,本质上都是操作这一块共享内存中的缓冲区数据,省去了用户空间和内核空间之间的数据拷贝操作。
现在我们重新来拷贝文件,就会变成下面这个步骤:
- 用户进程通过系统调用 read() 请求读取文件到用户空间缓冲区(第一次上下文切换),用户态 -> 核心态,数据从硬盘读取到内核空间缓冲区中(第一次数据拷贝)
- 系统调用返回到用户进程(第二次上下文切换),此时用户空间与内核空间共享这一块内存(缓冲区),所以不需要从内核缓冲区拷贝到用户缓冲区
- 用户进程发出 write() 系统调用请求写数据到硬盘上(第三次上下文切换),此时需要将内核空间缓冲区中的数据拷贝到内核的 Socket 缓冲区中(第二次数据拷贝)
- 由 DMA 将 Socket 缓冲区的内容写到硬盘上(第三次数据拷贝),write() 系统调用返回(第四次上下文切换)
整个过程就如下面这幅图所示。

图中,需要 CPU 参与工作的步骤只有第③个步骤,对比于传统的 IO,CPU 需要在用户空间与内核空间之间参与拷贝工作,需要无意义地占用 2 次 CPU 资源,导致 CPU 资源的浪费。
下面总结一下操作系统中零拷贝的优点:
- 降低 CPU 的压力:避免 CPU 需要参与内核空间与用户空间之间的数据拷贝工作
- 减少不必要的拷贝:避免用户空间与内核空间之间需要进行数据拷贝
上面的图示可能并不严谨,对于你理解零拷贝会有一定的帮助,关于零拷贝的知识点可以去查阅更多资料哦,这是一门大学问。
- 介绍完通道后,我们知道它是用于传输数据的一种介质,而且是可以双向读写的,那么如果放在网络 IO 中,这些通道如果有数据就绪时,服务器是如何发现并处理的呢?接下来我们去学习 NIO 中的最后一个重要知识点:选择器(Selector)
选择器(Selectors)
选择器是提升 IO 性能的灵魂之一,它底层利用了多路复用 IO机制,让选择器可以监听多个 IO 连接,根据 IO 的状态响应到服务器端进行处理。通俗地说:选择器可以监听多个 IO 连接,而传统的 BIO 每个 IO 连接都需要有一个线程去监听和处理。

图中很明显的显示了在 BIO 中,每个 Socket 都需要有一个专门的线程去处理每个请求,而在 NIO 中,只需要一个 Selector 即可监听各个 Socket 请求,而且 Selector 并不是阻塞的,所以不会因为多个线程之间切换导致上下文切换带来的开销。

在 Java NIO 中,选择器是使用 Selector 类表示,Selector 可以接收各种 IO 连接,在 IO 状态准备就绪时,会通知该通道注册的 Selector,Selector 在下一次轮询时会发现该 IO 连接就绪,进而处理该连接。
Selector 选择器主要用于网络 IO当中,在这里我会将传统的 BIO Socket 编程和使用 NIO 后的 Socket 编程作对比,分析 NIO 为何更受欢迎。首先先来了解 Selector 的基本结构。
重要方法方法解析open()打开一个 Selector 选择器int select()阻塞地等待就绪的通道int select(long timeout)最多阻塞 timeout 毫秒,如果是 0 则一直阻塞等待,如果是 1 则代表最多阻塞 1 毫秒int selectNow()非阻塞地轮询就绪的通道
在这里,你会看到 select() 和它的重载方法是会阻塞的,如果用户进程轮询时发现没有就绪的通道,操作系统有两种做法:
- 一直等待直到一个就绪的通道,再返回给用户进程
- 立即返回一个错误状态码给用户进程,让用户进程继续运行,不会阻塞
这两种方法对应了同步阻塞 IO 和 同步非阻塞 IO ,这里读者的一点小的观点,请各位大神批判阅读
- Java 中的 NIO 不能真正意义上称为 Non-Blocking IO,我们通过 API 的调用可以发现,select() 方法还是会存在阻塞的现象,根据传入的参数不同,操作系统的行为也会有所不同,不同之处就是阻塞还是非阻塞,所以我更倾向于把 NIO 称为 New IO,因为它不仅提供了 Non-Blocking IO,而且保留原有的 Blocking IO 的功能。
了解了选择器之后,它的作用就是:监听多个 IO 通道,当有通道就绪时选择器会轮询发现该通道,并做相应的处理。那么 IO 状态分为很多种,我们如何去识别就绪的通道是处于哪种状态呢?在 Java 中提供了选择键(SelectionKey)。
选择键(SelectionKey)
在 Java 中提供了 4 种选择键:
- SelectionKey.OP_READ:套接字通道准备好进行读操作
- SelectionKey.OP_WRITE:套接字通道准备好进行写操作
- SelectionKey.OP_ACCEPT:服务器套接字通道接受其它通道
- SelectionKey.OP_CONNECT:套接字通道准备完成连接
在 SelectionKey 中包含了许多属性
- channel:该选择键绑定的通道
- selector:轮询到该选择键的选择器
- readyOps:当前就绪选择键的值
- interesOps:该选择器对该通道感兴趣的所有选择键
选择键的作用是:在选择器轮询到有就绪通道时,会返回这些通道的就绪选择键(SelectionKey),通过选择键可以获取到通道进行操作。
简单了解了选择器后,我们可以结合缓冲区、通道和选择器来完成一个简易的聊天室应用。
示例:简易的客户端服务器通信
- 先说明,这里的代码非常的臭和长,不推荐细看,直接看注释附近的代码即可。
我们在服务器端会开辟两个线程
- Thread1:专门监听客户端的连接,并把通道注册到客户端选择器上
- Thread2:专门监听客户端的其它 IO 状态(读状态),当客户端的 IO 状态就绪时,该选择器会轮询发现,并作相应处理
public class NIOServer {
Selector serverSelector = Selector.open();
Selector clientSelector = Selector.open();
public static void main(String[] args) throws IOException {
NIOServer server = nwe NIOServer();
new Thread(() -> {
try { // 对应IO编程中服务端启动
ServerSocketChannel listenerChannel = ServerSocketChannel.open();
listenerChannel.socket().bind(new InetSocketAddress(3333));
listenerChannel.configureBlocking(false);
listenerChannel.register(serverSelector, SelectionKey.OP_ACCEPT); server.acceptListener();
} catch (IOException ignored) {
}
}).start();
new Thread(() -> {
try {
server.clientListener();
} catch (IOException ignored) {
}
}).start();
}}
// 监听客户端连接
public void acceptListener() {
while (true) {
if (serverSelector.select(1) > 0) {
Set<SelectionKey> set = serverSelector.selectedKeys();
Iterator<SelectionKey> keyIterator = set.iterator();
while (keyIterator.hasNextjava IO模型(BIO,NIO,AIO)