通过Logstash全量和增量同步Mysql一对多关系到Elasticsearch
Posted 陆小叁
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了通过Logstash全量和增量同步Mysql一对多关系到Elasticsearch相关的知识,希望对你有一定的参考价值。
前言
在实际开发项目过程当中,难免会使用到Elasticsearch做搜索。文章描述从mysql通过Logstash实时同步到Elasticsearch,下面就开始来进行实现吧!具体的Elasticsearch+Logstash+kibana搭建,请移步到 ELK搭建步骤。
实现方案
本人总结了两种实现方案来实现mysql到es的同步。
- 使用Elastic官方提供的 Logstash 来实现Mysql的全量和增量同步(根据时间戳或者自增id)。
- 使用Elastic 官方提供的 Logstash 来实现全量同步,后续的数据库表更新、删除、修改等通过阿里开源的框架canal实现(增量同步)。 canal伪装成mysql的从节点,通过binlog日志文件进行同步,通过Java程序进行监听,同步到Elasticsearch当中。
本次介绍通过 Elastic 官方提供的 Logstash 来实现Mysql的全量和增量同步。
全量和增量同步
先看Mysql表的关系
一个是主表:news 资讯文章表,表内容如下:

一个是从表:custom_infomation 定制信息表,与news 成 一对多的关系,一条文章对应多条定制信息。表内容如下:

描述:custom_information表中的item_id和news表中的id有关联关系。
用JSON数据结构来描述一对多的关系,如下:
{
"id":"15c7ee7a5dc411ea9bc2fa163e0c8256",
"title":"“宅经济”进入数字化时代",
"source":"人民日报",
"customList":[
{
"secondLevel":"32552",
"isRelEnterprise":"0",
"secondLevelName":"济南",
"moduleType":"1",
"customName":"地区1",
"firstLevel":"37200",
"firstLevelName":"山东",
"customId":"1",
"detId":"1"
},
{
"secondLevel":"222",
"isRelEnterprise":"0",
"secondLevelName":"林业1",
"moduleType":"1",
"customName":"行业1",
"firstLevel":"11",
"firstLevelName":"林业",
"customId":"2",
"detId":"3"
}
]
}
这里需要和Elasticsearch做映射关系。在Elasticsearch中也是一对多的关系。大致是这样的结构,这里采用的是Elasticsearch中的nested类型来实现。

创建所需索引(采用静态mapping映射)
PUT app-article-link
{
"mappings" : {
"properties" : {
"address" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"customList" : {
"type" : "nested",
"properties" : {
"customId" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"customName" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"detId" : {
"type" : "keyword"
},
"firstLevel" : {
"type" : "keyword"
},
"firstLevelName" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"isRelEnterprise" : {
"type" : "keyword"
},
"moduleType" : {
"type" : "keyword"
},
"secondLevel" : {
"type" : "keyword"
},
"secondLevelName" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
},
"custom_list" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"detail" : {
"type" : "text",
"analyzer" : "ik_max_word",
"search_analyzer" : "ik_smart"
},
"endTime" : {
"type" : "keyword"
},
"id" : {
"type" : "keyword"
},
"industryName" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"isDelete" : {
"type" : "keyword"
},
"price" : {
"type" : "keyword"
},
"publishDate" : {
"type" : "keyword"
},
"relevanceType" : {
"type" : "keyword"
},
"savePath" : {
"type" : "keyword"
},
"source" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
},
"suggest" : {
"type" : "completion",
"analyzer" : "simple",
"preserve_separators" : true,
"preserve_position_increments" : true,
"max_input_length" : 50
}
},
"analyzer" : "ik_max_word",
"search_analyzer" : "ik_smart"
},
"startTime" : {
"type" : "keyword"
},
"summary" : {
"type" : "text",
"analyzer" : "ik_max_word",
"search_analyzer" : "ik_smart"
},
"techFieldName" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"title" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
},
"suggest" : {
"type" : "completion",
"analyzer" : "simple",
"preserve_separators" : true,
"preserve_position_increments" : true,
"max_input_length" : 50
}
},
"analyzer" : "ik_max_word",
"search_analyzer" : "ik_smart"
},
"update_time" : {
"type" : "keyword"
},
"videoStatus" : {
"type" : "keyword"
}
}
}
}
以下是Logstash 相关配置操作:
由于上面描述的数据库表是一对多的关系,这里选择先建立一个视图,原因是会通过数据库表的最新时间字段来作为临界点进行数据同步(关键点是找出主表和从表的最新时间点)。视图创建sql如下:
SELECT
t.id,
t.title,
t.source,
'8' AS relevanceType ,
date_format( greatest( `t`.`update_time`, ifnull( `i`.`update_time`, '1970' )), '%Y-%m-%d %H:%i:%s' ) AS `update_time`
FROM
`news` t
LEFT JOIN custom_information i
ON t.id=i.item_id
AND i.is_delete='0'
AND i.module_type='8'
WHERE
t.state = '0'
AND t.publish_status='3'
AND t.relevance_type='2'
上面的update_time为两表中的最新时间。
在logstash congf目录下创建news.conf,内容如下:
input {
jdbc {
jdbc_driver_library => "/opt/apps/logstash/lib/mysql-connector-java-8.0.13.jar"
jdbc_driver_class => "com.mysql.cj.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://192.168.0.178:3306/test?characterEncoding=utf8&useSSL=false&serverTimezone=UTC&rewriteBatchedStatements=true"
jdbc_user => "root"
jdbc_password => "123456"
connection_retry_attempts => "3"
jdbc_validation_timeout => "3600"
jdbc_paging_enabled => "true"
jdbc_page_size => "500"
statement_filepath => "/opt/apps/logstash/sql/news.sql"
use_column_value => true
lowercase_column_names => false
tracking_column => "update_time"
tracking_column_type => "timestamp"
record_last_run => true
last_run_metadata_path => "/opt/apps/logstash/station/news.txt"
clean_run => false
schedule => "*/5 * * * * *"
type => "news"
}
}
filter {
aggregate {
task_id => "%{id}"
code => "
map['id'] = event.get('id')
map['title'] = event.get('title')
map['source'] = event.get('source')
map['custom_list'] ||=[]
map['customList'] ||=[]
if (event.get('detId') != nil)
if !(map['custom_list'].include? event.get('detId'))
map['custom_list'] << event.get('detId')
map['customList'] << {
'detId' => event.get('detId'),
'moduleType' => event.get('moduleType'),
'customId' => event.get('customId'),
'customName' => event.get('customName'),
'firstLevel' => event.get('firstLevel'),
'firstLevelName' => event.get('firstLevelName'),
'secondLevel' => event.get('secondLevel'),
'secondLevelName' => event.get('secondLevelName'),
'isRelEnterprise' => event.get('isRelEnterprise')
}
end
end
event.cancel()
"
push_previous_map_as_event => true
timeout => 5
}
mutate {
}
mutate {
remove_field => ["@timestamp","@version"]
}
}
output {
elasticsearch {
document_id => "%{id}"
document_type => "_doc"
index => "app-article-link"
hosts => ["http://192.168.0.178:9200"]
}
stdout{
codec => rubydebug
}
}
input{} 中
statement_filepath 为sql语句位置,
last_run_metadata_path 记录最新时间位置,下次从这个时间点开始更新,
tracking_column 为更新的时间字段,
schedule 执行的时间 上述中每个五秒钟执行一次,
执行的sql:
SELECT
n.id,
n.title,
n.source
FROM
news_view n
order by n.update_time
编辑conf/pipelines.yml
[root@localhost config]# vi pipelines.yml
# List of pipelines to be loaded by Logstash
#
# This document must be a list of dictionaries/hashes, where the keys/values are pipeline settings.
# Default values for omitted settings are read from the `logstash.yml` file.
# When declaring multiple pipelines, each MUST have its own `pipeline.id`.
#
# Example of two pipelines:
#
# - pipeline.id: test
# pipeline.workers: 1
# pipeline.batch.size: 1
# config.string: "input { generator {} } filter { sleep { time => 1 } } output { stdout { codec => dots } }"
# - pipeline.id: another_test
# queue.type: persisted
# path.config: "/tmp/logstash/*.config"
#
#- pipeline.id: news_table
# path.config: /opt/apps/logstash/config/addmysql.conf
#- pipeline.id: news_table3
# path.config: /opt/apps/logstash/config/addmysql3.conf
- pipeline.id: news
path.config: /opt/apps/logstash/config/news.conf
执行./bin/logstash
[root@localhost logstash]# ./bin/logstash
kibana常用查询
精确查询
GET /app-article-link/_search
{
"_source": ["id","title","source","customList","update_time","savePath","isDelete"],
"query": {
"bool": {
"must": [
{ "match": { "id": "15c7ee7a5dc411ea9bc2fa163e0c8256" }}
]
}}}
nested查询,mapping映射类型必须为nested
GET app-article-link/_search
{
"query": {
"bool": {
"must": [
{
"nested": {
"path": "customList",
"query": {
"bool": {
"must": [
{ "match": { "customList.customId": "1" }},
{ "match": { "customList.secondLevel": "5552" }}
]
}}}}
]
}}}
自动补全查询,字段类型必须为completion
GET app-article-link/_search
{
"_source": ["source","title","detail"],
"suggest": {
"title_suggest": {
"prefix": "国家知识产",
"completion": {
"field": "title.suggest",
"size": 10,
"skip_duplicates": true
}
}
}
}
高亮查询
GET app-article-link/_search
{
"query": {
"multi_match": {
"query": "安徽",
"fields": ["title"]
}
},
"highlight": {
"pre_tags": "<span class='highLight'>",
"post_tags": "</span>",
"fields": {
"title": {}
}
}
}
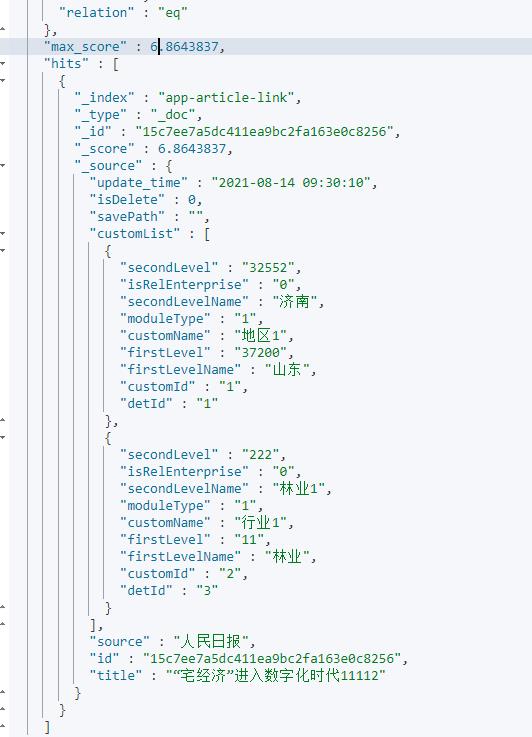
最终通过Logstash导入的数据格式:
SpringBoot集成Elasticearch
搭建的Elasticsearch为7.8.1版本。
引入依赖
<!-- es搜索 -->
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.8.1</version>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>7.8.1</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client</artifactId>
<version>7.8.1<以上是关于通过Logstash全量和增量同步Mysql一对多关系到Elasticsearch的主要内容,如果未能解决你的问题,请参考以下文章