基于DolphinScheduler的使用浅谈数仓分层及模型设计
Posted 学而知之@
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于DolphinScheduler的使用浅谈数仓分层及模型设计相关的知识,希望对你有一定的参考价值。
前言:本文旨在简单介绍DS的概述和架构上的设计,对其安装等不做展开介绍。之前了解了一下,很多小伙伴也在使用该产品。我呢,也是到现在公司后才开始接触并使用,对其 “开发” 的还不够深,这里根据官方文档和项目中的实践和大家简单分享。欢迎大家批评指正,敬礼!

一、简介
DS是分布式易扩展的可视化工作流任务调度平台。
Apache DolphinScheduler是一个分布式去中心化,易扩展的可视化DAG工作流任务调度平台。致力于解决数据处理流程中错综复杂的依赖关系,使调度系统在数据处理流程中开箱即用。
二、架构图

三、架构设计
1、名词解释
1.1、DAG:
相信大家对这个次并不陌生,在spark和flink中都有这个定义。在DS中,工作流中的Task任务以有向无环图的形式组装起来,从入度为零的节点进行拓扑遍历,直到无后继节点为止。举例如下图:

1.2、任务类型:
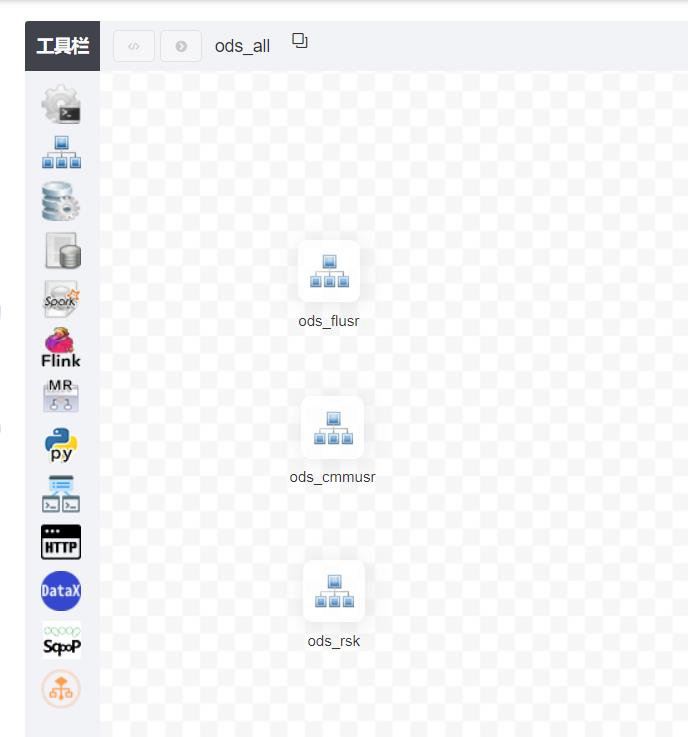
目前支持有SHELL、SQL、SUB_PROCESS(子流程)、PROCEDURE、MR、SPARK、PYTHON、DEPENDENT(依赖),同时计划支持动态插件扩展,注意:其中子 SUB_PROCESS 也是一个单独的流程定义,是可以单独启动执行的。举例如下图:
注:左侧边栏看大的都是可调度执行的组件,畅用无限~
1.3、调度方式:
系统支持基于 cron 表达式的定时调度和手动调度。
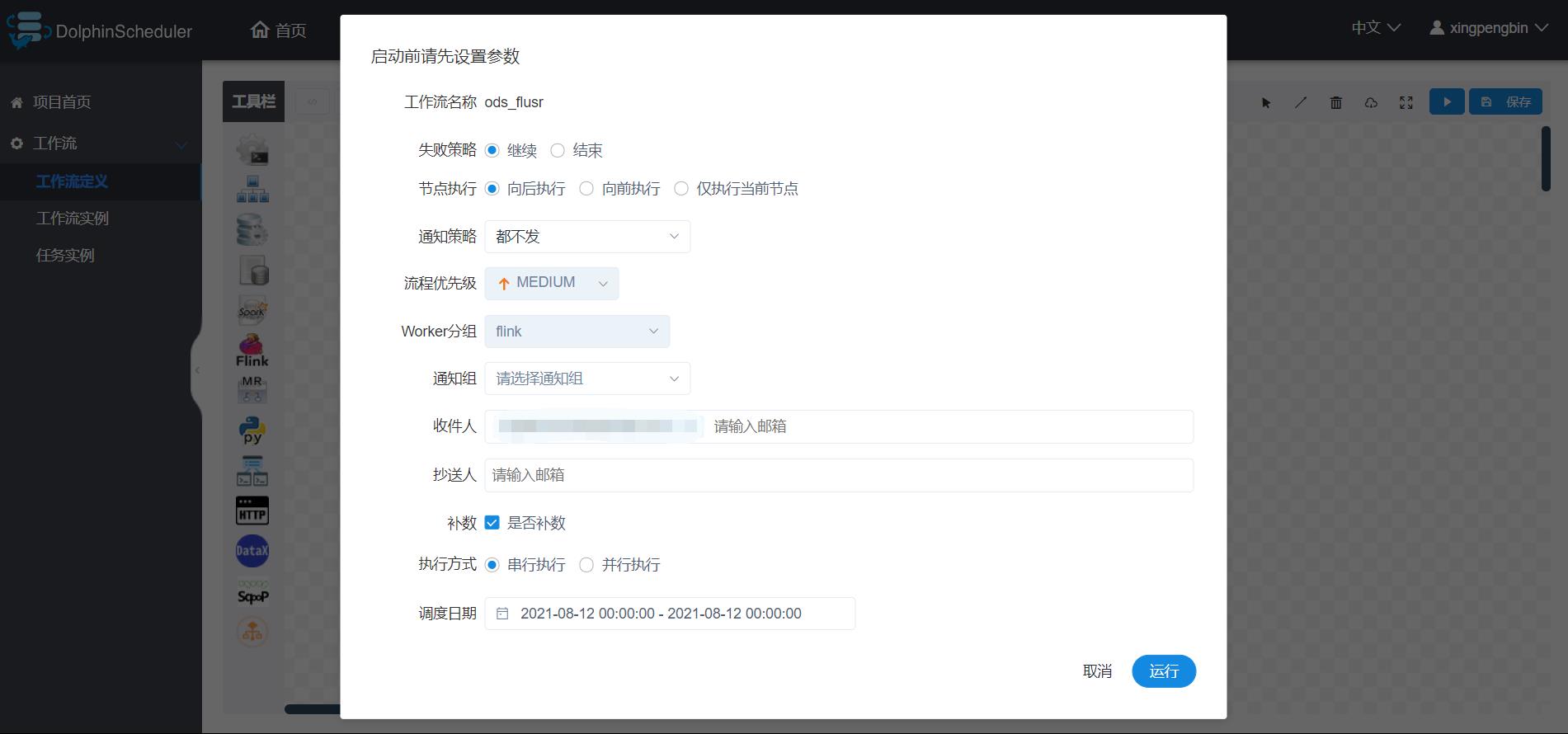
命令类型支持:启动工作流、从当前节点开始执行、恢复被容错的工作流、恢复暂停流程、从失败节点开始执行、补数、定时、重跑、暂停、停止、恢复等待线程。其中 恢复被容错的工作流 和 恢复等待线程 两种命令类型是由调度内部控制使用,外部无法调用。举例如下图:

1.4、依赖:
系统不单单支持 DAG 简单的前驱和后继节点之间的依赖,同时还提供任务依赖节点,支持流程间的自定义任务依赖。说到依赖想重点和兄弟们讨论下这个问题,但是文字表达起来比较费劲,希望各位兄弟可以留言,咱们针对具体问题一起聊聊。
1.5、补数:
补历史数据,支持区间并行和串行两种补数方式
1.6、邮件告警:
支持 SQL任务 查询结果邮件发送,流程实例运行结果邮件告警及容错告警通知
下图:是单独执行任务时进行的相关配置,我个人感觉补数功能是比较牛X的,用好系统时间的变量,造作起来吧(我也是这两天遇到了这样的需求,才 “开发出了这个功能”)。欢迎兄弟们一起讨论。
2、系统架构
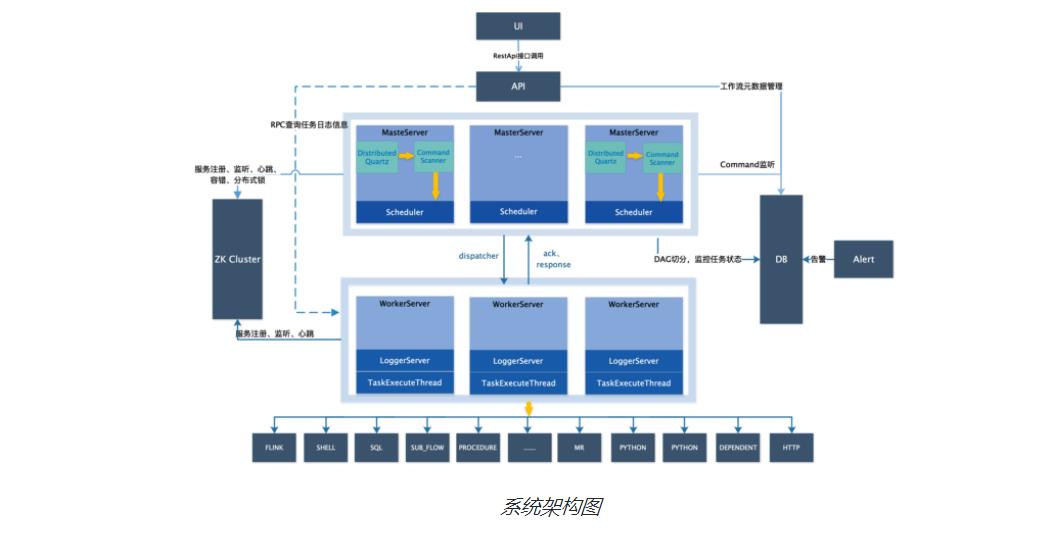
2.1、系统架构图
2.2、架构组成、简介
-
MasterServer
MasterServer采用分布式无中心设计理念,MasterServer主要负责 DAG 任务切分、任务提交监控,并同时监听其它MasterServer和WorkerServer的健康状态。 MasterServer服务启动时向Zookeeper注册临时节点,通过监听Zookeeper临时节点变化来进行容错处理。 MasterServer基于netty提供监听服务。
-
WorkerServer
WorkerServer也采用分布式无中心设计理念,WorkerServer主要负责任务的执行和提供日志服务。 WorkerServer服务启动时向Zookeeper注册临时节点,并维持心跳。 WorkerServer基于netty提供监听服务。
-
ZooKeeper
ZooKeeper服务,系统中的MasterServer和WorkerServer节点都通过ZooKeeper来进行集群管理和容错。另外系统还基于ZooKeeper进行事件监听和分布式锁。
-
Task Queue
提供任务队列的操作,目前队列也是基于Zookeeper来实现。由于队列中存的信息较少,不必担心队列里数据过多的情况。
-
Alert
提供告警相关接口,接口主要包括告警两种类型的告警数据的存储、查询和通知功能。其中通知功能又有邮件通知
-
API
API接口层,主要负责处理前端UI层的请求。该服务统一提供RESTful api向外部提供请求服务。 接口包括工作流的创建、定义、查询、修改、发布、下线、手工启动、停止、暂停、恢复、从该节点开始执行等等
-
UI
系统的前端页面,提供系统的各种可视化操作界面
2.3、架构设计思想
一、去中心化vs中心化
中心化思想:
中心化的设计理念比较简单,分布式集群中的节点按照角色分工,大体上分为两种角色:
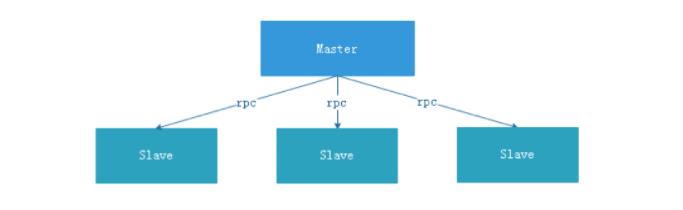
- Master的角色主要负责任务分发并监督Slave的健康状态,可以动态的将任务均衡到Slave上,以致Slave节点不至于“忙死”或”闲死”的状态。
- Worker的角色主要负责任务的执行工作并维护和Master的心跳,以便Master可以分配任务给Slave。
中心化思想设计存在的问题:
- 一旦Master出现了问题,则群龙无首,整个集群就会崩溃。为了解决这个问题,大多数Master/Slave架构模式都采用了主备Master的设计方案,可以是热备或者冷备,也可以是自动切换或手动切换,而且越来越多的新系统都开始具备自动选举切换Master的能力,以提升系统的可用性。
- 另外一个问题是如果Scheduler在Master上,虽然可以支持一个DAG中不同的任务运行在不同的机器上,但是会产生Master的过负载。如果Scheduler在Slave上,则一个DAG中所有的任务都只能在某一台机器上进行作业提交,则并行任务比较多的时候,Slave的压力可能会比较大。
去中心化思想:
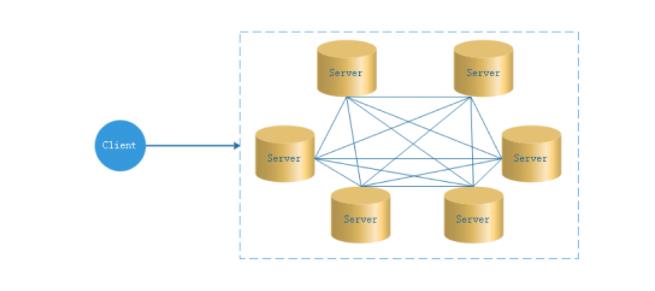
- 在去中心化设计里,通常没有Master/Slave的概念,所有的角色都是一样的,地位是平等的,全球互联网就是一个典型的去中心化的分布式系统,联网的任意节点设备down机,都只会影响很小范围的功能。
- 去中心化设计的核心设计在于整个分布式系统中不存在一个区别于其他节点的”管理者”,因此不存在单点故障问题。但由于不存在” 管理者”节点所以每个节点都需要跟其他节点通信才得到必须要的机器信息,而分布式系统通信的不可靠性,则大大增加了上述功能的实现难度。
- 实际上,真正去中心化的分布式系统并不多见。反而动态中心化分布式系统正在不断涌出。在这种架构下,集群中的管理者是被动态选择出来的,而不是预置的,并且集群在发生故障的时候,集群的节点会自发的举行"会议"来选举新的"管理者"去主持工作。最典型的案例就是ZooKeeper及Go语言实现的Etcd。
- DolphinScheduler的去中心化是Master/Worker注册到Zookeeper中,实现Master集群和Worker集群无中心,并使用Zookeeper分布式锁来选举其中的一台Master或Worker为“管理者”来执行任务。
四、实践
注:这部分的话,我截图给大家展示一下吧,然后配一些文字说明,有感兴趣的小伙伴可以讨论哈。
先来介绍下我们这边大致的设计思路:
按照数仓分层的思想,我们构建出了四个主要的项目。当然还会有一些其他的项目,包括临时需求、多场景取数等等吧。下面来重点看下这四个项目中内容:
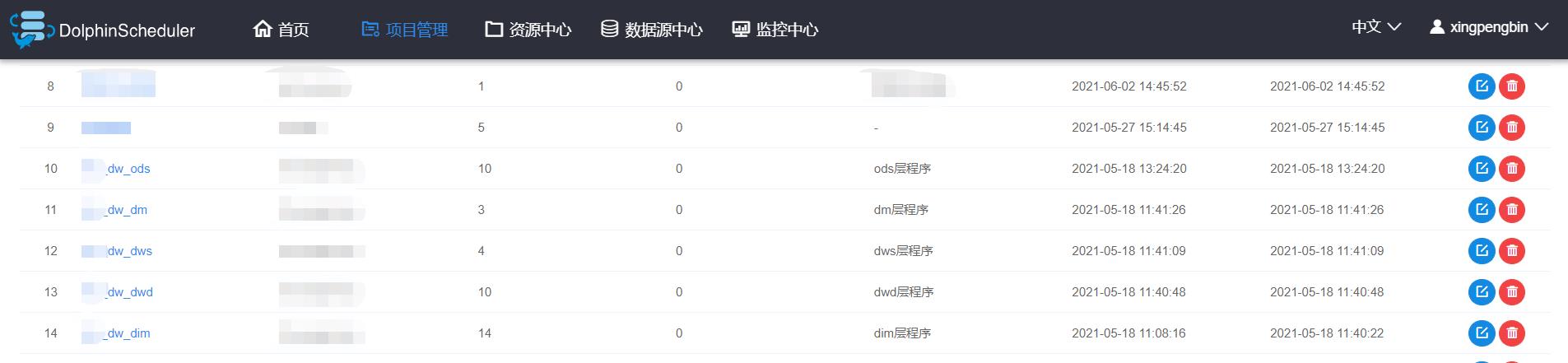
1、dw_ods层
看到这个名字,不用说,相信大家也知道是在做什么事了。对喽,就是你们想的那样。我来说下我们这边ODS层的设计吧(可能很乱,见笑了各位大佬)

对了,就是有这么多的ODS库,是不是很酸爽?基于工具的不能全局查找的特性,在不了解表的情况下,再加上运气背的话,可能要翻遍整个ODS的库才能知道你想看的表在哪个库下(哭瞎)~~
这么设计也是历史遗留问题了,很难再改变了。这就是所谓的按照业务系统的划分,在ODS落地时,也做了分库,并且基本是和ODS保持高度一致的。
其实从另外一面看待,这么设计也没什么问题。
也有了解过其他小伙伴们在ODS层的设计,其中有一种是将所有的ODS层表落到一个库下,但是在命名的时候,会按照业务系统进行划分。我个人觉得这两种设计各有利弊吧,不能绝对的说谁好谁坏~
另外还有一点,就是ODS层表的设计,目前我们是采用分区表进行存储的,并定期对历史分区进行删除,以保证存储空间和执行效率。当然也有把ODS层直接进行truncate再进行全量写的~看自己公司的设计理念和习惯了。
来给大家展示下,在DS中的设计:

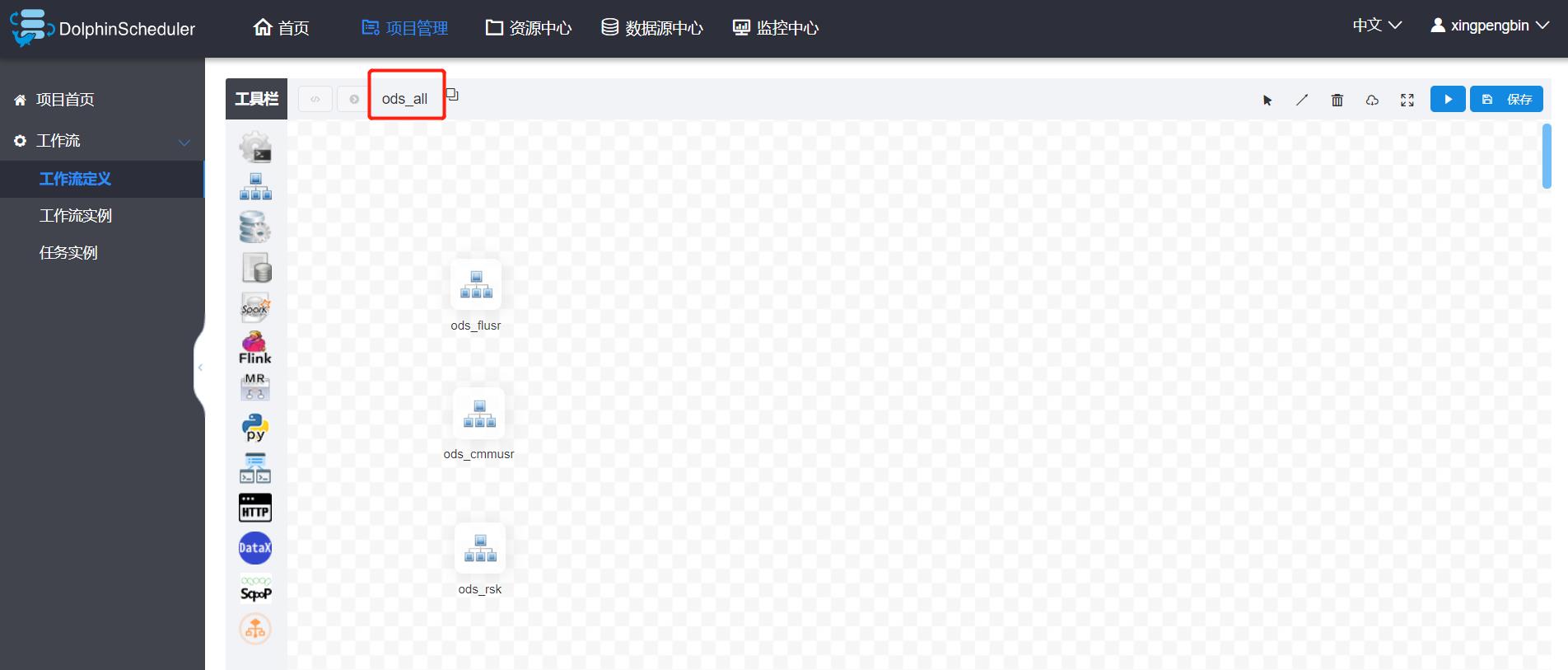
这两张图非常清晰的展示了我们在ODS层的设计,懂得一眼就明白了,不明白的咱可以留言交流。
2、dw_dwd层
说下DWD的设计,在数仓中将业务流转换为数据流。根据业务过程划分出主题,采用维度建模的方式,将数据进行汇总,采用一些七七八八的手段,尽可能的提高dwd层表的复用性。
在DS中,根据主题表创建不同的工作流:
弊端:等主题慢慢膨胀起来,管理起来比较费劲
好处:各自为战,清晰明了
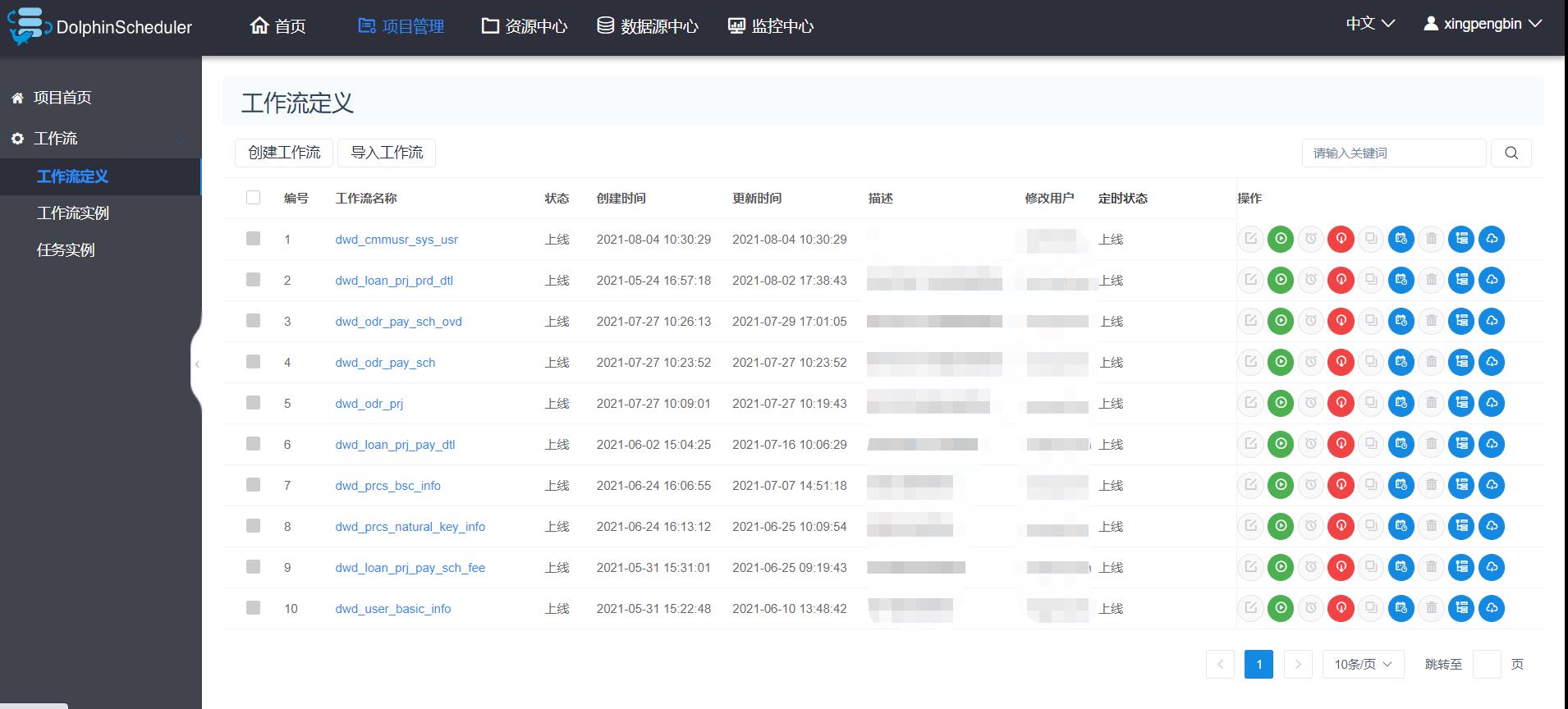
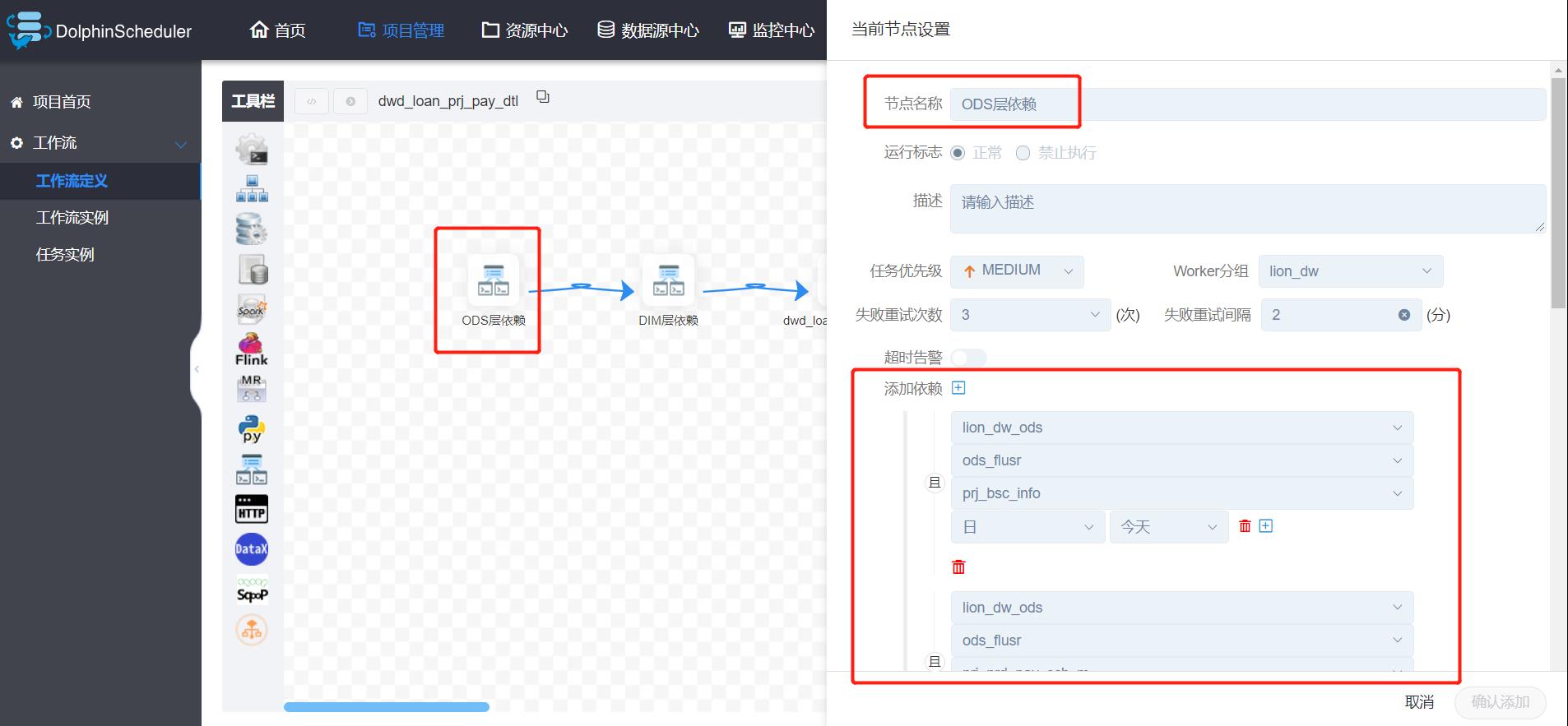
来看上面图二:
这是我们众多DWD表中的一张,在DS中,设置任务调度时,强依赖了DS中的依赖组件,并将DWD表中涉及到的ODS表增加至依赖中。这样做的好处,是比较精准的把控了每一张DWD表的动向。
3、dw_dws层
DWS层的设计也是比较明确的,基于DWD的层表,在同粒度的情况下,对数据进行汇总,然后形成主题宽表。
我们在设计这层的时候,严格按照数仓设计的规范:DWS层的表只能使用DWD的表进行关联汇总,坚决不允许出现跨层使用的情况。
如果在生产过程中,发现现有模型不能很好的支持业务的输出,会定期对模型进行小范围的重构(增减字段等),以保证模型的复用能力和“活力”。
在DS中,我们也是按照主题宽表进行分工作流设计的,如下图:

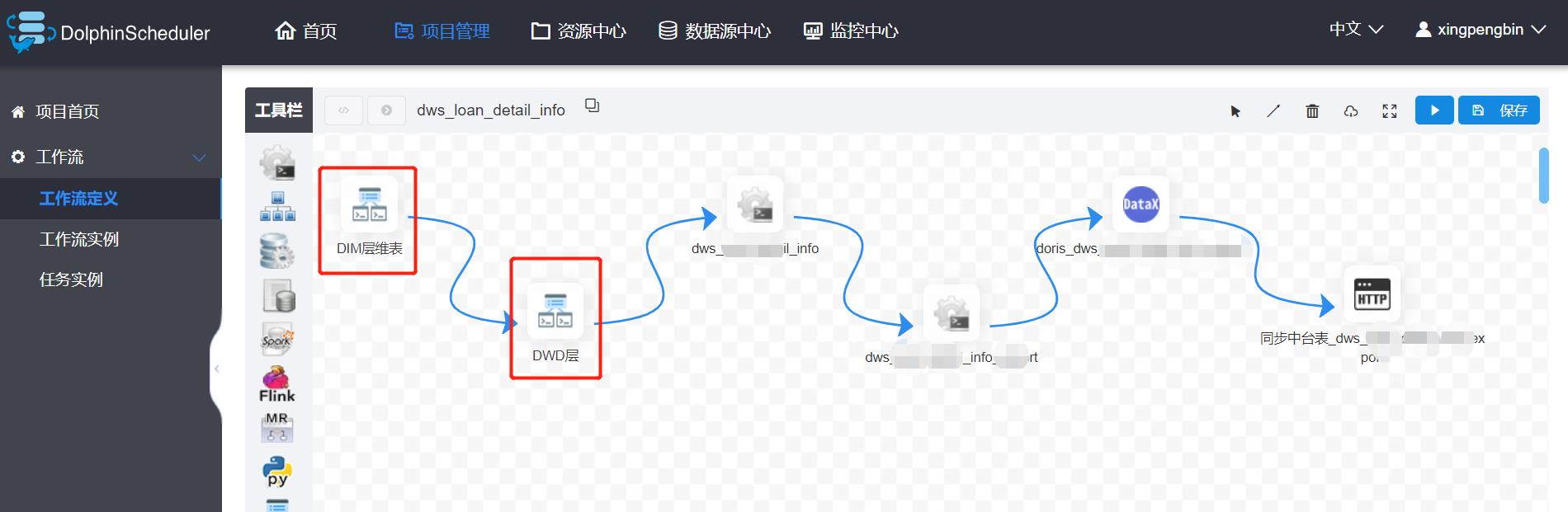
如上图二:在DWS中,我们也是按照依赖对工作流进行了设计。DIM层、DWD层都是在执行完毕的情况下,才能继续往下走。
PS:做任务依赖这点DS还是很香的,当然很多同学想用弱依赖来更加完美的配置工作流,但是目前DS貌似不支持,期待新功能早日上线吧。
4、DM层
设计完DWS层算是完成一大半工作了,DM层(或者叫ADS层)基本就是根据实际的报表需求,对数据进行汇总,最终由DM层将数据推到OLAP(目前我们使用的Doris,感兴趣的小伙伴可以一起交流下,哇咔咔~)供业务或者分析师使用。
5、DIM层
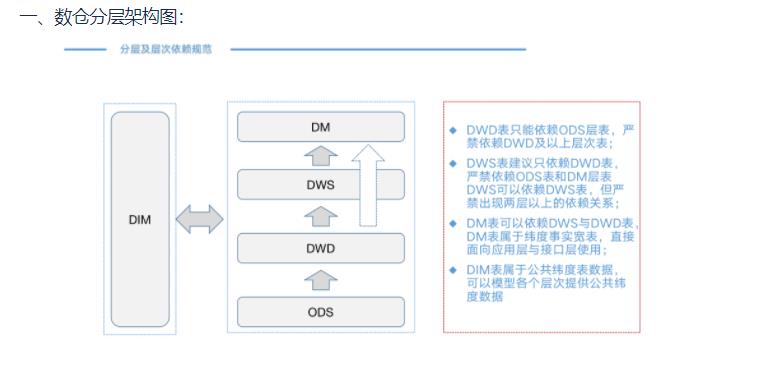
对了,差点忘了说,还有比较重要的一层:DIM层,即维度层。
在数仓建设的过程中,严格遵守一致性维度的原则。维度层的表是可以进行跨层使用的,下面展示下我们数仓分层的架构简图:
五、结束语
本文介绍了DS的架构原理和我实际工作中的使用情况,在我们整个数仓项目中,DS起到了至关重要的作用,使得开发效率明显提升,调度任务管理起来也更加清晰。
说一说我在使用过程中的心得吧,我个人个感觉,对调度的设计也是需要画个架构图提前规划的,不然随着需求的增加,项目越来越多,工作流越来越多,管理就变得困难了。提前做好规范,各位开发的小伙伴严格按照规范做事,即使会出圈也不会跑太偏。
本文篇幅有限,有些问题介绍也不是很深入,相信所有使用DS的小伙伴会充分挖掘它的功能,使开发变得更加容易。实际使用的功能还有很多,就不一一介绍了,有兴趣的小伙伴可以一起交流。
好了,此致吧,敬礼了~~睡觉了,晚安!!!
以上是关于基于DolphinScheduler的使用浅谈数仓分层及模型设计的主要内容,如果未能解决你的问题,请参考以下文章