[论文阅读笔记54]面向实体对齐的多视图知识图谱嵌入方法
Posted happyprince
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[论文阅读笔记54]面向实体对齐的多视图知识图谱嵌入方法相关的知识,希望对你有一定的参考价值。
1. 题目
Multi-view Knowledge Graph Embedding for Entity Alignment
面向实体对齐的多视图知识图谱嵌入方法
论文:https://arxiv.org/pdf/1906.02390.pdf
代码:https://github.com/nju-websoft/MultiKE
2. 研究背景
研究的问题:
知识图(KGs)之间基于嵌入的实体对齐问题;
目前存在问题:
以前的方法主要是在实体关系结构上,后面也有把属性加入作为特征,可是也有大量的实体特征未被去研究。表现在两方面的限制:
首先,知识图谱中的实体具有不同的特性,但当前基于嵌入的实体对齐方法只利用了其中的一种或两种类型;
例如[MTransE,IPTransE,BootEA]只是用了实体关系;另外,[JAPE,KDCoE, AttrE]加入了属性,文本描述或文字等信息;
其次,现有的基于嵌入的实体对齐方法依赖于丰富的种子实体对齐作为标记的训练数据。 这个是成本有点大的。
贡献:
提出了一种基于多视图知识图谱嵌入的实体对齐框架,称为MultiKE;
具体来说,基于实体名称、关系和属性的视图嵌入实体,并使用几种组合策略;
在实体层面,关系层面,属性层面设计了两个跨数据库的方法;
提出三种不同的组合多视图的策略;
多视图,跨图谱推理,嵌入组合
3. 内容
3.1 多视图嵌入
本质是想把知识中特征,分成多个子集,这里叫做views; 名称/关系/属性特性
多视图特征例子:

实体嵌入对这三种视图中分别用不同的方法去学习,最后把学习结果联合起来达到实体性能提高结果。
3.1.1 Literal Embedding(字面意思的嵌入):

对于词嵌入采用的方法–Advances in pre-training distributed word representations
对于字符—Skip-Gram

φ(·)表示输入的字面嵌入, encode(·) 对嵌入的压缩表示;[; ] 表示把字符拼接起来;这里n最大取5,超过的会被截断,短的会用空格代替;
3.1.2 Name View Embedding
名字视的嵌入,是使用了字面嵌入的。
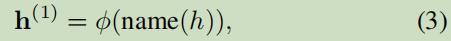
从对象抽取名字表示;
3.1.3 Relation View Embedding
基于TransE表达学习:
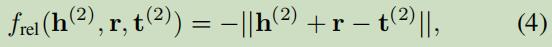


X _+ = X_a ∪ X_b:表示来自两图谱的正样本;X _−表示被随机替换了的负样本;
3.1.4 Attribute View Embedding
使用CNN去抽取;
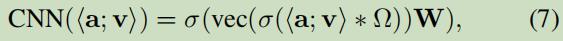
<a;v>:表示属性及其值拼接成一个matrix; 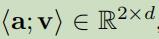
对于一个fact(h,a,v),如下定义:
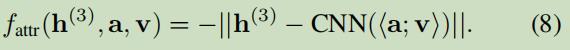
损失函数:

3.2 Cross-KG Training for Entity Alignment
基于种子实体对齐的跨kg实体对齐推断来捕获两个kg之间的对齐信息。
3.2.1 实体识别推理
我们利用少量已对齐的种子实体对作为监督数据:

关系:

3.2.2 Relation and Attribute Identity Inference
与实体识别推理差不多,不过这里增加了一个搞了辅助概率;

这里采用软相似性:由于不同知识图谱在本体层面可能差异巨大,所以我们不要求关系对是严格对齐的。

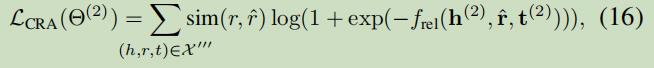
3.3 View Combination
3.3.1 Weighted View Averaging
 ,
,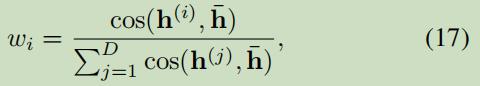 ,结果:
,结果: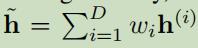
3.3.2 Shared Space Learning
引入一个正交矩阵,把视图嵌入映射到共享空间中。
 ,
,
Z_i表示看作为第i个视图嵌入空间映射到共享空间的映射矩阵。||·||F表示为Frobenius规范;
式中的第二项表示软正则的规约。
3.3.3 In-training Combination
联合多视图训练。
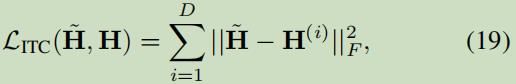
4. 训练过程

首先训练词与char的嵌入,然后训练其它的视图嵌入,软对齐也在迭代中计算;最后,如果是in-training的就不需要,否则进行合并。
5.实验
Datasets:DBP-WD,DBP-YG
对比方法使用了7种:MTransE, IPTransE, JAPE,BootEA, KDCoE, GCN-Align,AttrE ,也加了:TransD, HolE ,ConvE

从这个对比来看,提出模型有很大性能上是有很大的提升的。
视图影响分析:
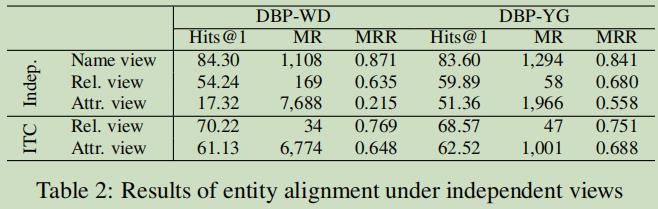
Name还是比加高的,字面意义起到很大的作用。不过这个也是很合理的,一般相同实体,名称也是差不多相同的。ITC:in-training
combination
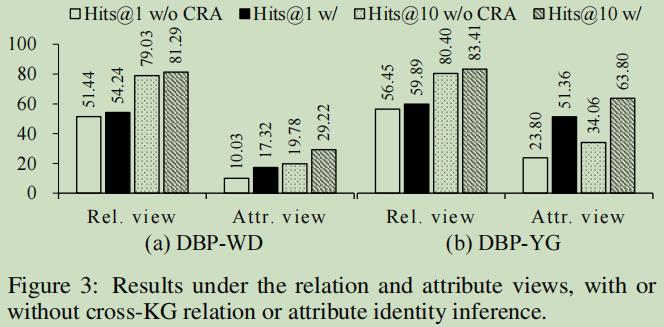
跨图谱推理影响
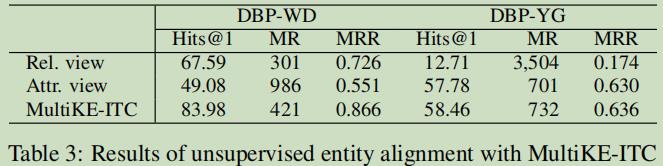
无监督实体对齐的分析
与常规方法对比分析
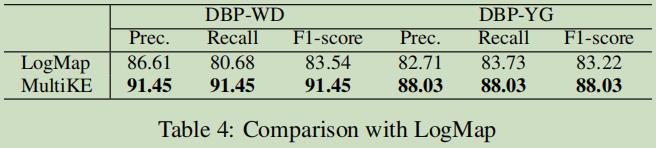
相关工作
KG embedding
分为三类:Translational 方法;Semantic matching方法;Neural方法
Embedding-based entity alignment
先嵌入,然后计算相似性;
Multi-view representation learning
多视图的的方法分三步:
(i)识别能够充分表示数据的多个视图;
(ii)对每个视图进行表示学习;
(iii)组合多个视图特定的表示。
参考:
【1】IJCAI 2019 论文:面向实体对齐的多视图知识图谱嵌入方法
以上是关于[论文阅读笔记54]面向实体对齐的多视图知识图谱嵌入方法的主要内容,如果未能解决你的问题,请参考以下文章