Python爬虫实战-性感gif图数据采集
Posted 小白兔白又白i
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫实战-性感gif图数据采集相关的知识,希望对你有一定的参考价值。
前言
最近发现一个十分有趣的网站(狗头保命),一些影视剧里让人血脉膨胀的镜头制作成的gif图片,满满的都是全是爱,作为一个合格的小爬虫,不把它都放进‘作业’文档里怎么行
爬取目标
网址:GIF出处

工具使用
开发工具:pycharm
开发环境:python3.7, Windows10
使用工具包:requests,lxml
重点内容学习
- requests使用
- xpath解析数据
- 获取gif数据
项目思路解析
首先明确自己需要采集的目标数据网址
通过requests工具包发送网络请求
翻页通过改变url
http://gifcc.com/forum-38-{}.html
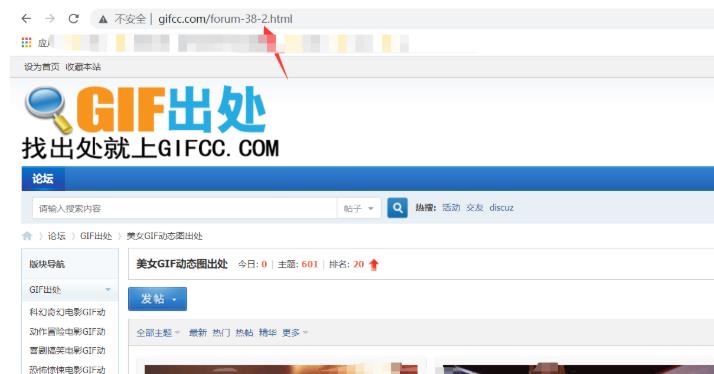
转换当前页面数据
通过xpath方式提取网页数据
提取的数据为a标签的值
我们需要的是动态图
gif在详情页面

url = 'http://gifcc.com/forum-38-{}.html'.format(page)
response = RequestTools(url).text
html = etree.HTML(response)
atarget = html.xpath('//div[@class="c cl"]/a/@href')
for i in atarget:
urls = 'http://gifcc.com/' + i
再次对详情页面发送网络请求
进入详情页面,通过xpath方式提取出对应的标题以及对应gif图片地址
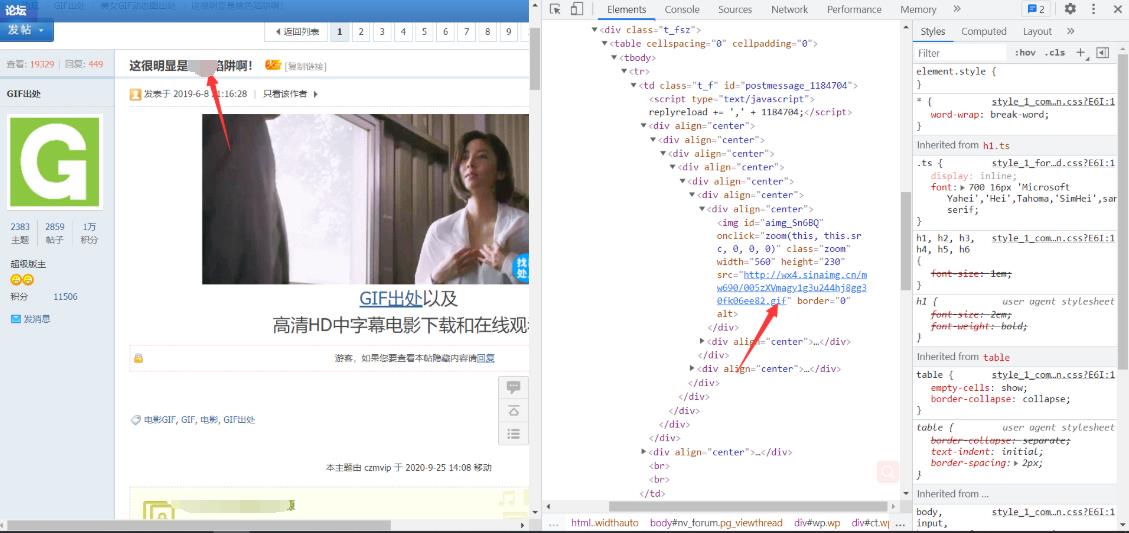
图片的名字也可以自行定义
response = RequestTools(url).text
html = etree.HTML(response) # HTML对象创建 替换了命名空间
try:
gifurl = html.xpath('//td[@class="t_f"]/div[1]/div/div/div/div/div/div[1]/img/@src')[0] # 提取gif图片地址
gifcontent = RequestTools(gifurl) # 请求图片地址
title = gifurl.split('/')[-1] # 文件的存储名称
Save(gifcontent, title)
except Exception as e:
print(e)
请求对应的图片地址
获取到gif图片数据
保存对应图片信息
def Save(gifcontent, title):
f = open('./GIF/' + title, 'wb') # open('文件路径', 写入方式(w 文件存在就写入 不存在就创建 b进制文件读写 图片 16进制数据))
f.write(gifcontent.content)
f.close()
print('{}下载完成...'.format(title))
简易源码分享
import requests
from lxml import etree # xpath 数据提取
def RequestTools(url):
# 请求头 -> 反爬 模拟浏览器请求
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.101 Safari/537.36'
}
# 发送请求
response = requests.get(url, headers=headers)
return response
def Save(gifcontent, title):
f = open('./GIF/' + title, 'wb') # open('文件路径', 写入方式(w 文件存在就写入 不存在就创建 b进制文件读写 图片 16进制数据))
f.write(gifcontent.content)
f.close()
print('{}下载完成...'.format(title))
def DateilsPage(url):
# url = 'http://gifcc.com/thread-5859-1-1.html' # 请求地址
response = RequestTools(url).text
html = etree.HTML(response) # HTML对象创建 替换了命名空间
try:
gifurl = html.xpath('//td[@class="t_f"]/div[1]/div/div/div/div/div/div[1]/img/@src')[0] # 提取gif图片地址
gifcontent = RequestTools(gifurl) # 请求图片地址
title = gifurl.split('/')[-1] # 文件的存储名称
Save(gifcontent, title)
except Exception as e:
print(e)
def main(page):
url = 'http://gifcc.com/forum-38-{}.html'.format(page)
response = RequestTools(url).text
html = etree.HTML(response)
atarget = html.xpath('//div[@class="c cl"]/a/@href')
for i in atarget:
urls = 'http://gifcc.com/' + i
DateilsPage(urls)
# 程序的启动入口 加密 源码加密
if __name__ == '__main__':
for page in range(1, 11):
main(page)
我是白又白i,一名喜欢分享知识的程序媛❤️
如果没有接触过编程这块的朋友看到这篇博客,发现不懂的或想要学习Python的,可以直接留言+私我鸭【非常感谢你的点赞、收藏、关注、评论,一键四连支持】
以上是关于Python爬虫实战-性感gif图数据采集的主要内容,如果未能解决你的问题,请参考以下文章
Python练习册 第 0013 题: 用 Python 写一个爬图片的程序,爬 这个链接里的日本妹子图片 :-),(http://tieba.baidu.com/p/2166231880)(代码片段
爬虫遇到头疼的验证码?Python实战讲解弹窗处理和验证码识别