Python3 爬虫神器总结
Posted Fu_Lin_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python3 爬虫神器总结相关的知识,希望对你有一定的参考价值。
关注我的公众号,有 PyCharmIDE 最新无码使用方案,更有含量资源下载!

前言
最近要学习python爬虫,发现无法动手,因为不知道咋解析数据,咋过滤自己需要的东东,所以一阵头大,茫茫然不知所终,于是百度,文档无所不用其极的乱找了一遍,算是大概心中有了一点基础,所以本篇将记录我所知道的爬虫需要的相关的神器,都是好东西,在日常其他的应用中也是可以用到的,下面看正文记录!
请求神器requests
首先出场的就是请求页面的工具 requests ,它的作用主要是获取网页的 html 信息, 当然在python3 中,你也可以使用 urllib.request , 下面简单分类介绍下这两个东东的区别
- urllib 库是 Python 内置的,无需我们额外安装,只要安装了 Python 就可以使用这个库。
- requests 库是第三方库,需要我们自己安装。
而 requests 库强大好用,所以我极力推荐的是使用此神器,requests 库的 github 地址:
https://github.com/requests/requests
requests安装
win系统下打开 cmd ,使用如下指令安装 requests :
pip install requests
或者:
easy_install requests
requests简单示例
requests 库的基础方法如下:
| 方法 | 说明 |
|---|---|
| requests.request() | 构造一个请求,支撑以下各方法的基础方法 |
| requests.get() | 获取HTML网页的主要方法,对应于HTTP的GET |
| requests.head() | 获取HTML网页头信息的方法,对应于HTTP的HEAD |
| requests.post() | 向HTML网页提交POST请求的方法,对应于HTTP的POST |
| requests.put() | 向HTML网页提交PUT请求的方法,对应于HTTP的PUT |
| requests. patch() | 向HTML网页提交局部修改请求,对应于HTTP的PATCH |
| requests.delete() | 向HTML页面提交删除请求,对应于HTTP的DELETE |
还有其他方法就不一 一列出了,有兴趣的可以去 requests官方中文教程地址 自己去搜索了解一番吧!
解析申请 Beautiful Soup
Beautiful Soup 是 Python 的一个第三方库,主要帮助我们解析网页数据。
Beautiful Soup安装
其具体安装其实可以去官网查看,下面列出pip的安装方式:
打开win系统的 cmd,使用 pip 或 easy_install 安装即可。
pip install beautifulsoup4
# 或者
easy_install beautifulsoup4
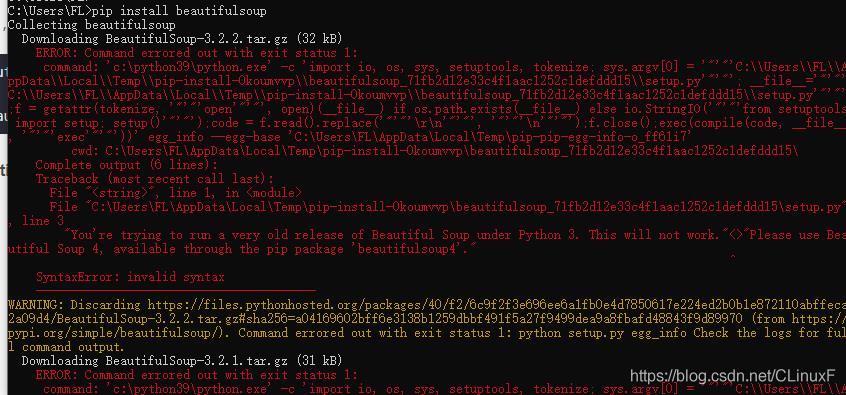
切记一定要是 beautifulsoup4, 而不是beautifulsoup, beautifulsoup是表示版本3,而官网已经不再维护3版本了,安装默认的beautifulsoup就会报错,如下,我安装时的报错:
lxml安装
安装好 beautifulsoup4 后,我们还需要安装 lxml,这是解析 HTML 需要用到的依赖:
pip install lxml
Beautiful Soup 的使用方法也很简单, 不啰嗦,直接自己去 Beautiful Soup 官方中文教程 去看吧, 简单详细,可直接上手
暂时发现,拥有这两大神奇可以入门爬虫,后续会持续更新其他爬虫神器
以上是关于Python3 爬虫神器总结的主要内容,如果未能解决你的问题,请参考以下文章