数据库误操作后悔药来了:AnalyticDB PostgreSQL教你实现分布式一致性备份恢复
Posted 阿里云云栖号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据库误操作后悔药来了:AnalyticDB PostgreSQL教你实现分布式一致性备份恢复相关的知识,希望对你有一定的参考价值。
简介: 本文将介绍AnalyticDB PostgreSQL版备份恢复的原理与使用方法。
一、背景
AnalyticDB PostgreSQL版(简称ADB PG)是阿里云数据库团队基于PostgreSQL内核(简称PG)打造的一款云原生数据仓库产品。在数据实时交互式分析、HTAP、ETL、BI报表生成等业务场景,ADB PG都有着独特的技术优势。
作为一款企业级数据仓库产品,数据安全的重要性不言而喻。备份恢复功能是保障数据安全的基本手段,也是ADB PG应对突发状况进行数据库恢复的重要保障。备份恢复,顾名思义,是对数据库进行数据备份,以便在必要时进行数据的恢复,防范于未然。当前,ADB PG的备份恢复功能已经应用在以下各个用户场景中:
- 由于系统故障、人为误操作造成数据被破坏或实例不可用时,基于备份数据对实例进行恢复。
- 用户需要基于已有实例,快速克隆出一个完全相同的实例。
- 在节点数不变的前提下,用户需要更改源实例的规格。
本文将介绍ADB PG备份恢复的原理与使用方法。
二、简介
ADB PG 是采用MPP水平扩展架构的分布式数据库。ADB PG实例由一个或多个协调节点(Master)和多个计算节点(Compute Node)组成,协调节点负责接收用户请求,制定分布式执行计划并下发至计算节点,收集执行结果并返回给客户端;计算节点负责并行计算分析与数据存储。数据在计算节点之间可以随机、哈希、复制分布。下图ADB PG的架构图:
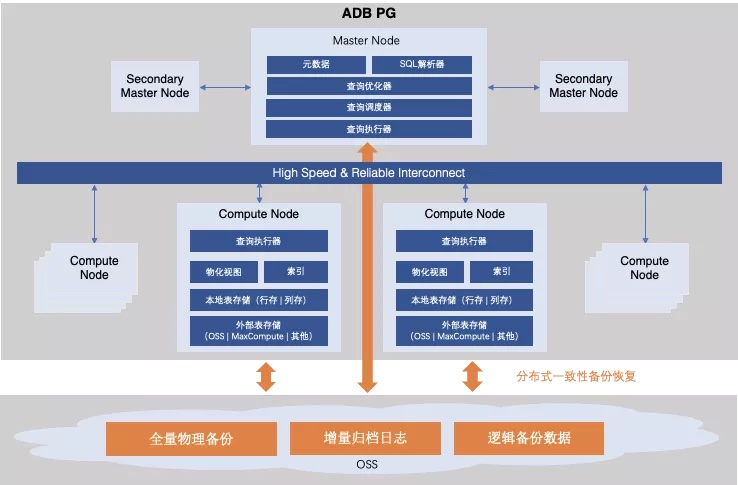
ADB PG的物理备份恢复功能,基于集群的基础备份和日志备份,可以在分布式数据库继续提供服务的同时备份各个节点的数据,并保证数据的一致性。在需要时,可以将分布式数据库恢复至备份的时刻。
基础备份是指对数据库所有数据进行的一个完全拷贝。基础备份会将集群全量数据快照压缩后存储在其它离线存储介质,集群在基础备份期间不会阻塞用户的读写,因此,备份期间产生的日志也会被备份来保证基础备份的完整性。
日志备份(也称为增量备份),是指将集群产生的日志文件备份至其他离线存储介质。日志文件记录了用户对数据库的DML与DDL操作。通过一个完整的基础备份以及连续的日志备份,可以将新集群恢复到某一历史事件点,保证了这段时间的数据安全性。
ADB PG可保障最小RPO为10分钟的备份恢复。
三、原理
在完整地介绍ADB PG的备份恢复原理之前,先简要地介绍单机PG的PITR(Point in Time Recovery)备份恢复机制。ADB PG的备份恢复机制基于单机PG的PITR原理,并加入了分布式数据一致性的保障机制。
(一)单机PG的PITR机制
WAL日志:
PostgreSQL数据库会将事务对数据的所有更改(包括DDL、DML等操作)记录在WAL(Write Ahead Log)日志文件中。WAL日志文件可以看作是一个无限增长的只追加文件,PG会将日志数据按固定大小切分成多个文件存储。事务的每次修改数据的操作都会被追加记录至WAL文件中,并赋予一个唯一的LSN序号(Log Sequence Number),在事务提交时,会保证WAL日志已持久化。
这些日志文件的作用是为了让数据库在需要恢复时,可以通过“重放”WAL日志来恢复数据库崩溃时还未持久化,但对应事务已提交的数据。
恢复点:
有了WAL日志可以进行“重放”操作,那么还有一个问题:需要重放到什么时候呢?这就需要恢复点(restore point)来解决。
恢复点相当于WAL日志中写入的一个标记,它标记了一个日志的位置。当PG对日志进行重放时,通过检查是否已经到达这个标记点,来决定是否需要停止"重放"的操作。
以下SQL可以在WAL日志文件中创建一个名为t1的标志点:
postgres=# select pg_create_restore_point('t1');
LOG: restore point "t1" created at 0/2205780
STATEMENT: select pg_create_restore_point('t1');
pg_create_restore_point
-------------------------
0/2205780
(1 row)
当数据库顺序回放WAL日志时,会检查当前日志包含此恢复点名称,若已包含,则停止重放。另外,PG还支持恢复至指定的任意时间点,事务号,LSN序号等操作。
基础备份与增量备份:
基础备份是对数据库数据的一份完整拷贝。可以使用pg_basebackup工具对单机PG进行一次基础备份,备份数据可保存至本地,也可存储在其他离线存储介质(OSS)中。
$ pg_basebackup -D pg_data_dir/ -p 6000 NOTICE: pg_stop_backup complete, all required WAL segments have been a
增量备份是指对产生的WAL日志文件进行备份。在PG中,可通过数据库参数archive_command来指定如何备份WAL日志数据。当PG生成一个WAL日志文件时,会通过执行archive_command的命令来尝试备份归档该日志文件。比如,如下命令会将日志文件发送至指定的OSS。
archive_command="ossutil cp %p oss://bucket/path/%f"
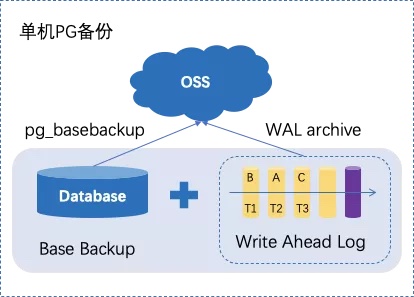
单机PG的全量备份与增量备份
需要注意的是,基础备份期间并不会阻塞数据库的读写,因此备份期间的数据更新对应的WAL日志也需要备份,以备恢复时保证数据的一致性。
PITR恢复:
当需要恢复数据库时,首先下载基础备份数据,然后使用基础备份开启集群,再下载日志文件备份,“重放”至指定的恢复点即可进行数据库的恢复。在单机PG中, 指定的恢复点的目标可以是事务号、时间戳、WAL序号(LSN)以及某个恢复点名称。
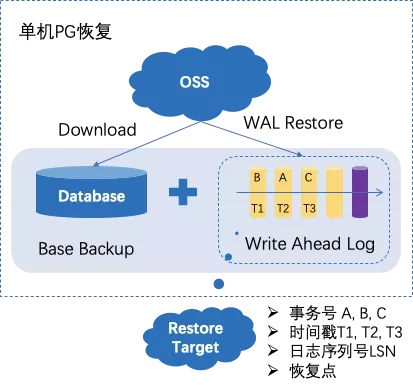
(二)ADB PG的分布式一致性备份恢复机制
ADB PG 作为分布式数据库,使用两阶段事务提交来管理分布式事务。如果照搬单机PG的PITR机制,会造成数据的不一致。比如如下场景:分布式事务按照A、B、C时间顺序分配,但由于种种原因(如网络延时、节点负载、显式提交等),分布式模式下事务的提交的顺序在各个节点可能各不相同,如下图所示:
- Master 按照 A、B、C顺序提交
- Compute Node 1 按照 A、C、B顺序提交
- Compute Node 2 按照 B、C、A顺序提交
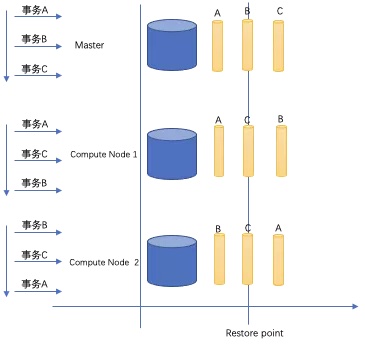
如果在此过程中,创建了恢复点,当恢复时如果指定恢复至该恢复点,显而易见,恢复后集群中各个节点所处的状态是不一致的。
两阶段事务提交锁与一致性恢复点:
为了解决上述的问题,我们引入了两阶段事务提交锁。分布式事务提交会以SHARED模式获得该锁,而创建恢复点都需要以EXCLUSIVE模式获得该锁。于是在集群中如果有分布式事务正在等待各个节点上提交,那么集群创建恢复点的动作必须等待所有节点上的分布式事务提交完后,才能进行。
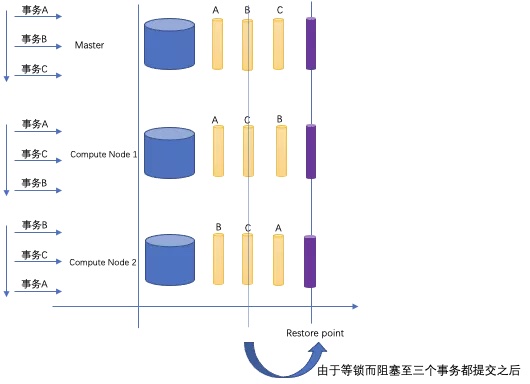
这从根本上解决了上述这就解决了在分布式事务还在提交的同时创建恢复点而造成恢复时数据不一致的问题。引入了两阶段提交锁机制之后,我们可以保证创建的恢复点所对应的各节点状态是一致的,因此我们将ADB PG中创建的恢复点称为一致性恢复点。
分布式备份与恢复过程:
有了事务提交锁与一致性恢复点之后,我们就可以放心地对ADB PG各个节点进行备份和创建一致性恢复点,而无需担心节点状态不一致的问题。
ADB PG的备份也分为基础备份和日志备份(也称为增量备份)。基础备份是对集群每个节点进行的一次完整拷贝,ADB PG会对计算节点和协调节点并发地进行备份,将备份数据流式保存至离线存储(如OSS)。在进行基础备份的期间,不会阻塞集群的读写服务。因此,如果在基础备份期间,用户有写入和更新的数据,也需要将数据更改对应的WAL日志进行备份。如下图所示, ADB PG会对每个节点并行地进行一次数据拷贝,将数据流式上传至OSS。
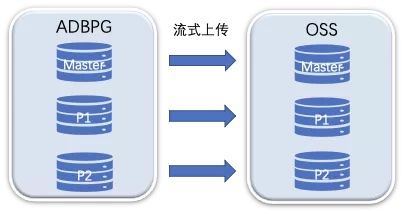
ADB PG基础备份过程
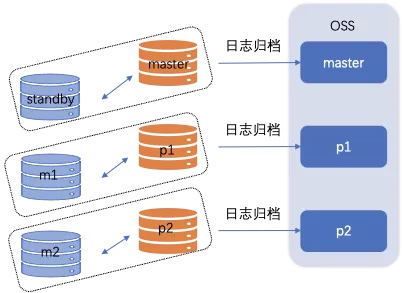
ADB PG的日志备份是对集群中的计算节点和协调节点产生的WAL日志的备份。各个节点会将自己生成的WAL日志转储至离线存储(如OSS)。同时,集群会定时地创建一致性恢复点,并将包含一致性恢复点的WAL日志进行备份。
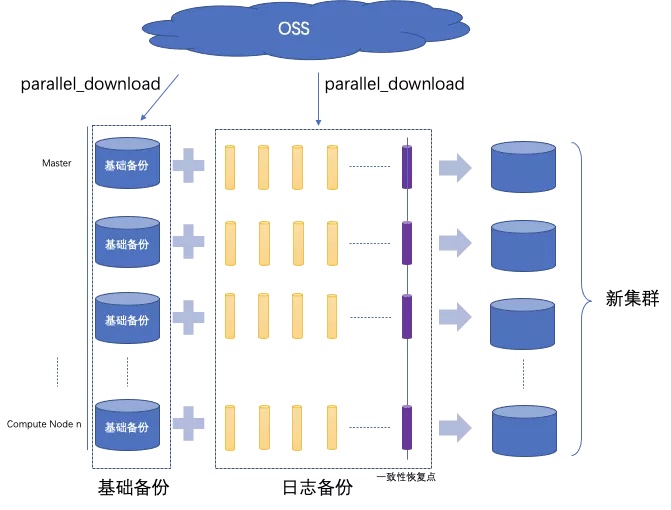
当需要恢复新的集群时,需要同时使用基础备份与日志备份,并首先创建一个节点数和原实例相同的恢复实例。各个节点并行拉取指定的基础备份至本地。之后,每个节点自己拉取自己所需的WAL日志备份文件,在本地重放,直到重放至指定的一致性恢复点而停止。最终,我们就能得到一个新的集群,并保证数据和状态与源实例在一致性恢复点对应的数据与状态一致。恢复的过程如下图所示:
四、使用
(1)控制台备份相关信息
- 查看基础备份集
用户在实例控制台的“备份恢复”页面,可以查看数据库的基础备份数据。目前基础备份数据保存在OSS上,默认保留天数为7天。
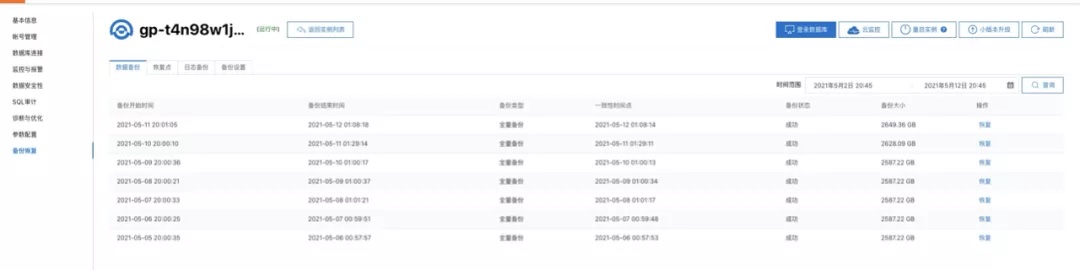
表格中每一行表示一份基础备份数据,并记录了备份的开始时间,结束时间,备份状态(成功/失败),备份数据大小以及一致性时间点。一致性时间点表示此基础备份数据可以将集群恢复至该历史时间点,并使数据库处于一致性状态。
- 查看一致性恢复点
一致性恢复点是指集群可以恢复到的某个历史时间点。用户在备份恢复页面的“恢复点”页可以查看当前实例的所有恢复点。

表格中每一行表示一个一致性恢复点,并记录了恢复点的时间戳,表示该恢复点可以让集群恢复至此历史时间点。
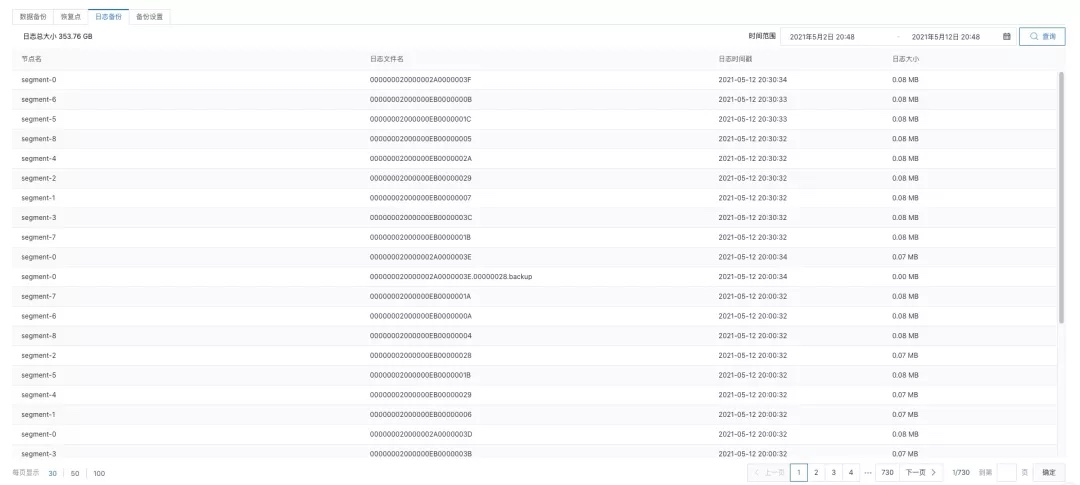
查看日志文件列表
日志文件记录了数据库的所有更改,在集群恢复时会使用相应的日志文件将集群恢复至一致性状态,当前用户集群恢复的日志文件都保存在OSS上。用户在备份恢复页面的"日志备份"中可查看日志文件列表。
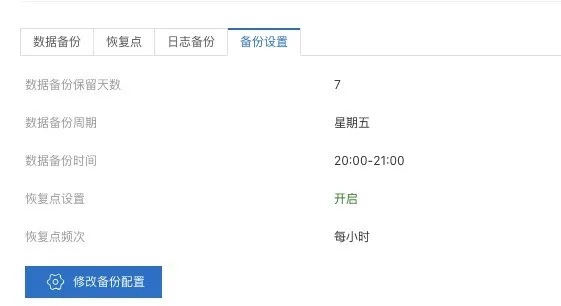
- 查看备份策略
备份策略是指实例进行备份的周期与时间段,创建一致性恢复点的频率,以及数据备份的保留天数等等。
用户可在备份恢复的“备份设置”中查看和修改备份策略。
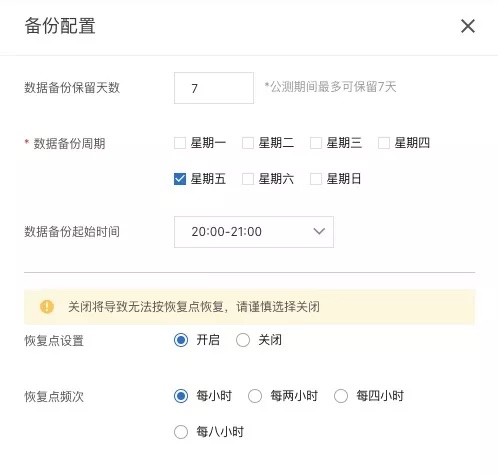
- 修改备份策略
点击“修改备份配置”按钮,可以对备份策略进行修改。
(2)实例恢复步骤
首先查看源实例上的数据
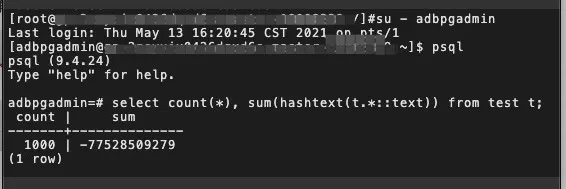
- 进入恢复页面
用户可以在控制台的实例列表,数据备份列表或恢复点列表点击恢复进入实例恢复页面;




恢复页面如下:
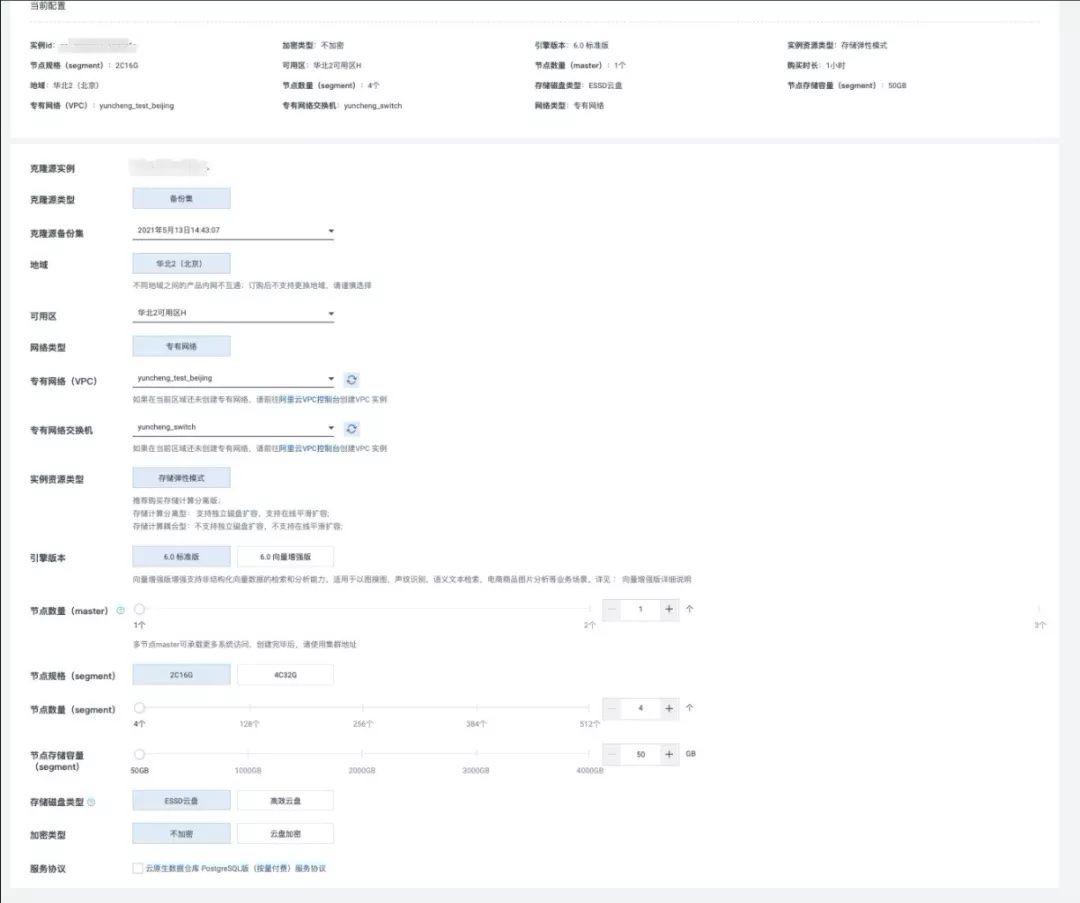
恢复实例的售卖页面与购买实例的页面大体一致,但多了如下限制:
1.当前恢复实例是master数量必须选择1个
2.选择的实例segment(computer node)数量必须与源实例保持一致
3.选择的实例存储空间必须大于或等于源实例
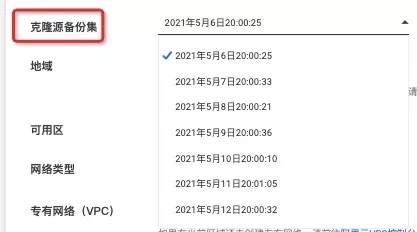
- 选择恢复时间点
在恢复页面的"克隆源备份集"的下拉框中选择需要恢复实例到哪一个历史时间点,即指定一个一致性恢复点。
- 点击购买
用户点击购买后,与购买新实例的流程一样,需要等待实例创建完成后,可在控制台看到新恢复出的实例。
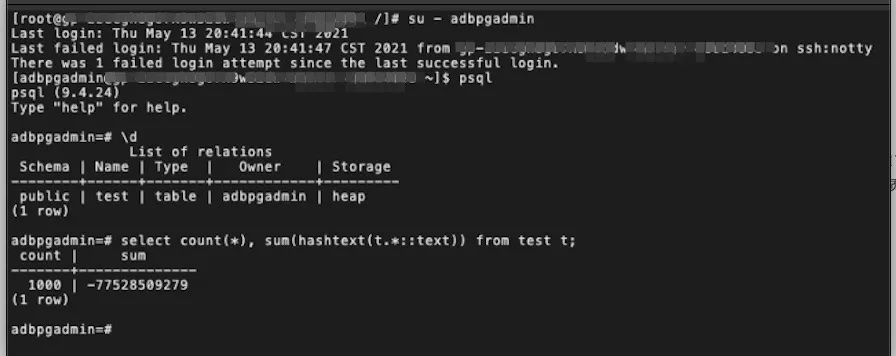
- 恢复的新实例
查看恢复的新实例上的数据,可以看到数据与源实例完全一致。
五、总结
备份恢复对ADB PG保障数据安全的具有很重要的价值。当前备份恢复功能已经应用多个用户场景,并保障了最少为10分钟的RPO。未来ADB PG备份恢复功能会继续优化备份恢复性能,支持差异化备份,支持更多的存储介质,提高用户使用体验,为用户提供更多的功能、性能和成本优化。
原文链接
本文为阿里云原创内容,未经允许不得转载。
以上是关于数据库误操作后悔药来了:AnalyticDB PostgreSQL教你实现分布式一致性备份恢复的主要内容,如果未能解决你的问题,请参考以下文章