森说AI:AI创造营大作业--应用paddlex完成对自定义车道路的语义分割
Posted 神佑我调参侠
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了森说AI:AI创造营大作业--应用paddlex完成对自定义车道路的语义分割相关的知识,希望对你有一定的参考价值。
AI创造营大作业–应用paddlex完成对自定义车道路的语义分割
一直想实现对车道的语义分割,接着这个机会去使用paddlex来从零开始实现,并且加深一下自己的理解!其实本来我是想用paddleseg做的,但是我看了模型训练的那个直播说要是想快速的开始训练的话可以用paddlex和paddlehub,然后这里的我们去尝试一下paddlex,我也是第一次使用!
一 、项目背景
我采集了我们学校的后山道路的图片,一个1000多张,想要使用语义分割去得到道路,然后根据返回的道路在去得到前进的方向,本来打算使用paddleseg去做的,但是在直播时说到,先考虑paddlehub和paddlex,所以这里也是我第一次使用paddlex,也会记录自己的实现的整个过程吧!
然后这里我们先看一下最终的结果:

二、 数据集简介
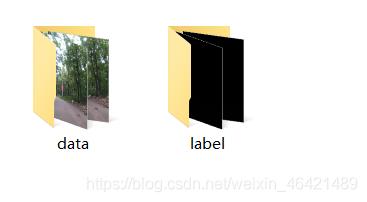
数据集的话我是控制小车,然后写了个脚本去定时收集道路数据,这里就不介绍了不是重点,然后我们先看一下数据集:

然后的话对于数据集标注的话开始我使用的是labelme,但是太慢了我一个人标1000张得标到什么时候,后来我了解到了交互式分割标注工具eiseg,然后我在官网去安装的时候怎么也安装不上,各种报错,当我要放弃时,GT大佬发了一个exe的文件夹给我,很是感谢,然后的话我就去标注了
记住保存时不要自定义路径,就按它的来,否则保存了会发现你的文件夹并没有(血的教训)
然后再标了两次之后终于标完了

因为像素是在0-1之间,所以我们人眼看不出来,后面会代码处理一下就行了。
三、 paddlex使用
初探paddlex
飞桨全流程开发工具,集飞桨核心框架、模型库、工具及组件等深度学习开发所需全部能力于一身,打通深度学习开发全流程。
我们这里先对paddlex进行安装:
! pip install paddlex==2.0.0rc4
这里我想要去打开GitHub,但是发现进不去,然后我去下载了郑佬在直播时分享的工具,现在妈妈再也不用担心我进步不去了(手动狗头),真是秒进呀,感谢郑佬分享!
这里我是进到了一个官方的一个实例:可以点进去看一下,然后先了解一下paddlex怎么使用!
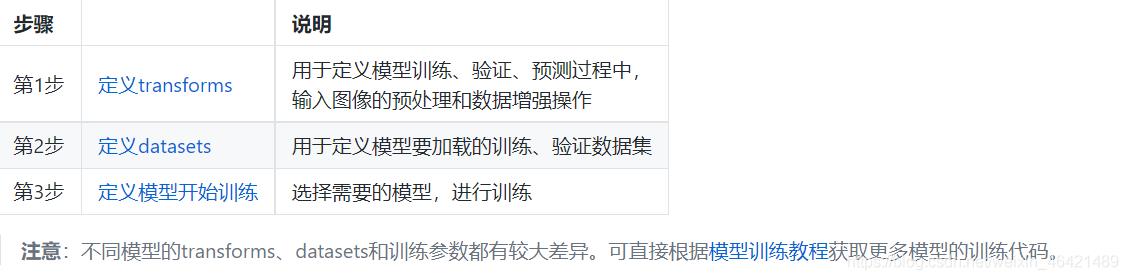
从官网我们可以看到我们要去训练模型要需要3个步骤,我们先看第一步数据增强,这里我们注意一下对于训练我们是对数据进行数据增强的但是对预测我们不对数据进行操作,所以我们来看一下这个增强的代码:
数据增强
from paddlex import transforms as T
train_transforms = T.Compose([
T.Resize(target_size=512),
T.RandomHorizontalFlip(),
T.RandomCrop(),
T.Normalize(
mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]),
])
eval_transforms = T.Compose([
T.Resize(target_size=512),
T.Normalize(
mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]),
])
一定要进行归一化,要不训练不出来,我以前训练个模型没有归一化loss6000多,用了很快收敛了
这里对训练集进行了归一化和对图像进行随机的水平翻转和剪切。然后对预测集的话只进行归一化。
定义数据集Dataset
这里会用到SegDataset这个API:

使用这个api的时候我们得先有file_list.txt,label_list.txt这两个文件,但是我们现在并没有,所以我们先去用代码去生成这两个文件
#解压数据集
!unzip data/data103908/images.zip
因为我们这里的数据是从0到1146张,所以我们可以不用去调os的库就可以去完成对txt文件的书写。先新建两个文件:
f1 = open("images/file_list.txt","a")
f2 = open("images/label_list.txt","a")
for i in range(1,1147):
name1 = "data/"+str(i)+".png\\n"
name2 = "label/"+str(i)+".png\\n"
f1.write(name1)
f2.write(name2)
print("done")
描述数据集图片文件和对应标注文件的文件路径(文本内每行路径为相对data_dir的相对路径)
但是这里输出后不知道为什么不是从1开始的不过小问题,因为是按顺序来的,自己从新剪切一下就行。


这里说一下我们的labels是用一个文件,我估计是我们用不同的图片之后,paddlex可以直接调用对应名字的标签文件吧
然后之后的话我们现在要去划分一下验证集,代码与上面的差不多,就是去写一个val_list,我直接将后面的146个文件剪切过去了。

然后接下来就开始定义吧:
import paddlex as pdx
train_dataset = pdx.datasets.SegDataset(
data_dir='images',
file_list='images/train_list.txt',
label_list='images/labels.txt',
transforms=train_transforms,
shuffle=True)
eval_dataset = pdx.datasets.SegDataset(
data_dir='images',
file_list='images/val_list.txt',
label_list='images/labels.txt',
transforms=eval_transforms)
在运行之前我们先改下文件名:

但是运行之后居然有报错,下面是报错图片:

说是索引超出了范围,但是为什么会超出呢?很蒙!是我数据集的格式不对?
果然是我的数据集格式不对,我去了解了一下,发现要用下面的格式

然后labels的是这样的:

但是我不清楚的是他的标注跟我的是不是一样呢,因为我没有标注背景呀,我在标注的时候只是取了道路,不过一想我的应该也应该是二分类,因为我没标的就是背景呗!先这么去做看看!
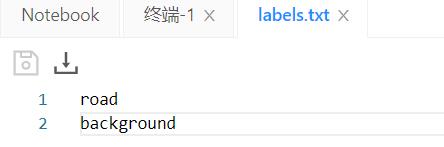
然后我们改写一下数据成上面的格式。
f1 = open("images/train.txt","a")
f2 = open("images/test.txt","a")
f3 = open("images/val.txt","a")
for i in range(1,801):
train_name = "data/"+str(i)+".png"+" "+"label/"+str(i)+".png\\n"
f1.write(train_name)
for a in range(801,1001):
val_name = "data/"+str(a)+".png"+" "+"label/"+str(a)+".png\\n"
f3.write(val_name)
for i in range(1001,1147):
test_name = "data/"+str(i)+".png"+" "+"label/"+str(i)+".png\\n"
f2.write(test_name)
print("done")
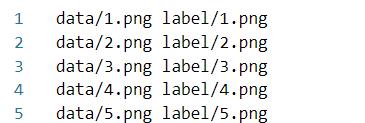
搞定!
然后开始定义吧:
然后接下来就开始定义吧:
train_dataset = pdx.datasets.SegDataset(
data_dir='images',
file_list='images/file_list.txt',
label_list='images/label_list.txt',
transforms=train_transforms,
shuffle=True)
eval_dataset = pdx.datasets.SegDataset(
data_dir='images',
file_list='images/val_list.txt',
label_list='images/labels.txt',
transforms=eval_transforms)
但是这里面出现了报错:

我去翻看了txt文件,发现居然出现了这个情况:

并且数据怎么还多了呢,不过小问题,去掉一下就好了:
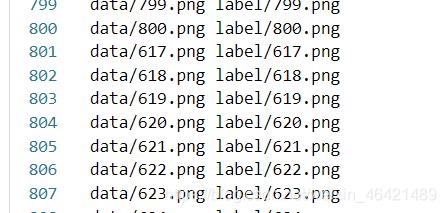
然后我们运行一下:
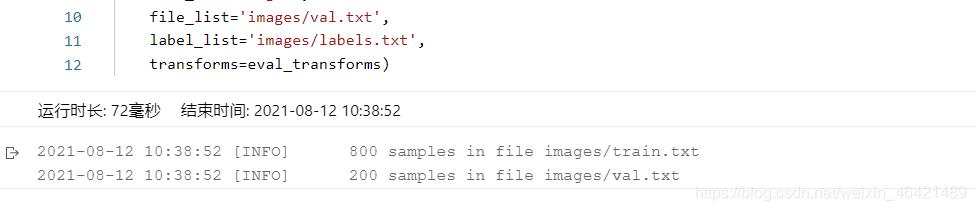
ok,运行成功!!!!!!!
开始训练模型
模型:这里我们选择deeplabv3进行训练,在训练之前我们先看一下这个调用这个模型的api:

然后我们先定义一下,这里我们先跑个4000轮吧,不行的化再改,然后写了train这个api,如下面如视:
num_classes = len(train_dataset.labels)
model = pdx.seg.DeepLabV3P(num_classes=num_classes)
model.train(
num_epochs=4000,
train_dataset=train_dataset,
train_batch_size=32,
eval_dataset=eval_dataset,
learning_rate=0.01,
save_interval_epochs=1,
save_dir='output/deeplab',
use_vdl=True)
但是运行的时候又报错了。。。。。。。。。。。,我们来看看:

这个看不懂呀,看看上面的报错:

这些都啥意思呀!!!我理解的大概意思就是说读入的预训练模型的信息不匹配,这是为啥呢?
后来我想到是不是我的图像处理搞得鬼的:
图像增强时不要加数据剪切,否则会报错,在数据增强中把 T.RandomCrop(),去掉
但是之后又出现了报错:让我去降低batch_size,这里我们给32看看

这里并不是降低的问题呀,我后来都降到2了还是会报错!后来我听人说在gpu上运行有问题,后来我在cpu上运行成功的运行起来了,我先训练着然后我去github上寻找下原因!

然后这里的话,我们训练了一轮后,当想要训练第二轮的时候,发现loss变成0了,然后我们也是得到了我们的模型,下面来预测了。

模型预测
代码实现也是很简单也是很简单的,我们先去加载我们训练好的模型,然后放上我们的测试集,然后就可以了
import paddlex as pdx
model = pdx.load_model('output/deeplab/best_model')
image_name = 'images/data/1001.png'
result = model.predict(image_name)
pdx.seg.visualize(image_name, result, weight=0.4, save_dir='./output/deeplab')
最后我们再来看下效果:

四、 总结
通过这次的大作业我学到了如何去使用paddlex来完成模型的训练和预测,并且学会了如何去使用eiseg做数据集的标准,写markdown文档等等,但是我想这只是个开始,我其实以前接触过paddle但是我的深度学习知识太差了,后来也是补了很多,这次使用paddle就感觉自己可以用起来了,这对我来说就是一个进步,项目还没有结束把还有部署什么的,但是这次的大作业就这样结束了!最后感谢飞桨的这次课程!
最后附上我的ai stdio项目连接
和我的ai stdio 主页
参考:https://aistudio.baidu.com/aistudio/projectdetail/2275923?forkThirdPart=1
以上是关于森说AI:AI创造营大作业--应用paddlex完成对自定义车道路的语义分割的主要内容,如果未能解决你的问题,请参考以下文章