JVM之GC日志分析与对象内存分配回收策略
Posted 活跃的咸鱼
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了JVM之GC日志分析与对象内存分配回收策略相关的知识,希望对你有一定的参考价值。
一. GC日志分析的引入
🐬GC日志分析的重要性:阅读分析虚拟机和垃圾收集器的日志是处理Java虚拟机内存问题必备的基础技能。
🐟垃圾收集日志面临的问题:垃圾收集器日志是一系列人为设定的规则,多少有点随开发者编码时的心情而定,没有任何的“业界标准”可言,换句话说,每个收集器的日志格式都可能不一样。除此以外还有一个麻烦,在JDK 9以前,HotSpot并没有提供统一的日志处理框架,虚拟机各个功能模块的日志开关分布在不同的参数上,日志级别、循环日志大小、输出格式、重定向等设置在不同功能上都要单独解决。
🐳解决方案:直到JDK 9,这种混乱不堪的局面才终于消失,HotSpot所有功能的日志都收归到了“-Xlog”参数上,这个参数的能力也相应被极大拓展了:
-Xlog[:[selector][:[output][:[decorators][:output-options]]]]
🐋-Xlog参数解析:命令行中最关键的参数是选择器(Selector),它由标签(Tag) 和 日志级别(Level) 共同组成。
标签:可理解为虚拟机中某个功能模块的名字,它告诉日志框架用户希望得到虚拟机哪些功能的日志输出。垃圾收集器的标签名称为“gc”,由此可见,垃圾收集器日志只是HotSpot众多功能日志的其中一项,全部支持的功能模块标签名如下所示:
add,age,alloc,annotation,aot,arguments,attach,barrier,
biasedlocking,blocks,bot,breakpoint,bytecode ...
日志级别从低到高:共有Trace,Debug,Info,Warning,Error,Off六种级别,日志级别决定了输出信息的详细程度,默认级别为Info,HotSpot的日志规则与Log4j、SLF4j这类Java日志框架大体上是一致的。另外,还可以使用修饰器(Decorator)来要求每行日志输出都附加上额外的内容,支持附加在日志行上的信息包括:
·time:当前日期和时间。
·uptime:虚拟机启动到现在经过的时间,以秒为单位。
·timemillis:当前时间的毫秒数,相当于System.currentTimeMillis()的输出。
·uptimemillis:虚拟机启动到现在经过的毫秒数。
·timenanos:当前时间的纳秒数,相当于System.nanoTime()的输出。
·uptimenanos:虚拟机启动到现在经过的纳秒数。
·pid:进程ID。
·tid:线程ID。
·level:日志级别。
·tags:日志输出的标签集。
如果不指定,默认值是uptime、level、tags这三个,此时日志输出类似于以下形式:
[3.080s][info][gc,cpu] GC(5) User=0.03s Sys=0.00s Real=0.01s
二. GC的分类 与GC日志结构剖析
GC的分类:针对HotSpot VM的实现,它里面的GC按照回收区域又分为两大种类型:一种是部分收集(Partial GC),一种是整堆收集(Full GC)
部分收集: 不是完整收集整个Java堆的垃圾收集。其中又分为:
- 新生代收集(Minor GC / Young GC) :只是新生代(Eden\\S0,S1) 的垃圾收集
- 老年代收集(Major GC / 0ld GC) :只是老年代的垃圾收集。目前,只有CMS GC会有单独收集老年代的行为。
注意,很多时候Major GC会和FullGC混淆使用,需要具体分辨是老年代回收还是整堆回收。
混合收集(Mixed GC): 收集整个新生代以及部分老年代的垃圾收集。目前,只有G1 GC会有这种行为。
整堆收集(Full GC): 收集整个java堆和方法区的垃圾收集。
🐤1.新生代收集:当Eden区满的时候就会进行新生代收集,所以新生代收集和S0区域和S1区域无关
🐔2.老年代收集和新生代收集的关系: 进行老年代收集之前会先进行一次年轻代的垃圾收集。
原因如下: 一个比较大的对象无法放入新生代,那它自然会往老年代去放,如果老年代也放不下,那会先进行一次新生代的垃圾收集,之后尝试往新生代放,如果还是放不下,才会进行老年代的垃圾收集,之后在往老年代去放,这是一个过程,为什么需要往老年代放,但是放不下而进行新生代垃圾收集的原因,这是因为新生代垃圾收集比老年代垃圾收集更加简单,这样做可以节省性能
🐫3.进行垃圾收集的时候, 堆包含新生代、老年代、元空间/永久代:可以看出Heap后面包含着新生代、老年代、元空间,但是我们设置堆空间大小的时候设置的只是新生代、老年代而已,元空间分开设置的
Heap (堆)
PSYoungGen (Parallel Scavenge收集器新生代) total 9216K,
used 6234K
[0x00000000ff600000,0x0000000100000000, 0x0000000100000000)
eden space (堆中的Eden区默认占比是8) 8192K, 768 used
[0x00000000ff600000, 0x00000000f fc16b08, 0x00000000f fe00000)
from space (堆中的Survivor,这里是From Survivor区默认占比是1) 1024K, 08 used
[0x00000000fff00000, 0x00000000ff f00000, 0x0000000100000000)
to space (堆中的Survivor,这里是to Survivor区默认占比是1,需要先了解一下堆的分配策略)
1024K, 08 used [0x00000000ffe00000, 0x00000000ffe00000, 0x00000000fff00000)
ParOldGen (老年代总大小和使用大小)total 10240K, used 7001K [ 0x00000000fec00000,
0x00000000ff600000,0x00000000ff 600000)
object space (显示个使用百分比) 10240K, 688
used
[0x00000000fec00000, 0x00000000ff2d6630, 0x00000000ff 600000)
PSPermGen (永久代总大小和使用大小)total 21504K, used 4949K [0x00000000f9a00000,
0x00000000faf00000,0x00000000fec00000)
object space (显示个使用百分比,自己能算出来) 21504K, 238 used
[0x00000000f9a00000,0x00000000f9ed55e0, 0x00000000faf00000)
Metaspace used 4000K, capacity 4568K, committed 4864K, reserved 1056768K
class space used 447K, capacity 460K, committed 512K, reserved 1048576K
🐦4. 哪些情况会触发Full GC: 老年代空间不足、方法区空间不足、显示调用System.gc()、 Minior GC进入老年代的数据的平均大小大于老年代的可用内存、大对象直接进入老年代,而老年代的可用空间不足
GC日志结构剖析
🐊1.垃圾收集器
-
" [GC"和"[Full GC"说明了这次垃圾收集的停顿类型,如果有"Full"则说明GC发生了"StopThe World"
-
使用Serial收集 器在新生代的名字是Default New Generation, 因此显示的是" [DefNew’
-
使用ParNew收集器在新生代的名字会变成" [ParNew",意思是"Parallel New Generation"
-
使用Parallel Scavenge收集器在新生代的名字是" [ PSYoungGen",这里的JDK1.7使用的就是PSYoungGen
-
使用Parallel old Generation收集器在老年代的名字是"[ParoldGen"
-
使用G1收集器的话,会显示为" garbage-first heap"
-
Allocation Failure: 表明本次引起GC的原因是因为在年轻代中没有足够的空间能够存储新的数据了。
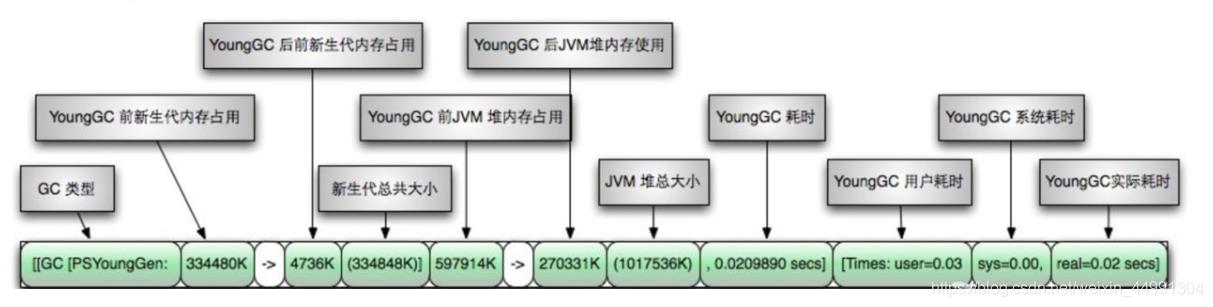
🐈2.GC前后情况
[PSYoungGen: 5986K- >696K( 8704K)] 5986K- >704K(9216K)
中括号内: GC回收前年轻代堆大小,回收后堆大小,( 年轻代堆总大小)
括号外: GC回收前年轻代和老年代大小,回收后大小,( 年轻代和老年代总大小)
🐾3.GC时间
GC日志中有三个时间: user, sys和real
user :进程执行用户态代码(核心之外)所使用的时间。这是执行此进程所使用的实际CPU时间,其他进程和此进程阻塞的时间并不包括在内。在垃圾收集的情况下,表示GC线程执行所使用的CPU总时间。
sys :进程在内核态消耗的CPU时间,即在内核执行系统调用或等待系统事件所使用的CPU时间
real :程序从开始到结束所用的时钟时间。这个时间包括其他进程使用的时间片和进程阻塞的时间(比如等待I/0完成)。对于并行gc,这个数字应该接近(用户时间+系统时间)除以垃圾收集器使用的线程数。
由于多核的原因,一般的GC事件中,real time是小于sys + user time的, 因为一 般是多个线程并发的去做GC, 所以real time是要小于sys+user time的。 如果real>sys+user的话,则你的应用可能存在下列问题: I0负载非常重或者是CPU不够用。
三. JDK1.9以前的日志分析
🐲内存分配与垃圾回收的参数列表
- XX: +PrintGC
输出GC日志。类似: -verbose :gc
- XX: +PrintGCDetails
输出GC的详细日志
-XX: +Prin tGCTimeStamps
输出GC的时间戳(以基准时间的形式)
- XX: +PrintGCDateStamps
输出GC的时间戳(以日期的形式,如2013-05-
04T21 :53:59.234+0800)
- XX: +PrintHeapAtGC
在进行GC的前后打印出堆的信息
-Xloggc: ../1ogs/gc.1og
日志文件的输出路径
🐼打开GC日志:-verbose:gc 这个参数只会显示总的GC堆的变化如下所示:

参数解析:
GC、Full GC: GC的类型,GC只在新生代 上进行,Full GC包括永生代,新生代, 老年代。
Allocation Failure: GC发生的原因。
80832K-> 19298K:堆在GC前堆内存的使用大小和GC后使用的大小。227840k:堆的总大小。
0.0084018 secs: GC持续的时间。
🐁打开GC日志:-verbose:gc- XX: +PrintGCDetails

参数解析:
GC,Full FC: 同样是Gc的类型
Allocation Failure: GC原因表明本次引起GC的原因是因为在年轻代中没有足够的空间能够存储新的数据了。
pSYoungGen:使用了Parallel scavenge并 行垃圾收集器的新生代GC前后大小的变化
ParoldGen:使用了Parallel Old并 行垃圾收集器的老年代GC前后大小的变化
Metaspace:元数据区GC前后大小的变化,JDK1.8中引入 了元数据区以替代永久代
XXX secs:指GC花费的时间
Times: user:指的是垃圾收集器花费的所有CPU时间,sys: 花费在等待系统调用或系统事件的时间,real:GC从开始到结束的时间,包括其他进程占用时间片的实际时间。
🐡打开GC日志:-verbose:gc- XX: +PrintGCDetails- XX: +PrintGCTimeStamps- XX: +PrintGCDateStamps
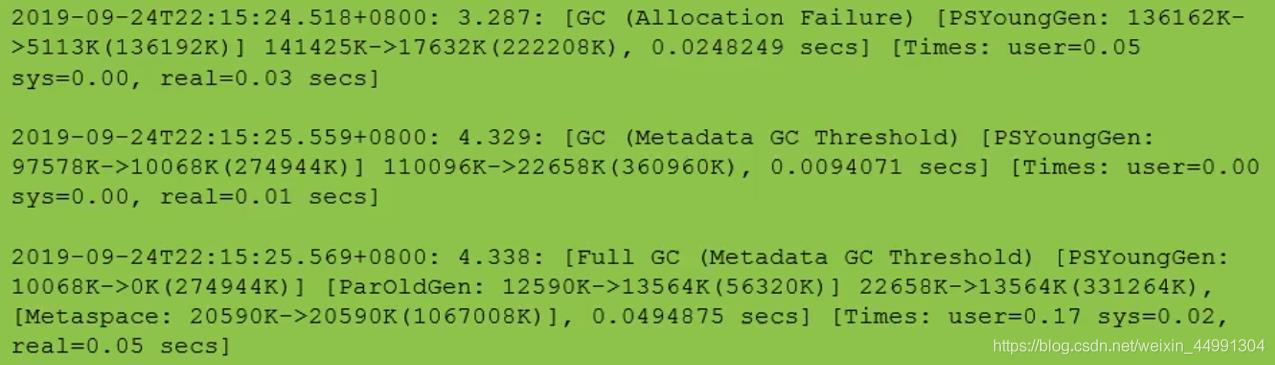
参数解析: 和上面的参数差不多就是加上了日期和时间
如果想把GC日志存到文件的话,是 下面这个参数:
-Xloggc: +路径名
🌁MinorGC日志分析实战
对下面这段GC日志逐断分析
2020-11-20T17 :19:43.265-0800: 0.822: [GC (ALLOCATION FAILURE)
[PSYOUNGGEN:76800K- >8433K ( 89600K)] 76800K->8449K(294400K),
0. 0088371 SECS] [TIMES:
USER=0.02 SYS=0.01, REAL=0.01 SECS]
2020-11-20T17:19:43.265-0800 :日志打印时间
0.822: gc发生时,Java虚拟机启动以来经过的秒数
[GC(Allocation Failure) :发生了一次垃圾回收,这是一次Minior GC。
它不区分新生代还是老年代GC,括号里的内容是gc发生的原因,
这里的Allocation Failure的原因
是新生代中没有足够区域能够存放需要分配的数据而失败
[PSYoungGen:76800K->8433K(89600K):PSYoungGen:表示GC发生的区域,
区域名称与使用的GC收集器是密切相关的
76800K->8433K(89600K):
GC前该内存区域已使用容量->GC后该区域使用容量(该区域总容量)
如果是新生代,总容量则会显示整个新生代内存的9/10,即eden+from/to区
如果是老年代,总容量则是全身内存大小,无变化
76800K->8449K(294400K)
在显示完区域容量GC的情况之后,会接着显示整个堆内存区域的GC情况:
GC前堆内存已使用容量->GC后堆内存容量(堆内存总容量),
并且堆内存总容量 = 9/10 新生代 + 老年代,
然后堆内存总容量肯定小于初始化的内存大小
0. 0088371 SECS] :整个GC花费的时间单位是秒
[Times:user=0.02 sys=0.01,real=0.01 secs]
user:指CPU工作在用户态所花费的时间
sys:指CPU工作在内核态所花费的时间
real:指在此次事件中所花费的总时间
🌊FULL GC日志分析实战
2020-11-20T17 :19:43.794-0800: 1.351: [FULL GC (METADATA GC THRESHOLD)
[ PSYOUNGGEN: 10082K- >0K( 89600K)] [PAROLDGEN: 32K- >9638K (204800K) ]
10114K- >9638K( 294400K) ,
[METASPACE: 20158K->20156K(1067008K)], 0. 0285388 SECS] [ TIMES: USER=0.11
SYS=0.00, REAL=0.03 SECS]
2020-11-20T17:19:43.265-0800 :日志打印时间
1.351: gc发生时,Java虚拟机启动以来经过的秒数
[FULL GC (METADATA GC THRESHOLD)
括号中是gc发生的原因,原因:Metaspace区不够用了。
除此之外,还有另外两种情况会引起Full GC,如下:
1、Full GC(FErgonomics)
原因:JVM自适应调整导致的GC
2、Full GC(System)
原因:调用了System.gc()方法
[PSYoungGen: 100082K->0K(89600K)]
PSYoungGen:表示GC发生的区域在年轻代,
使用的是Parallel Scavenge收集器
10082K->0K(89600K):
GC前该内存区域已使用容量->GC后该区域使用容量(该区域总容量)
ParOldGen:32K->9638K(204800K)
老年代区域没有发生GC,因此本次GC是metaspace引起的
10114K->9638K(294400K),
整个堆内存区域的GC情况:
GC前堆内存已使用容量为10114K->GC后堆内存容量为9638K(堆内存总容量为294400K)
[Meatspace:20158K->20156K(1067008K)],
metaspace GC 回收了2K空间
0. 0285388 SECS] 整个GC花费的时间单位是秒
[ TIMES: USER=0.11
SYS=0.00, REAL=0.03 SECS]
user:指CPU工作在用户态所花费的时间
sys:指CPU工作在内核态所花费的时间
real:指在此次事件中所花费的总时间
四. JDK1.9以后的日志分析
下面举几个例子,展示在JDK 9统一日志框架前、后是如何获得垃圾收集器过程的相关信息,以下均以JDK 9的G1收集器(JDK 9下默认收集器就是G1,所以命令行中没有指定收集器)为例。
1)🐻 查看GC基本信息,在JDK 9之前使用-XX:+PrintGC,JDK 9后使用-Xlog:gc:
[0.222s][info][gc] Using G1
[2.825s][info][gc] GC(0) Pause Young (G1 Evacuation Pause) 26M->5M(256M) 355.623ms
[3.096s][info][gc] GC(1) Pause Young (G1 Evacuation Pause) 14M->7M(256M) 50.030ms
[3.385s][info][gc] GC(2) Pause Young (G1 Evacuation Pause) 17M->10M(256M) 40.576ms
2)🐮 查看GC详细信息,在JDK 9之前使用-XX:+PrintGCDetails,在JDK 9之后使用-X-log:gc*,用通配符*将GC标签下所有细分过程都打印出来,如果把日志级别调整到Debug或者Trace还将获得更多细节信息:
[0.233s][info][gc,heap] Heap region size: 1M
[0.383s][info][gc ] Using G1
[0.383s][info][gc,heap,coops] Heap address: 0xfffffffe50400000, size: 4064 MB, Compressed Oops mode: Non-zero based:
0xfffffffe50000000, Oop shift amount: 3
[3.064s][info][gc,start ] GC(0) Pause Young (G1 Evacuation Pause)
gc,task ] GC(0) Using 23 workers of 23 for evacuation
[3.420s][info][gc,phases ] GC(0) Pre Evacuate Collection Set: 0.2ms
[3.421s][info][gc,phases ] GC(0) Evacuate Collection Set: 348.0ms
gc,phases ] GC(0) Post Evacuate Collection Set: 6.2ms
[3.421s][info][gc,phases ] GC(0) Other: 2.8ms
gc,heap ] GC(0) Eden regions: 24->0(9)
[3.421s][info][gc,heap ] GC(0) Survivor regions: 0->3(3)
3)🐒 查看GC前后的堆、方法区可用容量变化,在JDK 9之前使用-XX:+PrintHeapAtGC,JDK 9之后使用-Xlog:gc+heap=debug:
4)🐹 查看GC过程中用户线程并发时间以及停顿的时间,在JDK 9之前使用-XX:+PrintGCApplicationConcurrentTime以及-XX:+PrintGCApplicationStoppedTime,JDK 9之后使用-Xlog:
safepoint:
[1.376s][info][safepoint] Application time: 0.3091519 seconds
[1.377s][info][safepoint] Total time for which application threads were stopped: 0.0004600 seconds, Stopping threads took:
0.0002648 seconds
[2.386s][info][safepoint] Application time: 1.0091637 seconds
[2.387s][info][safepoint] Total time for which application threads were stopped: 0.0005217 seconds, Stopping threads took:
0.0002297 seconds
🐩 下表给出了全部在JDK 9中被废弃的日志相关参数及它们在JDK
9后使用-Xlog的代替配置形式。
| JDK9前日志参数 | JDK 9后配置形式 |
|---|---|
| G1 PrintHeapRegions | Xlog: gc+region=trace |
| G1 PrintRegionLivenessInfo | Xlog:gc+liveness=trace |
| G1 SummarizeConcMark | Xlog:gc+ marking=trace |
| G1 SummarizeRSetStats | Xlog:gc+remset*=trace |
| GCLogFileSize, NumberOfGCLogFiles, UseGCLog | Xlog:gc* :file=< file>::filecount=< count> ,filesize=< fileFile Rotationsize in kb> |
| PrintAdaptiveSizePolicy | Xlog:gc +ergo*=trace |
| PrintClassHistogramAfterFullGC | Xlog:classhisto* =trace |
| PrintClassHistogram BeforeFullGC | Xlog:classhisto* =trace |
| PrintGCApplicationConcurrentTime | Xlog:safepoint |
| PrintGCApplicationStoppcdTime | Xlog isafepoint |
| PrintGCDateStamps | 使用time修饰器 |
| PrintGCTask TimeStamps | Xlog:gc+task=trace |
| PrintGCTimeStamps | 使用uptime修饰器 |
| PrintHeapAtGC | Xlog:gc +heap= debug |
| PrintHeapAtGCExtended | Xlog:gc+heap=trace |
| PrintJNIGCStalls | Xlog:gc+jni=debug |
| PrintOldPLAB | Xlog:gc+plab-trace |
| PrintParallelOldGCPhaseTimes | Xlog:gc +phases=trace |
| PrintPLAB | Xlog;gc+ plab=trace |
| PrintPromotionFailure | Xlog:gc+promotion=debug |
| PrintReferenceGC | Xlog:gc+ ref-debug |
| PrintStringDeduplicationStatistics | Xlog:gc +stringdedup |
| Print Taskqueue | Xlog:gc+ task+ stats=trace |
| Print TenuringDistribution | Xlog:gc+agc=trace |
| PrintTerm inationStats | Xlog:ge+ task+ stats=debug |
| PrintTLAB | Xlog;gc+tlab=trace |
| TraceAdaptiveGCBoundary | Xlog:heap+ergo=debug |
| TraceDynamicGC Threads | Xlog;gc+task=trace |
| TraceMetadataHumongousAllocation | Xlog:gc+ metaspace+alloc- debug |
| G1TraceConcRefinement | Xlog:gc+ refine=debug |
| G1TraceEagerReclaimHumongousObjects | Xlog;gc+humongous= debug |
| G1TraceStringSymbolTableScrubbing | Xlog:gc +stringtable=trace |
五. 对象内存分配回收策略
内存分配策略
对象的内存分配,从概念上讲,应该都是在堆上分配,有部分情况是在栈上分配。在经典分代的设计下,新生对象通常会分配在新生代中,少数情况下(例如对象大小超过一定阈值)也可能会直接分配在老年代。对象分配的规则并不是固定的,《Java虚拟机规范》并未规定新对象的创建和存储细节,这取决于虚拟机当前使用的是哪一种垃圾收集器,以及虚拟机中与内存相关的参数的设定。
😹1.对象优先在Eden分配
大多数情况下,对象在新生代Eden区中分配。当Eden区没有足够空间进行分配时,虚拟机将发起一次Minor GC。
//虚拟机参数设置: -verbose:gc -Xms20M -Xmx20M -Xmn10M -Xlog:gc* -XX:SurvivorRatio=8 -XX:+UseParallelGC
public class TestOldObject {
public static final int _1MB=1024*1024;
public static void main(String[] args) {
byte[] allocation1,allocation2,allocation3;
allocation1=new byte[_1MB/4];
allocation2=new byte[_1MB*4];
allocation3=new byte[_1MB*4];
allocation3=new byte[_1MB*4];
}
}
[0.018s][info][gc,heap,coops] Heap address: 0x00000000fec00000, size: 20 MB, Compressed Oops mode: 32-bit
[0.201s][info][gc,heap,exit ] Heap
[0.201s][info][gc,heap,exit ] PSYoungGen total 9216K, used 6703K [0x00000000ff600000, 0x0000000100000000, 0x0000000100000000)
[0.201s][info][gc,heap,exit ] eden space 8192K, 81% used [0x00000000ff600000,0x00000000ffc8bf50,0x00000000ffe00000)
我们从控制台输出可以验证结论对象优先在Eden分配
🙈2.大对象直接进入老年代
大对象就是指需要大量连续内存空间的Java对象,最典型的大对象便是那种很长的字符串,或者元素数量很庞大的数组如下所示。
//-verbose:gc -Xms20M -Xmx20M -Xmn10M
//-Xlog:gc* -XX:SurvivorRatio=8 -XX:+UseParallelGC
public class TestOldObject {
public static final int _1MB=1024*1024;
public static void main(String[] args) {
byte[] allocation=new byte[8*_1MB];
}
}
控制台输出:
[0.172s][info][gc,heap,exit ] ParOldGen total 10240K, used 8192K [0x00000000fec00000, 0x00000000ff600000, 0x00000000ff600000)
[0.172s][info][gc,heap,exit ] object space 10240K, 80% used [0x00000000fec00000,0x00000000ff400010,0x00000000ff600000)
我们从日志分析中可以发现 allocation对象直接被分配进了老年代
注意:
大对象对虚拟机的内存分配来说就是一个不折不扣的坏消息,比遇到一个大对象更加坏的消息就是遇到一群“朝生夕灭”的“短命大对象”,我们写程序的时候应注意避免。在Java虚拟机中要避免大对象的原因是,在分配空间时,它容易导致内存明明还有不少空间时就提前触发垃圾收集,以获取足够的连续空间才能安置好它们,而当复制对象时,大对象就意味着高额的内存复制开销。HotSpot虚拟机提供了-XXPretenureSizeThreshold参数,指定大于该设置值的对象直接在老年代分配,这样做的目的就是避免在Eden区及两个Survivor区之间来回复制,产生大量的内存复制操作。
👹3 长期存活的对象将进入老年代
活对象应当放在新生代,哪些存活对象放在老年代中。为做到这点,虚拟机给每个对象定义了一个对象年龄(Age)计数器,存储在对象头中。对象通常在Eden区里诞生,如果经过第一次
Minor GC后仍然存活,并且能被Survivor容纳的话,该对象会被移动到Survivor空间中,并且将其对象年龄设为1岁。对象在Survivor区中每熬过一次Minor GC,年龄就增加1岁,当它的年龄增加到一定程度(默认为15),就会被晋升到老年代中。对象晋升老年代的年龄阈值,可以通过参数-XX:MaxTenuringThreshold设置。
🙉4 动态对象年龄判定
为了能更好地适应不同程序的内存状况,HotSpot虚拟机并不是永远要求对象的年龄必须达到XX:MaxTenuringThreshold才能晋升老年代,如果在Survivor空间中相同年龄所有对象大小的总和大于
Survivor空间的一半,年龄大于或等于该年龄的对象就可以直接进入老年代,无须等到-XX:MaxTenuringThreshold中要求的年龄。
🐰5 空间分配担保
在发生Minor GC之前,虚拟机必须先检查老年代最大可用的连续空间是否大于新生代所有对象总空间,如果这个条件成立,那这一次Minor GC可以确保是安全的。如果不成立,则虚拟机会先查看-XX:HandlePromotionFailure参数的设置值是否允许担保失败(Handle Promotion Failure);如果允许,那会继续检查老年代最大可用的连续空间是否大于历次晋升到老年代对象的平均大小,如果大于,将尝试进行一次Minor GC,尽管这次Minor GC是有风险的;如果小于,或者-XX:HandlePromotionFailure设置不允许冒险,那这时就要改为进行一次Full GC。
解释一下“冒险”是冒了什么风险:新生代使用复制收集算法,但为了内存利用率,只使用其中一个Survivor空间来作为轮换备份,因此当出现大量对象在Minor GC后仍然存活的情况——最极端的情况就是内存回收后新生代中所有对象都存活,需要老年代进行分配担保,把Survivor无法容纳的对象直接送入老年代,这与生活中贷款担保类似。
老年代要进行这样的担保,前提是老年代本身还有容纳这些对象的剩余空间,但一共有多少对象会在这次回收中活下来在实际完成内存回收之前是无法明确知道的,所以只能取之前每一次回收晋升到老年代对象容量的平均大小作为经验值,与老年代的剩余空间进行比较,决定是否进行Full GC来让老年代腾出更多空间。
取历史平均值来比较其实仍然是一种赌概率的解决办法,也就是说假如某次Minor GC存活后的对象突增,远远高于历史平均值的话,依然会导致担保失败。如果出现了担保失败,那就只好老老实实地重新发起一次Full GC,这样停顿时间就很长了。虽然担保失败时绕的圈子是最大的,但通常情况下都还是会将-XX:HandlePromotionFailure开关打开,避免Full GC过于频繁。
注意
JDK 6 Update 24之后的规则变为只要老年代的连续空间大于新生代对象总大小或者历次晋升的平均大小,就会进行Minor GC,否则将进行Full GC。
以上是关于JVM之GC日志分析与对象内存分配回收策略的主要内容,如果未能解决你的问题,请参考以下文章