大数据存储基石-HBase2.4.4全方位解析
Posted roykingw
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据存储基石-HBase2.4.4全方位解析相关的知识,希望对你有一定的参考价值。
大数据存储基石-HBase
HBase全解析
=== 楼兰 ===只做最纯粹的学习
一、关于HBase
1、HBase是什么?
HBase的官网地址: https://hbase.apache.org/ 标志是一个漂亮的虎鲸

官网上对HBase的介绍非常的简单直接:
Apache HBase™ is the Hadoop database, a distributed, scalable, big data store.
Apache HBase是一个Hadoop上的数据库。一个分布式,可扩展的大数据存储引擎。HBase有个最明显的特征:
1、HBase支持非常大的数据集,数十亿行*数百万列。如此庞大的数据量级,足以撑爆我们在J2EE阶段学习过的所有数据存储引擎。
2、HBase支持大数据量的随机、实时读写操作。在海量数据中,可以实现毫秒级的数据读写。
3、HBase从一开始就深度集成了Hadoop。HBase基于Hadoop进行文件持久化,还继承了Hadoop带来的强大的可扩展性。Hadoop可以基于廉价PC机组建庞大的应用集群。HBase也深度集成了Hadoop的MapReduce计算框架,并且也正在积极整合Spark。这使得HBase能够很轻松的融入到整个大数据生态圈。
4、HBase的数据是强一致性的,从CAP理论来看,HBase是属于CP的。这种设计可以让程序员不需要担心脏读、幻读这些事务最终一致性带来的问题。
5、最后最重要的还是HBase的框架性能是足够高效的。HBase的开源社区非常活跃,他的性能经过很多大型商业产品的验证。Facebook的整个消息流转的基础设施就构建于HBase之上。
可以说正是Hadoop+HBase一起提供的强悍无敌的性能,支撑起了大数据的整个技术体系。这就好比必须要先有操作系统,能够通过文件、内存来存储资料,后面开发出来的各种应用程序才有用武之地。
聊到了Hadoop+HBase,就不得不说Google发布的三篇论文。长久以来,各大互联网公司都在注重构建服务,而对于业务数据,很难达到海量这个级别。而对于海量数据的处理,还只是Google这样的搜索引擎巨头在进行深入的研究。
2003年,Google发布Google File System论文,(GFS)这是一个可扩展的分布式文件系统,用于大型的、分布式的、对大量数据进行访问的应用。它运行于廉价的普通硬件上,提供容错功能。从根本上说:文件被分割成很多块,使用冗余的方式储存于商用机器集群上。
紧随其后,2004年,Google公布了MapReduce论文,论文描述了大数据的分布式计算方式,主要思想是将任务分解然后在多台处理能力较弱的计算节点中同时处理,然后将结果合并从而完成大数据处理。
接着到了2006年,Google公布了BigTable论文,BigTable是一种构建于GFS和MapReduce之上的多维稀疏图管理工具。
正是这三篇论文,掀起了开源软件的大数据热潮。人们根据GFS,开发出了HDFS文件存储。MapReduce计算框架,也成了海量数据处理的标准。而HDFS与MapReduce结合在一起,形成了Hadoop。而BigTable更是启发了无数的NoSQL数据库。而HBase正是继承了正统的BigTable思想。所以,Hadoop+HBase是模拟了Google处理海量网页的三大基石实现的,他们也就成了开源大数据处理的基石。
2、HBase的数据结构
HBase也可以作为一个数据库使用,但是为了应对海量数据,他存储数据的方式与我们理解的传统关系型数据库有很大的区别。虽然他也有表、列这样的逻辑结构,但是整体上,他是以一种k-v键值对的方式来存储数据的。
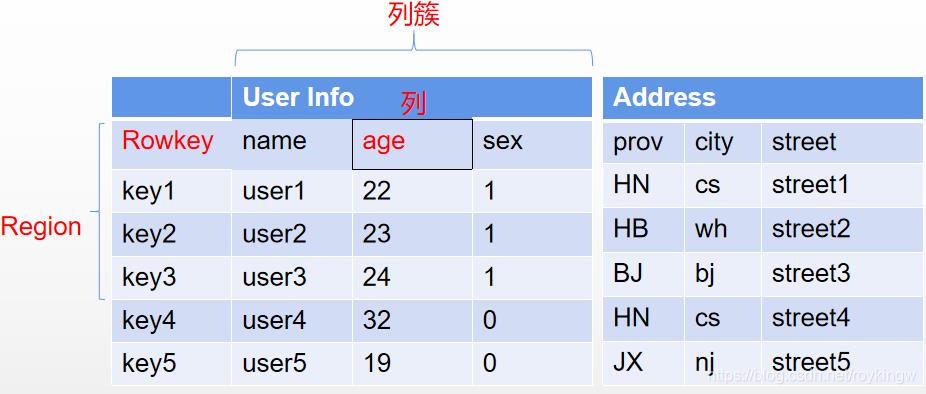
纵向来看,HBase中的每张表由Rowkey和若干个列族或者称为列簇组成。其中Rowkey是每一行数据的唯一标识,在对数据进行管理时,必须自行保证Rowkey的唯一性。接下来HBase依然会以不同的列来管理数据,但是这些列分别归属于不同的列簇。在HBase中,同一张表的数据,只需要保证列簇是相同的,而列簇下的列,可以是不相同的。所以由此可以扩展出非常多的列。在HBase中,对于同一张表,不建议定义过多的列簇,通常不要超过三个。而更多的数据,可以以列的方式来扩展。
从横向来看,HBase中的记录,会划分为一个一个的Region,存储在不同的RegionServer上。并且会在不同的RegionServer之前形成备份,以Region为单位提供了故障后自动恢复的机制。
最后,从整体来看,HBase虽然还是以HDFS作为文件存储,但是他存储的数据不再是简单的文本文件,而是经过HBase优化压缩过的二进制文件,所以他的存储文件通常是不能够直接查看的。
3、HBase的基础架构
HBase整体的基础架构如下图:
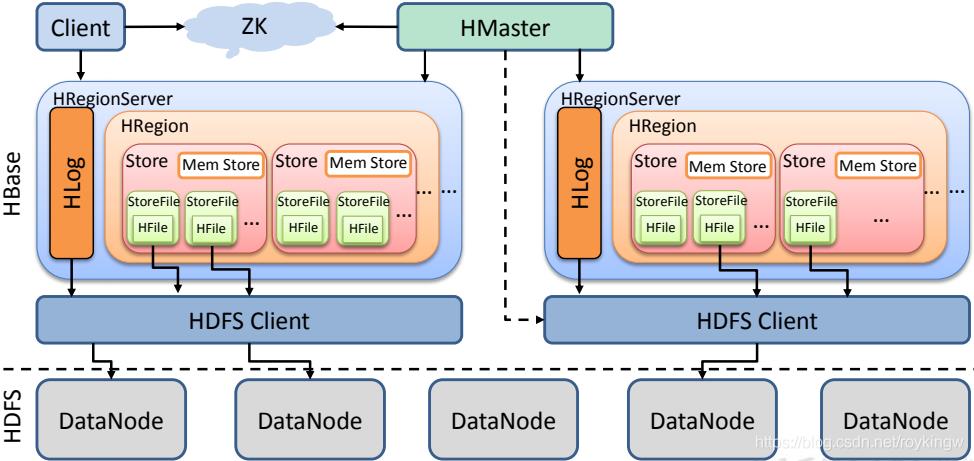
其中,
- client客户端包含了访问HBase的接口,另外也维护了对应的缓存来加速对HBase的访问。
- RegionServer直接对接用户的读写请求,是真正干活的节点。他会将数据以StoreFile的形式存储到不同的HDFS目录中。
- HMaster主要是维护一些集群的元数据信息,同时监控RegionServer的服务状态,并且通过Zookeeper提供集群服务,向客户端暴露集群的服务端信息。
4、HBase适用场景
还记得我们之前讲过的Hive框架吗?这里不妨拿Hive来比较一下,有助于我们理解HBase的适用场景。
Hive提供了基于SQL的对海量数据进行查询统计的功能,但是Hive不存储数据,所有数据操作都是对HDFS上的文件进行操作,所以他对数据的查询操作能做的优化比较有限。同时Hive也无法直接管理数据,对数据的管理依赖于MapReduce,所以延迟非常高。所以Hive通常只适用于一些OLAP的场景,并且通常是与其他组件结合一起进行使用。
而HBase与Hive的区别就非常明显。HBase基于HDFS来存储数据,但是他存储的数据都是经过自己优化索引后的数据,所以他对数据的存储是非常高效的,比HDFS直接存储文件的性能要高很多,可以作为整个大数据的存储基石。而HBase以类似于Redis的列式存储来管理数据,对数据的增删改都会非常高效,可以达到毫秒级响应。同时,也提供了完善的客户端API,所以他完全可以作为传统意义上的数据库使用,适用于大部分的OLTP的场景。但是他的缺点也比较明显,基于列式存储的数据,天生就不太适合大规模的数据统计,所以在很多OLAP的场景,需要结合其他一些组件如spark、hive等,来提供大规模数据统计的功能。
在后面的实战部分,我们不光要理解HBase这个产品,更要理解他与其他大数据组件如何合作。
二、HBase安装
1、实验环境与前置软件
实验环境:准备了三台服务器,预装CentOS7,分别分配机器名 hadoop01,hadoop02,hadoop03。IP地址不重要,因为集群都会通过机器名来配置。三台服务器需要配置时间同步,这个很重要。在后面的课程中预备在hadoop01机器上安装HBase的HMaster,所以需要配置hadoop01到三台机器的免密登录。
免密登录的配置方式: 在hadoop01上生成秘钥: ssh-keygen。然后将密钥分发到不同的机器 ssh-copy-id hadoop02。这样在hadoop01机器上,使用ssh hadoop02就不需要再输入密码了。
前置必须安装的软件:JDK8;Hadoop采用3.2.2版本;Spark采用3.1.1版本。
可选的软件:hadoop01上安装mysql服务,三台机器上安装spark集群,采用3.1.1版本。在hadoop02机器上安装hive3.1.2版本,并部署hive服务hiveserver2。(这些软件不是必须的,但是我们在学习HBase时会用到)
2、安装Zookeeper
HBase需要依赖Zookeeper来进行集群内的数据协调。虽然HBase的发布包中内置了Zookeeper,但是在搭建集群时,通常会另外搭建一个Zookeeper集群,减少组件之间的直接依赖。
到Zookeeper官网下载zookeeper3.5.8版本(zookeeper版本不能低于3.4.x)。apache-zookeeper-3.5.8-bin.tar.gz。上传到服务器后,解压到/app/zookeeper目录。然后进入zookeeper的conf目录。
mv zoo_sample.cfg zoo.cfg
vi zoo.cfg
修改zookeeper的数据目录
dataDir=/app/zookeeper/data
增加集群节点配置
server.1=hadoop01:2888:3888
server.2=hadoop02:2888:3888
server.3=hadoop03:2888:3888
修改完成后,将zookeeper目录整体分发到集群中的三台服务器上。然后需要在zookeeper的数据目录/app/zookeeper/data中增加一个myid文件。文件的内容就是当前服务器在zookeeper中的节点ID。例如Hadoop01机器的myid是1,Hadoop02机器的myid是2,Hadoop03机器的myid是3。
配置完成后,启动zookeeper集群: bin/zkServer.sh start。 启动完成后,使用jsp指令能看到一个QuorumPeerMain进程,表示集群启动成功。
2、安装HBase
可以到 https://hbase.apache.org/downloads.html 页面下载对应的HBase。选择HBase版本时,需要注意的是要与Hadoop版本兼容。这是目前官网上贴出的hadoop版本兼容表格:
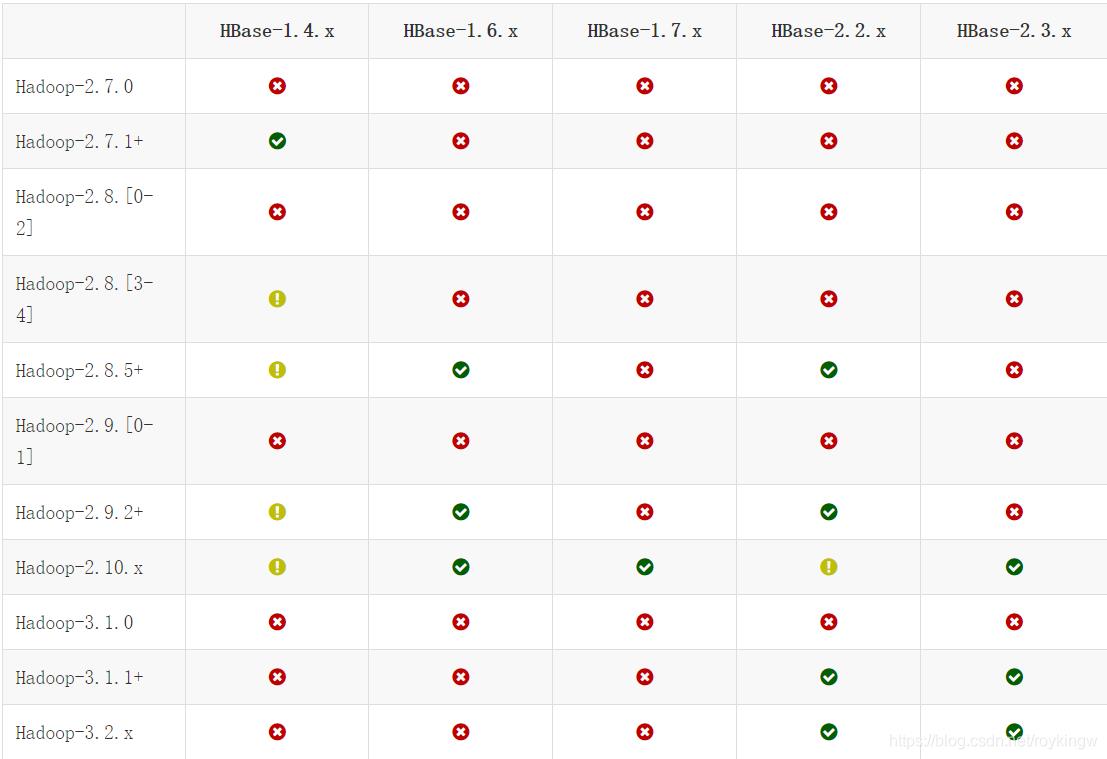
我们这次就选择目前最新的HBase2.4.4版本。(其实要注意,在工作中通常都不建议使用最新的版本)
3、搭建HBase集群模式
下载HBase部署包: hbase-2.4.4-bin.tar.gz,上传到服务器hadoop01。
1 解压后移动到/app/hbase目录。
tar -zxvf hbase-2.4.4-bin.tar.gz
mv hbase-2.4.4 /app/hbase
进入hbase的conf配置目录,修改配置文件。
2 先修改hbase-env.sh。在文件最后加入如下配置:
export JAVA_HOME=/app/java/jdk1.8.0_212
#是否使用HBase内置的ZK。默认是true。
export HBASE_MANAGES_ZK=false
3 修改hbase-site.xml,加入如下配置
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoop01:8020/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.master.port</name>
<value>16000</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop01:2181,hadoop02:2181,hadoop03:2181</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/app/zookeeper/data</value>
</property>
</configuration>
这里配置了一个hbase在hdfs上的根目录。这个目录不需要手动创建,并且最好保证这个目录在HDFS上不存在。
4 配置regionservers文件,在文件里列出集群中所有的节点。
hadoop01
hadoop02
hadoop03
5 同步Hadoop的配置文件。为了保证文件内容一致,采用软连接的方式。
ln -s /app/hadoop/hadoop-3.2.2/etc/hadoop/core-site.xml /app/hbase/hbase-2.4.4/conf/
ln -s /app/hadoop/hadoop-3.2.2/etc/hadoop/hdfs-site.xml /app/hbase/hbase-2.4.4/conf/
6 将hbase整体分发到其他服务器
scp -r /app/hbase/ root@hadoop02:/app
scp -r /app/hbase/ root@hadoop03:/app
7、配置Hbase环境变量。将HBase安装目录配置到环境变量中,并将bin目录配置到PATH环境变量
vi ~/.bash_profile
增加 export HBASE_HOME=/app/hbase/hbase-2.4.4
并在PATH变量中增加 $HBASE_HOME:BIN
8 启动hbase
bin/start-hbase.sh
启动完成后,使用jps指令能够查看到在当前机器上启动了HMaster进程。三台机器上都启动了HRegionServer进程。
然后可以访问HBase的管理页面: http://hadoop01:16010 查看集群的状态。

注意:
1、三台服务必须要进行时钟同步,否则启动hbase时会报错。抛出ClockOutOfSyncException异常。
2、在官方文档中提到, HBase是基于Hadoop的,所以HBase内置了Hadoop的jar包。但是jar包的版本要跟实际部署的hadoop一致。例如我们使用的HBase2.4.4版本,内置的Hadoop的jar包版本都是2.10.0的。在实际部署时,最好使用hadoop集群中的jar包。但是我们在学习过程中,这个jar包版本不一致并没有带来什么问题,所以就没有去替换了。但是实际部署时要注意。
3、部署完成后,可以在HDFS上看到HBase的元数据。/hbase
三、HBase基础操作
关于HBase的使用,在官网上有一个很重要的文档,下载地址 https://hbase.apache.org/apache_hbase_reference_guide.pdf 这是学习HBase最好的资料。不过这个资料是全英文的,并且内容非常非常多,需要有一定的理解能力。
1> 基础指令
1、使用HBase的客户端:
#查看HBase基础指令
[root@192-168-65-174 hbase-2.4.4]# bin/hbase --help
#hbase命令行
[root@192-168-65-174 hbase-2.4.4]# bin/hbase shell
#查看帮助
hbase:001:0> help
#列出已有的表
hbase:002:0> list
2、基础的表操作
#创建表 user表,有一个列簇 basicinfo
hbase:003:0> create 'user','basicinfo'
#插入一条数据
hbase:004:0> put 'user','1001','basicinfo:name','roy'
hbase:005:0> put 'user','1001','basicinfo:age',18
hbase:006:0> put 'user','1001','basicinfo:salary',10000
#插入第二条数据
hbase:007:0> put 'user','1002','basicinfo:name','sophia'
hbase:008:0> put 'user','1002','basicinfo:sex','female'
hbase:009:0> put 'user','1002','basicinfo:job','manager'
#插入第三条数据
hbase:005:0> put 'user','1003','basicinfo:name','yula'
hbase:006:0> put 'user','1003','basicinfo:school','phz school'
3、数据操作
#按照RowKey,查找单条记录
hbase:007:0> get 'user','1001'
hbase:011:0> get 'user','1001','basicinfo:name'
#按照版本查询数据,每次put都会给这条数据的VERSIONS+1
hbase:031:0> get 'user','1001',{COLUMN => 'basicinfo:name',VERSIONS=>3}
#使用scan,查询多条记录
hbase:008:0> scan 'user'
hbase:009:0> scan 'user',{STARTROW => '1001',STOPROW => '1002'}
1、HBase查询数据只能依据Rowkey来进行查询,而Rowkey是由客户端直接指定的,所以在使用HBase时, Rowkey如何设计非常重要,要带上重要的业务信息。
2、scan指令后面的查询条件,STARTROW和STOPROW是必须大写的。查询的结果是左开右闭的。3、其他查询数据的操作可以使用help ‘get’ 或者 help ‘scan’,来查看更多的查询方式。例如对数据进行过滤
#查看表结构 这个结果很重要。列出了列簇的所有属性。
hbase:012:0> desc 'user'
Table user is ENABLED
user
COLUMN FAMILIES DESCRIPTION
{NAME => 'basicinfo', BLOOMFILTER => 'ROW', IN_MEMORY => 'false', VERSIONS => '1', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', COMPRESSION => 'NONE', TTL => 'FOREVER',
MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE => '0'}
#查询表中的记录数。
hbase:013:0> count 'user'
#修改表结构
hbase:019:0> alter 'user',{NAME => 'basicinfo',VERSIONS => 3}
hbase:020:0> desc 'user'
COLUMN FAMILIES DESCRIPTION
{NAME => 'basicinfo', BLOOMFILTER => 'ROW', IN_MEMORY => 'false', VERSIONS => '3', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', COMPRESSION => 'NONE', TTL => 'FOREVER',
MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE => '0'}
#删除某一列
delete 'user','1002','basicinfo:sex'
#删除某一条数据
deleteall 'user','1003'
#清空表数据
truncate 'user'
#删除表 删除之前需要先disable。
disable 'user'
drop 'user'
在desc指令中能够看到Hbase的表有很多重要的属性,这些属性都对应HBase底层维护数据的一些方式。例如COMPRESSION 属性指定了HBase的数据压缩格式,默认是NONE,另外还可以修改为JDK内置的GZ或者Hadoop集成的LZ4,另外还可以配置其他的属性。具体可以参看官方文档中的Appendix D部分。
2> HBase的数据结构
从上面的一系列实验,我们可以理解HBase的基础数据结构
RowKey:
Rowkey是用来检索记录的唯一主键,类似于Redis中的key。访问HBase中的表数据,只能通过Rowkey来查找。访问HBase的数据只有三种方式:
1、通过get指令访问单个rowkey对应的数据。
2、通过scan指令,默认全表扫描
3、通过scan指令,指定rowkey的范围,进行范围查找。
Rowkey可以是任意字符串,最大长度是64KB,实际中通常用不到这么长。在HBase内部,Rowkey保存为字节数组。存储时,会按照Rowkey的字典顺序排序存储。
在实际使用时,对Rowkey的设计是很重要的,往往需要将一些经常读取的重要列都包含到Rowkey中。并且要充分考虑到排序存储这个特性,让一些相关的数据尽量放到一起。比如我们创建一个用户表,经常会按用户ID来查询, 那Rowkey中一定要包含用户ID字段。而如果把用户ID放在Rowkey的开头,那数据就会按照用户ID排序存储,查询Rowkey时效率就会比较快。
Column Family(列簇) 与 Column(列):
HBase中的列都是归属于某一个列簇的,HBase在表定义中只有对列簇的定义,没有对列的定义。也就是说,列是可以在列簇下随意扩展的。要访问列,也必须以列簇作为前缀,使用冒号进行连接。列中的数据是没有类型的, 全部都是以字节码形式存储。同一个表中,列簇不宜定义过多。
物理上,一个列簇下的所有列都是存储在一起的。由于HBase对于数据的索引和存储都是在列簇级别进行区分的,所以,通常在使用时,建议一个列簇下的所有列都有大致相同的数据结构和数据大小,这样可以提高HBase管理数据的效率。
Versions:
在HBase中,是以一个{row,column,version}这样的数据唯一确定一个存储单元,称为cell。在HBase中,可能存在很多cell有相同的row和column,但是却有不同的版本。多次使用put指令,指定相同的row和column,就会产生同一个数据的多个版本。
默认情况下,HBase是在数据写入时以时间戳作为默认的版本,也就是用scan指令查找数据时看到的timestamp内容。HBase就是以这个时间戳降序排列来存储数据的,所以,HBase去读取数据时,默认就会返回最近写入的数据。客户端也可以指定写入数据的版本,并且这个版本并不要求严格递增。
当一个数据有多个版本时,HBase会保证只有最后一个版本的cell数据是可以查询的,而至于其他的版本,会由HBase提供版本回收机制,在某个时间进行删除。
例如:以下指令可以指定要存储多少个版本
#给basicinfo声明最多保存5个版本
alter 'user',NAME => 'basicinfo',VERSIONS=>5
#指定最少两个版本
alter 'user',NAME => 'basicinfo',MIN_VERSIONS => 2
#查询多个版本的数据。
get 'user','1001',{COLUMN => 'basicinfo:name',VERSIONS => 3}
#查询10个历史版本
scan 'user',{RAW => true, VERSIONS => 10}
put与delete时,也可以指定版本。具体可以使用help指令查看。
另外,在使用scan查询批量数据时,Hbase会返回一个已经排好序的结果。按照 列=>列簇=>时间戳 的顺序进行排序。也可以在scan时,指定逆序返回。
Namespace 命名空间
在创建表的时候,还可以指定表所属的命名空间。例如
create_namespace 'my_ns'
create 'my_ns:my_table','fam'
alter_namespace 'my_ns',{METHOD => 'set','PROPERTY_NAME' => 'PROPERTY_VALUE'}
list_namespace
drop_namespace 'my_ns'
在HBase中,每个命名空间会对应HDFS上的/hbase/data目录下的一个文件夹。不同命名空间的表存储是隔离的。
在HDFS上可以看到, HBase默认创建了两个命名空间,一个是hbase,这是系统的命名空间,用来存放HBase的一些内部表。另一个是default,这个是默认的命名空间。不指定命名空间的表都会创建在这个命名空间下。
四、HBase原理
1、HBase文件读写框架
对HBase有了一定的了解了之后,再回头来看一下之前介绍过的HBase的架构图,对HBase的整体结构就可以有更深入的理解。

1、StoreFile
实际保存数据的物理文件,StoreFile以HFile的形式存储在HDFS上,每个Store会有一个或多个StoreFile,数据在每个StoreFile内都是有序的。在HDFS /hbase/data/default/user目录下。
2、MemStore
写缓存。由于HFile中的数据要求是有序的,所以数据是先存储在MemStore中,排好序后,等到达刷写时机才会写入到HFile。每次刷写都会形成一个新的HFile。
3、WAL
由于数据要经过MemStore排序后才能刷写到HFile,但是数据在内存中会有很高的概率丢失。为了解决这个问题,数据会先写在一个叫做Write-Ahead-logfile的文件中,然后再写入MemStore中。当系统出现故障时,就可以从这个日志文件进行重建。
2、HBase写数据流程
HBase写数据的流程如下图:

1、client向HReginoServer发送写请求
2、HRegionServer将数据写到WAL.
3、HRegionServer将数据写到内存MemStore
4、反馈Client写成功
图中meta表信息为hbase默认维护的一个表。 可以用scan 'hbase:meta’指令查看。他维护了系统中所有的Region信息。这个表的HDFS路径会维护在Zookeeper中。这个表里的info:server字段就保存了Region所在的机器以及端口。
客户端要写入的数据,实际上写入到MenStore就算完成了,HBase会在后续的过程中定期将MemStore内的数据写入到StoreFile中。在客户端可以通过flush指令手动触发这一过程。
HBase刷写MemStore的几个时机:
-
MemStore级别限制
habse.hregion.memstore.flush.size 默认128M。 当Region中任意一个MemStore的大小达到这个上限,就会触发一次MemStore操作,生成一个HFile。
-
Region级别限制:
hbase.hregion.memstore.block.multiplier 默认4. 当Region中所有MemStore的大小总和达到上限,也会触发MemStore的刷新。这个上限就是 hbase.hregion.memstore.flush.size * habse.hregion.memstore.flush.size
-
RegionServer级别限制
对整个RegionServer里写入的所有MemStore数据大小,配置了一个低水位阈值和高水位阈值。 当所有MemStore文件大小达到低水位阈值时,会开始强制执行flush。并按照MemStore文件从大到小一次刷写。
而当所有MenStore文件大小达到高水位时,就会阻塞所有的写入操作,强制执行flush。直到总MenStore大小下降到低水位阈值。
涉及到两个参数:
hbase.regionserver.global.memstore.size 表示RegionServer的高水位阈值。默认配置None。分配JVM的Heap堆内存大小的40%(0.4)。 老版本的参数是hbase.regionserver.global.memstore.upperLimit
hbase.regionserver.global.memstore.size.lower.limit 表示RegionServer的低水位占据高水位阈值的百分比。 默认配置也是None,表示是高水位阈值的95%(0.95)。老版本的参数是hbase.regionserver.global.memstore.lowerLimit
-
WAL级别限制
hbase.regionserver.maxlogs WAL数量上限。当RegionServer的WAL文件数量达到这个上下后,系统就会选取最早的Hlog对应的一个或多个Region进行Flush。这时候会在日志中有一条报警信息 Too many WALs。count=…
-
定期刷新MemStore
hbase.regionserver.optionalcacheflushinterval 默认是3600000 单位是毫秒,即1个小时。这是HBase定期刷新MemStore的时间间隔。通常在生产中,为了尽量保证业务性能会将这个参数配置为0,表示关闭定时自动刷写。
-
手动调用flush执行
在HBase的刷写机制下,只有RegionServer达到高水位阈值时才会阻塞写入操作,对业务产生直接影响。其他的几个限制级别都不会产生阻塞,但是通常还是会对性能产生一定的影响。所以在很多生产系统中,会根据业务的进展情况定制MemStore文件刷写策略。比如在业务不繁忙的时候进行定期手动刷写。
3、HBase读数据流程
HBase读数据的流程大致如下:

1、Client先访问zookeeper,从meta表读取region的位置,然后读取meta表中的数据。meta中存储了用户表的region信息。
2、根据namespace、表名和rowkey在meta表中找到对应的region信息。
3、找到这个Region对应的Regionserver
4、读取数据时,会启动多个StoreFileScanner和一个MemStoreScanner,最终的结果会同时读取内存和磁盘中的数据,并按照数据的版本号也就是时间戳,获取最新的一条数据返回给客户端。
5、在读取StoreFile时,为了提高读取数据的效率,会构建一个BlockCache作为读缓存。MemStore和StoreFile中查询到的目标数据,都会先缓存到BlockCache中,再返回给客户端。
从整体上来看, HBase写数据的操作只需要把数据写入内存就算完成,反而读数据要从文件开始读。所以,对于HBase,会呈现出写数据比读数据更快的效果。
4、HBase文件压缩流程
上面从HBase读写文件的流程简单的推出了一个结论:HBase的写操作会表现得比读操作更快。但是如果在面试过程中问个为什么,这样简单的流程推导显然无法让面试官信服。这个时候,就需要更加深入HBase的底层,寻找答案。
4.1 HBase底层的LSM树
HBase的每个Region中存储的是一系列可搜索的键值映射,底层会以LSM树( Log Structured Merge Tree )的结构来对key进行索引。LSM树也是B-树的一种扩展,很多NoSQL数据库都会采用这种LSM树来存储数据。
LSM树的基础思想是将对数据的修改增量保存在内存中,当内存达到指定大小限制后,将这些修改操作批量写入磁盘。这样写的性能得到极大的提升,不过读取的时候就会稍微麻烦一些,需要合并磁盘中的隶属数据和内存中最近修改的操作。LSM树通过这种机制,将一棵大树拆分成N棵小树,这些小树首先写入内存。随着小树越来越大,内存中的小树会flush到磁盘中,磁盘中的树再异步定期进行merge操作,最终将数据合并成一棵大树,以优化读性能。
在HBase中,因为小树要先写入内存,为了防止内存数据丢失,写内存的同时需要暂时持久化到磁盘(HBase的磁盘对应HDFS上的文件 ),这就对应了HBase的MemStore和Hlog。MemStore对应一个可变的内存存储,记录了最近的写(put)操作。当MemStore上的树达到一定大小后,就需要进行flush操作,这样MemStore就变成了HDFS上的磁盘文件StoreFile。之前介绍过,HBase是将所有数据修改存储为单独的版本,因此,对同一个key,会有多个版本保留在MemFile和StoreFile中,这些过时的数据是有冗余的,HBase会定期对StoreFile做merge合并操作,彻底删除无效的空间,多棵小树在这个时候合并成大树,来增强读性情。
在HBase 2.0版本中,还引入了一个重要的机制IN_MEMORY Compact内存压缩,来优化LSM中的内存树。内存压缩是HBase2.0中的一个重要特性,通过在内存中引入LSM结构,减少多余的数据,实现降低flush频率和减少MemFile刷写数据的效果。具体可以参看一个官方的博客:https://blogs.apache.org/hbase/entry/accordion-hbase-breathes-with-in。
在HBase2.0中,可以通过修改hbase-site.xml来对内存压缩方式进行统一配置
<property>
<name>hbase.hregion.compacting.memstore.type</name>
<value><none|basic|eager|adaptive></value>
</property>
或者也可以对某个列簇进行单独的设定:
alter 'user',{NAME=>'basicinfo',IN_MEMORY_COMPACTION=>'<none|basic|eager|adaptive>'}
内存压缩有四种模式可以选择。默认是basic。另外一个eager模式,会在内存中过滤重复的数据,这也意味着eager模式相比basic模式,内存过滤时会有额外的性能开销,但是刷写文件时的数据量会相对较小。eager模式更适合于数据大量淘汰的场景,比如MQ、购物车等。而另外一个adaptive是一个实验性的选项,其基本作用就是自动判断是否需要启用eager模式。
4.2 HBase文件压缩过程
HBase使用LSM树的方式,可以将应用程序级别的随机IO转换成为顺序磁盘IO,对于写性能的提升非常明显。但是LSM树对读数据的性能影响也是非常大的。所以,整体上,相比于MySQL的B+树结构,HBase的写性能会比MySQL高很多,同时读性能又会比MySQL低很多。另外,LSM结构是一种append-only-tree,文件不支持修改,只支持添加,这也正贴合Hadoop的文件机构,再加上HBase设计时,所面临的是TB级别的数据量,这种机制基本也就成了必选的方式了。
而HBase也对读操作做了一定的优化。例如,为了加快对MemFile映射的内存做数据读取,HBase会构建一个布隆过滤器,对内存中的数据进行快速过滤,从而减少对内存的搜索。这也就对应了desc指令中看到的BLOOMFILTER属性。
在HBase中,flush指令,将内存中的数据刷写到HDFS上。这时,只刷写,不过滤数据。每次刷写都会在HDFS上新刷写一个文件。
另外compact和major-compact两个指令,会用来将文件进行合并。
hbase:016:0> help 'compact'
Compact all regions in passed table or pass a region row
to compact an individual region. You can also compact a single column
family within a region.
You can also set compact type, "NORMAL" or "MOB", and default is "NORMAL"
Examples:
Compact all regions in a table:
hbase> compact 'ns1:t1'
hbase> compact 't1'
Compact an entire region:
hbase> compact 'r1'
Compact only a column family within a region:
hbase> compact 'r1', 'c1'
Compact a column family within a table:
hbase> compact 't1', 'c1'
Compact table with type "MOB"
hbase> compact 't1', nil, 'MOB'
Compact a column family using "MOB" type within a table
hbase> compact 't1', 'c1', 'MOB'
hbase:015:0> help 'major_compact'
Run major compaction on passed table or pass a region row
to major compact an individual region. To compact a single
column family within a region specify the region name
followed by the column family name.
Examples:
Compact all regions in a table:
hbase> major_compact 't1'
hbase> major_compact 'ns1:t1'
Compact an entire region:
hbase> major_compact 'r1'
Compact a single column family within a region:
hbase> major_compact 'r1', 'c1'
Compact a single column family within a table:
hbase> major_compact 't1', 'c1'
Compact table with type "MOB"
hbase> major_compact 't1', nil, 'MOB'
Compact a column family using "MOB" type within a table
hbase> major_compact 't1', 'c1', 'MOB'
这个compact指令是将相邻的部分小文件合并成大文件,并且他不会删除过时的数据,所以性能消耗不会太大。而major-compact指令是将所有的storefile文件合并成一个大文件,这时他就会删除过时的数据,就会消耗很多的机器性能。
当我们发送一个delete指令删除一个列时,HBase并不会直接删除数据,而是给数据添加一个删除标记,这样客户端就查不到当前列的值。而在flush阶段,只会删除那一列最新版本的数据,但是删除标记同样不会删除,以保证历史的版本不会让客户端查询出来。compact阶段,由于数据依然没有统一,所以删除标记依然不会删除,以保证客户端始终查不到历史版本的数据。只到major-compact阶段,数据全部合并到一个StoreFile中时,才会将历史版本的数据以及删除标记一起删除。
不同版本的数据可以使用下面的指令查看。包含历史版本以及删除标记。
hbase> scan ‘t1’, {RAW => true, VERSIONS => 10}
HBase提供了按照HFile文件大小以及文件个数,定时触发compact和major-compact的机制。例如 hbase.hregion.majorcompaction这个参数就用来配置自动文件压缩的时间间隔
但是这个参数在生产环境一般都是建议设置为0,关闭的。由手动来定时触发major-compact操作。这是因为文件压缩需要对数据做大量的合并和删除,会影响线上的性能。所以通过定时脚本保证集群在晚上业务不太繁忙时进行major-compact。
如果storeFile文件过大,HBase还会有另外的机制将storefile重新拆分成几个大小合适的文件,即Region,分到不同的RegionServer上。所以整体上,如果HBase的数据操作频繁, 你可以看到他的文件是分久必合合久必分,经常变来变去的。
五、HBase客户端
HBase支持多种客户端的API操作。从官方文档中可以看到, HBase支持Rest、Thrift、C/C++、Scala、Jython多种客户端,其中这个Jython比较有趣,是Python语言的一种纯JAVA实现,整体上兼容了JAVA和Python。
我们这次重点就关注HBase的Rest和Java两种API。
1、Rest API
基础服务指令:
#前台启动
bin/hbase rest start -p <port>
#后台启动 日志记录在$HBASE_LOGS_DIR
bin/hbase-daemon.sh start rest -p <port>
#停止Rest服务
bin/hbase-daemon.sh stop rest
这里要注意下HBase的Rest服务默认的启动接口是8080,这个接口用得非常多,非常容易端口冲突。spark默认就会使用这个端口。所以可以另行指定一个端口,比如9090。
HBase提供了非常丰富的Rest端口来管理HBase,这里列出了几个比较常用的端口。具体所有的窗口可以查看官方文档。
| Rest地址 | HTTP方法 | 意义 |
|---|---|---|
| /status/cluster | GET | 查看集群状态 |
| /namespaces | GET | 查看hbase的命名空间。后面可以带上具体的命名空间,查看某个namespace的详情 |
| /namespaces/{namespace}/tables | GET | 列出命名空间下的所有表。 |
| /namespaces/{namespace} | POST | 创建命名空间。 |
| /namespaces/{namespace} | DELETE | 删除命名空间。命名空间必须是空的才可以删除。 |
| /{table}/schema | GET | 查看表结构。同时POST请求更新表结构,PUT创建或更新一张表。DELETE删除表 |
| /{table}/regions | GET | 查看表所在的region |
| /{table}/{row_key} | PUT | 往表中写入一条数据。 |
| /{table}/{row_key}/{column:qualifier}/{version_id} | DELETE | 删除表中某一个历史版本数据 |
2、Java API
HBase作为一个NoSQL的数据库,他的客户端就设计得相当简单了。构建HBase客户端,需要引入Maven依赖:
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>2.4.4</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>2.4.4</version>
</dependency>
然后就可以调用HBase提供的API进行数据操作了。主要记住几个关键对象即可。例如对HBase的所有操作都基于Connection对象。表结构管理都通过HBaseAdmin对象来操作,表数据都通过Table对象来操作。其他的代码不用强记,用到哪里点哪里就行。 只不过要注意下,HBase2.X版本的源码中有非常多已经过时的类,现在版本勉强还可以用,但是源码中很多都会提示在未来的3.X版本会删除,所以尽量使用不过时的类。
1、获取HBase管理实例
public Connection getConfig() throws IOException {
final Configuration configuration = HBaseConfiguration.create();
//必选参数
configuration.set("hbase.zookeeper.quorum","hadoop01,hadoop02,hadoop03");
configuration.set("hbase.zookeeper.property.clientPort", "2181");
//其他可选参数
configuration.set("hbase.client.scanner.timeout.period", "10000");
configuration.set("hbase.hconnection.threads.max", "0");
configuration.set("hbase.hconnection.threads.core", "0");
configuration.set("hbase.rpc.timeout", "60000");
return ConnectionFactory.createConnection(configuration);
}
2、判断表是否存在
//查询表是否存在。默认使用default命名空间。其他命名空间需要传入 {namespace}:tableName
public Boolean isTableExist(Connection connection,String tableName) throws IOException {
final HBaseAdmin admin = (HBaseAdmin) connection.getAdmin();
return admin.tableExists(TableName.valueOf(tableName));
}
3、创建表
public void createTable(Connection connection,String tableName,String... columnFamilys) throws IOException {
final HBaseAdmin admin = (HBaseAdmin) connection.getAdmin();
if(columnFamilys.length<=0){
System.out.println("请设置列簇信息");
}else if (admin.tableExists(TableName.valueOf(tableName))) {
System.out.println("表"+tableName+"已经存在。");
}
else{
//2.0.0版本新的API。官网说明2.0.0版本有很多API已经过时,预计会在3.0版本后删除。如HTableDescriptor等
TableDescriptorBuilder builder = TableDescriptorBuilder.newBuilder(TableName.valueOf(tableName));
List<ColumnFamilyDescriptor> families = new ArrayList<>();
for(String columnFamily : columnFamilys){
final ColumnFamilyDescriptorBuilder cfdBuilder = ColumnFamilyDescriptorBuilder.newBuilder(ColumnFamilyDescriptorBuilder.of(columnFamily));
final ColumnFamilyDescriptor cfd = cfdBuilder.setMaxVersions(10).setInMemory(true).setBlocksize(8 * 1024)
.setScope(HConstants.REPLICATION_SCOPE_LOCAL).build();
families.add(cfd);
}
final TableDescriptor tableDescriptor = builder.setColumnFamilies(families).build();
admin.createTable(tableDescriptor);
}
}
4、删除表
public void dropTable(Connection connection,String tableName) throws IOException {
final HBaseAdmin admin = (HBaseAdmin) connection.getAdmin();
if(admin.tableExists(TableName.valueOf(tableName))){
admin.disableTable(TableName.valueOf(tableName));
admin.deleteTable(TableName.valueOf(tableName));
System.out.println("表"+tableName+"成功删除");
}else {
System.out.println("表"+tableName+"不存在");
}
}
5、向表中插入数据
public void addRowData(Connection connection,String tableName,String rowkey,
String columnFamily,String column,String value) throws IOException {
Table table = connection.getTable(TableName.valueOf(tableName));
//构建Put指令,rowkey必传
Put put = new Put(Bytes.toBytes(rowkey));
//指定版本时间戳
// put.addColumn(Bytes.toBytes(columnFamily),Bytes.toBytes(column),System.currentTimeMillis(),Bytes.toBytes(value));
put.addColumn(Bytes.toBytes(columnFamily),Bytes.toBytes(column),Bytes.toBytes(value));
//也可以传入一个List<Put> 插入多列数据
table.put(put);
//表操作之后记得要close,关闭线程池
table.close();
6、根据rowkey删除数据
public void deleteMultiRow(Connection connection,String tableName,String... rows) throws IOException {
Table table = connection.getTable(TableName.valueOf(tableName));
List<Delete> deletes = new ArrayList<>();
for(String row: rows){
Delete delete = new Delete(Bytes.toBytes(row));
deletes.add(delete);
}
if(deletes.size()>0){
table.delete(deletes);
}
table.close();
System.out.println("表数据删除成功");
}
7、Get获取某一行数据
public void getRowData(Connection connection,String tableName,String row) throws IOException {
Table table = connection.getTable(TableName.valueOf(tableName));
Get get = new Get(Bytes.toBytes(row));
final Result result = table.get(get);
for (Cell cell : result.rawCells()) {
System.out.println("rowkey:"+Bytes.toString(CellUtil.cloneRow(cell))