神经网络图片基础与tf.keras介绍
Posted ZSYL
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了神经网络图片基础与tf.keras介绍相关的知识,希望对你有一定的参考价值。
神经网络-图片基础与tf.keras介绍
1. 图像基本知识
回忆:之前我们在特征抽取中讲过如何将文本处理成数值。
思考:如何将图片文件转换成机器学习算法能够处理的数据?
我们经常接触到的图片有两种,一种是黑白图片(灰度图),另一种是彩色图片。

- 组成图片的最基本单位是像素。
1.1 图片三要素
组成一张图片特征值是所有的像素值,有三个维度:图片长度、图片宽度、图片通道数。
图片的通道数是什么?
描述一个像素点,如果是灰度图,那么只需要一个数值来描述它,就是单通道。
如果一个像素点,有RGB三种颜色来描述它,就是三通道。
- 灰度图:单通道
- 彩色图片:三通道

假设一张彩色图片的长200,宽200,通道数为3,那么总的像素数量为200 * 200 * 3
1.2 张量形状
在TensorFlow中如何用张量表示一张图片呢?
一张图片可以被表示成一个3D张量,即其形状为[height, width, channel],height就表示高,width表示宽,channel表示通道数。我们会经常遇到3D和4D的表示
- 单个图片:[height, width, channel]
- 多个图片:[batch,height, width, channel],batch表示一个批次的张量数量
2. tf.keras介绍
Keras是一个用Python编写的开源神经网络库。它能够运行在TensorFlow,Microsoft Cognitive Toolkit,Theano或PlaidML之上。TensorFlow 1.9 新增 tf.keras,Keras与TF的深度集成。
2.1 为什么选择 Keras?
在如今无数深度学习框架中,为什么要使用 Keras 而非其他?以下是 Keras 与现有替代品的一些比较。
- Keras 遵循减少认知困难的最佳实践: 它提供一致且简单的 API,它将常见用例所需的用户操作数量降至最低,并且在用户错误时提供清晰和可操作的反馈。
- 因为 Keras 与底层深度学习语言(特别是 TensorFlow)集成在一起,所以它可以让你实现任何你可以用基础语言编写的东西。特别是,
tf.keras作为 Keras API 可以与 TensorFlow 工作流无缝集成。
- Keras 被工业界和学术界广泛采用
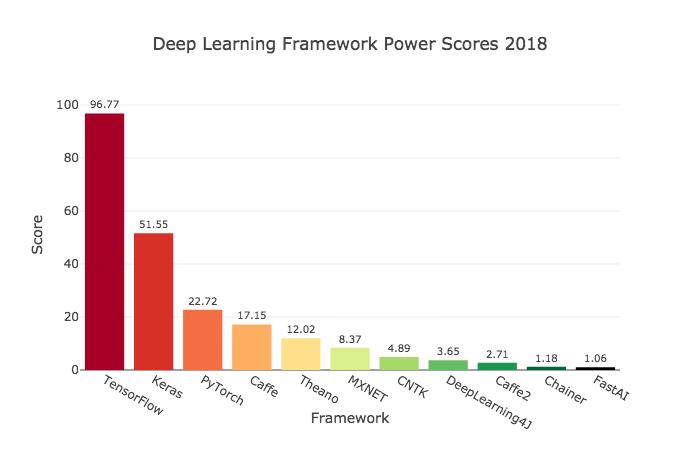
截至 2018 年中期,Keras 拥有超过 250,000 名个人用户。与其他任何深度学习框架相比,Keras 在行业和研究领域的应用率更高(除 TensorFlow 之外,且 Keras API 是 TensorFlow 的官方前端,通过 tf.keras 模块使用)。
-
Keras 拥有强大的多 GPU 和分布式训练支持
- Keras内置对多 GPU 数据并行的支持。
-
Keras 的发展得到深度学习生态系统中的关键公司的支持
Keras API 以 tf.keras 的形式包装在 TensorFlow 中。

2.2 tf.keras与keras API
keras与tf.keras相关API设置一样,主要有以下常用模块
-
applications模块:Keras应用程序是具有预训练权重的固定架构。 -
callbacksmodule:回调:在模型训练期间在某些点调用的实用程序。 -
datasetsmodule:Keras内置数据集。 -
initializers模块:Keras初始化器序列化/反序列化。 -
layers模块:Keras层API。 -
losses模块:内置损失功能。 -
metrics模块:内置指标。 -
modelsmodule:模型克隆代码,以及与模型相关的API。 -
optimizersmodule:内置优化器类。 -
preprocessing模块:Keras数据预处理工具。 -
regularizers模块:内置正规化器。 -
utils模块:Keras实用程序。
2.3 图片读取处理
2.3.1 tf.keras.preprocessing.image
image模块提供了读取图片处理的API
要使用该模块需要下载图片读取库
pip install Pillow
- load_img(path=filepath, target_size):加载图片
image = load_img("./bus/300.jpg")
print(image)
<PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=384x256 at 0x10E51D6D8>
返回一个PIL.JpegImagePlugin.JpegImageFile对象。
图片特征值处理-图片大小
为什么要缩放图片到统一大小?
在进行图像识别的时候,每个图片样本的特征数量要保持相同。所以需要将所有图片张量大小统一转换。
另一方面,如果图片的像素量太大,通过这种方式适当减少像素的数量,减少训练的计算开销。
image = load_img("./bus/300.jpg", target_size=(200, 200))
<PIL.Image.Image image mode=RGB size=200x200 at 0x1082A06A0>
由于读取出来的类型不能直接在TensorFlow中使用,所以需要进行类型转换
img_to_array(img, data_format=None, dtype=None):图片转换成数组格式- img: PIL Image instance.
- data_format: Image data format,either “channels_first” or “channels_last”.
- dtype: Dtype to use for the returned array.
image = img_to_array(image)
print(image.shape)
(200, 200, 3)
打印出来图片的数组值
"""加载图片"""
from tensorflow.python.keras.preprocessing.image import load_img, img_to_array
def main():
image = load_img('./bus/300.jpg', target_size=(300, 300)) # target_size:指定大小
print(image)
# 输入到TensorFlow中,需要转为矩阵
image = img_to_array(image)
print(image)
print(image.shape)
if __name__ == '__main__':
main()
2.3.2 NHWC与NCHW
在读取设置图片形状的时候有两种格式"channels_first" or “channels_last”.:
设置为 “NHWC” 时,排列顺序为 [batch, height, width, channels];
设置为 “NCHW” 时,排列顺序为 [batch, channels, height, width]。
其中 N 表示这批图像有几张,H 表示图像在竖直方向有多少像素,W 表示水平方向像素数,C 表示通道数。
Tensorflow默认的[height, width, channel]
假设RGB三通道两种格式的区别如下图所示:

- 理解
假设1, 2, 3, 4-红色 5, 6, 7, 8-绿色 9, 10, 11, 12-蓝色
- 如果通道在最低维度0[channel, height, width],RGB三颜色分成三组,在第一维度上找到三个RGB颜色
- 如果通道在最高维度2[height, width, channel],在第三维度上找到RGB三个颜色


# 1、想要变成:[2 height, 2width, 3channel],但是输出结果不对
In [7]: tf.reshape([1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12], [2, 2, 3]).eval()
Out[7]:
array([[[ 1, 2, 3],
[ 4, 5, 6]],
[[ 7, 8, 9],
[10, 11, 12]]], dtype=int32)
# 2、所以要这样去做
In [8]: tf.reshape([1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12], [3, 2, 2]).eval()
Out[8]:
array([[[ 1, 2],
[ 3, 4]],
[[ 5, 6],
[ 7, 8]],
[[ 9, 10],
[11, 12]]], dtype=int32)
# 接着使用tf.transpose ,0,1,2代表三个维度标记
# Convert from [depth, height, width] to [height, width, depth].
# 0,1,2-----> 1, 2, 0
In [17]: tf.transpose(depth_major, [1, 2, 0]).eval()
Out[17]:
array([[[ 1, 5, 9],
[ 2, 6, 10]],
[[ 3, 7, 11],
[ 4, 8, 12]]], dtype=int32)
- 转换API
tf.transpose(a, perm=None)- Transposes
a. Permutes the dimensions according toperm.- 修改维度的位置
- a:数据
- perm:形状的维度值下标列表
- Transposes
- 处理图片的形状
所以在读取数据处理形状的时候
- 1 image (3072, ) —>tf.reshape(image, [])里面的shape是[channel, height, width], 所以得先从[depth * height * width] to [depth, height, width]。
- 2 然后使用tf.transpose, 将刚才的数据[depth, height, width],变成Tensorflow默认的[height, width, channel]
2.4 tf.keras 数据集
2.4.1 CIFAR10 小图片分类数据
50000张32x32大小的训练数据和10000张测试数据,总共100个类别。
from keras.datasets import cifar100
(x_train, y_train), (x_test, y_test) = cifar100.load_data()
- 返回值:
- 两个元组:
- x_train, x_test: uint8 数组表示的 RGB 图像数据,尺寸为 (num_samples, 3, 32, 32) 或 (num_samples, 32, 32, 3),基于
image_data_format后端设定的channels_first或channels_last。 - y_train, y_test: uint8 数组表示的类别标签,尺寸为 (num_samples,)。
- x_train, x_test: uint8 数组表示的 RGB 图像数据,尺寸为 (num_samples, 3, 32, 32) 或 (num_samples, 32, 32, 3),基于
- 两个元组:
2.4.2 时装分类Mnist数据集
60,000张28x28总共10个类别的灰色图片,10,000张用于测试。
| 类别编号 | 类别 |
|---|---|
| 0 | T-shirt/top |
| 1 | Trouser |
| 2 | Pullover |
| 3 | Dress |
| 4 | Coat |
| 5 | Sandal |
| 6 | Shirt |
| 7 | Sneaker |
| 8 | Bag |
| 9 | Ankle boot |
from keras.datasets import fashion_mnist
(x_train, y_train), (x_test, y_test) = fashion_mnist.load_data()
- 返回两个元组:
- x_train, x_test: uint8 数组表示的灰度图像,尺寸为 (num_samples, 28, 28)。
- y_train, y_test: uint8 数组表示的数字标签(范围在 0-9 之间的整数),尺寸为 (num_samples,)。
2.4.3 加载数据集
"""加载数据集"""
from tensorflow.python import keras
def main():
# 加载数据集
(x_train, y_train), (x_test, y_test) = keras.datasets.cifar100.load_data()
print(x_train.shape)
print(y_train.shape)
# 加载时装数据集
(x_train, y_train), (x_test, y_test) = keras.datasets.fashion_mnist.load_data()
print(x_train)
print(y_train)
if __name__ == '__main__':
main()
加油!
感谢!
努力!
以上是关于神经网络图片基础与tf.keras介绍的主要内容,如果未能解决你的问题,请参考以下文章