小白必读神经网络原理
Posted ZSYL
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了小白必读神经网络原理相关的知识,希望对你有一定的参考价值。
学习目标
- 目标
- 说明神经网络的分类原理
- 说明softmax回归
- 说明交叉熵损失
神经网络的主要用途在于分类,那么整个神经网络分类的原理是怎么样的?我们还是围绕着损失、优化这两块去说。神经网络输出结果如何分类?
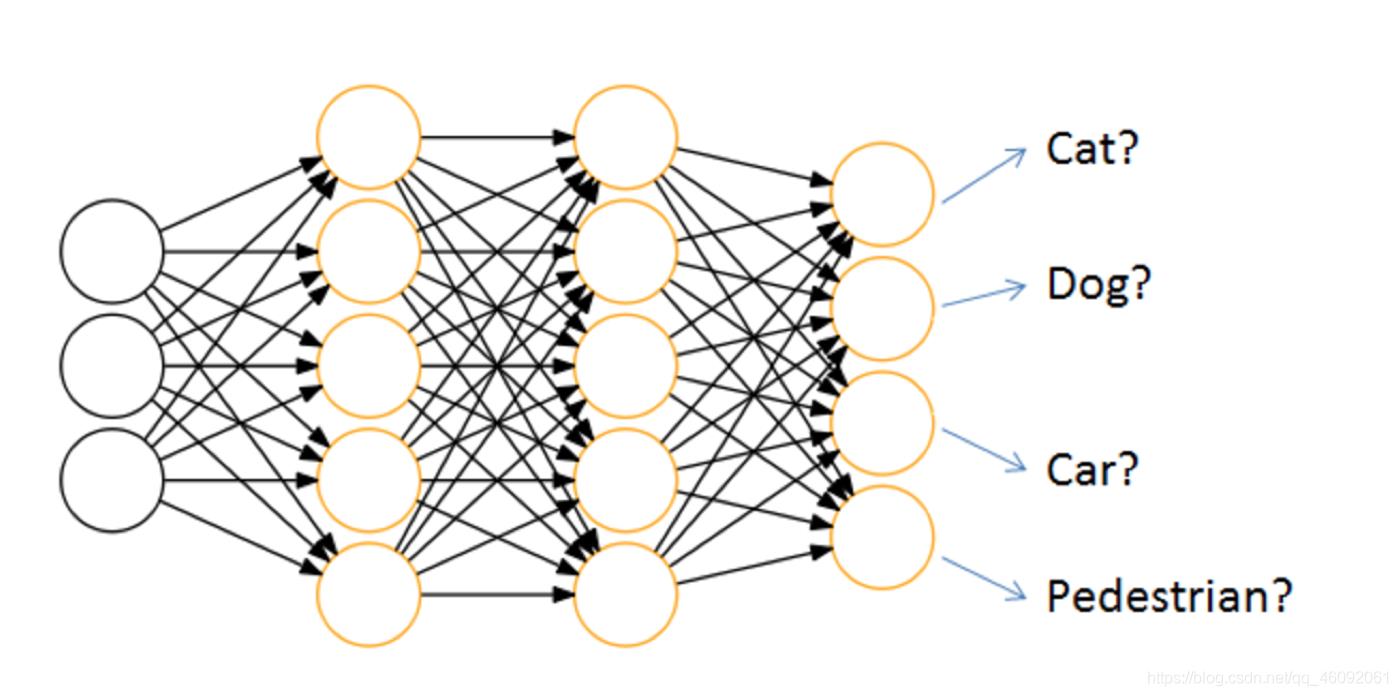
神经网络解决多分类问题最常用的方法是设置n个输出节点,其中n为类别的个数。
任意事件发生的概率都在0和1之间,且总有某一个事件发生(概率的和为1)。如果将分类问题中“一个样例属于某一个类别”看成一个概率事件,那么训练数据的正确答案就符合一个概率分布。
如何将神经网络前向传播得到的结果也变成概率分布呢?
Softmax回归就是一个常用的方法。
1. softmax回归
Softmax回归将神经网络输出转换成概率结果
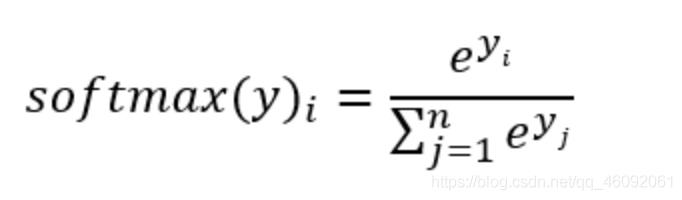
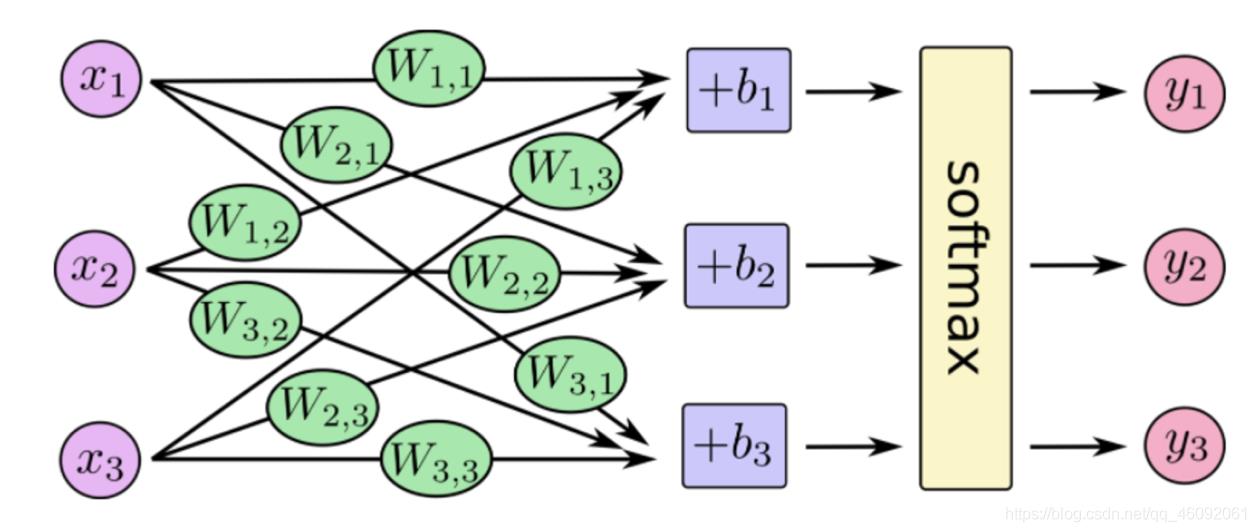

- softmax特点
如何理解这个公式的作用呢?看一下计算案例
假设输出结果为:2.3, 4.1, 5.6
softmax的计算输出结果为:
y1_p = e^2.3/(e^2.3+e^4.1+e^5.6)
y1_p = e^4.1/(e^2.3+e^4.1+e^5.6)
y1_p = e^5.6/(e^2.3+e^4.1+e^5.6)
这样就把神经网络的输出也变成了一个概率输出
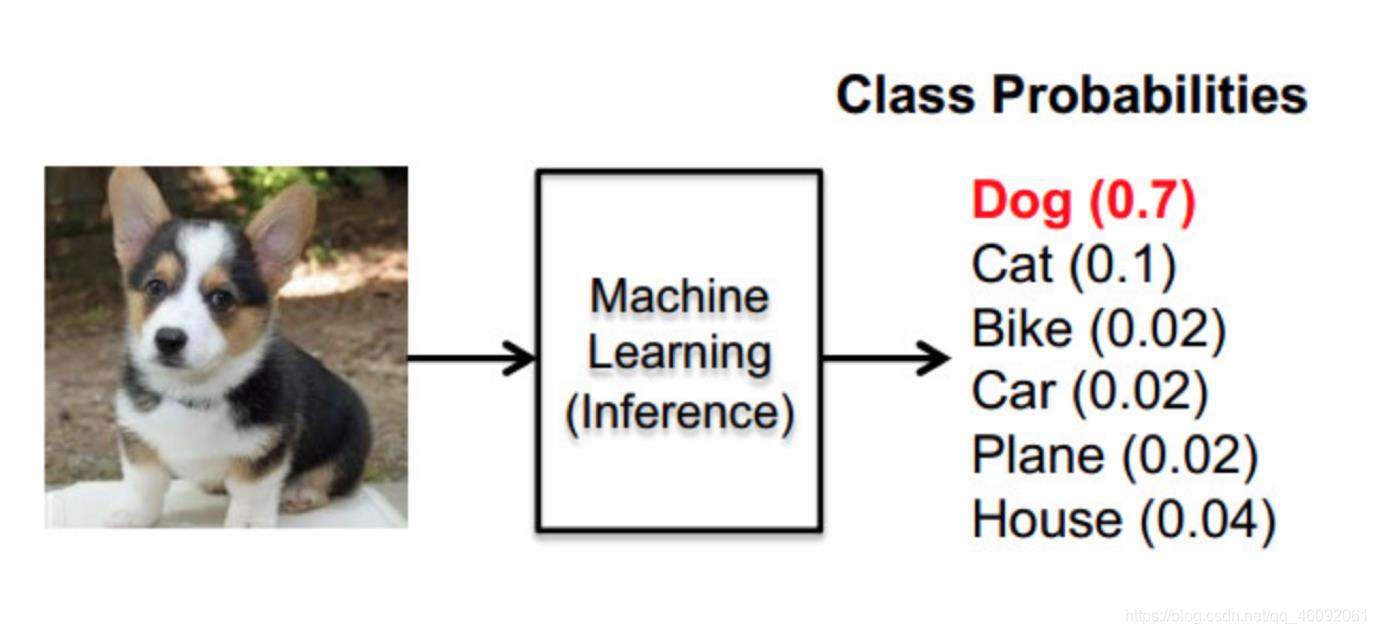
那么如何去衡量神经网络预测的概率分布和真实答案的概率分布之间的距离?
2. 交叉熵损失
2.1 公式
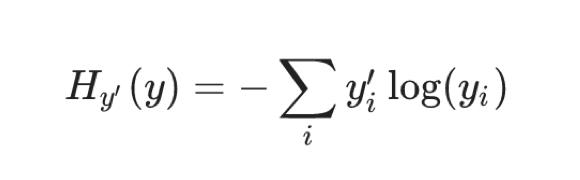
为了能够衡量距离,目标值需要进行one-hot编码,能与概率值一一对应,如下图
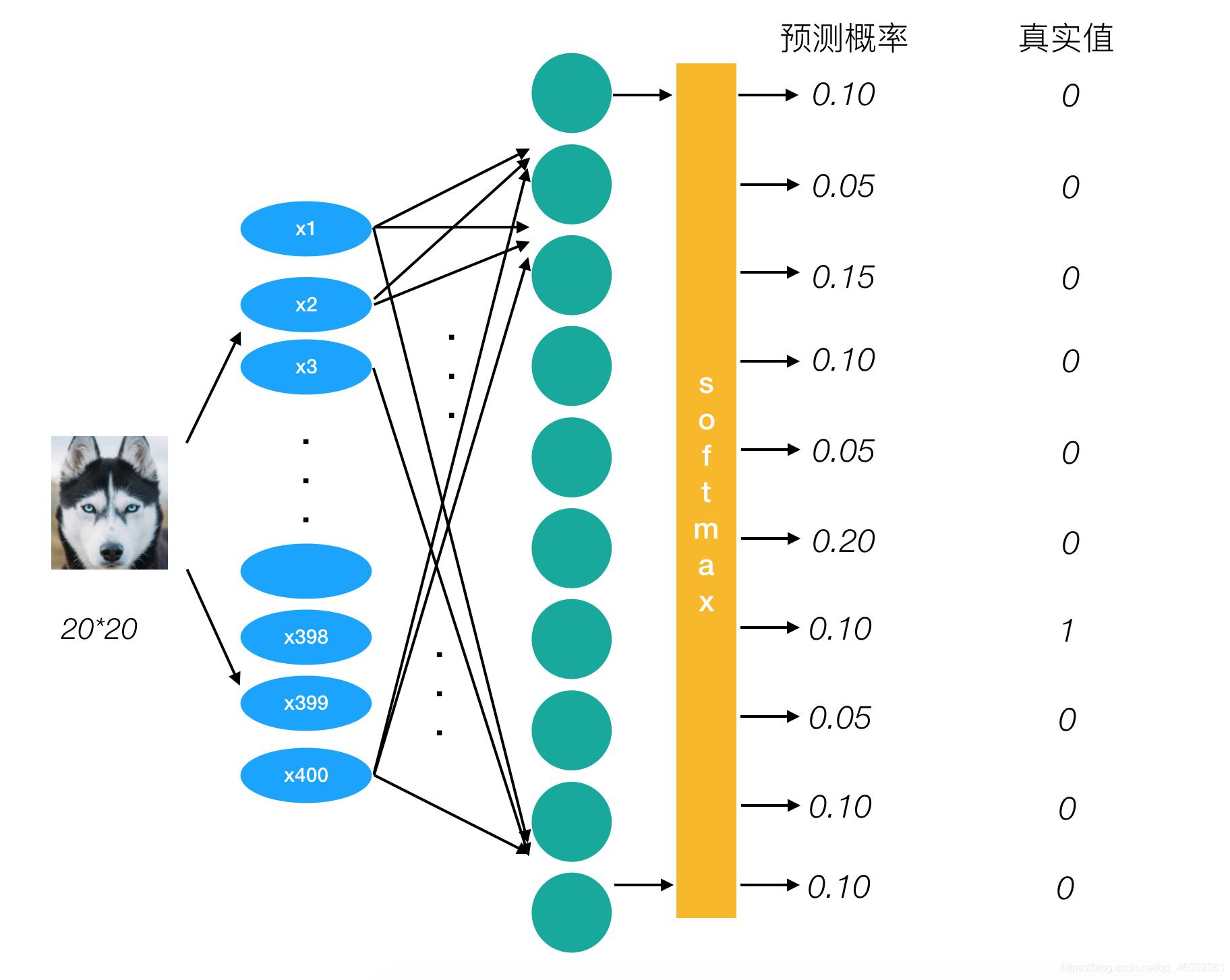
它的损失如何计算?
0log(0.10)+0log(0.05)+0log(0.15)+0log(0.10)+0log(0.05)+0log(0.20)+1log(0.10)+0log(0.05)+0log(0.10)+0log(0.10)
上述的结果为1log(0.10),那么为了减少这一个样本的损失。神经网络应该怎么做?
所以会提高对应目标值为1的位置输出概率大小,由于softmax公式影响,其它的概率必定会减少。只要这样进行调整这样是不是就预测成功了!!!
提高对应目标值为1的位置输出概率大小
2.2 损失大小
神经网络最后的损失为平均每个样本的损失大小。对所有样本的损失求和取其平均值
3. 梯度下降算法
目的:使损失函数的值找到最小值
方式:梯度下降
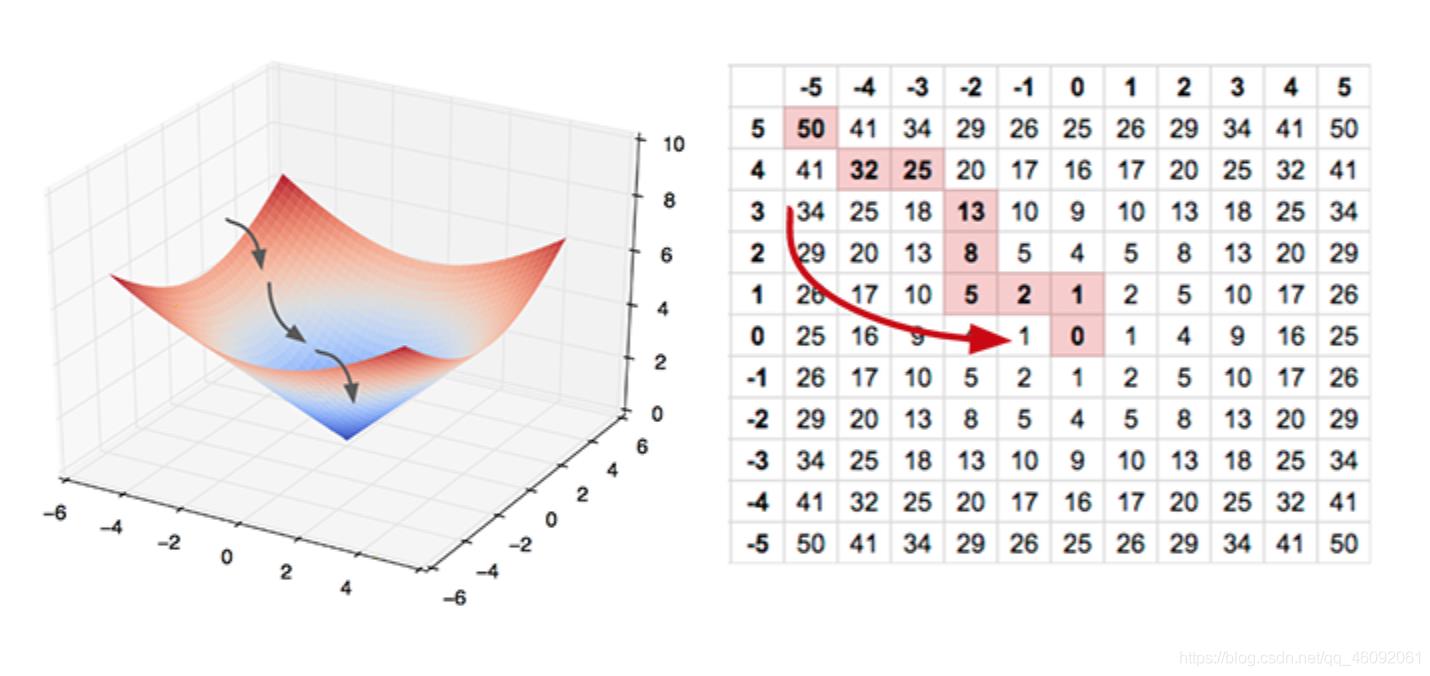
函数的 梯度(gradient) 指出了函数的最陡增长方向。梯度的方向走,函数增长得就越快。那么按梯度的负方向走,函数值自然就降低得最快了。模型的训练目标即是寻找合适的 w 与 b 以最小化代价函数值。假设 w 与 b 都是一维实数,那么可以得到如下的 J 关于 w 与 b 的图:
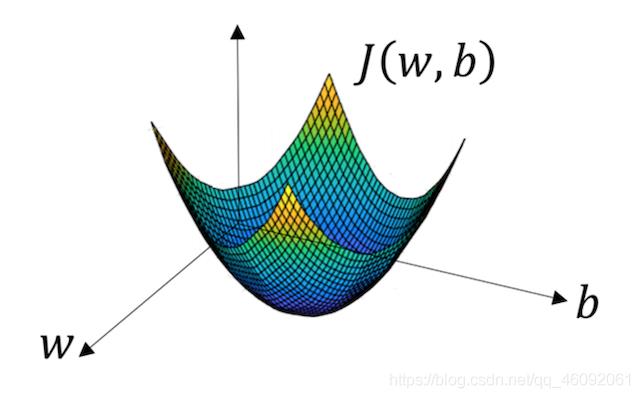
可以看到,此成本函数 J 是一个凸函数
参数w和b的更新公式为:
w : = w − α d J ( w , b ) d w w := w - \\alpha\\frac{dJ(w, b)}{dw} w:=w−αdwdJ(w,b), b : = b − α d J ( w , b ) d b b := b - \\alpha\\frac{dJ(w, b)}{db} b:=b−αdbdJ(w,b)
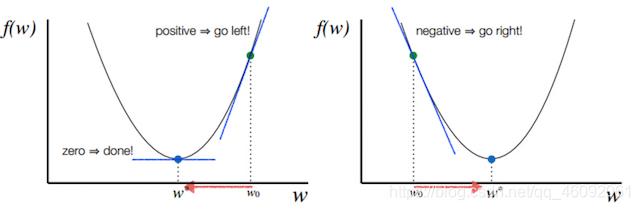
注:其中 α 表示学习速率,即每次更新的 w 的步伐长度。当 w 大于最优解 w′ 时,导数大于 0,那么 w 就会向更小的方向更新。反之当 w 小于最优解 w′ 时,导数小于 0,那么 w 就会向更大的方向更新。迭代直到收敛。
通过平面来理解梯度下降过程:
4. 网络原理总结
我们不会详细地讨论可以如何使用反向传播和梯度下降等算法训练参数。训练过程中的计算机会尝试一点点增大或减小每个参数,看其能如何减少相比于训练数据集的误差,以望能找到最优的权重、偏置参数组合。

加油!
感谢!
努力!
以上是关于小白必读神经网络原理的主要内容,如果未能解决你的问题,请参考以下文章