机器学习项目实践(什么是深度学习?)
Posted yk 坤帝
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习项目实践(什么是深度学习?)相关的知识,希望对你有一定的参考价值。
个人公众号 yk 坤帝
获取更多学习资料,学习建议
在过去的几年里,人工智能(AI)一直是媒体大肆炒作的热点话题。机器学习、深度学习和人工智能都出现在不计其数的文章中,而这些文章通常都发表于非技术出版物。
我们的未来被描绘成拥有智能聊天机器人、自动驾驶汽车和虚拟助手,这一未来有时被渲染成可怕的景象,有时则被描绘为乌托邦,人类的工作将十分稀少,大部分经济活动都由机器人或人工智能体(AI agent)来完成。对于未来或当前的机器学习从业者来说,重要的是能够从噪声中识别出信号,从而在过度炒作的新闻稿中发现改变世界的重大进展。
我们的未来充满风险,而你可以在其中发挥积极的作用:读完本书后,你将会成为人工智能体的开发者之一。那么我们首先来回答下列问题:到目前为止,深度学习已经取得了哪些进展?深度学习有多重要?接下来我们要做什么?媒体炒作是否可信?
1.1 人工智能、机器学习与深度学习
首先,在提到人工智能时,我们需要明确定义所讨论的内容。什么是人工智能、机器学习与深度学习(见图1-1)?这三者之间有什么关系?
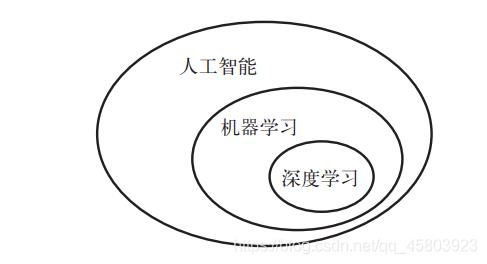
图1-1 人工智能、机器学习与深度学习
1.1.1 人工智能
人工智能诞生于20世纪50年代,当时计算机科学这一新兴领域的少数先驱开始提出疑问:计算机是否能够“思考”?我们今天仍在探索这一问题的答案。人工智能的简洁定义如下:努力将通常由人类完成的智力任务自动化。
因此,人工智能是一个综合性的领域,不仅包括机器学习与深度学习,还包括更多不涉及学习的方法。例如,早期的国际象棋程序仅包含程序员精心编写的硬编码规则,并不属于机器学习。在相当长的时间内,许多专家相信,只要程序员精心编写足够多的明确规则来处理知识,就可以实现与人类水平相当的人工智能。这一方法被称为符号主义人工智能(symbolic AI),从20世纪50年代到80年代末是人工智能的主流范式。在20世纪80年代的**专家系统(expert system)**热潮中,这一方法的热度达到了顶峰。
虽然符号主义人工智能适合用来解决定义明确的逻辑问题,比如下国际象棋,但它难以给出明确的规则来解决更加复杂、模糊的问题,比如图像分类、语音识别和语言翻译。于是出现了一种新的方法来替代符号主义人工智能,这就是机器学习(machine learning)。
1.1.2 机器学习
在维多利亚时代的英格兰,埃达•洛夫莱斯伯爵夫人是查尔斯•巴贝奇的好友兼合作者,后者发明了分析机(Analytical Engine),即第一台通用的机械式计算机。虽然分析机这一想法富有远见,并且相当超前,但它在19世纪三四十年代被设计出来时并没有打算用作通用计算机,因为当时还没有“通用计算”这一概念。
它的用途仅仅是利用机械操作将数学分析领域的某些计算自动化,因此得名“分析机”。1843年,埃达•洛夫莱斯伯爵夫人对这项发明评论道:“分析机谈不上能创造什么东西。它只能完成我们命令它做的任何事情……它的职责是帮助我们去实现我们已知的事情。”
随后,人工智能先驱阿兰•图灵在其1950年发表的具有里程碑意义的论文“计算机器和智能”a中,引用了上述评论并将其称为“洛夫莱斯伯爵夫人的异议”。图灵在这篇论文中介绍了图灵测试以及日后人工智能所包含的重要概念。在引述埃达•洛夫莱斯伯爵夫人的同时,图灵还思考了这样一个问题:通用计算机是否能够学习与创新?他得出的结论是“能”。
机器学习的概念就来自于图灵的这个问题:对于计算机而言,除了“我们命令它做的任何事情”之外,它能否自我学习执行特定任务的方法?计算机能否让我们大吃一惊?如果没有程序员精心编写的数据处理规则,计算机能否通过观察数据自动学会这些规则?
图灵的这个问题引出了一种新的编程范式。在经典的程序设计(即符号主义人工智能的范式)中,人们输入的是规则(即程序)和需要根据这些规则进行处理的数据,系统输出的是答案 (见图1-2)。利用机器学习,人们输入的是数据和从这些数据中预期得到的答案,系统输出的是规则。这些规则随后可应用于新的数据,并使计算机自主生成答案。
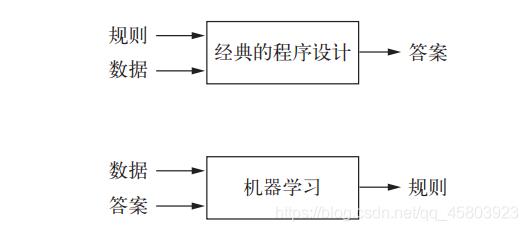 图1-2 机器学习:一种新的编程范式
图1-2 机器学习:一种新的编程范式
机器学习系统是训练出来的,而不是明确地用程序编写出来的。将与某个任务相关的许多示例输入机器学习系统,它会在这些示例中找到统计结构,从而最终找到规则将任务自动化。举个例子,你想为度假照片添加标签,并且希望将这项任务自动化,那么你可以将许多人工打好标签的照片输入机器学习系统,系统将学会将照片与特定标签联系在一起的统计规则。
虽然机器学习在20世纪90年代才开始蓬勃发展,但它迅速成为人工智能最受欢迎且最成功的分支领域。这一发展的驱动力来自于速度更快的硬件与更大的数据集。机器学习与数理统计密切相关,但二者在几个重要方面有所不同。
不同于统计学,机器学习经常用于处理复杂的大型数据集(比如包含数百万张图像的数据集,每张图像又包含数万个像素),用经典的统计分析(比如贝叶斯分析)来处理这种数据集是不切实际的。因此,机器学习(尤其是深度学习)呈现出相对较少的数学理论(可能太少了),并且是以工程为导向的。这是一门需要上手实践的学科,想法更多地是靠实践来证明,而不是靠理论推导。
1.1.3 从数据中学习表示
为了给出深度学习的定义并搞清楚深度学习与其他机器学习方法的区别,我们首先需要知道机器学习算法在做什么。前面说过,给定包含预期结果的示例,机器学习将会发现执行一项数据处理任务的规则。因此,我们需要以下三个要素来进行机器学习。
‰
**输入数据点。**例如,你的任务是语音识别,那么这些数据点可能是记录人们说话的声音文件。如果你的任务是为图像添加标签,那么这些数据点可能是图像。
‰
**预期输出的示例。**对于语音识别任务来说,这些示例可能是人们根据声音文件整理生成的文本。对于图像标记任务来说,预期输出可能是“狗”“猫”之类的标签。
‰
**衡量算法效果好坏的方法。**这一衡量方法是为了计算算法的当前输出与预期输出的差距。衡量结果是一种反馈信号,用于调节算法的工作方式。这个调节步骤就是我们所说的学习。
机器学习模型将输入数据变换为有意义的输出,这是一个从已知的输入和输出示例中进行“学习”的过程。因此,机器学习和深度学习的核心问题在于有意义地变换数据,换句话说,在于学习输入数据的有用表示(representation)——这种表示可以让数据更接近预期输出。在进一步讨论之前,我们需要先回答一个问题:什么是表示?这一概念的核心在于以一种不同的方式来查看数据(即表征数据或将数据编码)。
例如,彩色图像可以编码为RGB(红-绿-蓝)格式或HSV(色相-饱和度-明度)格式,这是对相同数据的两种不同表示。在处理某些任务时,使用某种表示可能会很困难,但换用另一种表示就会变得很简单。举个例子,对于“选择图像中所有红色像素”这个任务,使用RGB格式会更简单,而对于“降低图像饱和度”这个任务,使用HSV格式则更简单。机器学习模型都是为输入数据寻找合适的表示——对数据进行变换,使其更适合手头的任务(比如分类任务)。

我们来具体说明这一点。考虑x轴、y轴和在这个(x, y)坐标系中由坐标表示的一些点,如图1-3所示。
可以看到,图中有一些白点和一些黑点。假设我们想要开发一个算法,输入一个点的坐标(x, y),就能够判断这个点是黑色还是白色。在这个例子中:
‰ 输入是点的坐标;
‰ 预期输出是点的颜色;
‰ 衡量算法效果好坏的一种方法是,正确分类的点所占的百分比。
这里我们需要的是一种新的数据表示,可以明确区分白点与黑点。可用的方法有很多,这里用的是坐标变换,如图1-4所示。

在这个新的坐标系中,点的坐标可以看作数据的一种新的表示。这种表示很棒!利用这种新的表示,用一条简单的规则就可以描述黑/白分类问题:“x>0的是黑点”或“x<0的是白点”。这种新的表示基本上解决了该分类问题。
在这个例子中,我们人为定义了坐标变换。但是,如果我们尝试系统性地搜索各种可能的坐标变换,并用正确分类的点所占百分比作为反馈信号,那么我们做的就是机器学习。机器学习中的学习指的是,寻找更好数据表示的自动搜索过程。
所有机器学习算法都包括自动寻找这样一种变换:这种变换可以根据任务将数据转化为更加有用的表示。这些操作可能是前面提到的坐标变换,也可能是线性投影(可能会破坏信息)、平移、非线性操作(比如“选择所有x>0的点”),等等。机器学习算法在寻找这些变换时通常没有什么创造性,而仅仅是遍历一组预先定义好的操作,这组操作叫作假设空间(hypothesis space)。
这就是机器学习的技术定义:在预先定义好的可能性空间中,利用反馈信号的指引来寻找输入数据的有用表示。这个简单的想法可以解决相当多的智能任务,从语音识别到自动驾驶都能解决。
现在你理解了学习的含义,下面我们来看一下深度学习的特殊之处。
个人公众号 yk 坤帝
获取更多学习资料,学习建议
以上是关于机器学习项目实践(什么是深度学习?)的主要内容,如果未能解决你的问题,请参考以下文章
《21个项目玩转深度学习:基于TensorFlow的实践详解》高清带标签PDF版本学习下载