python爬虫_第二课
Posted 一只特立独行的猫
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python爬虫_第二课相关的知识,希望对你有一定的参考价值。
目录
前提
下载并在环境中安装requests库,可以在命令行cmd下采用
pip install requests
进行安装。这个库用来模拟浏览器向服务器发送信息。
爬取搜狗浏览器的首页:
代码
#!/usr/bin/env python
# -*- coding:utf-8 -*-
#- 需求:爬取搜狗首页的页面数据
import requests
if __name__ == "__main__":
#step_1:指定url
url = 'https://www.sogou.com/'
#step_2:发起请求
#get方法会返回一个响应对象
response = requests.get(url=url)
#step_3:获取响应数据.text返回的是字符串形式的响应数据
page_text = response.text
print(page_text)
#step_4:持久化存储
with open('./sogou.html','w',encoding='utf-8') as fp:
fp.write(page_text)
print('爬取数据结束!!!')
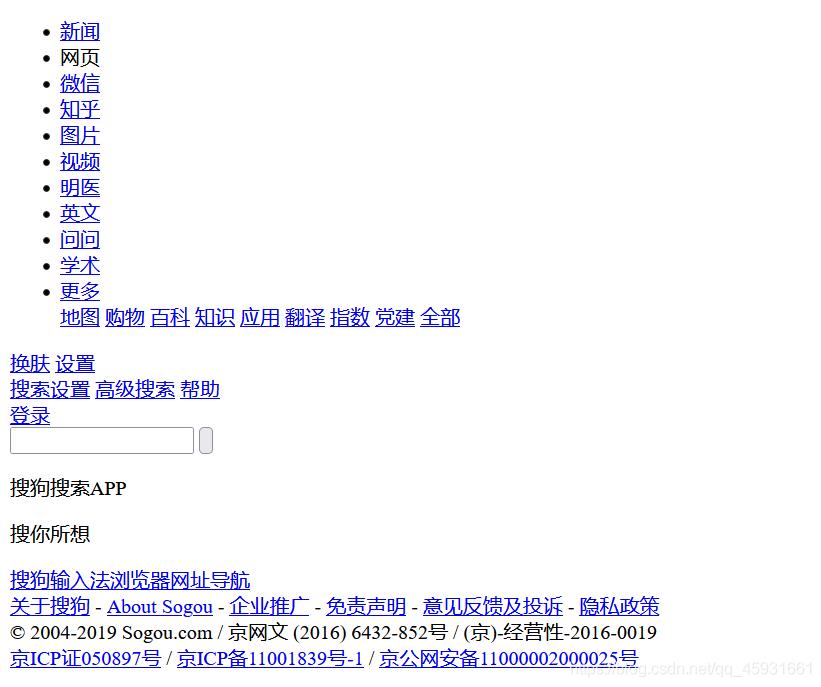
结果展示
注意点:
只爬取html文件,丢弃css和js文件,因为我们只需要对字符进行分析,不关注网页布局,为了追求速度,js和css进行丢弃。
爬取搜狗词条对应的搜索结果页面(简易网页采集器)
URL分析:
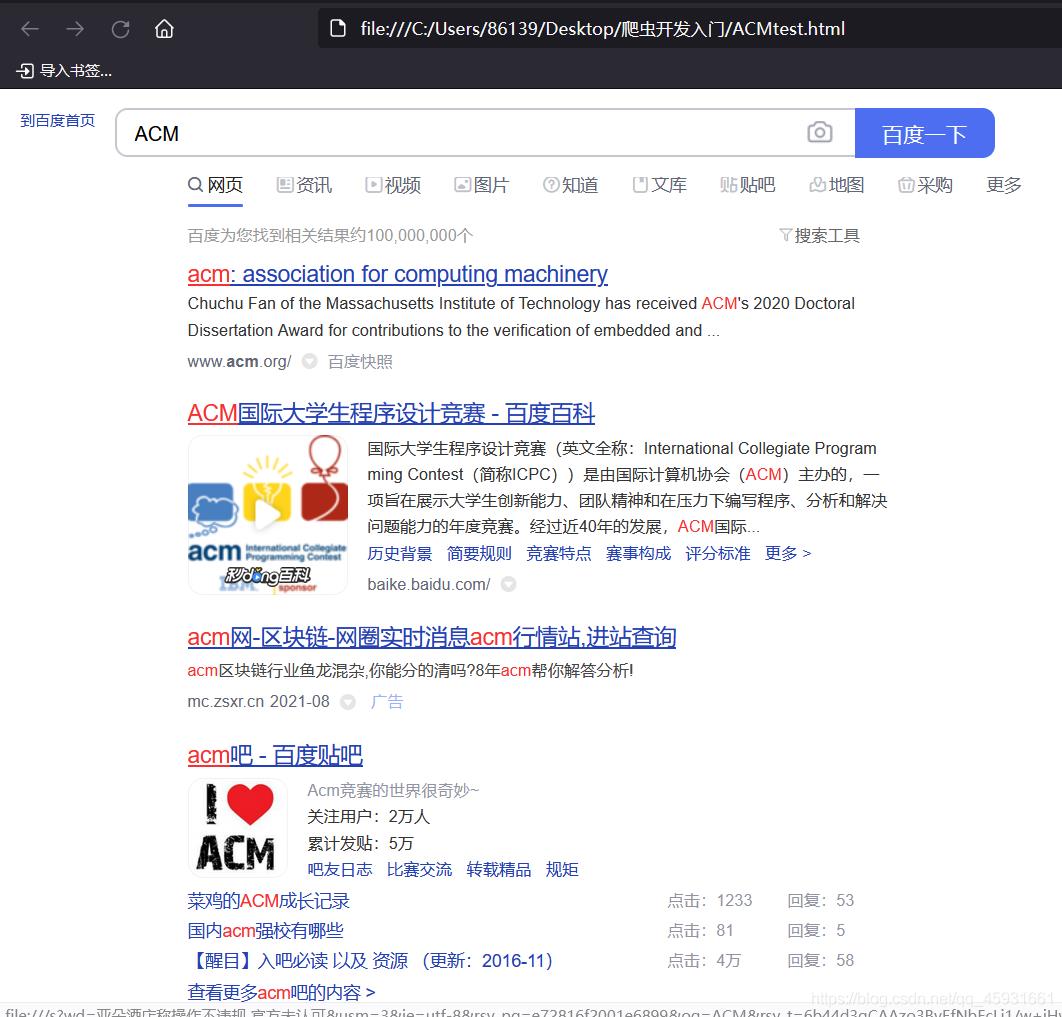
在百度的首页输入ACM后,发现他的URL是https://www.baidu.com/s?wd=ACM
经过分析可知,对关键词的URL请求是:
https://www.baidu.com/s?wd=关键词
分析得到了URL的格式:
https://www.baidu.com/s? 键=值&键=值
代码
# -*- coding:utf-8 -*-
#UA:User-Agent(请求载体的身份标识)
#UA检测:门户网站的服务器会检测对应请求的载体身份标识,如果检测到请求的载体身份标识为某一款浏览器,
#说明该请求是一个正常的请求。但是,如果检测到请求的载体身份标识不是基于某一款浏览器的,则表示该请求
#为不正常的请求(爬虫),则服务器端就很有可能拒绝该次请求。
#UA伪装:让爬虫对应的请求载体身份标识伪装成某一款浏览器
import requests
if __name__ == "__main__":
#UA伪装:将对应的User-Agent封装到一个字典中
headers = {
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36'
}
url = 'https://www.baidu.com/s'
#处理url携带的参数:封装到字典中
kw = input('enter a word:')
param = {
'wd':ACM
}
#对指定的url发起的请求对应的url是携带参数的,并且请求过程中处理了参数
response = requests.get(url=url,params=param,headers=headers)
page_text = response.text
fileName = kw+'.html'
with open(fileName,'w',encoding='utf-8') as fp:
fp.write(page_text)
print(fileName,'保存成功!!!')
结果展示:

爬取百度翻译
网页分析:

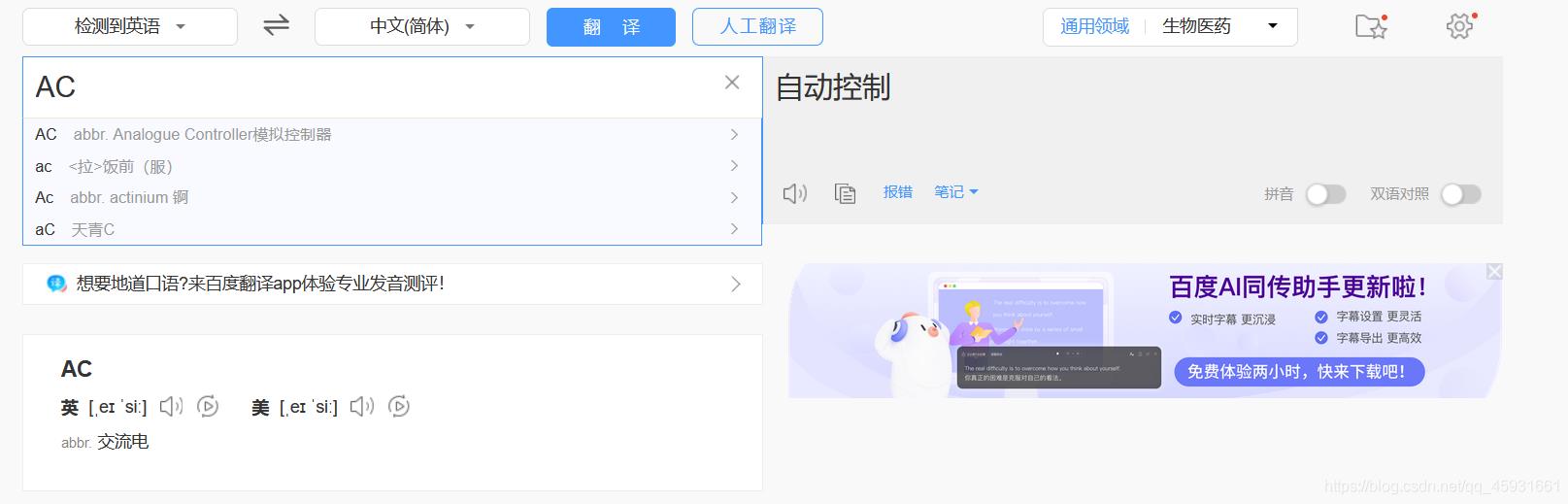
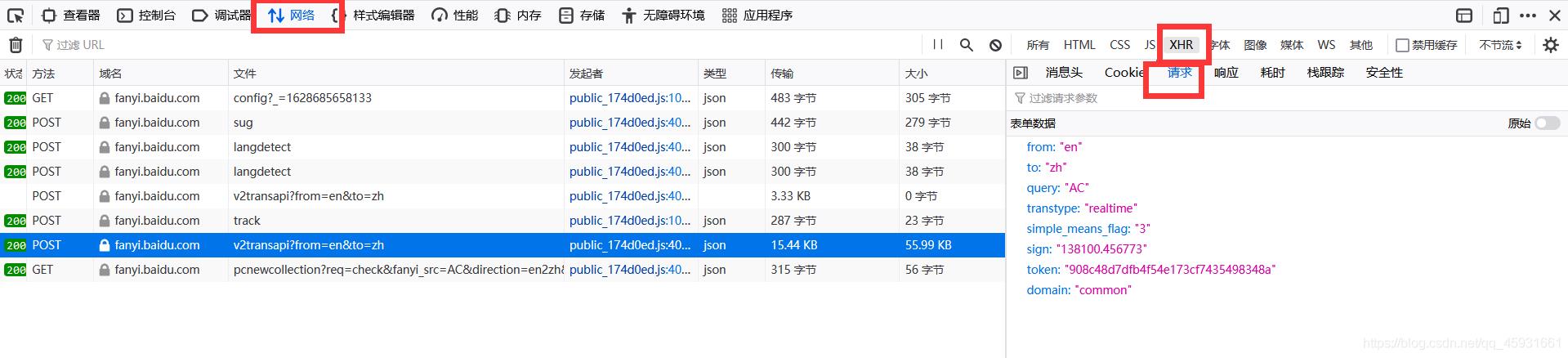
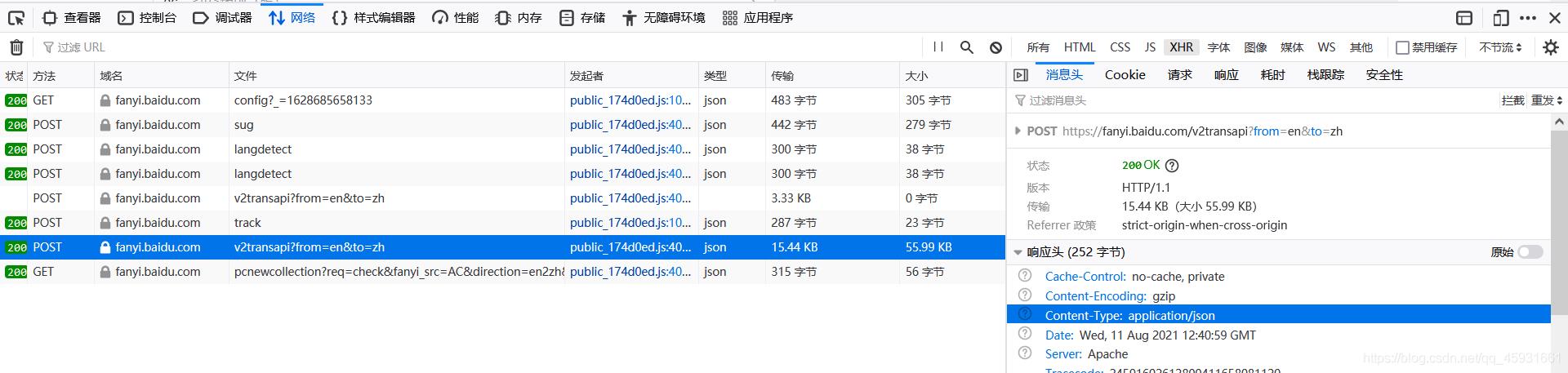
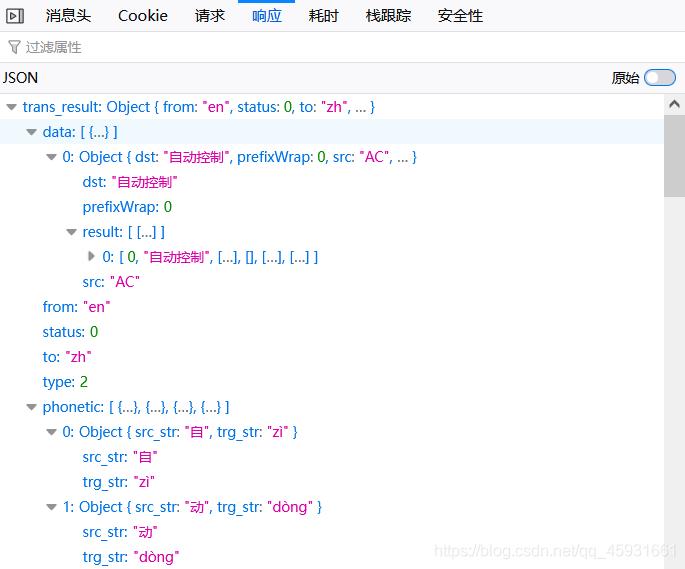
观察前后两个页面,发现在输入文本后网页出现了局部刷新。这是由于ajax实现的。按f12进行审查元素,看请求的格式。发现在请求体中发送了表单数据query:‘AC’,以及响应体的内容格式:json文件
代码:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import requests
import json
if __name__ == "__main__":
#1.指定url,通过f12观察POST请求最先向哪里发送数据得到
post_url = 'https://fanyi.baidu.com/sug'
#2.进行UA伪装
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36'
}
#3.post请求参数处理(同get请求一致)
word = input('enter a word:')
data = {
'kw':word
}
#4.请求发送
response = requests.post(url=post_url,data=data,headers=headers)
#5.获取响应数据:json()方法返回的是obj(如果确认响应数据是json类型的,才可以使用json())
dic_obj = response.json()
#持久化存储
fileName = word+'.json'
fp = open(fileName,'w',encoding='utf-8')
json.dump(dic_obj,fp=fp,ensure_ascii=False)
print('over!!!')
展示结果:

注意点:

第一个post向sug发送请求
爬取电影分类排行榜
网页分析
分析发现,每次导航条拖到底部,都会进行局部刷新,推测使用ajsx进行局部刷新,f12进行查看。
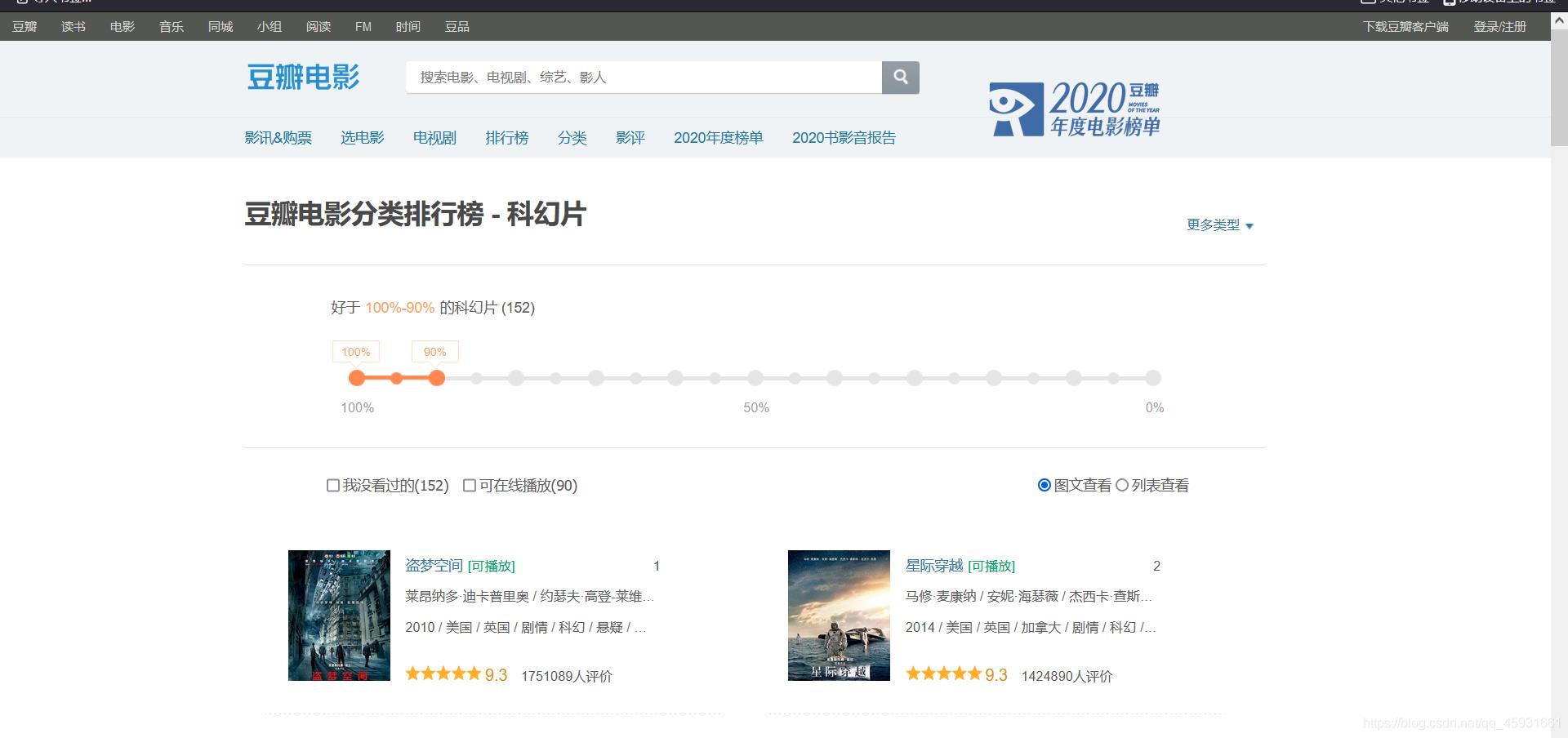
验证猜测,确实是通过ajsx进行页面局部刷新。
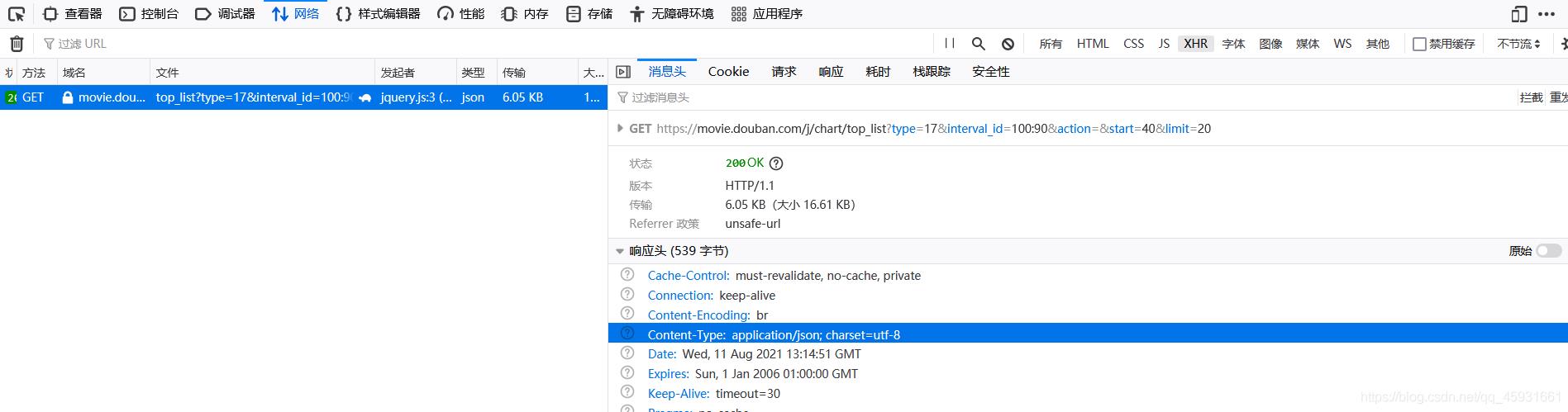
分析发现请求行的规律
https://movie.douban.com/j/chart/top_list?type=17&interval_id=100:90&action=&start=40&limit=20
猜测start是开始电影的意思,limit是每次发送数量的意思。验证猜测,猜测成立。
代码
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import requests
import json
if __name__ == "__main__":
url = 'https://movie.douban.com/j/chart/top_list'
param = {
'type': '24',
'interval_id': '100:90',
'action':'',
'start': '0',#从库中的第几部电影去取
'limit': '20',#一次取出的个数
}
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36'
}
#发送get请求
response = requests.get(url=url,params=param,headers=headers)
#得到相应的json文件
list_data = response.json()
fp = open('./douban.json','w',encoding='utf-8')
json.dump(list_data,fp=fp,ensure_ascii=False)
print('over!!!')
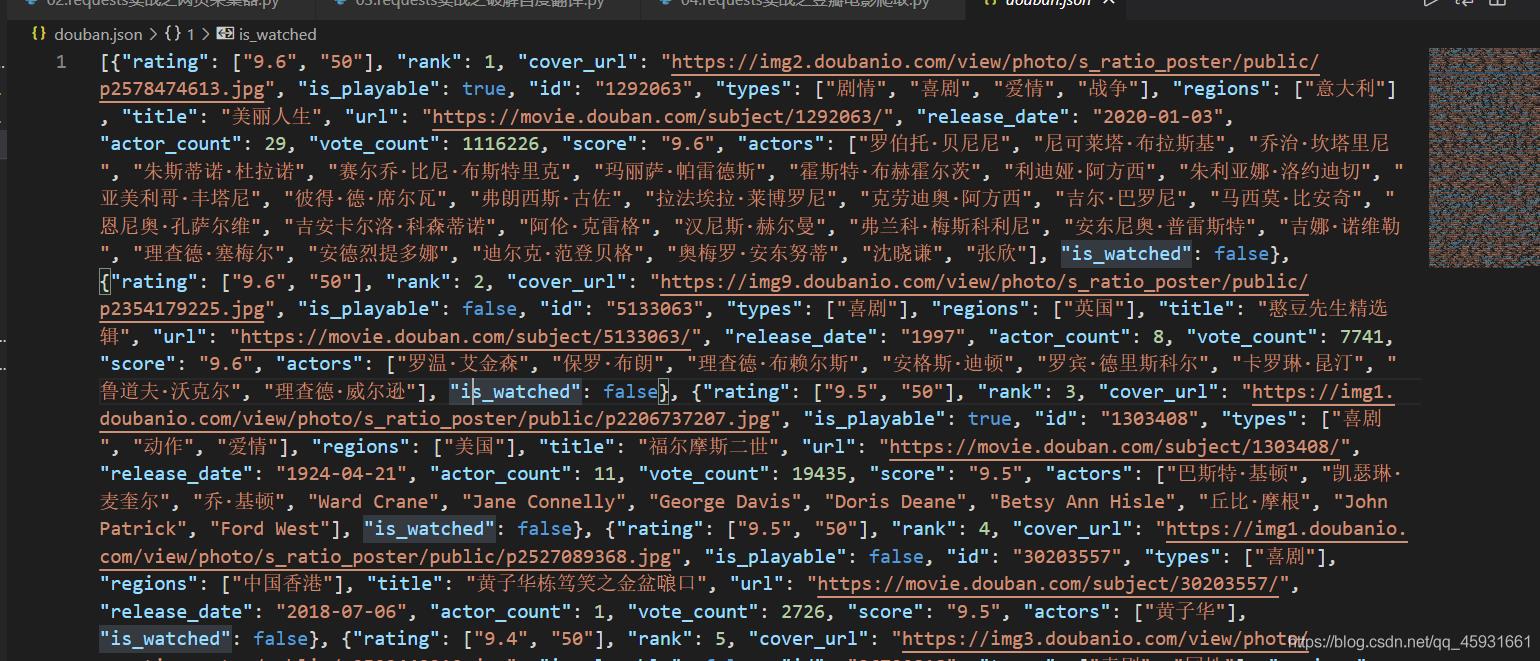
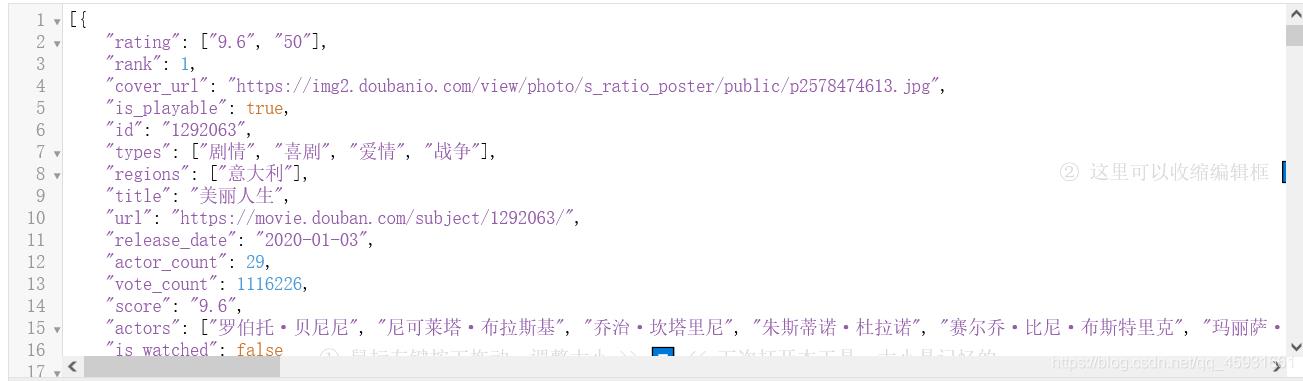
展示结果:
以上是关于python爬虫_第二课的主要内容,如果未能解决你的问题,请参考以下文章