论文泛读196Seq2Seq 的微型神经模型
Posted 及时行樂_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文泛读196Seq2Seq 的微型神经模型相关的知识,希望对你有一定的参考价值。
贴一下汇总贴:论文阅读记录
论文链接:《Tiny Neural Models for Seq2Seq》
一、摘要
在面向任务的对话系统中应用的语义解析模型需要高效的序列到序列 (seq2seq) 架构在设备上运行。为此,我们提出了一种基于投影的编码器-解码器模型,称为 pQRNN-MAtt。基于投影方法的研究仅限于编码器模型,我们相信这是第一项将其扩展到 seq2seq 架构的研究。生成的量化模型小于 3.5MB,非常适合设备上延迟关键的应用程序。我们表明,在 MTOP(一个具有挑战性的多语言语义解析数据集)上,平均模型性能超过了基于 LSTM 的 seq2seq 模型,该模型使用预训练的嵌入尽管小 85 倍。此外,该模型可以成为提炼大型预训练模型(如 T5/BERT)的有效学生。
二、结论
我们使用QRNN编码器和MAtt解码器将基于投影的表示扩展到设备seq2seq模型。尽管小了85倍,但在MTOP数据集上的评估证明,与使用预训练嵌入训练的LSTM模型相比,该模型是非常有效的。
未来的方向包括采用蒸馏技术(Kaliamoorthi等人,2021年)进一步改进模型,并探索多语言投影的不同标记化方案。
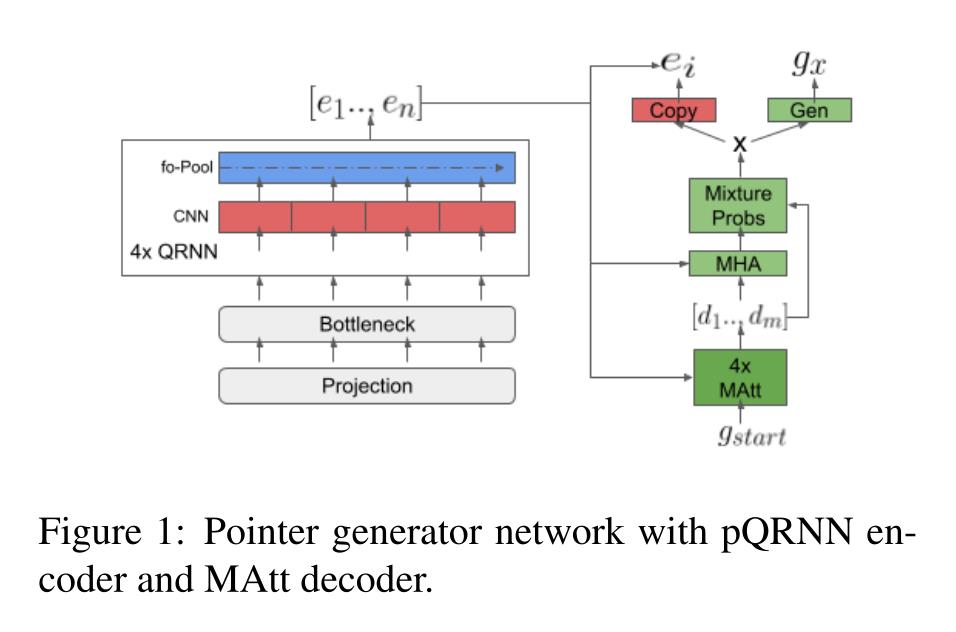
三、模型
带有pQRNN编码器和MAtt解码器的指针生成器网络:

以上是关于论文泛读196Seq2Seq 的微型神经模型的主要内容,如果未能解决你的问题,请参考以下文章
论文写作分析之一 《基于混合注意力Seq2seq模型的选项多标签分类》
论文泛读·Adversarial Learning for Neural Dialogue Generation
[翻译] 可视化神经网络机器翻译模型(Seq2Seq模型的注意力机制)