带你深入了解对齐与非对齐访问(ARM指令集)
Posted 狂奔De鸵鸟
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了带你深入了解对齐与非对齐访问(ARM指令集)相关的知识,希望对你有一定的参考价值。
首先你需要知道在什么情况下你才需要用到对齐与非对齐这个概念
typedef struct {
char* pCmd; //4个字节
char *pCmdPara; //4个字节
char isFree; //4个字节
}AT_QUEUE_ITEM_T;
AT_QUEUE_ITEM_T q[500] = {0}; //12*500 = 6000个字节上面的代码 isFree 会应为对齐的原因填充成4个字节。所以原本只有9*500=4500个字节的数据,在这里硬生生变成了6000个字节,浪费了1500个字节。这对资源本就有限的单片机来说是致命的。
有没有解决方案呢?答案当然是有的。
#pragma pack(1) //强制一字节对齐
typedef struct {
char* pCmd; //4个字节
char *pCmdPara; //4个字节
char isFree; //1个字节
}AT_QUEUE_ITEM_T;
#pragma pack()
AT_QUEUE_ITEM_T q[500] = {0}; //9*500 = 4500个字节这里我们使用 #pragma pack(n) 的预编译指令,将结构体强制1字节对齐。
如果用该结构声明的变量要作为参数传递入函数内部怎么办?
IAR 提供了 __packed属性
#pragma pack(1) //强制一字节对齐
typedef struct {
char* pCmd; //4个字节
char *pCmdPara; //4个字节
char isFree; //1个字节
}AT_QUEUE_ITEM_T;
#pragma pack()
AT_QUEUE_ITEM_T q[500] = {0}; //9*500 = 4500个字节
void test(AT_QUEUE_ITEM_T __packed par )
{
}(备注:关于#pragma pack() 这个预编译指令的详细解释可以看这篇文章。 https://blog.csdn.net/boazheng/article/details/88574234)
你以为到这里就完了?
就这??
NO!NO!NO!
图样图森破!
首先并不是所有硬件平台都支持非对齐访问,且并不是所有操作都支持非对齐。
所以你首先的知道
什么是数据的对齐和非对齐
下面我们来看一下Cortex-M3与Cortex-M4权威指南 6.6的内容
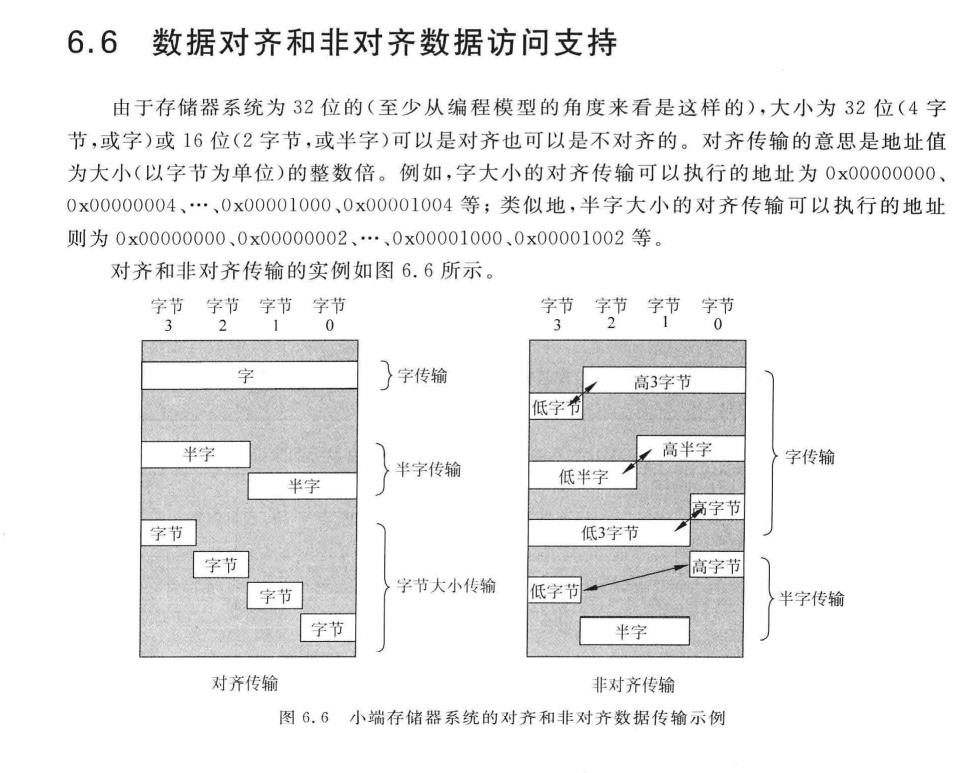

划重点:
ARM7/9/10只允许对齐传输,Cortex-M3和4 支持非对齐传输,非对齐传输不能在多加载/存储指令,栈操作指令,排他访问指令,位段操作中使用,且非对齐访问会降低性能。
文中没有对加载/存储指令给出明确说明,哪....
什么是加载/存储指令
存储指令用于在寄存器和存储器之间传送数据,加载指令用于将存储器中的数据传送到寄存器,存储指令则完成相反的操作。常用的加载存储指令如下:
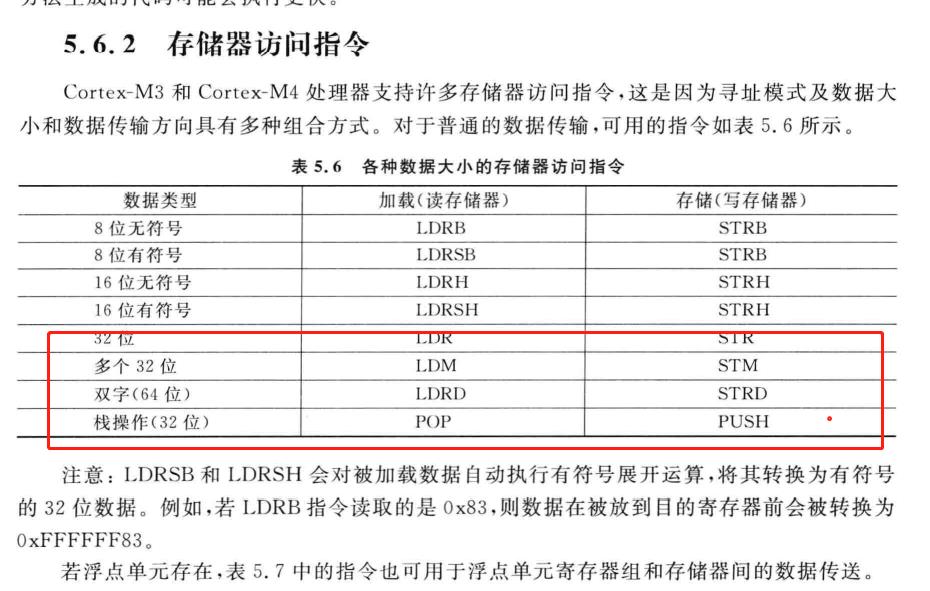
那么在Cortex-M3与Cortex-M4权威指南中提到的多加载是什么鬼?
在上表中所有数据类型的是32的都不支持,多载因该就是LDM,LDRD这2个了,存储就是STR,STM,STRD,PUSH。
而STRB,LDRH正是这几个指令的存在才允许你非对齐访问。
我们知道了什么是加载,存储的指令,哪。。。。
什么是排他访问
在Cortex-M3与Cortex-M4权威指南中是这样描述的。

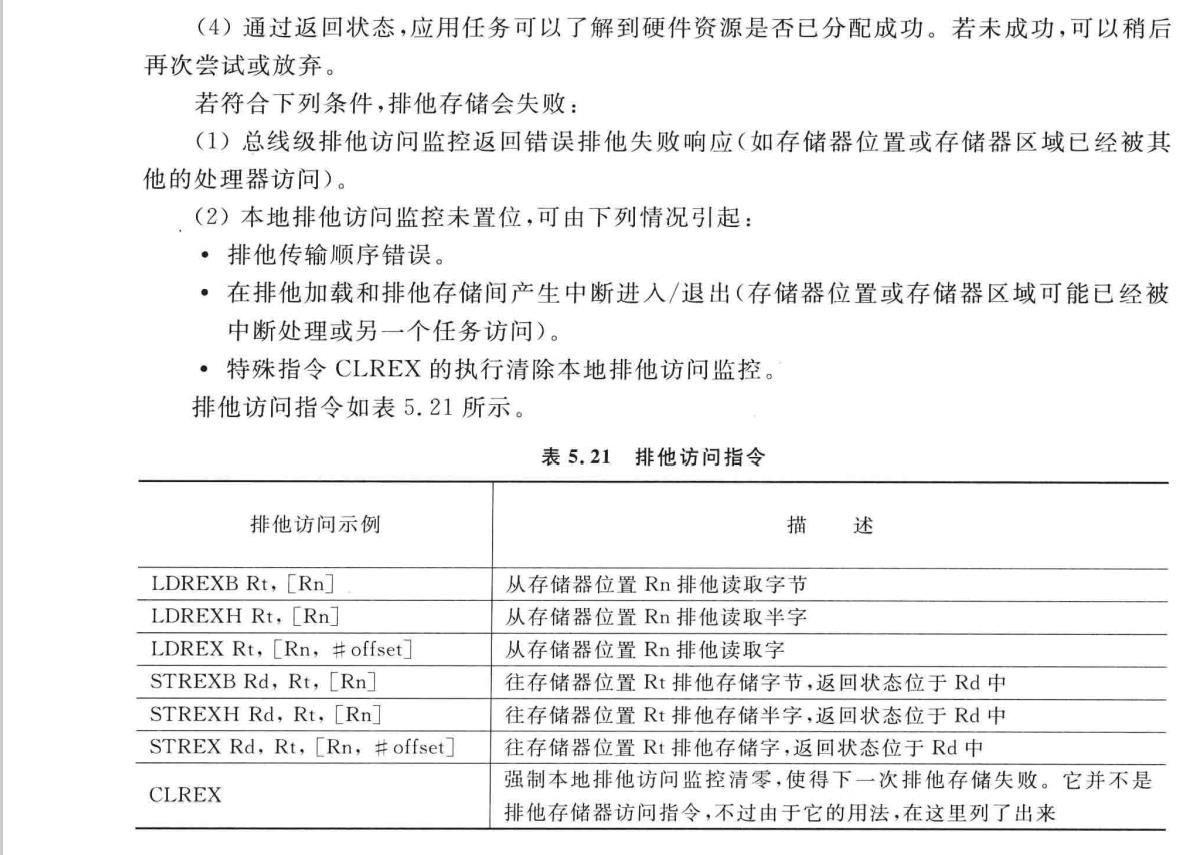
说人话就是。。。
我们知道临界区使任务有秩序地访问共享资源,避免资源竞争。但全局中断屏蔽不仅需要许多额外的指令周期,而且降低了紧急中断的响应速度。的排他访问旨在改善这一问题。
ARMv7指令集包含三对同步原语 ( synchronization primitives ) 。这三对同步原语分别为:
32位数据读写的 LDREX 和 STREX,
16位数据读写的 LDREXH 和 STREXH,
8位数据读写的 LDREXB 和 STREXB,
此外,还有用于清零排他访问标识的 CLREX
这些同步原语给多任务提供了一种不阻塞的资源竞争应对方法 —— 排他访问。排他访问实现有保障的 “ 读 - 改 - 写 ” 操作,可以用于信号量、自旋锁等系统服务。
请看图。。。。
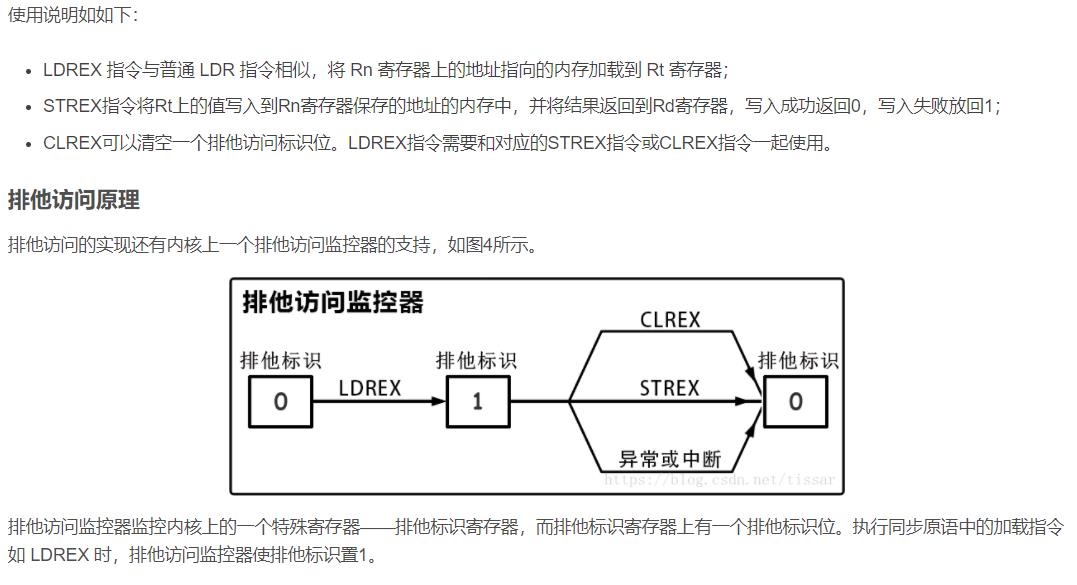
所以我们可以看出排他访问主要用在有嵌入式系统的情况下,信号量,自旋锁,互斥锁等等的应用上。
本文精华所在:
罗里吧嗦的说了这么多干巴巴的感念,到底有什么用?
那就是非对其访问什么时候用,怎么用?什么时候不能用。
1.在IAR中所支持的硬件平台
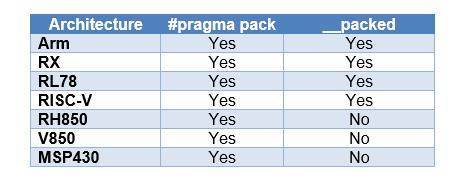
这里我们只关注ARM部分。在ARM中在Cortex-M3与Cortex-M4都是支持非对其访问的,但在Cortex-M0不支持。
2.在什么样的情况下不要用。
使用__packed和#pragma pack 有一个显著的缺点#pragma pack是每次访问结构中未对齐的元素都会使用更多的代码,也就是说在在需要高性能的地方最好不要用,如果一定要用,请自己平衡高性能和存储控件之间的矛盾。
其次函数内部直接使用非对其访问会影响出栈入栈,所以可以将非对齐访问的内容放在堆里,比如用Malloc或者静态变量来申明他的实体。
还有,不要对信号量类型的变量使用__packed属性修饰符。
3.什么时候用
例如本文一开始说的可以节省大量空间的地方,还有我们在解析或封装通信字节流的时候,或者需要写入Flash的结构体等。
相关资料阅读:
IAR关于未对其访问的介绍
https://www.iar.com/knowledge/support/technical-notes/compiler/accessing-unaligned-data/
微软关于#pragma pack的介绍
https://docs.microsoft.com/zh-cn/cpp/preprocessor/pack?view=msvc-160
扩展阅读:
以上是关于带你深入了解对齐与非对齐访问(ARM指令集)的主要内容,如果未能解决你的问题,请参考以下文章