ElasticSearch探索之路分布式原理:分布式路由存储搜索原理
Posted 凌桓丶
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ElasticSearch探索之路分布式原理:分布式路由存储搜索原理相关的知识,希望对你有一定的参考价值。
分布式存储
路由
当索引一个文档的时候,Elasticsearch会通过哈希来决定将文档存储到哪一个主分片中,路由计算公式如下:
shard = hash(routing) % number_of_primary_shards
//routing:默认为文档id,也可以自定义。
//number_of_primary_shards:主分片的数量
-
查询时指定routing:可以直接根据routing信息定位到某个分片查询,不需要查询所有的分配,经
过协调节点排序。
-
查询时不指定routing:因为不知道要查询的数据具体在哪个分片上,所以整个过程分为 2 个步骤
- 分发:请求到达协调节点后,协调节点将查询请求分发到每个分片上。
- 聚合:协调节点搜集到每个分片上查询结果,在将查询的结果进行排序,之后给用户返回结果。
从上面的这个公式我们也可以看到一个问题,路由的逻辑与当前主分片的数量强关联,也就是说如果分片数量变化了,那么所有之前路由的值都会无效,文档也再也找不到了。这也就是为什么我们要在创建索引的时候就确定好主分片的数量并且永远不会改变这个数量。
分片数量固定是否意味着会使索引难以进行扩容?
答案是否定的,Elasticsearch还提供了其他的一些方案来让我们轻松的实现扩容,如:
- 分片预分配:一个分片存在于单个节点,但一个节点可以持有多个分片。因此我们可以根据未来的数据的扩张状况来预先分配一定数量的分片到各个节点中。(注意⚠️:预先分配过多的分片会导致性能的下降以及影响搜索结果的相关度)
- 新建索引:分片数不够时,可以考虑新建索引,搜索1个有着50个分片的索引与搜索50个每个都有1个分片的索引完全等价。
更多关于水平拓展的内容可以参考官方文档扩容设计。
新增、索引和删除文档
我们可以发送请求到集群中的任一节点。 每个节点都有能力处理任意请求。 每个节点都知道集群中任一文档位置,所以可以直接将请求转发到需要的节点上。 在下面的例子中,将所有的请求发送到 Node 1 ,我们将其称为协调节点(coordinating node) 。
当发送请求的时候, 为了扩展负载,更好的做法是轮询集群中所有的节点。
新建、索引和删除请求都是写操作, 必须在主分片上面完成之后才能被复制到相关的副本分片。
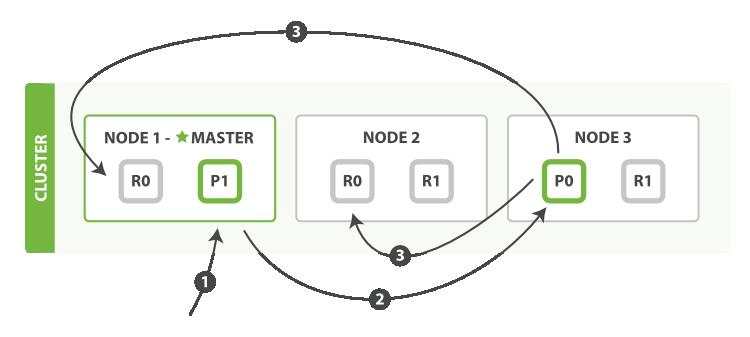
流程如下:
- 客户端向
Node 1发送新建、索引或者删除请求。 - 节点使用文档的
_id确定文档属于分片 0 。请求会被转发到Node 3,因为分片 0 的主分片目前被分配在Node 3上。 Node 3在主分片上面执行请求。如果成功了,它将请求并行转发到Node 1和Node 2的副本分片上。一旦所有的副本分片都报告成功,Node 3将向协调节点报告成功,协调节点向客户端报告成功。
取回文档
由于取回文档为读操作,我们可以从主分片或者从其它任意副本分片检索文档。
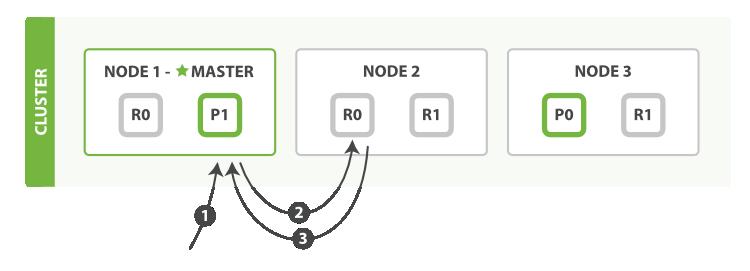
流程如下:
- 客户端向
Node 1发送获取请求。 - 节点使用文档的
_id来确定文档属于分片0。分片0的副本分片存在于所有的三个节点上。 在这种情况下,它将请求转发到Node 2。 Node 2将文档返回给Node 1,然后将文档返回给客户端。
在处理读取请求时,协调结点在每次请求的时候都会通过轮询所有的副本分片来达到负载均衡。
并发控制
在数据库领域中,有两种方法通常被用来确保并发更新时变更不会丢失:
- 悲观并发控制:这种方法被关系型数据库广泛使用,它假定有变更冲突可能发生,因此阻塞访问资源以防止冲突。 一个典型的例子是读取一行数据之前先将其锁住,确保只有放置锁的线程能够对这行数据进行修改。
- 乐观并发控制:Elasticsearch中使用的这种方法假定冲突是不可能发生的,并且不会阻塞正在尝试的操作。 然而,如果源数据在读写当中被修改,更新将会失败。应用程序接下来将决定该如何解决冲突。 例如,可以重试更新、使用新的数据、或者将相关情况报告给用户。
Elasticsearch是分布式的。当文档创建、更新或删除时, 新版本的文档必须复制到集群中的其他节点。Elasticsearch也是异步和并发的,这意味着这些复制请求被并行发送,并且到达目的地时也许会乱序。所以Elasticsearch 需要一种方法确保文档的旧版本不会覆盖新的版本。
在Elasticsearch中,其通过版本号机制来实现乐观并发控制。即每一个文档中都会有一个_version版本号字段,当文档被修改时版本号递增。 Elasticsearch使用_version来确保变更以正确顺序得到执行。如果旧版本的文档在新版本之后到达,它可以被简单的忽略。
我们可以利用_version号来确保应用中相互冲突的变更不会导致数据丢失。我们通过指定想要修改文档的 version 号来达到这个目的。 如果该版本不是当前版本号,我们的请求将会失败。
// 例如我们想更新文档的内容,并指定版本号为1
PUT /website/blog/1?version=1
{
"title": "My first blog entry",
"text": "Starting to get the hang of this..."
}
// 当文档的版本号为1时,次请求成功,同时响应体告诉我们版本号递增到2
{
"_index": "website",
"_type": "blog",
"_id": "1",
"_version": 2
"created": false
}
// 此时我们再次尝试更新文档的内容,仍然指定版本号为1,由于版本号不符合,此时返回409 Conflict HTTP 响应码
{
"error": {
"root_cause": [
{
"type": "version_conflict_engine_exception",
"reason": "[blog][1]: version conflict, current [2], provided [1]",
"index": "website",
"shard": "3"
}
],
"type": "version_conflict_engine_exception",
"reason": "[blog][1]: version conflict, current [2], provided [1]",
"index": "website",
"shard": "3"
},
"status": 409
}
分布式搜索
搜索需要一种更加复杂的执行模型,因为我们不知道查询会命中哪些文档,这些文档有可能在集群的任何分片上。 一个搜索请求必须询问我们关注的索引的所有分片的某个副本来确定它们是否含有任何匹配的文档。
但是找到所有的匹配文档仅仅完成事情的一半。 在 search 接口返回一个 page 结果之前,多分片中的结果必须组合成单个排序列表。 为此,搜索被执行成一个两阶段过程,我们称之为query then fetch(查询后取回)。
查询阶段
在查询阶段时, 查询会广播到索引中每一个分片拷贝(主分片或者副本分片)。 每个分片在本地执行搜索并构建一个匹配文档的优先队列。
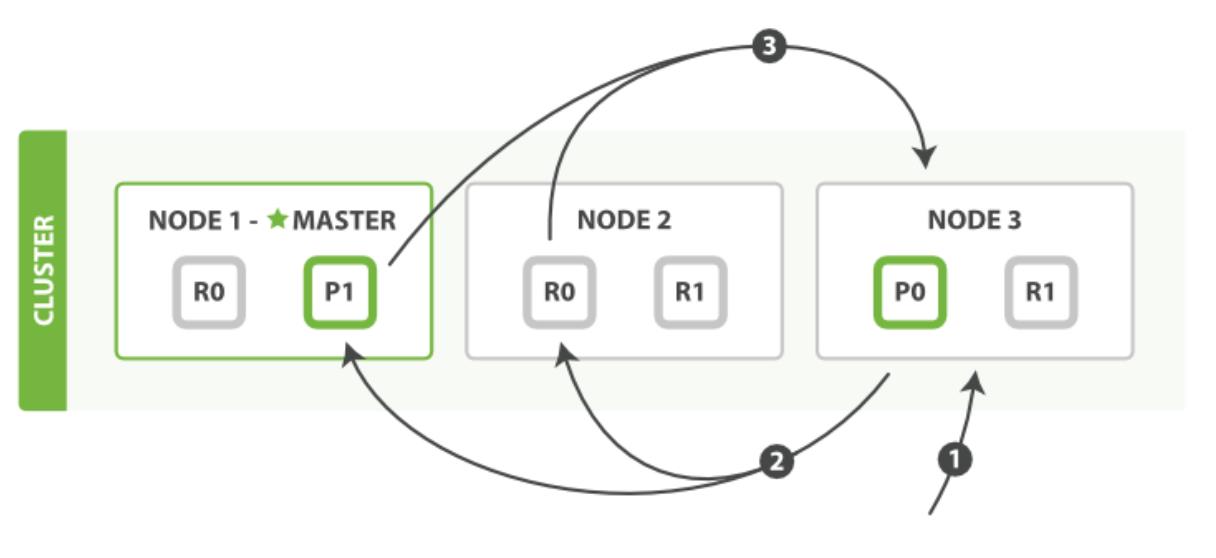
查询阶段包含以下三个步骤
- 客户端发送一个
search请求到Node 3,此时Node 3成为协调节点,由它来负责本次的查询。 Node 3将查询请求广播到索引的每个主分片或副本分片中。每个分片在本地执行查询并添加结果到大小为from + size的本地有序优先队列中。- 每个分片返回各自优先队列中所有文档的ID和排序值给协调节点,也就是
Node 3,它合并这些值到自己的优先队列中来产生一个全局排序后的结果列表。至此查询过程结束。
一个索引可以由一个或几个主分片组成, 所以一个针对单个索引的搜索请求需要能够把来自多个分片的结果组合起来。 针对 multiple 或者 all 索引的搜索工作方式也是完全一致的——仅仅是包含了更多的分片而已。
取回阶段
在查询阶段中,我们标识了哪些文档满足搜索请求,而接下来我们就需要取回这些文档。
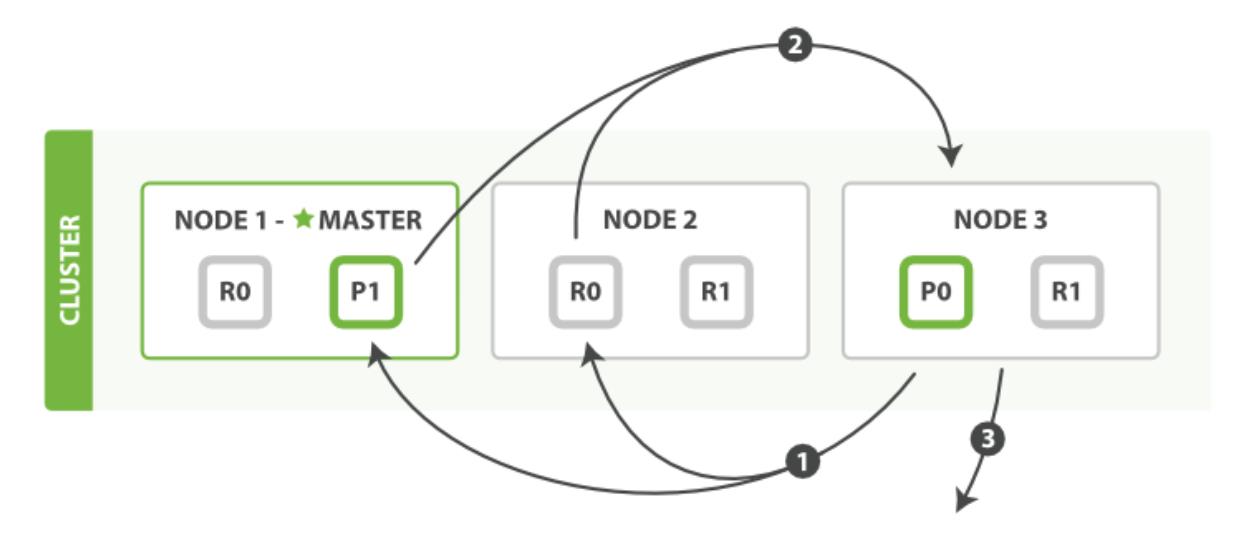
取回阶段由以下步骤构成
- 协调节点辨别出哪些文档需要被取回并向相关的分片提交多个
GET请求。例如,如果我们的查询指定了{ "from": 90, "size": 10 },最初的90个结果会被丢弃,只有从第91个开始的10个结果需要被取回。 - 每个分片加载并丰富文档(如_source字段和高亮参数),接着返回文档给协调节点。
- 协调节点等待所有文档被取回,将结果返回给客户端。
以上是关于ElasticSearch探索之路分布式原理:分布式路由存储搜索原理的主要内容,如果未能解决你的问题,请参考以下文章