硬核整理四万字,学会数据库只要一篇就够了,盘它!MySQL基本操作以及常用的内置函数汇总整理
Posted 北慕辰
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了硬核整理四万字,学会数据库只要一篇就够了,盘它!MySQL基本操作以及常用的内置函数汇总整理相关的知识,希望对你有一定的参考价值。

🧡💛💚💙💜🤎💗🧡💛💚💙💜🤎💗
感谢各位一直以来的支持和鼓励 , 制作不易
🙏 求点赞 👍 ➕ 收藏 ⭐ ➕ 关注✅
一键三连走起来 ! ! !
🧡💛💚💙💜🤎💗 🧡💛💚💙💜🤎💗
一、简单了解数据库
二、SQL语句的基本操作
(1)数据库的基本操作(登录,查看,创建,删除)
(2)创建表
(3)修改表
1.ADD 追加字段
2.MODIFY 修改字段的属性
3.DROP删除字段
4.修改表的名称
5.修改字段的名称
6.修改表的字符集
(4)表数据的增删改查
1.增加数据(insert)
2.删除数据(delete)
3.修改数据(updata)
4.查找数据(select)
(5)AS起别名 和 子句内容
1.AS起别名
2.子句内容
(6)LIMIT限制语句
(7)DISTINCT去重
(8)ORDER BY排序
(9)GROUP BY分组
(10)WHERE/HAVING筛选
(11)连表查询
1.union结果集进行合并(纵向合并)
2.left join(以左表为基准关联右表中的数据)
3.right join(以右表为基准关联左表中的数据)
4.inner join(求两张表的交集)
三、常用内置函数
(1)聚合函数
1. count(字段):求多少行数据
2.sum(字段):求和
3.avg(字段):平均数
4.max(字段):最大值
5.min(字段):最小值
(2)字符串函数
1.字段进行算术运算
2.字段进行拼接
(3)日期函数
1.获取当前日期
2.将当前日期转换为字符串(str)形式(DATE_FORMAT)
3.将当前字符串(str)转换为日期形式(STR_TO_DATE)
4.日期相减(DATEDIFF)
5.向日期添加指定的时间间隔(DATE_ADD)
(4)数值计算函数
1.四舍五入(round)
2.向上取整(ceil)
3.向下取整(floor)
4.随机数(0-1之间)(rand)
(5)空值判断函数(is null / is not null)
(6)条件判断函数(CASE WHEN)
一、简单了解数据库
(1)什么是数据库
数据库其实就是数据的仓库,而数据库和普通的数据仓库的区别在于,数据库是依据数据结构来组织数据的,由于数据库依据数据结构组建的,所以我们查看到的数据是条理化的,清晰明了。 我们经常说的 XX数据库,其实就是指的XX数据库管理系统,而数据库管理系统是一个软件,它是数据库服务的体现。
(2)数据库和普通文件系统的区别
数据库和普通文件系统的区别,在于数据库拥有数据结构,可以都快速的·查找到对应的数据
(3)数据库分类
根据数据结构的不同数据库可以分为关系型数据库和非关系型数据库
(4)什么是关系型数据库
关系型数据库是依据关系模型而创建数据库,关系模型就是一对一,一对多,多对多等关系模型,关系模型的存储格式是以行、列组成的二维表格,所以一个关系型数据库其实就是由二维表格之间的联系所组成的一个数据组织。我们常见的关系型数据库有,SQL Server、ORACLE、mysql、HSQL、SQLite等等。
(5)什么是非关系型数据库
由于关系型数据库的太大和太复杂,所以会使用“ 非关系型数据” 来表示其它类型的数据库;常见的非关系型的模型有:列模型:以列来存储数据,列模式的非关系型数据库的每一列为一条记录,而关系型数据库都是一行为一条记录。键值对模型:该模型存储的数据是一个个键值对的形式,例如name:list。文档类模型:用一个个文档来存储数据,也类似于键值对模式。我们常见的非关系型数据库有Redis、Hbase、MongoDB、cassandra等等。
那么下面就让我开始学习数据库的基本操作以及常用的函数吧!本文以MySQL数据库为例。
小北用的是Centos7虚拟机下安装的MySQL5.7;使用navicat软件来链接MySQL数据库操作–>centos7安装mysql5.7详细教程
二、SQL语句的基本操作
注意:每个命令执行结束都要加分号结束
查询所有的数据库: show databases;
切换数据库: use 库命名;
创建数据库: create database [IF NOT EXISTS] 库名;
删除数据库: drop database [IF EXISTS] 库名;
查询数据库创建: show 建库语句;
指定数据库采用的字符集: CHARACTER SET
注意:
1.建议不要修改mysql服务器的编码集,表的编码集默认和库一致的
2.sql语句对大小写不敏感
3.IF NOT EXISTS 指创建的库或表是否不存在,若不存在则创建,否则不创建
4.IF EXISTS 指创建的库或表是否存在,已存在则不创建,否则创建
5.[] 是用来表示里面的内容可用可不用,[]并不是sql语法
(1)数据库的基本操作(登录,查看,创建,删除)
登录MySQL数据库:
mysql -u用户名 -p登录密码;

查看数据库:
show databases;
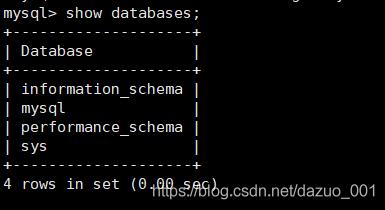
创建数据库
create database if not exists beimuchen;

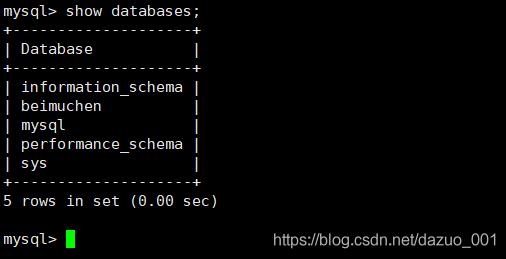
查看数据库的创建信息
show create database beimuchen;
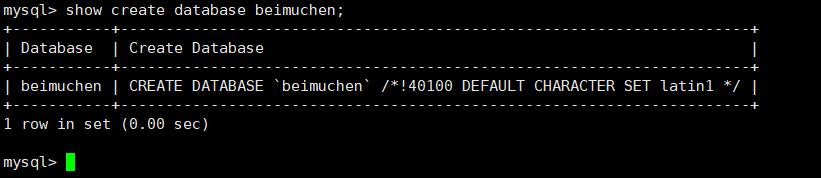
删除数据库
drop database if exists beimuchen;
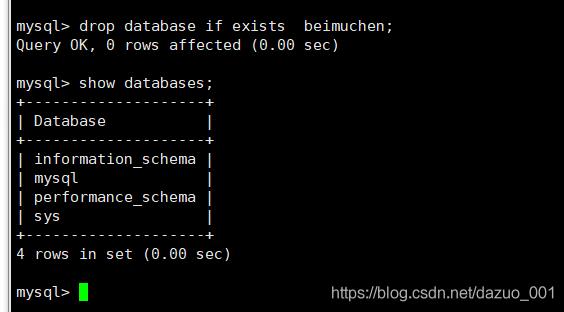
(2)创建表
使用create database if not exists beimuchen;创建数据库;下面我们就进入navicat软件来操作数据库;
创建表的一般格式:
create table [if exists] 表名(
字段1 数据类型 字段属性,
字段2 数据类型 字段属性,
...
字段N 数据类型 字段属性,
primary key(字段)
)engine=引擎 default charset=编码集;
使用navicat新建查询来创建表格
-- 使用beimuchen数据库
USE beimuchen;
-- 创建学生表
-- 字段类型int VARIANCE(长度)
-- NOT NULL 设置字段的属性为非空,也可设置为空
-- AUTO_INCREMENT设置自增,一般用于主键,数值会自动加1
-- DEFAULT 设置默认值
-- ENGINE=INNODB 指定引擎
-- CHARSET=utf8 指定表的编码集
CREATE TABLE student(
student_id INT NOT NULL AUTO_INCREMENT,
student_name INT NOT NULL,
student_sex VARCHAR(50) NOT NULL DEFAULT "男",
PRIMARY KEY(student_id)
)ENGINE=INNODB DEFAULT CHARSET=utf8;
查看建的表的结构
show create table student;
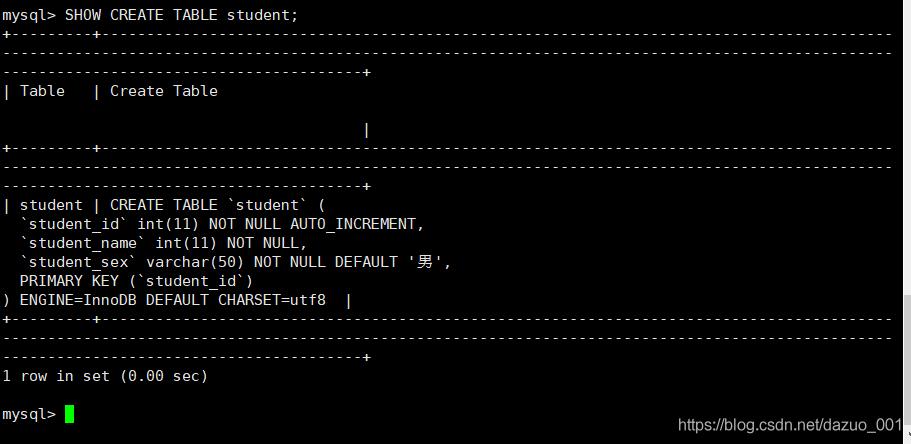
或者使用desc student查看表的结构
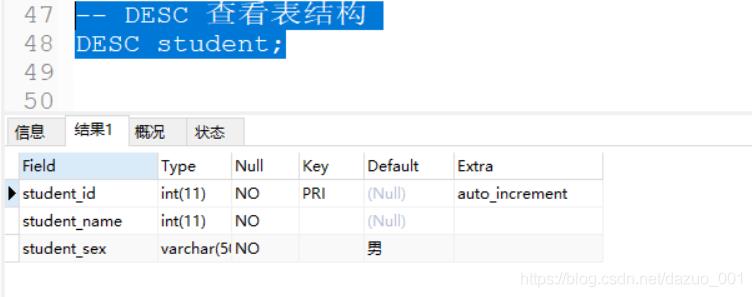
(3)修改表
点我返回目录
使用 ALTER TABLE 语句追加, 修改, 或删除列的语法.
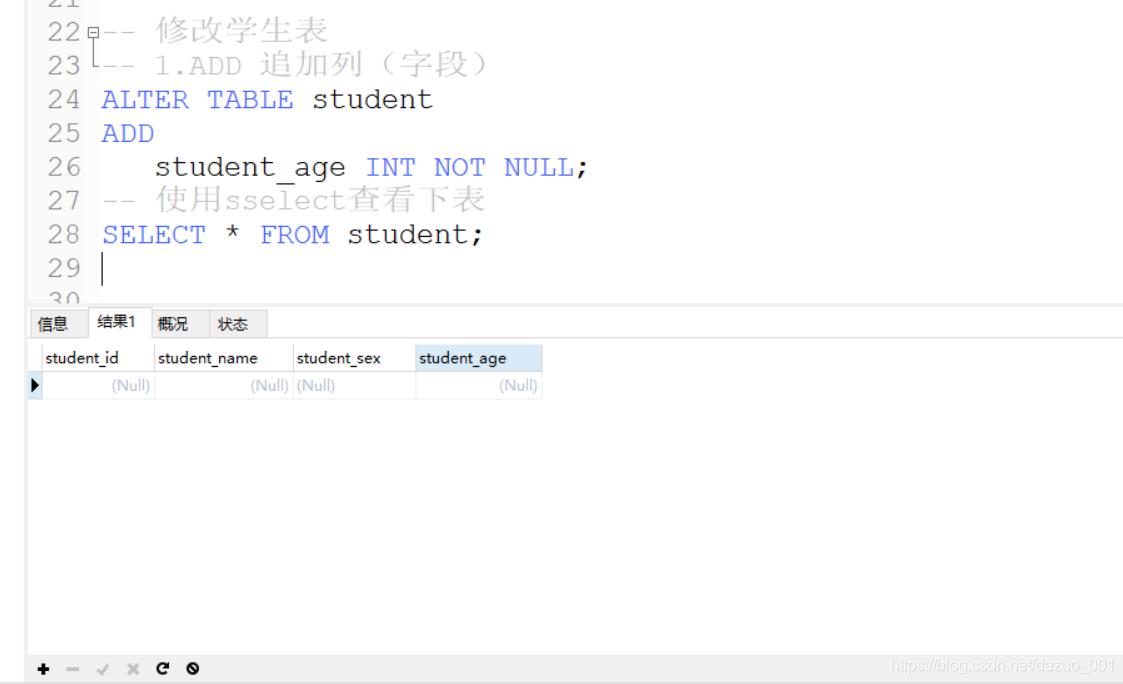
1.ADD追加字段
点我返回目录
使用的一般格式
alter table 表名 add 字段 字段数据类型 属性;
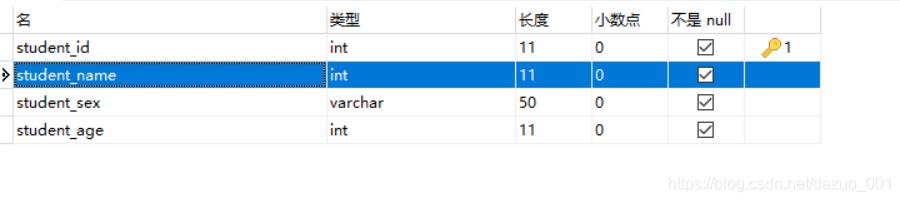
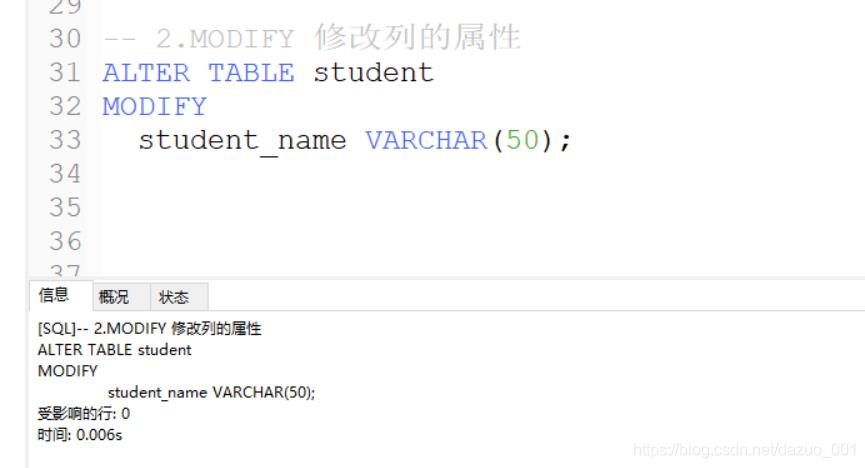
2.MODIFY 修改字段的属性
使用的一般格式
alter table 表名 modify 字段 数据类型 属性;
由于前面我们设置了student_name为int类型,需要修改为varchar字符类型

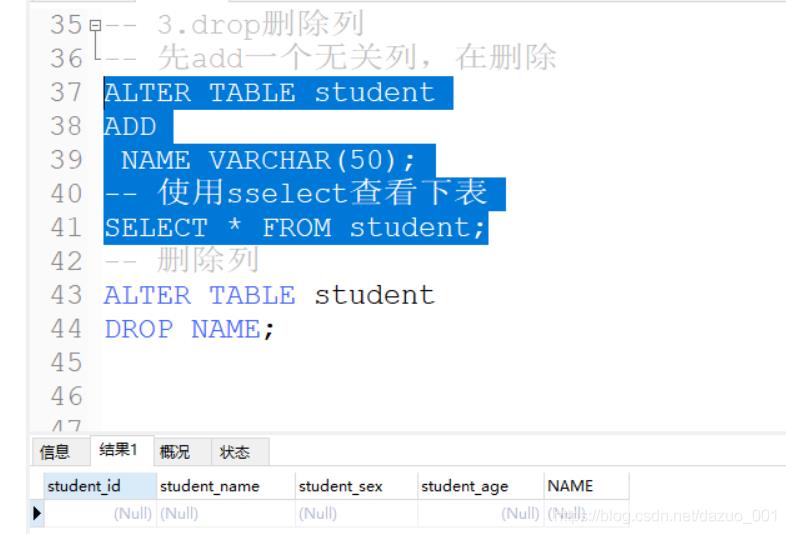
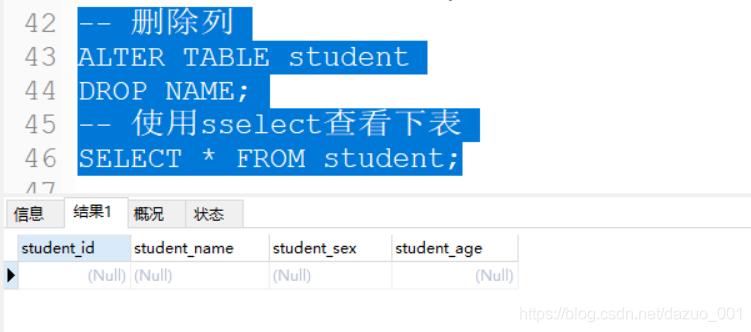
3.DROP删除字段
点我返回目录
使用的一般格式
ALTER TABLE table DROP 字段;
4.修改表的名称
rename table 表名 to 新表名;

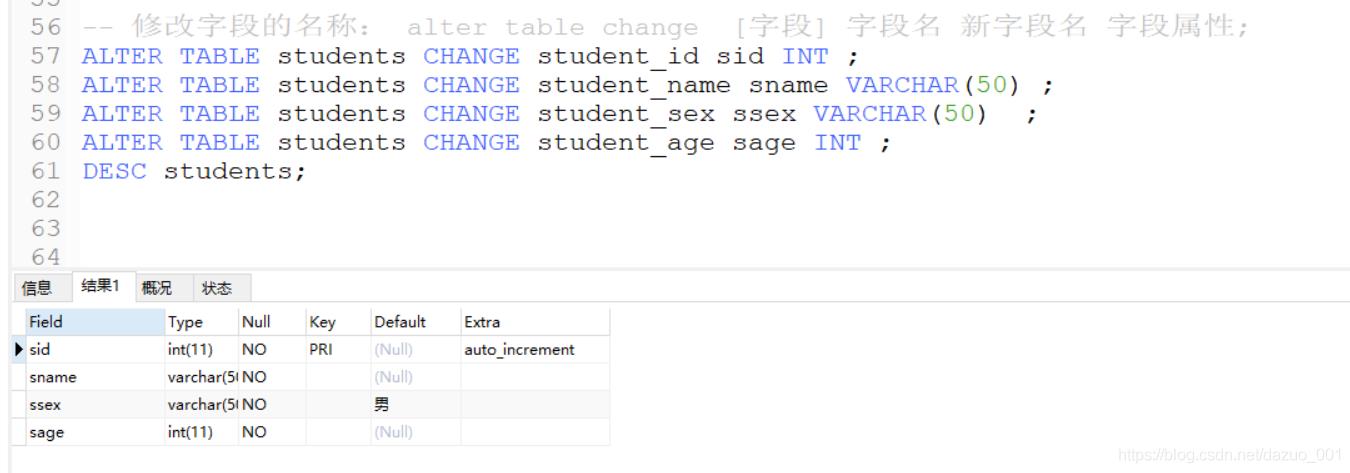
5.修改字段的名称
alter table 表名 change 旧字段 新字段 数据类型 属性;
6.修改表的字符集
alter table 表名 character set 编码集;
(4)表数据的增删改查
1.增加数据(insert)
格式:
insert into 表名(字段) values(值),(值)...(值);
INSERT INTO students(sid,sname,ssex,sage) VALUES(100010,'张三','男',20);
-- 由于创建表时设置了id的自增,插入第二条数据时,不写id,会以前一条的记录为基准自增1
INSERT INTO students(sname,ssex,sage) VALUES('李四','男',21);
INSERT INTO students(sname,ssex,sage) VALUES('李三','女',22);
INSERT INTO students(sname,ssex,sage) VALUES('李五','男',19);
INSERT INTO students(sname,ssex,sage) VALUES('李六','女',18);
-- 由于创建表时设置了性别sex的默认值为‘男’,插入数据时可以不写性别,默认为男
INSERT INTO students(sname,sage) VALUES('王五',19);
INSERT INTO students(sname,sage) VALUES('王六',17);
INSERT INTO students(sname,sage) VALUES('王七',18);
INSERT INTO students(sname,sage) VALUES('王九',16);
INSERT INTO students(sid,sname,ssex,sage) VALUES(100110,'张晓晓','女',22);
INSERT INTO students(sid,sname,ssex,sage) VALUES(100210,'李天爱','女',21);
INSERT INTO students(sid,sname,ssex,sage) VALUES(100150,'张鹏飞','男',25);

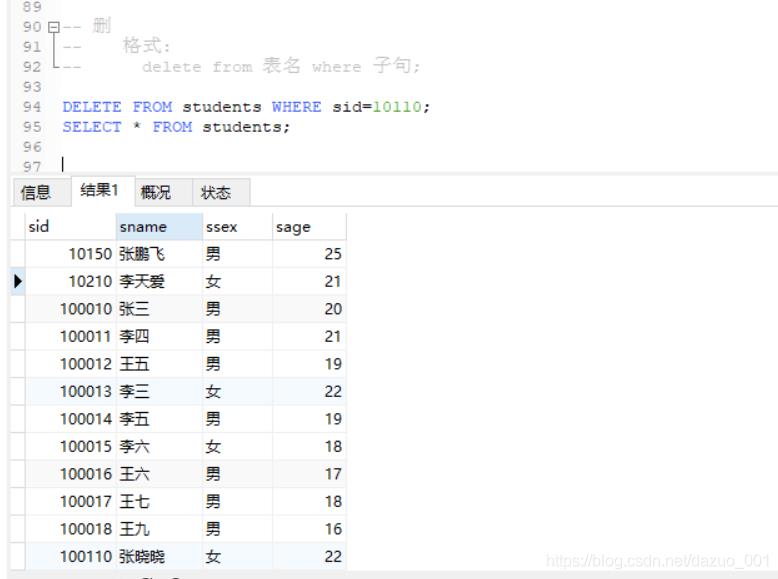
2.删除数据(delete)
格式:
delete from 表名 where 子句;
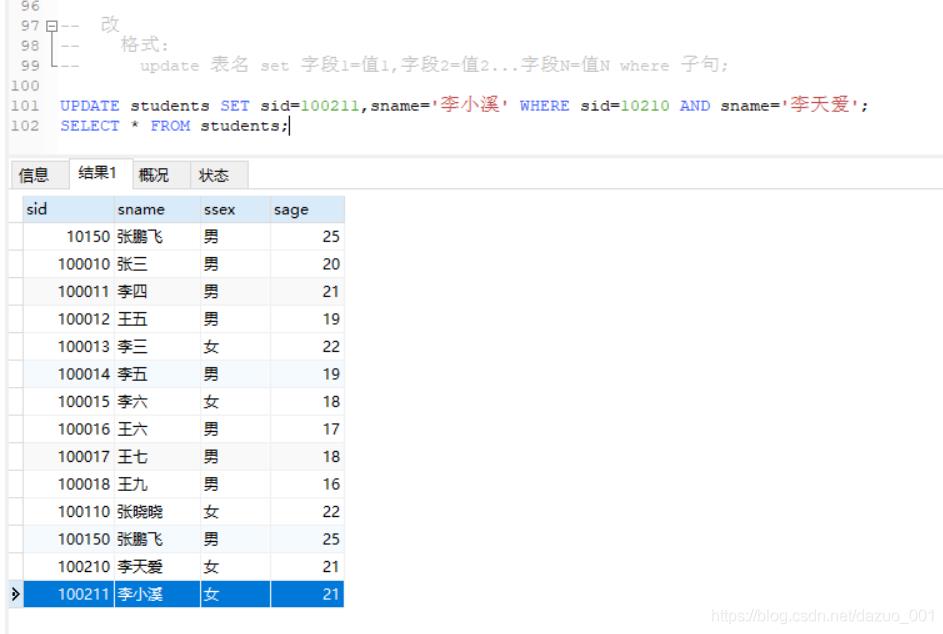
3.修改数据(updata)
格式:
update 表名 set 字段1=值1,字段2=值2...字段N=值N where 子句;
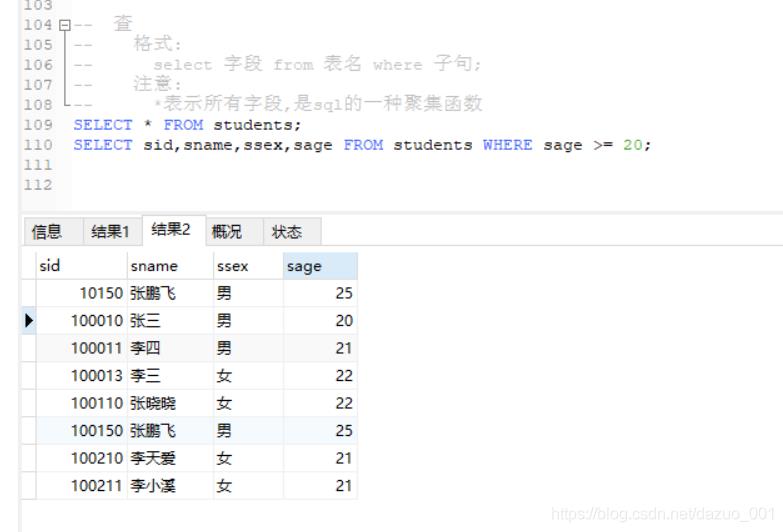
4.查找数据(select)
格式:
select 字段 from 表名 where 子句;
注意:
* 表示所有字段,是sql的一种聚集函数
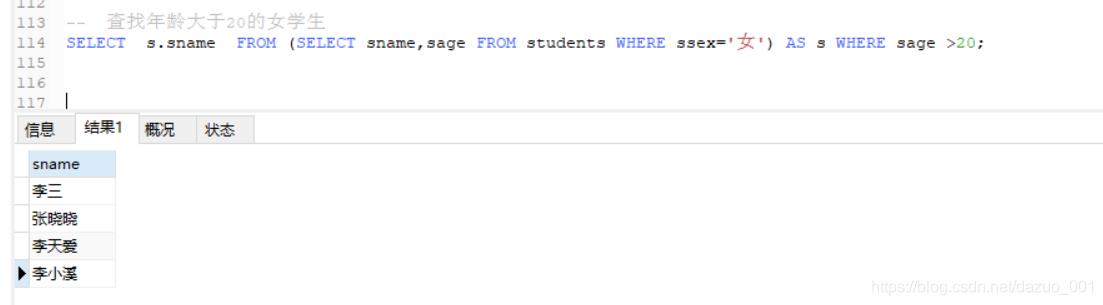
(5)AS起别名 和 子句内容
1.AS起别名
格式:
字段 as 名称
注意:
as 可加可不加
一般用于给子查询的数据表起别名,方便使用
2.子句内容
子句:
> < <= >= = <> 大于、小于、大于(小于)等于、不等于
between ...and... 显示在某一区间的值(含头含尾)
in(set) 显示在in列表中的值,例:in(100,200)只能匹配100或200
like '张_' 模糊查询 使用% 和 _ ( %表示匹配所有 _表示匹配一个)
Is null 判断是否为空
and 多个条件同时成立
or 多个条件中任一一个成立
not 不成立,例:where not(expection>10000);
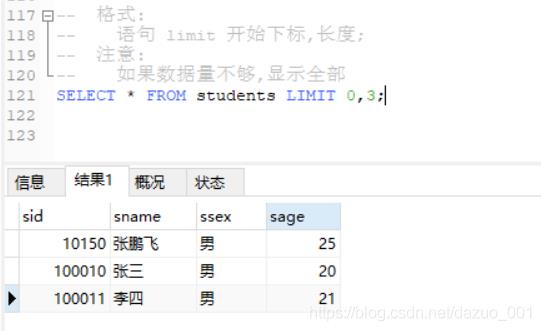
(6)LIMIT限制语句
格式:
语句 limit 开始下标,长度;
注意:
如果数据量不够,显示全部
例如: 从下标为0开始显示10条
select * from stduents limit 0,10;
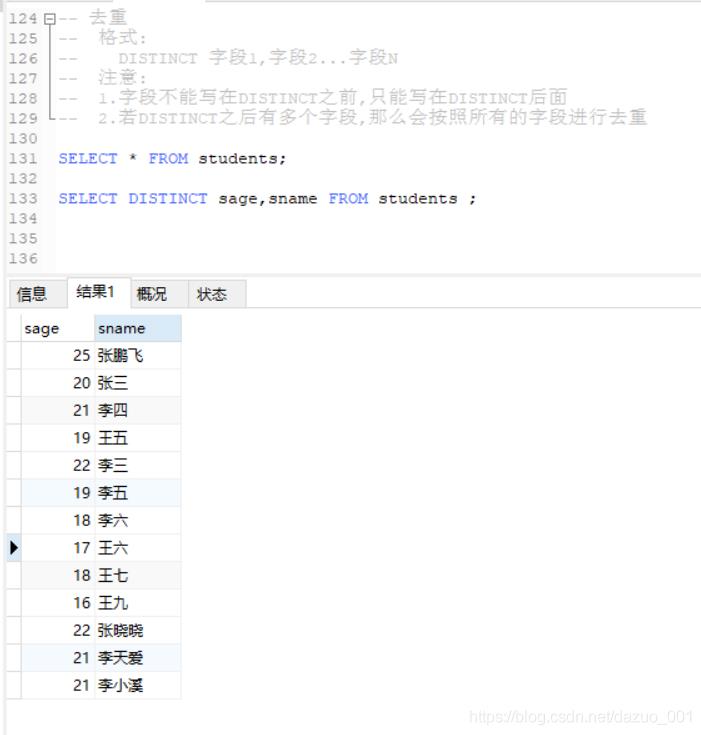
(7)DISTINCT去重
格式:
DISTINCT 字段1,字段2...字段N
注意:
1.字段不能写在DISTINCT之前,只能写在DISTINCT后面
2.若DISTINCT之后有多个字段,那么会按照所有的字段进行去重
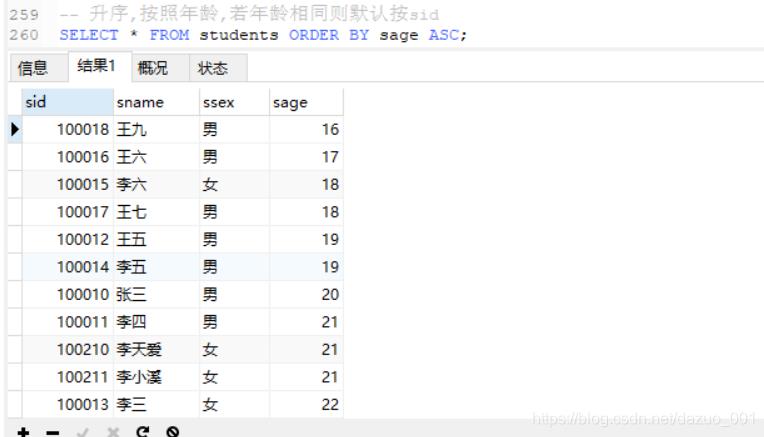
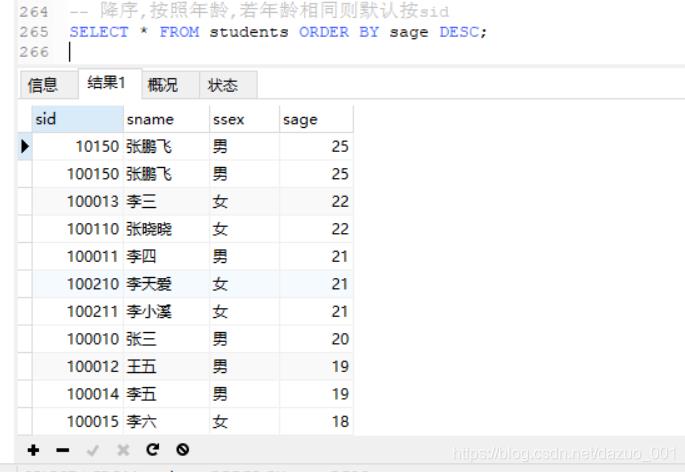
(8)ORDER BY排序
格式:
order by 字段1 asc|desc,字段2 asc|desc...字段n asc|desc;
例如:按照age进行降序排列,age相同按照id进行降序排列
select * from students order by age desc,id desc;
注意:
默认升序asc,降序desc
如果有多个字段,按照先后顺序依次排序
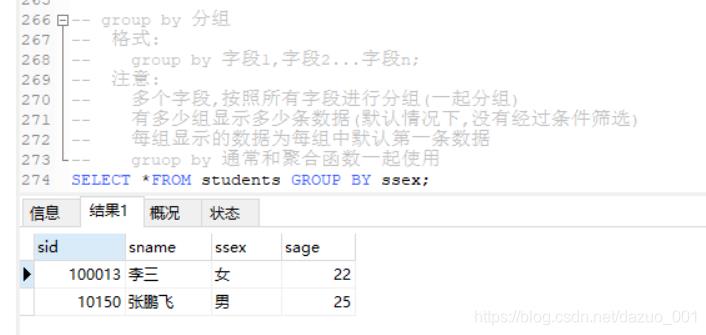
(9)GROUP BY分组
格式:
group by 字段1,字段2...字段n;
注意:
1.若多个字段会按照所有字段进行分组(一起分组)
2.有多少组显示多少条数据(默认情况下,没有经过条件筛选)
3.每组显示的数据为每组中默认第一条记录
4.gruop by 通常和聚合函数一起使用
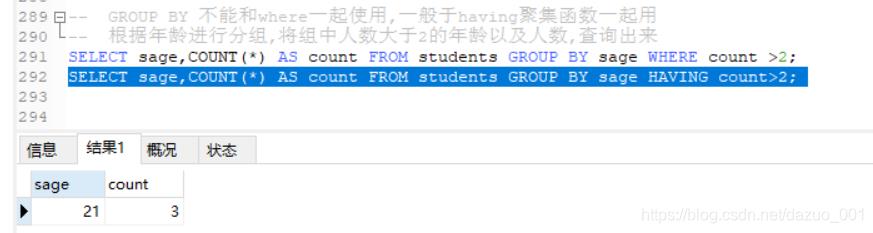
(10)WHERE/HAVING筛选
WHERE和HAVING之间的区别:having可以使用聚合函数,但where不行
不使用聚集函数,where和having都可用
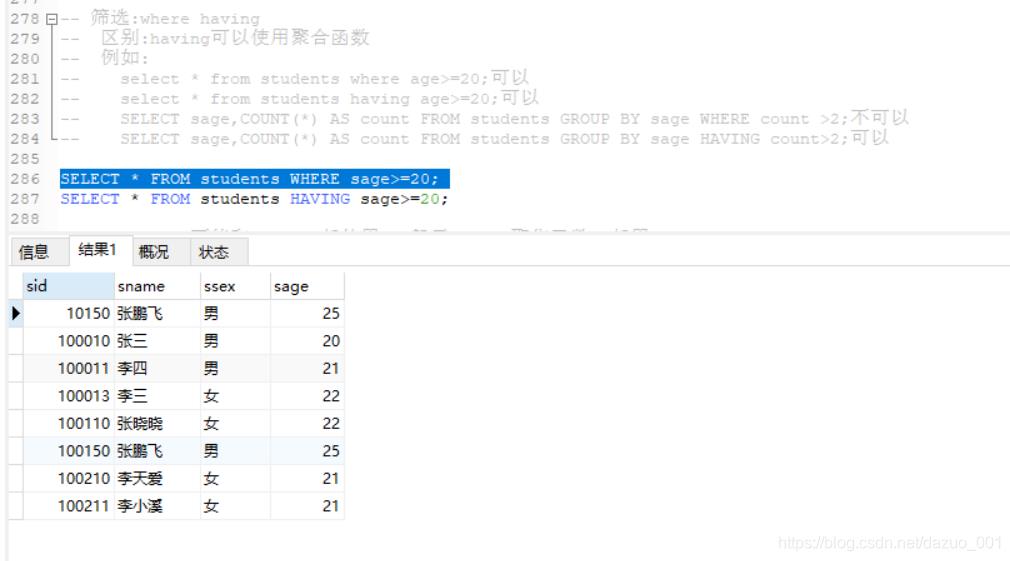
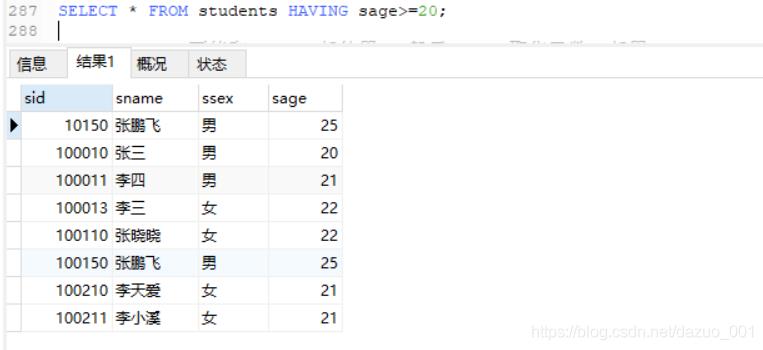
使用聚集函数,不能使用where仅能用having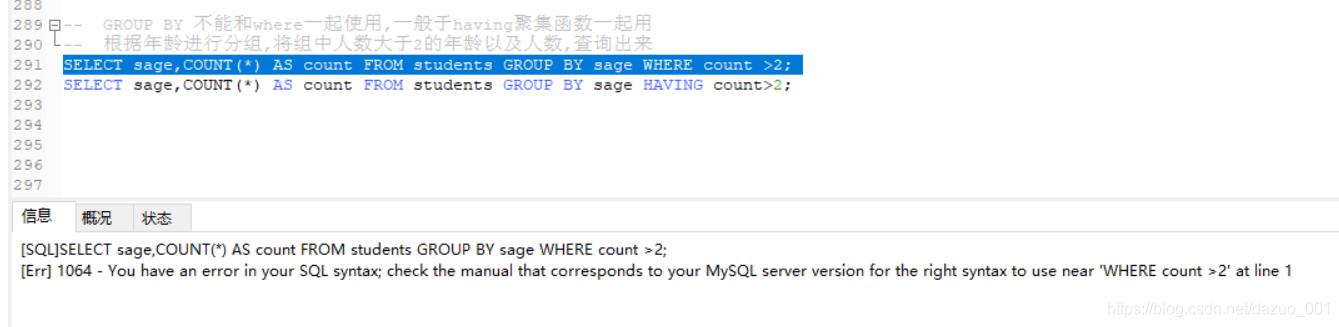
(11)连表查询
-- 新建一个学生表
CREATE TABLE `student` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) NOT NULL,
`age` int(11) DEFAULT NULL,
`sex` enum('0','1') DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1001 DEFAULT CHARSET=utf8;
-- 添加学生信息
insert into student(name,age,sex)VALUES("李四",19,"1");
insert into student(name,age,sex)VALUES("王五",20,"1");
insert into student(name,age,sex)VALUES("赵六",21,"1");
insert into student(name,age,sex)VALUES("钱琪",22,"1");
insert into student(name,age,sex)VALUES("杨甜甜",18,"0");
insert into student(name,age,sex)VALUES("赵丽丽",19,"0");
insert into student(name,age,sex)VALUES("苗莎莎",20,"0");
insert into student(name,age,sex)VALUES("周慧慧",22,"0");
insert into student(name,age,sex)VALUES("刘翠翠",23,"0");
-- 创建成绩表
CREATE TABLE score(
`id` int(11) NOT NULL AUTO_INCREMENT,
`subjectName` varchar(255) NOT NULL,
`score` int(11) NOT NULL,
`studentId` int(11) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=31 DEFAULT CHARSET=utf8;
-- 添加学生成绩
insert into score(subjectName,score,studentId)VALUES("语文",80,1001);
insert into score(subjectName,score,studentId)VALUES("数学",89,1001);
insert into score(subjectName,score,studentId)VALUES("英语",73,1001);
insert into score(subjectName,score,studentId)VALUES("语文",81,1002);
insert into score(subjectName,score,studentId)VALUES("数学",99,1002);
insert into score(subjectName,score,studentId)VALUES("英语",94,1002);
insert into score(subjectName,score,studentId)VALUES("语文",65,1003);
insert into score(subjectName,score,studentId)VALUES("数学",45,1003);
insert into score(subjectName,score,studentId)VALUES("英语",12以上是关于硬核整理四万字,学会数据库只要一篇就够了,盘它!MySQL基本操作以及常用的内置函数汇总整理的主要内容,如果未能解决你的问题,请参考以下文章