JavaScript为什么是单线程-JS异步与回调详解
Posted BY彡阿长
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了JavaScript为什么是单线程-JS异步与回调详解相关的知识,希望对你有一定的参考价值。
javascript为什么是单线程
JavaScript 最初被设计为浏览器脚本语言,主要用途包括对页面的操作、与浏览器的交互、与用户的交互、页面逻辑处理等。如果将 JavaScript 设计为多线程,那当多个线程同时对同一个 DOM 节点进行操作时,线程间的同步问题会变得很复杂。
同步任务与异步任务
-
同步任务:在主线程上排队执行的任务,前一个任务完整地执行完成后,后一个任务才会被执行。
-
异步任务:不会阻塞主线程,在其任务执行完成之后,会再根据一定的规则去执行相关的回调。
同步任务与函数调用栈
在 JavaScript 中,同步任务基本上可以认为是执行 JavaScript 代码。在上一讲内容中,我们提到 JavaScript 在执行过程中每进入一个不同的运行环境时,都会创建一个相应的执行上下文。那么,当我们执行一段 JavaScript 代码时,通常会创建多个执行上下文。
而 JavaScript 解释器会以栈的方式管理这些执行上下文、以及函数之间的调用关系,形成函数调用栈(call stack)(调用栈可理解为一个存储函数调用的栈结构,遵循 FILO(先进后出)的原则)。
我们来看一下 JavaScript 中代码执行的过程:
-
首先进入全局环境,全局执行上下文被创建并添加进栈中;
-
每调用一个函数,该函数执行上下文会被添加进调用栈,并开始执行;
-
如果正在调用栈中执行的 A 函数还调用了 B 函数,那么 B 函数也将会被添加进调用栈;
-
一旦 B 函数被调用,便会立即执行;
-
当前函数执行完毕后,JavaScript 解释器将其清出调用栈,继续执行当前执行环境下的剩余的代码。
由此可见,JavaScript 代码执行过程中,函数调用栈栈底永远是全局执行上下文,栈顶永远是当前执行上下文。
在不考虑全局执行上下文时,我们可以理解为刚开始的时候调用栈是空的,每当有函数被调用,相应的执行上下文都会被添加到调用栈中。执行完函数中相关代码后,该执行上下文又会自动被调用栈移除,最后调用栈又回到了空的状态(同样不考虑全局执行上下文)。
调用栈示例
还是来个示例,捋清楚一下
let a = 10;
function test() {
console.log("你好");
};
test();
通过Chrome的调试工具可以看到,代码执行过程中产生了两个执行上下文,当前栈顶为test函数的执行上下文,顺便一说,这里的Scope中有三个:Local,Script,Global,Local代表函数的作用域,而Script则是let关键字产生的块级作用域,Global毋庸置疑就是全局环境
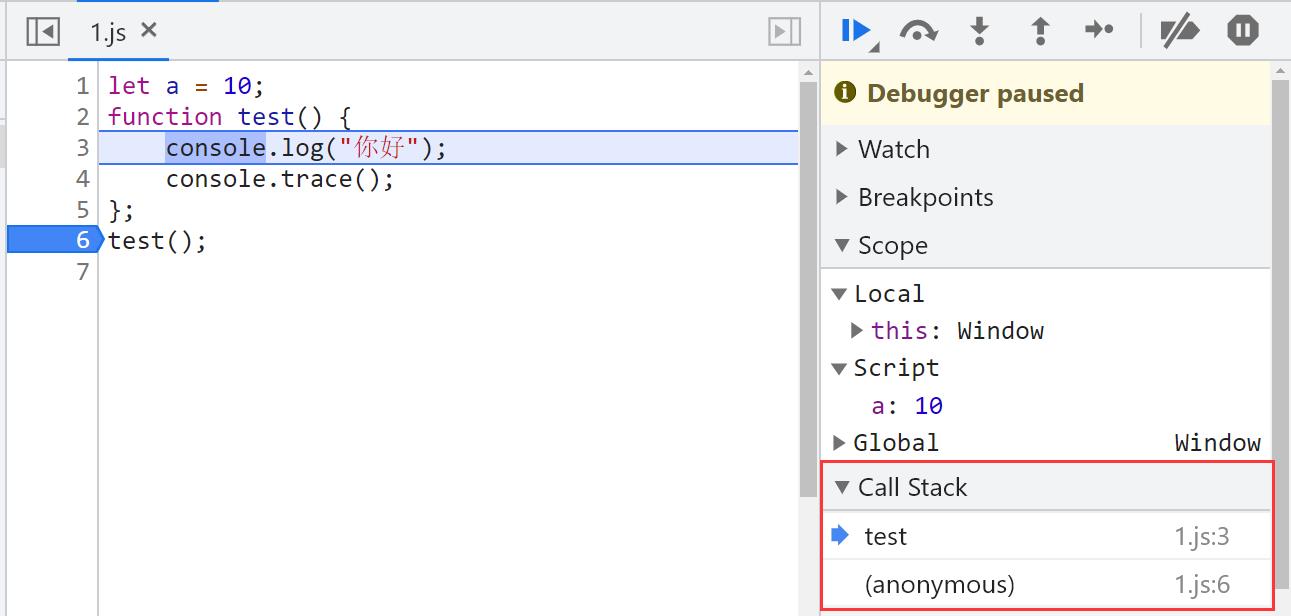
我们也可以直接通过console.trace();API向控制台输出一个输出一个堆栈跟踪
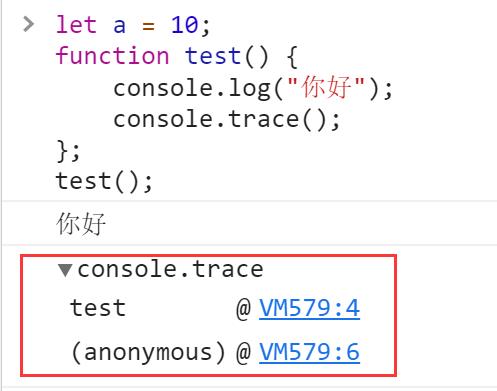
但是栈的容量是有限制的,所以当我们没有合理调用函数的时候,可能会导致爆栈异常,此时控制台便会抛出错误:
递归爆栈
function fn(n) {
if (n < 1) {
return
}
console.log(n);
fn(n - 1)
}
fn(100000)

这样的一个函数调用栈结构,可以理解为 JavaScript 中同步任务的执行环境,同步任务也可以理解为 JavaScript 代码片段的执行。
同步任务的执行会阻塞主线程,也就是说,一个函数执行的时候不会被抢占,只有在它执行完毕之后,才会去执行任何其他的代码。这意味着如果我们一个任务执行的时间过长,浏览器就无法处理与用户的交互,例如点击或滚动。
因此,我们还需要用到异步任务。
异步任务与回调队列
异步任务
异步任务包括一些需要等待响应的任务,包括用户交互、HTTP 请求、定时器等。
setTimeout(() => {
console.log("张三")
}, 0);
console.log("你好");
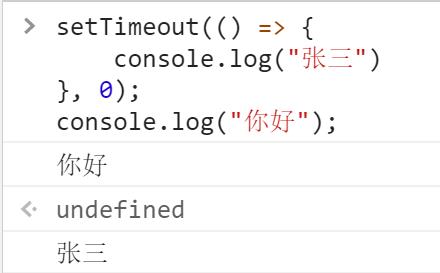
此处可以看出,同步任务总是优先于异步任务执行,即使定时器定时为0,但其实不是真正的0。
我们知道,I/O 类型的任务会有较长的等待时间,对于这类无法立刻得到结果的事件,可以使用异步任务的方式。这个过程中 JavaScript 线程就不用处于等待状态,CPU 也可以处理其他任务。
异步任务需要提供回调函数,当异步任务有了运行结果之后,该任务则会被添加到回调队列中,主线程在适当的时候会从回调队列中取出相应的回调函数并执行。
回调队列
这里提到的回调队列又是什么呢?
实际上,JavaScript 在运行的时候,除了函数调用栈之外,还包含了一个待处理的回调队列。在回调队列中的都是已经有了运行结果的异步任务,每一个异步任务都会关联着一个回调函数。
回调队列则遵循 FIFO(先进先出)的原则,JavaScript 执行代码过程中,会进行以下的处理:
-
运行时,会从最先进入队列的任务开始,处理队列中的任务;
-
被处理的任务会被移出队列,该任务的运行结果会作为输入参数,并调用与之关联的函数,此时会产生一个函数调用栈;
-
函数会一直处理到调用栈再次为空,然后 Event Loop 将会处理队列中的下一个任务。
这里我们提到了 Event Loop,它主要是用来管理单线程的 JavaScript 中同步任务和异步任务的执行问题。
示例
此处还是举一个栗子吧
window.setTimeout除了回调函数和延迟时间外,还有一个可选的参数,当定时器到期,会作为参数传递给回调函数
setTimeout((name) => {
console.log(name)
console.trace();
}, 0, "张三");
console.log("你好");

可以看出,的的确确是将结果传递过去了,并且产生了相应的调用栈
单线程的 JavaScript 是如何管理任务的
事件循环Event Loop
我们知道,单线程的设计会存在阻塞问题,为此 JavaScript 中任务被分为同步和异步任务。那么,同步任务和异步任务之间是按照什么顺序来执行的呢?
JavaScript 有一个基于事件循环的并发模型,称为事件循环(Event Loop),它的设计解决了同步任务和异步任务的管理问题。
根据 JavaScript 运行环境的不同,Event Loop 也会被分成浏览器的 Event Loop 和 Node.js 中的 Event Loop。
浏览器的 Event Loop
在浏览器里,每当一个被监听的事件发生时,事件监听器绑定的相关任务就会被添加进回调队列。通过事件产生的任务是异步任务,常见的事件任务包括:
-
用户交互事件产生的事件任务,比如输入操作;
-
计时器产生的事件任务,比如
setTimeout; -
异步请求产生的事件任务,比如 HTTP 请求。
JavaScript 的运行过程,可以借用 Philip Roberts 演讲《Help, I’m stuck in an event-loop》中经典的一张图来描述:
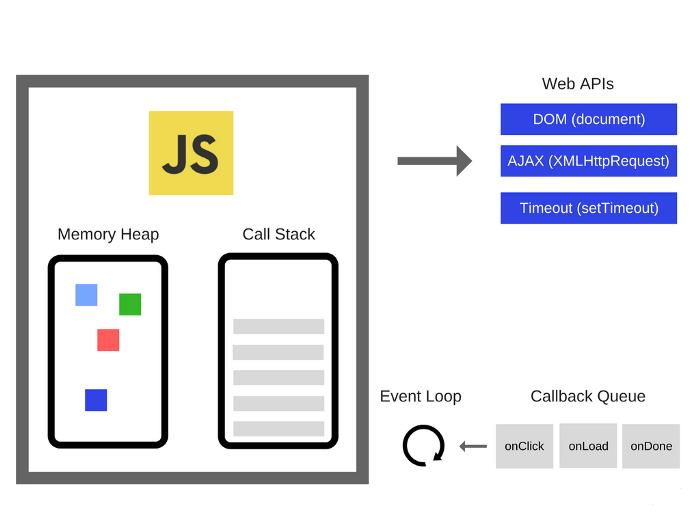
如图,主线程运行的时候,会产生堆(heap)和栈(stack),其中堆为内存、栈为函数调用栈。我们能看到,Event Loop 负责执行代码、收集和处理事件以及执行队列中的子任务,具体包括以下过程。
这个过程很重要,理解记忆
-
JavaScript 有一个主线程和调用栈,所有的任务最终都会被放到调用栈等待主线程执行。
-
同步任务会被放在调用栈中,按照顺序等待主线程依次执行。
-
主线程之外存在一个回调队列,回调队列中的异步任务最终会在主线程中以调用栈的方式运行。
-
同步任务都在主线程上执行,栈中代码在执行的时候会调用浏览器的 API,此时会产生一些异步任务。
-
异步任务会在有了结果(比如被监听的事件发生时)后,将异步任务以及关联的回调函数放入回调队列中。
-
调用栈中任务执行完毕后,此时主线程处于空闲状态,会从回调队列中获取任务进行处理。
上述过程会不断重复,这就是 JavaScript 的运行机制,称为事件循环机制(Event Loop)。
Event Loop 的设计会带来一些问题,比如setTimeout、setInterval的时间精确性。这两个方法会设置一个计时器,当计时器计时完成,需要执行回调函数,此时才把回调函数放入回调队列中。
如果当回调函数放入队列时,假设队列中还有大量的回调函数在等待执行,此时就会造成任务执行时间不精确。
要优化这个问题,可以使用系统时钟来补偿计时器的不准确性,从而提升精确度。举个例子,如果你的计时器会在回调时触发二次计时,可以在每次回调任务结束的时候,根据最初的系统时间和该任务的执行时间进行差值比较,来修正后续的计时器时间。
Node.js 中的 Event Loop
除了浏览器,Node.js 中同样存在 Event Loop。由于 JavaScript 是单线程的,Event Loop 的设计使 Node.js 可以通过将操作转移到系统内核中,来执行非阻塞 I/O 操作。
Node.js 中的事件循环执行过程为:
-
当 Node.js 启动时将初始化事件循环,处理提供的输入脚本;
-
提供的输入脚本可以进行异步 API 调用,然后开始处理事件循环;
-
在事件循环的每次运行之间,Node.js 会检查它是否正在等待任何异步 I/O 或计时器,如果没有,则将其干净地关闭。
与浏览器不一样,Node.js 中事件循环分成不同的阶段:
┌───────────────────────────┐
┌─>│ timers │
│ └─────────────┬─────────────┘
│ ┌─────────────┴─────────────┐
│ │ pending callbacks │
│ └─────────────┬─────────────┘
│ ┌─────────────┴─────────────┐
│ │ idle, prepare │
│ └─────────────┬─────────────┘ ┌───────────────┐
│ ┌─────────────┴─────────────┐ │ incoming: │
│ │ poll │<─────┤ |
│ └─────────────┬─────────────┘ │ data, etc. │
│ ┌─────────────┴─────────────┐ └───────────────┘
│ │ check │
│ └─────────────┬─────────────┘
│ ┌─────────────┴─────────────┐
└──┤ close callbacks │
└───────────────────────────┘
由于事件循环阶段划分不一致,Node.js 和浏览器在对宏任务和微任务的处理上也不一样。
| Event Loop | 描述 |
|---|---|
| timers | 此阶段由setTimeout()和安排的回调setInterval()执行 |
| pending callbacks | 执行推迟到下一个循环迭代的I/O回调 |
| idle/prepare | 仅在Node.js内部使用 |
| poll | 检索新的I/O事件,执行与I/O相关的回调,节点将在此处阻塞 |
| check | setImmediate()在这里回调 |
| close callbacks | 一些关闭回调,例如socket.on('close',...) |
宏任务和微任务
事件循环中的异步回调队列有两种:宏任务(MacroTask)和微任务(MicroTask)队列。
什么是宏任务和微任务呢?
- 宏任务:包括 script 全部代码、
setTimeout、setInterval、setImmediate(Node.js)、requestAnimationFrame(浏览器)、I/O 操作、UI 渲染(浏览器),这些代码执行便是宏任务。 - 微任务:包括
process.nextTick(Node.js)、Promise、MutationObserver,这些代码执行便是微任务。
区分的目的
为什么要将异步任务分为宏任务和微任务呢?这是为了避免回调队列中等待执行的异步任务(宏任务)过多,导致某些异步任务(微任务)的等待时间过长。在每个宏任务执行完成之后,会先将微任务队列中的任务执行完毕,再执行下一个宏任务。
因此,前面我们所说的回调队列可以理解为宏任务队列,同时还有另外一个任务队列为微任务队列。
宏任务和微任务的执行过程
在浏览器的异步回调队列中,宏任务和微任务的执行过程如下:
- 0宏任务队列一次只从队列中取一个任务执行,执行完后就去执行微任务队列中的任务。
- 微任务队列中所有的任务都会被依次取出来执行,直到微任务队列为空。
- 在执行完所有的微任务之后,执行下一个宏任务之前,浏览器会执行 UI 渲染操作、更新界面。
我们能看到,在浏览器中每个宏任务执行完成后,会执行微任务队列中的任务。而在 Node.js 中,事件循环分为 6 个阶段,微任务会在事件循环的各个阶段之间执行。也就是说,每当一个阶段执行完毕,就会去执行微任务队列的任务。
宏任务和微任务的执行顺序,常常会被用作面试题,比如下面这道考察Promise、setTimeout、async/await等 API 执行顺序的题目:
console.log("script start");
setTimeout(() => {
console.log("setTimeout");
}, 1000);
Promise.resolve()
.then(function () {
console.log("promise1");
})
.then(function () {
console.log("promise2");
});
async function errorFunc() {
try {
await Promise.reject("error!!!");
} catch (e) {
console.log("error caught"); // 微1-3
}
console.log("errorFunc");
return Promise.resolve("errorFunc success");
}
errorFunc().then((res) => console.log("errorFunc then res"));
console.log("script end");
分析
首先执行同步代码
console.log("script start");
setTimeout(() => {
// 8
console.log("setTimeout");
}, 1000);
console.log("script end");
但由于setTimeout是异步任务,所以不会等待它执行完成,
而是开启一个浏览器的定时器线程,这个线程在渲染器进程中,指定一个回调函数,到期后再讲回调函数放入异步回调队列
执行完以上代码后,此时的微任务有 Promise.resolve(), errorFunc(),把它们加入异步回调队列
此时主线程是空闲的,就开始从异步回调队列开始提前任务,回调队列是先进先出,所以最先取出的是Promise.resolve(),将它调入调用栈,接着主线程就从调用栈中取出它运行,此时输出promise1,此时.then()会产生一个微任务,将其加入到异步回调队列中
接下来从回调队列中调出errorFunc()
async function errorFunc() {
try {
await Promise.reject("error!!!");
} catch (e) {
console.log("error caught");
}
console.log("errorFunc");
return Promise.resolve("errorFunc success");
}
因为 await会阻塞异步操作, 所以这个 await后面的 Promise不会进入回调队列排队, 而是等待完成,捕获到错误,此时输出error caught,接着是同步代码,直接输出errorFunc,然后返回的promise对象也会被加入到异步回调队列中
接着从回调队列中取出第一次.then()产生的微任务,执行第二个.then(),输出promise2
接着执行
errorFunc().then((res) => console.log("errorFunc then res"));
输出errorFunc then res
最后setTimeout的等待时间到了,将其回调函数加入回调队列,并执行,输出setTimeout
注意:因为宏任务队列一次取一个任务执行,执行完成后执行所有的微任务,当所有的微任务执行完成后在执行下一个宏任务,所以就算等待时间为0,也是在最后执行
所以最终结果为
"script start",
"script end",
"promise 1",
"error caught",
"errorFunc",
"promise 2",
"errorFunc then res",
"setTimeout"
补充
Promise.resolve()
.then(function () {
console.log("promise1");
})
以上代码会返回一个成功态的promise对象,也就是fulfilled状态
小结
介绍了 JavaScript 的单线程设计,它的设计初衷是为了让用户获得更好的交互体验。同时,为了避免单线程的任务执行过程中发生阻塞,事件循环(Event Loop)机制便出现了。
在浏览器和 Node.js 中,都存在单线程的 Event Loop 设计,它们之间的不一致主要表现为 Event Loop 阶段划分以及宏任务和微任务的处理。
或许你会感到疑惑,除了应对面试以外,掌握 JavaScript 的事件循环、宏任务和微任务相关机制,对我们有什么用处呢?
要知道,浏览器中在执行 JavaScript 代码的时候不会进行页面渲染,如果一项任务花费的时间太长,浏览器将无法执行其他任务(例如处理用户事件)。因此,当存在大量复杂的计算、或导致了死循环的编程错误时,甚至会使页面终止。
我们可以更合理地利用这些机制来拆分任务,比如考虑将多次触发的数据变更通过微任务收集起来,再一起进行 UI 的更新和渲染,便可以降低浏览器渲染的频率,提升浏览器的性能,给到用户更好的体验。
以上是关于JavaScript为什么是单线程-JS异步与回调详解的主要内容,如果未能解决你的问题,请参考以下文章